Android GreenDao的基本应用
转载请注明:
http://blog.csdn.net/sinat_30276961/article/details/50061377
上一篇介绍了GreenDao的基本特性和使用GreenDao的Generator生成数据库业务代码。本篇将基于上篇的例子,继续讲解GreenDao的核心api,增删改查。
按照国际惯例,先讲实例演示:
我要展示的小应用是一个很简单的资讯查看类应用,意在展示greendao的使用,别吐槽它有多简陋。
它包含两个主体界面:
1.新闻列表界面
可以增加新闻,也可以删除新闻,然后可以根据标题动态搜索新闻。
(这里包含了增、删、查)
2.新闻详细界面
可以查看新闻的详情和评价,然后可以评价。
(这里包含增,改。增,体现在一则新闻对应的评价增加)
这两个界面都是通过fragment去维护。
新闻列表展示根据新闻时间升序排序;长按某条新闻,就会删除当前新闻;点击右上角的“ADD NEWS”,会增加一条新闻;点击进入新闻,可以更新内容:

点击ActionBar的”SEARCH”,就会根据输入内容动态显示包含关键字的新闻列表;进入新闻详细页,可以输入评价信息:

ok,实例演示看完,接着步入正题。
上篇,通过创建了一个java工程,生成了一些数据库业务代码:

由于篇幅有限,时间有限。关于生成的数据业务代码,在这里会很快的过一遍。
业务代码
首先,来看下首席执行官–DaoMaster:
public class DaoMaster extends AbstractDaoMaster {
public static final int SCHEMA_VERSION = 1;
/** Creates underlying database table using DAOs. */
public static void createAllTables(SQLiteDatabase db, boolean ifNotExists) {
NewsDao.createTable(db, ifNotExists);
DetailDao.createTable(db, ifNotExists);
OpinionDao.createTable(db, ifNotExists);
}
/** Drops underlying database table using DAOs. */
public static void dropAllTables(SQLiteDatabase db, boolean ifExists) {
NewsDao.dropTable(db, ifExists);
DetailDao.dropTable(db, ifExists);
OpinionDao.dropTable(db, ifExists);
}
public static abstract class OpenHelper extends SQLiteOpenHelper {
public OpenHelper(Context context, String name, CursorFactory factory) {
super(context, name, factory, SCHEMA_VERSION);
}
@Override
public void onCreate(SQLiteDatabase db) {
Log.i("greenDAO", "Creating tables for schema version " + SCHEMA_VERSION);
createAllTables(db, false);
}
}
/** WARNING: Drops all table on Upgrade! Use only during development. */
public static class DevOpenHelper extends OpenHelper {
public DevOpenHelper(Context context, String name, CursorFactory factory) {
super(context, name, factory);
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
Log.i("greenDAO", "Upgrading schema from version " + oldVersion + " to " + newVersion + " by dropping all tables");
dropAllTables(db, true);
onCreate(db);
}
}
public DaoMaster(SQLiteDatabase db) {
super(db, SCHEMA_VERSION);
registerDaoClass(NewsDao.class);
registerDaoClass(DetailDao.class);
registerDaoClass(OpinionDao.class);
}
public DaoSession newSession() {
return new DaoSession(db, IdentityScopeType.Session, daoConfigMap);
}
public DaoSession newSession(IdentityScopeType type) {
return new DaoSession(db, type, daoConfigMap);
}
}代码不多,而且也都是创建数据库的基本代码,可以看到,DaoMaster创建了一个内部类继承自SQLiteOpenHelper,然后创建数据表。在数据库版本增加时,先drop再create。然后还提供了获取DaoSession的接口。
接着看看DaoSession:
public class DaoSession extends AbstractDaoSession {
private final DaoConfig newsDaoConfig;
private final DaoConfig detailDaoConfig;
private final DaoConfig opinionDaoConfig;
private final NewsDao newsDao;
private final DetailDao detailDao;
private final OpinionDao opinionDao;
public DaoSession(SQLiteDatabase db, IdentityScopeType type, Map>, DaoConfig>
daoConfigMap) {
super(db);
newsDaoConfig = daoConfigMap.get(NewsDao.class).clone();
newsDaoConfig.initIdentityScope(type);
detailDaoConfig = daoConfigMap.get(DetailDao.class).clone();
detailDaoConfig.initIdentityScope(type);
opinionDaoConfig = daoConfigMap.get(OpinionDao.class).clone();
opinionDaoConfig.initIdentityScope(type);
newsDao = new NewsDao(newsDaoConfig, this);
detailDao = new DetailDao(detailDaoConfig, this);
opinionDao = new OpinionDao(opinionDaoConfig, this);
registerDao(News.class, newsDao);
registerDao(Detail.class, detailDao);
registerDao(Opinion.class, opinionDao);
}
public void clear() {
newsDaoConfig.getIdentityScope().clear();
detailDaoConfig.getIdentityScope().clear();
opinionDaoConfig.getIdentityScope().clear();
}
public NewsDao getNewsDao() {
return newsDao;
}
public DetailDao getDetailDao() {
return detailDao;
}
public OpinionDao getOpinionDao() {
return opinionDao;
}
} 可以看到,DaoSession初始化了三个Dao类,然后提供getter方法。
接着,关于三个Dao类,挑一个NewsDao:
public class NewsDao extends AbstractDao<News, Long> {
public static final String TABLENAME = "NEWS";
/**
* Properties of entity News.
