阿里云ECS(Ubuntu)搭建hadoop3.X 伪分布式环境
一、准备工作
①利用xshell以及xftp远程连接云服务器
②配置云服务器的相关端口
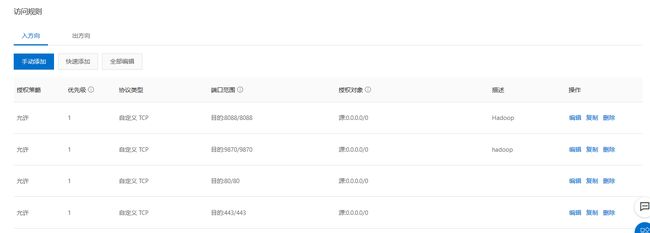
hadoop3.X相比hadoop2.X,网页端口变化:
Namenode ports: 50470 --> 9871, 50070 --> 9870, 8020 --> 9820
Secondary NN ports: 50091 --> 9869, 50090 --> 9868
Datanode ports: 50020 --> 9867, 50010 --> 9866, 50475 --> 9865, 50075 --> 9864
二、传输jdk、Hadoop到Ubuntu中并解压
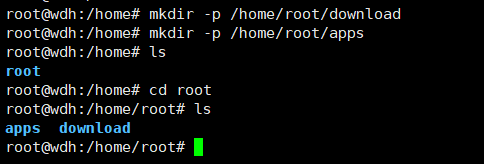
新建文件夹download放置文件压缩包
新建文件夹apps放置解压后的文件
mkdir -p /home/root/download
mkdir -p /home/root/apps
利用xftp将jdk以及Hadoop文件传输到download文件夹
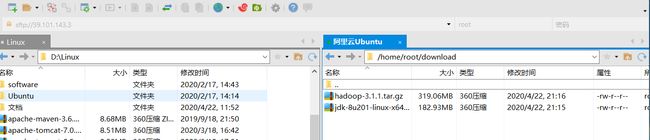
进入download文件夹解压jdk和hadoop到apps文件夹
cd /home/root/download
tar -xzvf jdk-8u201-linux-x64.tar.gz -C /home/root/apps
tar -xzvf hadoop-3.1.1.tar.gz -C /home/root/apps
进入apps文件夹查看是否解压成功
cd /home/root/apps
ll

三、配置jdk环境变量
修改文件:
vim ~/.bashrc
文件末尾加入:
(JAVA_HOME路径根据自己jdk解压后的文件路径来配置)
export JAVA_HOME=/home/root/apps/jdk1.8.0_201
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$JAVA_HOME/bin:$PATH
刷新配置文件
source ~/.bashrc
检验java环境变量是否配置正确,出现版本信息则成功
java -version

三、配置Hadoop环境变量
修改文件:
vim ~/.bashrc
文件末尾加入:
(HADOOP_HOME路径根据自己Hadoop解压后的文件路径来配置)
export HADOOP_HOME=/home/root/apps/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
刷新配置文件
source ~/.bashrc
检验Hadoop环境变量是否配置正确,出现版本信息则成功
(不是 -version)
hadoop version

四、安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆, 你可以登录某台 Linux 主机,并且在上面运行命令)
安装 SSH client,SSH server(大部分云服务器都是已经安装好的)
apt-get install openssh-clients
apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示输入密码,输入密码后就登陆到本机了。
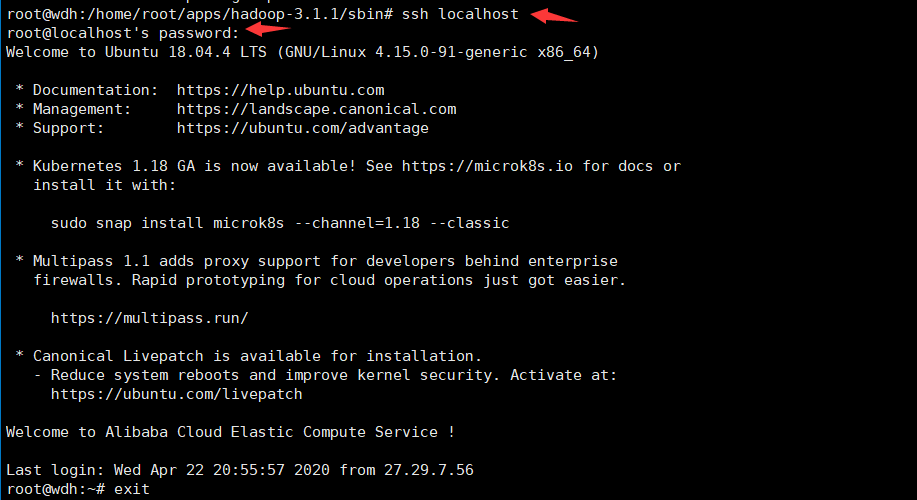
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了

