Oozie的安装与使用
Oozie的介绍
Oozie是运行在hadoop平台上的一种工作流调度引擎,它可以用来调度与管理hadoop任务,如,MapReduce、Pig等。
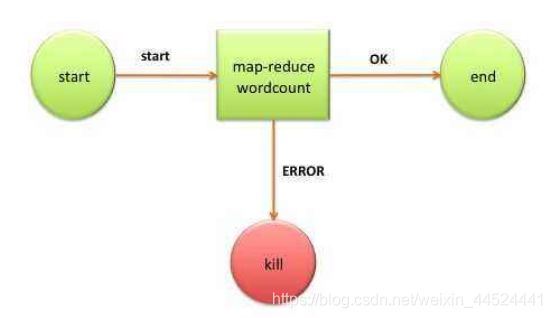
oozie的组件介绍
workFlow:工作流,定义工作流任务的执行,主要由一个个的action组成,每个action都是一个任务,在xml中 进行配置即可
Coordinator :协作器,可以理解为工作流的协调器,可以将多个工作流协调成一个工作流来进行处理。也是 oozie当中的定时任务调度的模块,
Bundle :捆,束。多个Coordinator 的抽象,可以通过bundle将多个Coordinator 进行组装集合起来,形成一个 bundle

oozie的架构

oozie的安装
第一步:修改core-site.xml
修改core-site.xml添加我们hadoop集群的代理用户
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim core-site.xml
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
注意:hadoop的历史任务的服务必须启动,即19888端口可以查看,具体如何配置19888请查看hadoop课程的环境搭建
修改完成之后,记得重启hadoop的hdfs与yarn集群,还要记得启动jobhistory
重启hdfs与yarn集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/stop-dfs.sh
sbin/start-dfs.sh
sbin/stop-yarn.sh
sbin/start-yarn.sh
第二步:上传oozie的安装包并解压
将oozie的安装包上传到/export/softwares
cd /export/softwares/
tar -zxvf oozie-4.1.0-cdh5.14.0.tar.gz -C …/servers/
第三步:解压hadooplibs到与oozie平行的目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
tar -zxvf oozie-hadooplibs-4.1.0-cdh5.14.0.tar.gz -C …/
第四步:创建libext目录
在oozie的安装路径下创建libext目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
mkdir -p libext
第五步:拷贝依赖包到libext
拷贝一些依赖包到libext目录下面去
拷贝所有的依赖包
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra hadooplibs/hadooplib-2.6.0-cdh5.14.0.oozie-4.1.0-cdh5.14.0/* libext/
拷贝mysql的驱动包
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/oozie-4.1.0-cdh5.14.0/libext/
第六步:添加ext-2.2.zip压缩包
拷贝ext-2.2.zip这个包到libext目录当中去
将我们准备好的软件ext-2.2.zip拷贝到libext目录当中去
第七步:修改oozie-site.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/conf
vim oozie-site.xml
如果没有这些属性,直接添加进去即可,oozie默认使用的是UTC的时区,我们需要在我们oozie-site.xml当中记得要配置时区为GMT+0800时区
oozie.service.JPAService.jdbc.driver
com.mysql.jdbc.Driver
oozie.service.JPAService.jdbc.url
jdbc:mysql://node03.hadoop.com:3306/oozie
oozie.service.JPAService.jdbc.username
root
oozie.service.JPAService.jdbc.password
123456
oozie.processing.timezone
GMT+0800
oozie.service.ProxyUserService.proxyuser.hue.hosts
*
oozie.service.ProxyUserService.proxyuser.hue.groups
*
oozie.service.coord.check.maximum.frequency
false
oozie.service.HadoopAccessorService.hadoop.configurations
*=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
第八步:创建mysql数据库
mysql -uroot -p
create database oozie;
第九步:上传oozie依赖的jar包到hdfs上面去
上传oozie的解压后目录的yarn.tar.gz到hdfs目录去
bin/oozie-setup.sh sharelib create -fs hdfs://node01:8020 -locallib oozie-sharelib-4.1.0-cdh5.14.0-yarn.tar.gz
实际上就是将这些jar包解压到了hdfs上面的路径下面去了
第十步:创建oozie的数据库表
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh db create -run -sqlfile oozie.sql
第十一步:打包项目,生成war包
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh prepare-war
第十二步:配置oozie的环境变量
vim /etc/profile
export OOZIE_HOME=/export/servers/oozie-4.1.0-cdh5.14.0
export OOZIE_URL=http://node03.hadoop.com:11000/oozie
export PATH=:$OOZIE_HOME/bin:$PATH
source /etc/profile
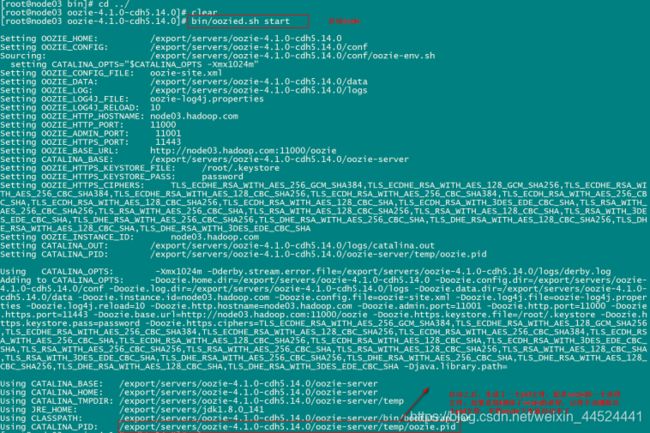
第十三步:启动与关闭oozie服务
启动命令
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozied.sh start
关闭命令
bin/oozied.sh stop
第十四步:浏览器页面访问oozie
http://node03:11000/oozie/
解决oozie的页面的时区问题:
我们页面访问的时候,发现oozie使用的还是GMT的时区,与我们现在的时区相差一定的时间,所以我们需要调整一个js的获取时区的方法,将其改成我们现在的时区
修改js当中的时区问题
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie-server/webapps/oozie
vim oozie-console.js
function getTimeZone() {
Ext.state.Manager.setProvider(new Ext.state.CookieProvider());
return Ext.state.Manager.get(“TimezoneId”,“GMT+0800”);
}
重启oozie即可
cd /export/servers/oozie-4.1.0-cdh5.14.0
关闭oozie服务
bin/oozied.sh stop
启动oozie服务
bin/oozied.sh start
oozie的使用
使用oozie调度shell脚本
oozie安装好了之后,需要测试oozie的功能是否完整好使,官方已经给我们带了各种测试案例,我们可以通过官方提供的各种案例来对oozie进行调度
第一步:解压官方提供的调度案例
oozie自带了各种案例,我们可以使用oozie自带的各种案例来作为模板,所以我们这里先把官方提供的各种案例给解压出来
cd /export/servers/oozie-4.1.0-cdh5.14.0
tar -zxf oozie-examples.tar.gz

