Python——集合与字典
文章目录
- Python——集合与字典
- 1.集合
- 1)集合的创建
- 2)集合内置方法
- 2.集合应用案例——列表去重
- 1)列表去重
- 2)明明的随机数
- 3)Python查看微信共同好友
- 3.字典
- 1)定义
- 2)字典创建与删除
- 4.字典应用案例
- 1)英文文本预处理:词频统计
- 2)列表去重方法三
- 3)switch语句实现
- 4)基于用户协同过滤算法的电影推荐代码demo
- 5.一键多值字典:defaultdict
- 6.内置数据结构总结
Python——集合与字典
1.集合
1)集合的创建
集合(set)是一个无序的不重复元素序列。1,2,3,4,1,2,3 = 1,2,3,4创建:
1). 使用大括号 { } 或者 set() 函数创建集合;
2). 注意:创建一个空集合必须用 set() 而不是 { }
{ } 是用来创建一个空字典。
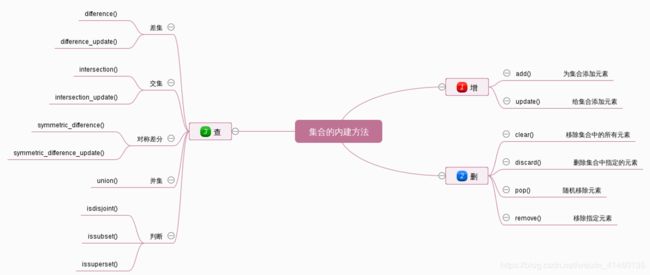
2)集合内置方法
2.集合应用案例——列表去重
1)列表去重
在抓取页面图片时,为避免重复抓取,将抓取的img结果(结果集是list类型的)通过集合去重。
方法一: 依次遍历并判断
ids = [1,2,3,3,4,2,3,4,5,6,1]
news_ids = []
for id in ids:
if id not in news_ids:
news_ids.append(id)
print news_ids
方法二: 通过set方法进行处理
ids = [1,4,3,3,4,2,3,4,5,6,1]
ids = list(set(ids))
2)明明的随机数
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤1000),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从大到小排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作(同一个测试用例里可能会有多组数据,希望大家能正确处理)。
import random
# 先生成n个随机数
# 列表, 集合也可以, 优先选择集合,
s = set([])
for i in range(int(input('N:'))):
# num = random.randint(1,1000)
# s.add(num)
s.add(random.randint(1,1000))
print(sorted(s))
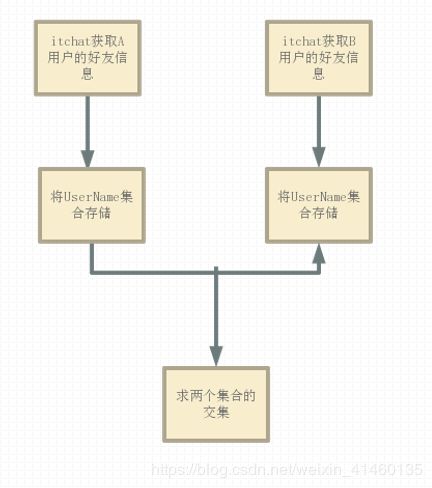
3)Python查看微信共同好友
random, math: 内置模块
itchat是一个开源的微信个人号接口,使用python调用微信从未如此简单。
思路:
1). 通过itchat微信个人号接口扫码登录个人微信网页版,获取可以识别好友身份的数 据。此项目需要分别登录两人微信的,拿到两人各自的好友信息存到列表中。
2). 查共同好友就转化成了查两个列表中相同元素的问题。获取到共同好友信息后, 可以通过命令行窗口print出来,也可以写入txt文件
import itchat
def get_list():
# 在命令行生成登录二维码
#itchat.auto_login(enableCmdQR=True)
# 获取登录二维码图片,扫码登录微信网页版
itchat.auto_login()
# 获取好友信息列表
friendList = itchat.get_friends(update=True)[1:]
# 每个登录的微信号生成一个好友信息列表
contactlist = set()