* Can be used for QueryBuilder and for referencing column names.
*/
public static class Properties {
public final static Property Id = new Property(0, Long.class, "id", true, "_id");
public final static Property Title = new Property(1, String.class, "title", false, "TITLE");
public final static Property Time = new Property(2, String.class, "time", false, "TIME");
public final static Property DetailId = new Property(3, long.class, "detailId", false, "DETAIL_ID");
};
private DaoSession daoSession;
public NewsDao(DaoConfig config) {
super(config);
}
public NewsDao(DaoConfig config, DaoSession daoSession) {
super(config, daoSession);
this.daoSession = daoSession;
}
/** Creates the underlying database table. */
public static void createTable(SQLiteDatabase db, boolean ifNotExists) {
String constraint = ifNotExists? "IF NOT EXISTS ": "";
db.execSQL("CREATE TABLE " + constraint + "\"NEWS\" (" + //
"\"_id\" INTEGER PRIMARY KEY ," + // 0: id
"\"TITLE\" TEXT NOT NULL ," + // 1: title
"\"TIME\" TEXT NOT NULL ," + // 2: time
"\"DETAIL_ID\" INTEGER NOT NULL );"); // 3: detailId
}
/** Drops the underlying database table. */
public static void dropTable(SQLiteDatabase db, boolean ifExists) {
String sql = "DROP TABLE " + (ifExists ? "IF EXISTS " : "") + "\"NEWS\"";
db.execSQL(sql);
}
......代码有点多,只贴了部分。
可以看到,它继承自AbstractDao,创建了4个静态数据表字段属性。并且,创建这个表的sql语句也在这里。
可以这么说,我们后面的数据库操作基本都是和Dao类做交互。它的这些业务代码都在它的父类里。
如下所示,就是基本的增、删、改、查,当然它的接口还有很多,我只是贴了最具代表的。
public long insert(T entity)
public void delete(T entity)
public void update(T entity)
public QueryBuilder queryBuilder() 最后,就是实体类,代码就不贴了。它除了提供一些setter和getter的方法外,还提供了update,delete,refresh,其内部会去调用Dao类。
然后在News这个类里,可以看到它还提供了一个
public List。这个是在java工程里News和Opinion建立“一对多”关系时产生的。
实例
在之前,我们已经创建了一个Android工程。现在需要给这个工程添加greendao库。
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.android.support:appcompat-v7:23.0.1'
compile 'com.android.support:support-v4:23.0.1'
compile 'de.greenrobot:greendao:2.0.0'
}support-v4此应用也需要,因为要用到fragment。
基于上面的分析,要创建一个数据库,首先,你得创建一个DaoMaster。因为它只要创建一次,所以你可以考虑把它放到一个单例类里。
我选择把它放在Application里。
public DaoMaster getDaoMaster() {
if (mDaoMaster == null) {
DaoMaster.DevOpenHelper helper = new DaoMaster.DevOpenHelper(this, "news.db", null);
mDaoMaster = new DaoMaster(helper.getWritableDatabase());
