Deep Forest(gcforest)通俗易懂理解
DeepForest(gcforest)深度森林介绍
1.背景介绍
当前的深度学习模型主要建立在神经网络上,即可以通过反向传播训练的多层参数化可微分非线性模块,周志华老师希望探索深度学习模型的新模式,探索不可微模块构建深度模型的可能性。从而提出了一种深度学习模型-----gcforest(multi-Grained Cascade Forest)
上述算法主要有以下几个特点:
(1)超参数少
(2)模型的复杂度可以通过与数据相关的方式自动确定
(3)无需使用反向传播就可以实现深度模型
作者提出了三个疑问:
(1)深度模型=DNN?
(2)是否可以在不进行反向传播的情况下实现深度模型
(3)是否可以使得深度模型赢得kaggle比赛(就是对小数据集的表现)
2.作者的两个启发
2.1. DNN的启发
此篇论文刊登于2017年,当时一般人认为DNN的成功主要是由于DNN其巨大的模型复杂度,但作者认为不然,因为如此的话,浅层网络也可以通过添加无限数量的隐含层达到巨大模型复杂度的目的,但是浅层网络没有深度网络成功,作者认为模型复杂度并不是DNN成功的关键因素,认为逐层处理才是DNN成功的最关键因素,boosting集成算法及其决策树模型只是在数据的原始特征上做处理,没有对模型内的特征做特征变换,且只有有限的模型复杂度。
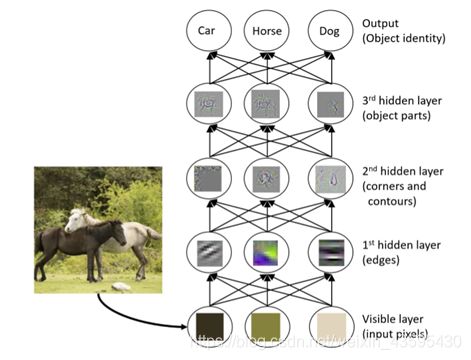
作者推测深度模型成功的三个因素为:
(1)逐层处理
(2)特征变换
(3)巨大的模型复杂度
2.2.集成学习的启示
作者认为为了建立一个好的集成模型,个体的学习应该是准确且多样化的,单方面的准确的基学习器不如合并准确的基学习器和一些较弱的基学习器效果好,因为可以达到互补的效果,准确的基学习器可以很好地预测那些容易预测的模块,但是一些较弱的基学习器可能对一些比较难以预测的模块进行准确预测,两方面之间的合并可以达到更好的效果,此方面也就是模型的多样性。
下面是提高模型多样性的一些方法:
(1)数据样本的操作:有放回的随机抽样,随机抽样,聚类抽样等。。。
(2)输入特征的操作:不同的特征的选取生成树的模型是不一样的
(3)学习参数的不同
(4)输出表示操作(将数据的标签进行改变,训练的模型可能会有所不同)
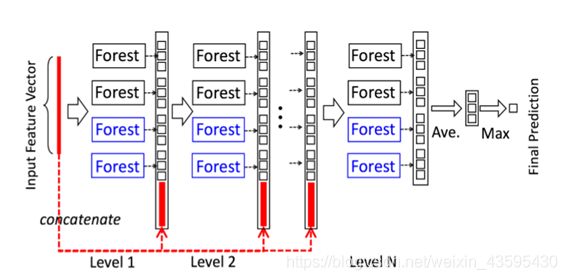
- gcforest
受上述DNN主要由于逐层处理的启发,gcforest采用级联结构
采用不同种类的树提高模型的多样性
使用两个完全随机的树森林和两个完全随机的随机森林,每个森林都产生500个随机生成的树,如果类别为三类别,每一个森林都会产生一个三维的特征向量(称为增强向量),一共产生一个12维的特征向量。
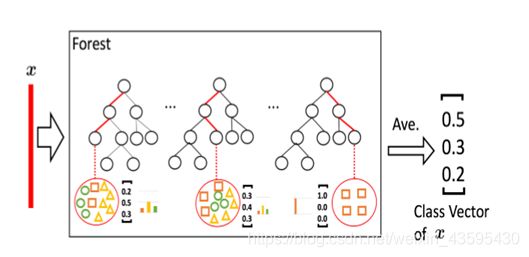
上述为增强向量的生成规则,通过相关样本所属的叶子结点的类分布进行平均得到,从而产生3维增强向量,每一个森林产生的增强向量都通过k折交叉验证生成,再对其取平均产生最终的增强向量,作为下一个级联的输入向量,扩展到新的模块之后,会在验证集上评估整个级联的性能,如果没有提升,则会停止级联,从而达到根据数据本身自动确定模型复杂度的目的。
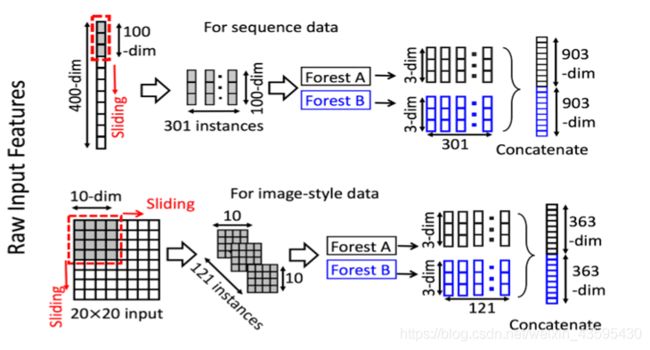