第二步:创建工作目录
在任意地方创建一个oozie的工作目录,以后调度任务的配置文件全部放到oozie的工作目录当中去
我这里直接在oozie的安装目录下面创建工作目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
mkdir oozie_works
第三步:拷贝任务模板到工作目录当中去
任务模板以及工作目录都准备好了之后,我们把shell的任务模板拷贝到我们oozie的工作目录当中去
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -r examples/apps/shell/ oozie_works/
第四步:随意准备一个shell脚本
cd /export/servers/oozie-4.1.0-cdh5.14.0
vim oozie_works/shell/hello.sh
注意:这个脚本一定要是在我们oozie工作路径下的shell路径下的位置
#!/bin/bash
echo "hello world" >> /export/servers/hello_oozie.txt
第五步:修改模板下的配置文件
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/shell
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell
EXEC=hello.sh
修改workflow.xml
vim workflow.xml
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${EXEC}
/user/root/oozie_works/shell/${EXEC}#${EXEC}
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]
第六步:上传调度任务到hdfs上面去
注意:上传的hdfs目录为/user/root,因为我们hadoop启动的时候使用的是root用户,如果hadoop启动的是其他用户,那么就上传到
/user/其他用户
cd /export/servers/oozie-4.1.0-cdh5.14.0
hdfs dfs -put oozie_works/ /user/root
第七步:执行调度任务
通过oozie的命令来执行调度任务
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://bd001:11000/oozie -config oozie_works/shell/job.properties -run
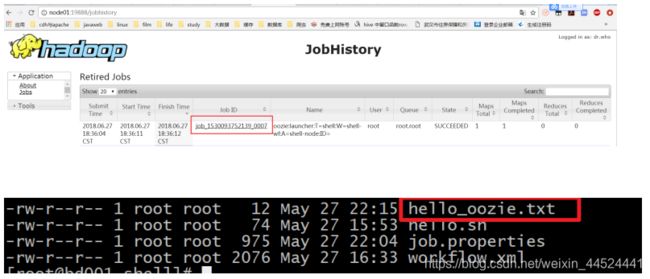
从监控界面可以看到任务执行成功了