五、修改hadoop相关的配置文件
①进入解压后的hadoop文件下的 etc/hadoop
cd /home/root/apps/hadoop-3.1.1/etc/hadoop

②编辑core-site.xml文件
vim core-site.xml
将如下代码填在在configuration标签内部
hadoop.tmp.dir
/home/root/apps/hadoop-3.1.1/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
③编辑hdfs-site.xml文件
vim hdfs-site.xml
将如下代码添加在configuration标签内部
dfs.replication
1
dfs.namenode.name.dir
file:/home/root/apps/hadoop-3.1.1/tmp/dfs/name
dfs.datanode.data.dir
file:/home/root/apps/hadoop-3.1.1/tmp/dfs/data
④编辑mapred-site.xml
vim mapred-site.xml
将如下代码添加在configuration标签内部
mapreduce.framework.name
yarn
⑤编辑yarn-site.xml
vim yarn-site.xml
将如下代码添加在configuration标签内部
yarn.nodemanager.aux-services
mapreduce_shuffle
⑥编辑hadoop-env.sh文件
找到 export JAVA_HOME=
将前面的#去掉
将java的安装路径添加在后面
export JAVA_HOME=/home/root/apps/jdk1.8.0_201
⑦编辑yarn-env.sh文件
将
export JAVA_HOME=/home/root/apps/jdk1.8.0_201
添加在在最后一行
六、格式化namenode
可能会有warning,但是只要没有error即格式化成功
hadoop namenode -format
七、修改sbin中相关文件
①进入sbin目录
cd /home/root/apps/hadoop-3.1.1/sbin
②修改 start-dfs.sh和stop-dfs.sh两个文件
在顶部加入如下代码
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
③修改 start-yarn.sh和stop-yarn.sh两个文件
在顶部加入如下代码
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
八、执行启动命令
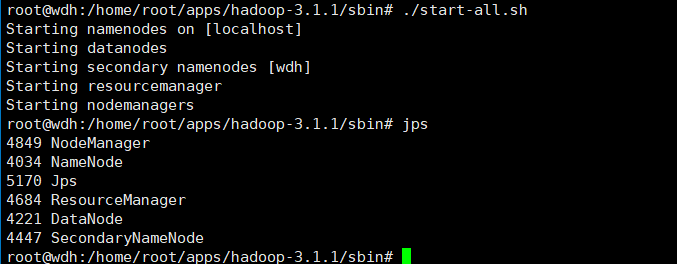
进入sbin目录下执行启动命令
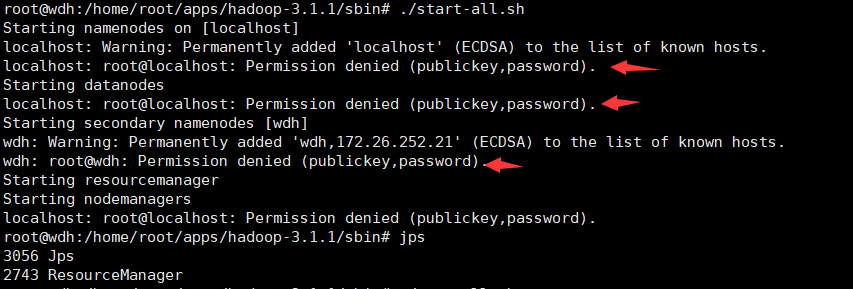
./start-all.sh
关闭命令:
./stop-all.sh
jps显示当前所有java进程pid,查看Hadoop是否启动成功
jps
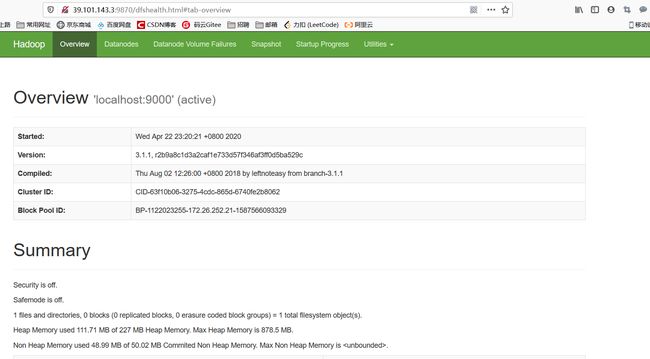
网页查看
公网IP:9870
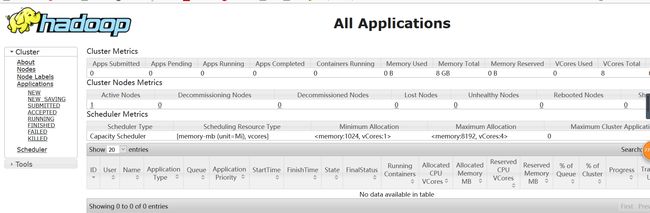
公网IP:8088
可能出现的问题:
问题一:

原因:没有配置sbin目录下的四个文件,按要求配置即可
问题二: