python正则表达式入门
本文主要学习python中正则表达式的使用
何为正则表达式
根据百科:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
根据菜鸟教程的里的定义则为:正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等
简单地来说:通过定义一些规则字符串(A)去从需要被匹配的字符串(可以认为是一堆文本信息)中匹配出我们需要的内容。而我们需要的内容被定义成了规则的字符串即前面的字符串(A)。
初识python正则
使用python自带的re模块
import re
因为正则表达式也是用字符串表示的,所以,我们要首先了解如何用字符来描述字符。
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,所以:
‘00\d’可以匹配’007’,但无法匹配’00A’;
‘\d\d\d’可以匹配’010’;
‘\w\w\d’可以匹配’py3’;
'.'可以匹配任意字符,所以:
‘py.‘可以匹配’pyc’、‘pyo’、‘py!‘等等。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
来看一个复杂的例子:\d{3}\s+\d{3,8}。
我们来从左到右解读一下:
\d{3}表示匹配3个数字,例如’010’;
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配’ ‘,’ ‘等
\d{3,8}表示3-8个数字,例如’1234567’。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配’010-12345’这样的号码呢?由于’-‘是特殊字符,在正则表达式中,要用’‘转义,所以,上面的正则是\d{3}-\d{3,8}。
但是,仍然无法匹配’010 - 12345’,因为带有空格。所以我们需要更复杂的匹配方式。
re模块中的部分函数介绍
re.compile()
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。(也可以这样理解:就是将我们给的匹配规则即字符串传入,compile函数会自动把它变为Pattern对象,提前进行编译,从而提高效率。)
所以这个是match()和search()的前序工作,但是你也可以选择不用compile()生成一个Pattern对象,可以直接直接使用match()和search()语法进行。只是在一些需要复杂的匹配规则时,使用compile()可以提高代码运行的效率,也使得代码更加的清晰。
语法:
re.compile(string,flags)
string:字符串形式的正则表达式
flags:可选参数,指定匹配模式(文末会有匹配模式的汇总)
re.match()
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none.(注意:match函数匹配的是从起始位置,也就是如果起始位置一旦不匹配,就直接返回None;这也是与search()的区别)
语法:
re.match(pattern,string,flags)
pattern:Pattern对象
string:待被匹配的内容
flags:可选参数,匹配模式
如果使用match()匹配成功后,可以使用group()或group(num)来获取匹配成功的内容
例:
注意先使用import re 导入re模块
string = "Hajo's best friend is Shanel."
pattern = re.compile('(.*?)\'s best friend is(.*)')
matchOjb = re.match(pattern,string)
##或者不使用compile()
matchOjb3 = re.match(r'(.*?)\'s best friend is(.*)',string)
##输出结果:
使用group()或者group(num)获取内容
matchOjb3.group()#matchOjb3.group(0)
##输出结果:"Hajo's best friend is Shanel."
matchOjb3.group(1)
##输出结果:'Hajo'
matchOjb3.group(2)
##输出结果:' Shanel.'
re.search()
re.search 扫描整个字符串并返回第一个成功的匹配。(search会扫描整个内容,但是只会返回第一个成功匹配的内容,所以如果匹配成功的话,结果也就只有一个内容)
语法:
re.search(pattern,string,flags)
pattern:Pattern对象
string:待被匹配的内容
flags:可选参数,匹配模式
如果使用match()匹配成功后,可以使用group()或group(num)来获取匹配成功的内容
例:从一串字符串中匹配手机号码
string = "Hajo's phone is 15500022252,and SHanel's phone is 15500022253"
phone = re.search(r'\d{11}',string) ## \d{11}可以理解为:匹配一个11位的数字
phone
##输出结果:
phone.group()
##输出结果:'15500022252'
由于只匹配第一个,如果这是使用group(2)就会报索引错误:
phone.group(2)
##报错:
Traceback (most recent call last):
File "", line 1, in
phone.group(2)
IndexError: no such group
re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。(findall函数匹配带匹配字符串中所有可以被匹配的内容,是多次的,而match和search是单次的)
语法:
re.findall(pattern,string,flags)
pattern:Pattern对象
string:待被匹配的内容
flags:可选参数,匹配模式
结果返回一个列表
例:匹配手机号码
string = "Hajo's phone is 15500022252,and SHanel's phone is 15500022253"
phone = re.findall(r'\d{11}',string) ## \d{11}可以理解为:匹配一个11位的数字
phone
##输出结果:['15500022252', '15500022253']
所以,在爬虫中,对于页面内容的解析中,如果使用正则表达式时,我们一般使用findall()函数
re.split()
split 方法按照能够匹配的子串将字符串分割后返回列表。其用法与split()函数的使用方法相似,不过split()函数只能分割一次,而re.split()可以实现同时分割多次。
其区别如下:
对于’a b b c c’,进行空格分割
正常代码:
'a b b c c'.split(' ')
##输出结果:['a', '', '', 'b', 'b', 'c', '', '', 'c']
可以看到结果出现很多我们不需要的空格
而使用re.split()可以解决这问题:
string = 'a b b c c'
result = re.split(r'\s+',string)
result
##输出结果:['a', 'b', 'b', 'c', 'c']
注意:这里使用了’\s+‘表示至少一个空格,如果使用’\s’,则跟普通的split结果一样
以上就python 正则表达式的部分函数介绍和使用方法;正则表达式还有:re.fullmatch(),re.sub(),re.finditer()这些函数,如果需要的可以参考:
https://www.runoob.com/python3/python3-reg-expressions.html
或者官方文档:
https://docs.python.org/zh-cn/3/library/re.html
总结
match的常用用法:
match函数(还有fullmatch函数)一般用于判断,其伪代码如下:
string = '用户输入的字符串'
if re.match(r'正则表达式', string):
##存在时执行的内容......
print('ok')
else:
##不存在时,执行的内容.......
print('failed')
部分常用的匹配规则:
Email:
"^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$"
手机号码(国内)
"^(13[0-9}|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$"
url
"[a-zA-Z]+://[^\s]*"
#或
"^[http|https]://([\w-]+\.)+[\w-]+(/[\w_./?%&=]*)?$"
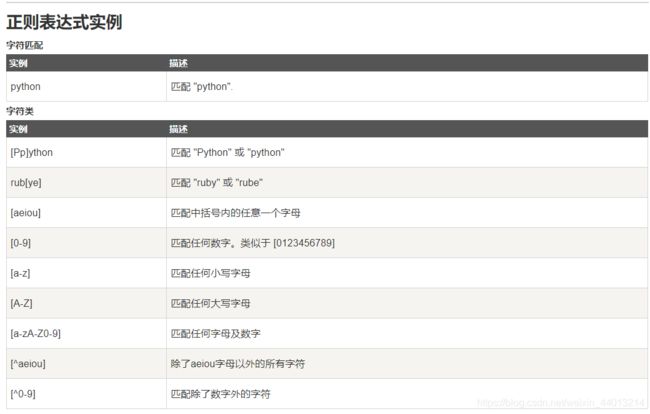
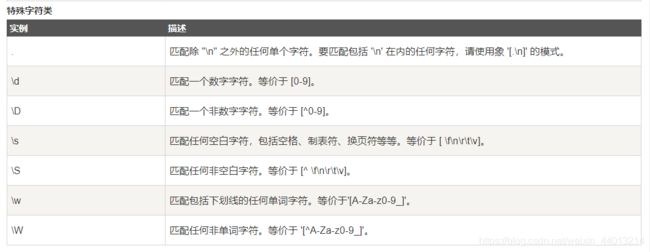
常用的正则表达式
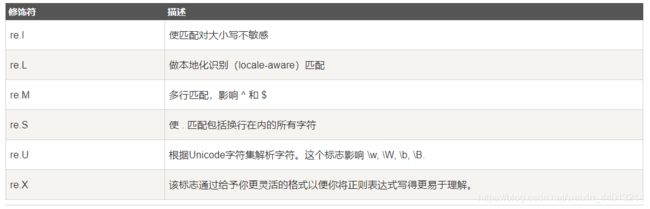
可选标志(匹配模式)
正则实例
正则表达式模式

以上内容总结自菜鸟教程和廖雪峰的官方网站。