查看hadoop的19888端口,我们会发现,oozie启动了一个MR的任务去执行shell脚本
使用oozie调度hive
第一步:拷贝hive的案例模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra examples/apps/hive2/ oozie_works/
第二步:编辑hive模板
这里使用的是hiveserver2来进行提交任务,需要注意我们要将hiveserver2的服务给启动起来
hive --service hiveserver2 &
hive --service metastore &
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/hive2
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
jdbcURL=jdbc:hive2://node03:10000/default
examplesRoot=oozie_works
oozie.use.system.libpath=true
#配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/hive2这个路径下
oozie.wf.application.path= n a m e N o d e / u s e r / {nameNode}/user/ nameNode/user/{user.name}/${examplesRoot}/hive2
修改workflow.xml
vim workflow.xml
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${jdbcURL}
INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table
OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2
Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
编辑hivesql文件
vim script.q
DROP TABLE IF EXISTS test;
CREATE EXTERNAL TABLE default.test (a INT) STORED AS TEXTFILE LOCATION ‘${INPUT}’;
insert into test values(10);
insert into test values(20);
insert into test values(30);
第三步:上传工作文件到hdfs
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
hdfs dfs -put hive2/ /user/root/oozie_works/
第四步:执行oozie的调度
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://bd001:11000/oozie -config oozie_works/hive2/job.properties -run
第五步:查看调度结果