for i in friendList:
# 将该好友添加到列表中
contactlist.add(i['NickName'])
# 登出微信号
itchat.logout()
# 返回该微信号好友信息列表
return contactlist
#获取第一位扫码登录微信号的好友信息列表
contactlist1 = get_list()
#获取第二位扫码登录微信号的好友信息列表
contactlist2 = get_list()
#共同好友计数
print(len(contactlist1 & contactlist2 ))
3.字典
1)定义
字典是另一种可变容器模型,且可存储任意类型对象。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
2)字典创建与删除
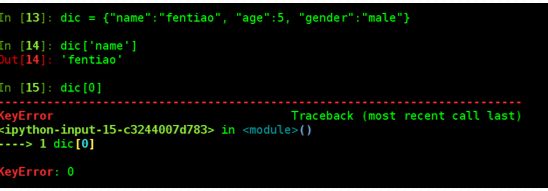
- 简单字典创建
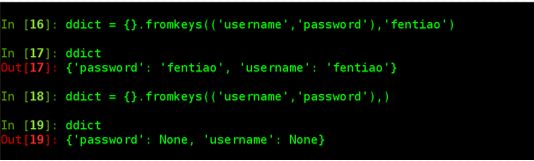
- 内建方法:fromkeys
字典中的key有相同的value值,默认为None
- zip间接创建


4.字典应用案例
1)英文文本预处理:词频统计
作为字典(key-value)的经典应用题目,单词统计几乎出现在每一种语言键值对学习后的必练题目,主要需求:
写一个函数wordcount统计一篇文章的每个单词出现的次数(词频统计)。统计完成后,对该统计按单词频次进行排序。
# ***************************方法一************************************
def wordcount(str):
# 文章字符串前期处理
strl_ist = str.replace('\n', '').lower().split(' ')
count_dict = {}
# 如果字典里有该单词则加1,否则添加入字典
for str in strl_ist:
if str in count_dict.keys():
count_dict[str] = count_dict[str] + 1
else:
count_dict[str] = 1
#按照词频从高到低排列
count_list=sorted(count_dict.iteritems(),key=lambda x:x[1],reverse=True)
return count_list
print wordcount(str_context)
# ***********************************方法二*******************************************
# ********************* 简易方法实现**********************
from collections import defaultdict
from collections import Counter
# **************1.统计每个单词出现的次数************
wordDict = defaultdict(int)
for word in li:
wordDict[word] += 1
print(wordDict.items())
# *******************2. 找出单词出现次数最多的3个单词**********
c = Counter(wordDict)
print(c.most_common(5))
2)列表去重方法三
方法三: 通过字典的方式去重:, 因为字典的key值是不能重复的.
li = [1, 2, 3, 4, 65, 1, 2, 3]
print({}.fromkeys(li).keys())
3)switch语句实现