}
return mDaoMaster;
}
public DaoSession getDaoSession() {
if (mDaoSession == null) {
if (mDaoMaster == null) {
mDaoMaster = getDaoMaster();
}
mDaoSession = mDaoMaster.newSession();
}
return mDaoSession;
}为啥放在Application,我基于两个考虑:
1.Application也算是一个单例类
2.Application的Context是一直存在的。
然后,在主体activity获取DaoMaster对象和DaoSession对象。此时,数据库就创建完成了。
主体activity在获取到DaoSession之后,又可以获取到相应的Dao类。ok,至此,准备工作已经完成。
@Override
protected void onCreate(Bundle savedInstanceState) {
initDao();
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mFragmentManager = getSupportFragmentManager();
if (savedInstanceState == null) {
mNewsListFragment = NewsListFragment.newInstance();
FragmentTransaction transaction = mFragmentManager.beginTransaction();
transaction.replace(R.id.container, mNewsListFragment);
transaction.commit();
}
}
private void initDao() {
mDaoMaster = ((AppApplication) getApplication()).getDaoMaster();
mDaoSession = ((AppApplication) getApplication()).getDaoSession();
mNewsDao = mDaoSession.getNewsDao();
mDetailDao = mDaoSession.getDetailDao();
mOpinionDao = mDaoSession.getOpinionDao();
}上面是主体activity的初始化。可以看到,我把initDao放在了super.onCreate(savedInstanceState)前面。这是为啥呢?
上面我有提过,使用的是fragment,所以在横竖屏切换的时候,会在super.onCreate里重新创建原先存在的fragment。然后fragment提取数据会用到数据库,所以,数据库初始化就放到super.onCreate前面了。
插入
我们先来看看GreenDao的插入。
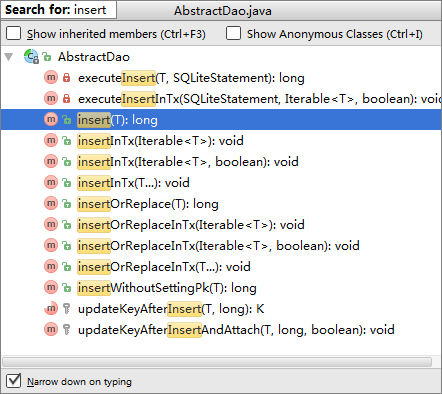
可以看到,有很多api可以使用。
insert是插入一个,insertInTx是插入多个,“Tx”表示用一个事务去控制整个过程(提高效率)。
insertOrReplace是插入或替换。
api都很清晰,这里的T指的就是实体类。对于单个插入,返回值是它的_id值。
所以对于我们的新闻应用,要插入一条新闻,就需要操作两个表,对应两个实体对象:News和Detail。
@Override
public boolean onOptionsItemSelected(MenuItem item) {
int id = item.getItemId();
//noinspection SimplifiableIfStatement
if (id == R.id.action_add) {
// 添加一条新新闻
addANews();
mNewsListFragment.listUpdate(getNewsFromDb());
return true;
}
return super.onOptionsItemSelected(item);
}
private void addANews() {
String[] content = CreateNewsUtil.createOneNews();
long detailId = mDetailDao.insert(new Detail(null, content[3], content[2]));
mNewsDao.insert(new News(null, content[0], content[1], detailId));
}这里,需要先插入一个Detail,因为News里有个字段是外键,关联到Detail,所以需要先获取Detail的id。
再来看评价的插入。News和Opinion的关系是“一对多”的关系。
Opinion里包含一个News的id外键。所以创建的一个Opinion实体时需要当前News的id。
然后他的插入有个特点。
@Override
public void addOpinionToDB(Opinion opinion) {