使用oozie调度MR任务
第一步:准备MR执行的数据
我们这里通过oozie调度一个MR的程序的执行,MR的程序可以是自己写的,也可以是hadoop工程自带的,我们这里就选用hadoop工程自带的MR程序来运行wordcount的示例
准备以下数据上传到HDFS的/oozie/input路径下去
hdfs dfs -mkdir -p /oozie/input
vim wordcount.txt
hello world hadoop
spark hive hadoop
将数据上传到hdfs对应目录
hdfs dfs -put wordcount.txt /oozie/input
第二步:执行官方测试案例
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar wordcount /oozie/input/ /oozie/output
第三步:准备调度的资源
将需要调度的资源都准备好放到一个文件夹下面去,包括jar包,job.properties,以及workflow.xml。
拷贝MR的任务模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra examples/apps/map-reduce/ oozie_works/
删掉MR任务模板lib目录下自带的jar包
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib
rm -rf oozie-examples-4.1.0-cdh5.14.0.jar
第三步:拷贝的jar包到对应目录
从上一步的删除当中,可以看到需要调度的jar包存放在了
/export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib这个目录下,所以我们把我们需要调度的jar包也放到这个路径下即可
cp /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib/
第四步:修改配置文件
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.wf.application.path= n a m e N o d e / u s e r / {nameNode}/user/ nameNode/user/{user.name}/${examplesRoot}/map-reduce/workflow.xml
outputDir=/oozie/output
inputdir=/oozie/input
修改workflow.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim workflow.xml
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
mapred.mapper.new-api
true
mapred.reducer.new-api
true
mapreduce.job.output.key.class
org.apache.hadoop.io.Text
mapreduce.job.output.value.class
org.apache.hadoop.io.IntWritable
mapred.input.dir
${nameNode}/${inputdir}
mapred.output.dir
${nameNode}/${outputDir}
mapreduce.job.map.class
org.apache.hadoop.examples.WordCount$TokenizerMapper
mapreduce.job.reduce.class
org.apache.hadoop.examples.WordCount$IntSumReducer
mapred.map.tasks
1
Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
第五步:上传调度任务到hdfs对应目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
hdfs dfs -put map-reduce/ /user/root/oozie_works/
第六步:执行调度任务
执行调度任务,然后通过oozie的11000端口进行查看任务结果
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://bd001:11000/oozie -config oozie_works/map-reduce/job.properties -run
oozie的任务串联
在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个action,实现多个任务之间的相互依赖关系
需求:首先执行一个shell脚本,执行完了之后再执行一个MR的程序,最后再执行一个hive的程序
第一步:准备工作目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
mkdir -p sereval-actions
第二步:准备调度文件
将我们之前的hive,shell,以及MR的执行,进行串联成到一个workflow当中去,准备资源文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp hive2/script.q sereval-actions/
cp shell/hello.sh sereval-actions/
cp -ra map-reduce/lib sereval-actions/
第三步:开发调度的配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
创建配置文件workflow.xml并编辑
vim workflow.xml
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${EXEC}
/user/root/oozie_works/sereval-actions/${EXEC}#${EXEC}
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
mapred.mapper.new-api
true
mapred.reducer.new-api
true
mapreduce.job.output.key.class
org.apache.hadoop.io.Text
mapreduce.job.output.value.class
org.apache.hadoop.io.IntWritable
mapred.input.dir
${nameNode}/${inputdir}
mapred.output.dir
${nameNode}/${outputDir}
mapreduce.job.map.class
org.apache.hadoop.examples.WordCount$TokenizerMapper
mapreduce.job.reduce.class
org.apache.hadoop.examples.WordCount$IntSumReducer
mapred.map.tasks
1
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${jdbcURL}
INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table
OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]
开发job.properties配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
EXEC=hello.sh
outputDir=/oozie/output
inputdir=/oozie/input
jdbcURL=jdbc:hive2://node03:10000/default
oozie.use.system.libpath=true
#配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/sereval-actions这个路径下
oozie.wf.application.path= n a m e N o d e / u s e r / {nameNode}/user/ nameNode/user/{user.name}/${examplesRoot}/sereval-actions/workflow.xml
第四步:上传资源文件夹到hdfs对应路径
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/
hdfs dfs -put sereval-actions/ /user/root/oozie_works/
第五步:执行调度任务
cd /export/servers/oozie-4.1.0-cdh5.14.0/
bin/oozie job -oozie http://node03:11000/oozie -config oozie_works/serveral-actions/job.properties -run
oozie的任务调度,定时任务执行
在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与workflow类似的,Coordinator 这个模块也是主要通过xml来进行配置即可,接下来我们就来看看如何配置Coordinator 来实现任务的定时调度
Coordinator 的调度主要可以有两种实现方式
第一种:基于时间的定时任务调度,
oozie基于时间的调度主要需要指定三个参数,第一个起始时间,第二个结束时间,第三个调度频率
第二种:基于数据的任务调度,只有在有了数据才会去触发执行
这种是基于数据的调度,只要在有了数据才会触发调度任务
oozie当中定时任务的设置
第一步:拷贝定时任务的调度模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -r examples/apps/cron oozie_works/cron-job
第二步:拷贝hello.sh脚本
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp shell/hello.sh cron-job/
第三步:修改配置文件
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/cron-job
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.coord.application.path= n a m e N o d e / u s e r / {nameNode}/user/ nameNode/user/{user.name}/ e x a m p l e s R o o t / c r o n − j o b / c o o r d i n a t o r . x m l s t a r t = 2018 − 08 − 22 T 19 : 20 + 0800 e n d = 2019 − 08 − 22 T 19 : 20 + 0800 E X E C = h e l l o . s h w o r k f l o w A p p U r i = {examplesRoot}/cron-job/coordinator.xml start=2018-08-22T19:20+0800 end=2019-08-22T19:20+0800 EXEC=hello.sh workflowAppUri= examplesRoot/cron−job/coordinator.xmlstart=2018−08−22T19:20+0800end=2019−08−22T19:20+0800EXEC=hello.shworkflowAppUri={nameNode}/user/ u s e r . n a m e / {user.name}/ user.name/{examplesRoot}/cron-job/workflow.xml
修改coordinator.xml
vim coordinator.xml
${workflowAppUri}
jobTracker
${jobTracker}
nameNode
${nameNode}
queueName
${queueName}
修改workflow.xml
vim workflow.xml
${jobTracker}
${nameNode}
mapred.job.queue.name
${queueName}
${EXEC}
/user/root/oozie_works/cron-job/${EXEC}#${EXEC}
第四步:上传到hdfs对应路径
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
hdfs dfs -put cron-job/ /user/root/oozie_works/
第五步:运行定时任务
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://node03:11000/oozie -config oozie_works/cron-job/job.properties -run
oozie当中任务的查看以及杀死
查看所有普通任务
oozie jobs -oozie http://bd001:11000/oozie
查看定时任务
oozie jobs -oozie http://bd001:11000/oozie -jobtype coordinator

杀死某个任务
oozie可以通过jobid来杀死某个定时任务
oozie job -kill [id]
例如我们可以使用命令
oozie job -oozie http://bd001:11000/oozie -kill 0000033-200526143050941-oozie-root-W
来杀死我们定时任务

Oozie和Azkaban来做对比:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
工作流定义: Oozie是通过xml定义的而Azkaban为properties来定义。
部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
运行环境: Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行