上述为多粒度扫描的结构图,对应上图的上方,假设输入特征是一个400维的序列特征向量,通过滑动一个100维特征窗口可以产生301个100维的特征向量,从正负训练样本提取的所有特征向量都被视为正负样本,用于生成增强向量,301个100维的特征向量如上图所示经过两个森林每个森林会产生301个三维的特征向量,两个森林经过concatenate一共生成903+903=1806维的特征向量。
上图下方假设为20x20x400的输入特征,经过10x10的窗口会产生121个10x10的特征向量,经过两个森林会产生2个121个的3维特征向量,合并之后一共产生一个726维的特征向量,当然也可以使用多尺度滑动窗口。
下面是整体框架图:
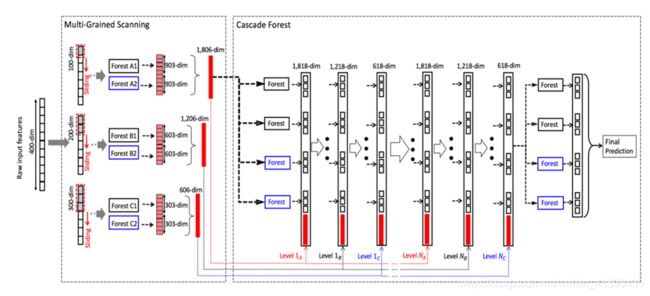
假设上述输入特征为400维的序列特征,经过三个滑动窗口分别为100维,200维,300维的滑动窗口,分别生成1806维,1206维,606维,对于Level 1A,1806维的特征向量经过4个森林产生一个12维的增强向量,并且和之前的输入特征(1806维)进行合并也就是1818维特征向量作为Level 1B的输入向量,经过4个森林也会产生一个12维的特征向量,再与200维滑动窗口生成的1206维的特征向量进行合并生成1218维的特征向量作为Level 1C的输入特征向量,同理,经过4个森林产生12维的特征向量,再与300维滑动窗口生成的606维向量进行合并产生610维的特征向量作为下一层级联的输入向量,自此,一个级联结束(Level 1A, 1B, 1C,每个级联由1A,1B,1C组成,每个级别代表一个扫描粒度)。到下一个级联也是如上述所示的操作,经过验证集评估每一个级联的效果,知道预测效果不在提升,最后Level Nc的生成的618维向量作为输入经过4个森林产生最终的12维增强向量用于最后的预测。
对于d维的原始特征,文中指出使用大小为d/16,d/8,d/4的特征窗口
4.代码
gcforest的代码已经开源,这里可以看到。
选择采用scikit学习语法以方便使用,下面将介绍如何使用它。
下面是参数的介绍:
shape_1X:
单个样本元素的形状[n_lines,n_cols]。 调用mg_scanning时需要!对于序列数据,可以给出单个int。
n_mgsRFtree:
多粒度扫描期间随机森林中的树木数量。
window:int(default = None)
多粒度扫描期间使用的窗口大小列表。如果“无”,则不进行切片。
stride:int(default = 1)
切片数据时使用的步骤。
cascade_test_size:float或int(default = 0.2)
级联训练集分裂的分数或绝对数。
n_cascadeRF:int(default = 2)
级联层中随机森林的数量,对于每个伪随机森林,创建完整的随机森林,因此一层中随机森林的总数将为2 * n_cascadeRF。
n_cascadeRFtree:int(default = 101)
级联层中单个随机森林中的树数。
min_samples_mgs:float或int(default = 0.1)
节点中执行拆分的最小样本数 在多粒度扫描随机森林训练期间。 如果int number_of_samples = int。 如果float,min_samples表示要考虑的初始n_samples的分数。
min_samples_cascade:float或int(default = 0.1)
节点中执行拆分的最小样本数 在级联随机森林训练期间。 如果int number_of_samples = int。 如果float,min_samples表示要考虑的初始n_samples的分数。
cascade_layer:int(default = np.inf)
允许的最大级联级数。 有用的限制级联的结构。
tolerance:float(default= 0.0)
联生长的精度差,整个级联的性能将在验证集上进行估计, 如果没有显着的性能增益,训练过程将终止
n_jobs:int(default = 1)
任意随机森林适合并预测的并行运行的工作数量。 如果为-1,则将作业数设置为核心数。
from GCForest import gcForest
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import confusion_matrix as cm,recall_score as recall,roc_auc_score as auc
data = pd.read_csv('data.csv',header=None,encoding='utf-16')
x = data.iloc[:,0:264]
y = data.iloc[:,-1]
#x = x.fillna(0)
x = np.array(x)
#y = y.fillna(0)
y = np.array(y)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.3)
model = gcForest(shape_1X=264, n_mgsRFtree=30, window=90,)
model.fit(X_train, y_train) #fit(X,y) 在输入数据X和相关目标y上训练gcForest;
y_predict = model.predict(X_test) #预测未知样本X的类别;
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true=y_test, y_pred=y_predict)
print('gcForest accuracy : {}'.format(accuracy))
没有做参数的选择,可能做了之后效果会好一点。下面是结果:准确率为74.52%,但是这个级联好像没有效果,对于我的这个数据。

手写数字识别的表现:
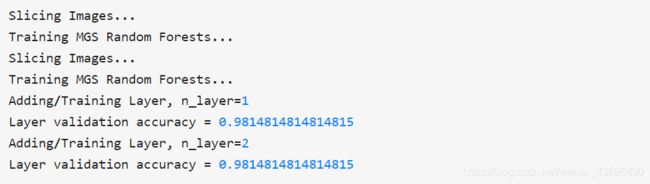
上面的实在手写数字识别的数据上面的表现,很简单的参数就可以表现很好的效果,达到了98.14%
5.评价
下面给出一些我运行过程中认为有道理的知乎大神的一些评论:

深度森林对小数据分析确实要比深度学习鲁棒性更好。多粒度扫描是真的吃资源,在cv问题中,这是不容忽视的问题,想要应用必须要先优化这个问题。在nlp中可能不存在这个问题,我也不是很清楚。深度森林确实有科研价值,没有跟风DL(毕竟周大佬本来就是搞深度森林的)。如果只是想刷榜,或者落地应用一下,真的比不过DL。所以,深度森林替换深度学习,是不可能的,引用在这里
我的理解:深度森林确实有科研价值,没有跟风DL,但是当前不可能比得过DL,没有核心的转变,替换是不可能的!