# python里面不支持switch语句;
# C/C++/Java/Javascript:switch语句是用来简化if语句的.
grade = 'B'
if grade == 'A':
print("优秀")
elif grade == 'B':
print("良好")
elif grade == 'C':
print("合格")
else:
print('无效的成绩')
"""
C++:
char grade = 'B'
switch(grade)
{
case 'A':
print('')
break
case 'B':
print('')
break
default:
print('error')
}
"""
grade = 'D'
d = {
'A': '优秀',
'B':'良好',
'C':"及格"
}
# if grade in d:
# print(d[grade])
# else:
# print("无效的成绩")
print(d.get(grade, "无效的成绩"))
4)基于用户协同过滤算法的电影推荐代码demo
题目需求: 假设已有若干用户名字及其喜欢的电影清单,现有某用户,已看过并喜欢一些电影,现在想找个新电影看看,又不知道看什么好。根据已有数据,查找与该用户爱好最相似的用户,也就是看过并喜欢的电影与该用户最接近,然后从那个用户喜欢的电影中选取一个当前用户还没看过的电影,进行推荐。
{
“小明”: {“绿皮书”, “流浪地球”},
“小红”: {“绿皮书”, “流浪地球”},
}
# 1). 从文件中读取用户和电影数据
# 打开文件信息, 默认打开方式是读
f = open('movie.txt')
# 将文件中的json字符串转成python便于处理的字典数据类型;
movieDb = json.load(f)
# 关闭文件
f.close()
# print(type(movieDb))
# pprint.pprint(movieDb)
searchUser = input("请输入需要推荐的用户名: ")
# 2). 依次遍历字典的每一个元素, 查找跟user3用户交集最多的用户(user1);
# searchUser 和自己是不需要比较的;
searchUserMovies = set(movieDb.pop(searchUser))
# result存储 searchUser和每个用户喜欢电影交集的个数;= {'user1': 1, 'user2': 2}
result = {}
for user, movies in movieDb.items():
# 求用户和searchUser交集的个数;
interaction_count = len(set(movies) & searchUserMovies)
# 并存储到字典中;
result[user] = interaction_count
# 3). 打印统计结果
# pprint.pprint(result)
# 4). 对于结果进行排序
# 对字典的value值进行排序, 由大到小;
counter = Counter(result)
# 打印排序结果的前几个, 目前指定的是前5个;
top5UserCounter = counter.most_common(5)
# print(top5UserCounter)
# 5). 获取前5个跟searchUser相似用户喜欢的电影, 并求并集;
# 获取所有跟searchUser最相关的前5个用户名;
top5User = dict(top5UserCounter).keys()
# allUnionMovies 跟searchUser最相关的前5个用户喜欢的电影的并集; 定义空集合用set()
allUnionMovies = set()
for user in top5User:
# 获取用户喜欢的电影; 列表;
# 集合添加元素: add: 添加一个元素; update: 一次添加多个元素;
allUnionMovies.update(movieDb[user])
# 前5个用户喜欢的电影的并集 - searchUser喜欢的电影
allRecommendMovies = allUnionMovies - searchUserMovies
print(allRecommendMovies)
5.一键多值字典:defaultdict
collections.defaultdict类,本身提供了默认值的功能, 默认值可以是整形,列表,集合等.
-
需求:
我们想要一个能将键(key)映射到多个值的字(即所谓的一键多值字典) -
解决方案:
1). 字典是一种关联容器,每个键都映射到一个单独的值上。如果想让键映射到多个值,需要将这些多个值保存到容器(列表或者集合)中。
2). 利用collections模块中的defaultdict类自动初始化第一个值,这样只需关注添加元素.

-
案例练习:
用defaultDict来做一个练习,把list(随机生成50个1-100之间的随机数)中大于66的元素和小于66的元素
{
‘大于66的元素’: [71,8 2, ,83],
‘小于66的元素’: [1, 2, 3],
}
l1 = [123,12,344,56,777,888,999,999,8,33]
test_list = collections.defaultdict(list)
for i in l1:
if i > 66:
test_list["大于66的值"].append(i)
else:
test_list["小于66的值"].append(i)
print(test_list)
# defaultdict(, {'大于66的值': [123, 344, 777, 888, 999, 999], '小
于66的值': [12, 56, 8, 33]})
6.内置数据结构总结
-
可变数据类型:
可以增删改。可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。 -
不可变数据类型:
不可以增删改。python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象。 -
序列: Python包含列表、元组、字符串、集合, 字典等内建的序列。所有序列类型都可以进行某些特定的操作。可以for循环
-
有序序列: 这些操作包括:索引(indexing)、切片(sliceing)、连接操作符(adding)、重复操作符(multiplying)以及成员操作符。
-
非序列:int, long, float, bool, complex
-
可以for循环: 字符串, 列表, 元组, 集合, 字典
-
不可以for循环:数值类型(int, long, float, bool, complex)