News news = mNewsDao.load(opinion.getNewsId());
List opinions = news.getOpinions();
opinions.add(opinion);
mOpinionDao.insert(opinion);
} 可以看到,我是先获取当前News的Opinion list,然后往里添加了当前的Opinion对象,最后再把当前的Opinion插入到数据库。
这里涉及到Greendao的数据缓存机制。对于“一对多”To Many这种关系,它在首次获取列表信息时是去访问数据库的数据,并将这些数据缓存起来,之后就不去访问数据库信息,直接从缓存获取。
public List _queryNews_Opinions(long newsId) {
synchronized (this) {
if (news_OpinionsQuery == null) {
QueryBuilder queryBuilder = queryBuilder();
queryBuilder.where(Properties.NewsId.eq(null));
queryBuilder.orderRaw("T.'TIME' ASC");
news_OpinionsQuery = queryBuilder.build();
}
}
Query query = news_OpinionsQuery.forCurrentThread();
query.setParameter(0, newsId);
return query.list();
} 如上代码,第一次获取时,news_OpinionsQuery为空,然后会调用queryBuilder.build()进行数据库查询。这之后,就直接获取缓存的query。
所以说,在针对To Many时,除了插入数据库,还需要添加到缓存列表里。
这也是GreenDao之所以快的原因。
删除
接着来讲讲删除。
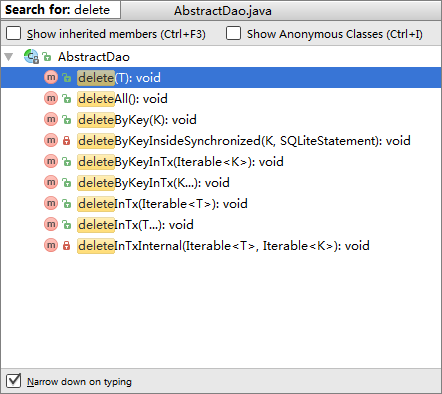
删除的api同样也挺多,也很清晰,就不展开讲了。
对于我的新闻应用,删除很简单,就是删除长按的那条新闻,包括它对应的详细信息和评价。
@Override
public void deleteOneNews(News news) {
mDetailDao.delete(news.getDetail());
List opinions = news.getOpinions();
// for (int i = 0; i < opinions.size(); i++) {
// mOpinionDao.delete(opinions.get(i));
// }
mOpinionDao.deleteInTx(opinions);
mNewsDao.delete(news);
mHandler.postDelayed(new Runnable() {
@Override
public void run() {
mNewsListFragment.listUpdate(getNewsFromDb());
}
}, 1000);
} 这里需要注意的是,别用我注释掉的那种方式去删除评价。因为如果你这样去做,每次删除,都会建立一个事务,这样明显是不明智的选择。所以,针对集合类对象的处理,最好选择带”Tx”的方法。
更改
按照惯例,我先贴出相关api看看:
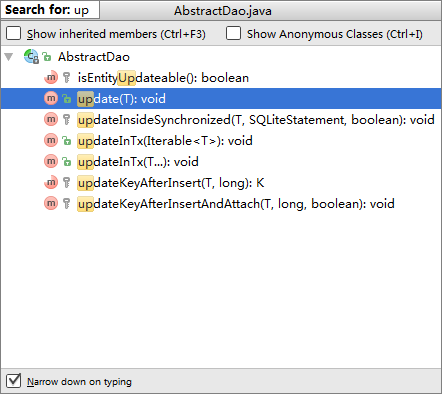
看看就行~不讲了。
还是讲讲我的小新闻应用。这里更新,是更新一则新闻的标题、时间、摘要和详细内容。
@Override
public void updateNews(News news, Detail detail) {
mNewsDao.update(news);
mDetailDao.update(detail);
mFragmentManager.popBackStackImmediate();
}可以看到,代码异常简单,调用两次update,最后那句是为了从新闻详细界面跳回到新闻列表界面。
查询
说到查询,你不能再去AbstractDao里Ctrl+o去搜索”search”了,因为它玩新花样了。
可以想想,数据库关于查询的方式是挺多的,where、or、and、limit、join、order等等。
如果要设计一个灵活的框架,我总不可能针对每个方式去创建一堆的api。
GreenDao用到了一个QueryBuilder辅助类。它可以很轻松的构建查询语句,而不需要你手动去写那麻烦的查询语句了。因为你纯粹手打sql语句,那是很容易出错滴,关键是编译还不会报错。如果用QueryBuilder,麻麻再也不担心我sql语句写错了,偶也!
我们来看看一些查询示例(取自官网):
List joes = userDao.queryBuilder()
.where(Properties.FirstName.eq("Joe"))
.orderAsc(Properties.LastName)
.list();可以看到,使用so easy,就是不断的去添加条件。这里”eq”代表等于
再来个:
QueryBuilder qb = userDao.queryBuilder();
qb.where(Properties.FirstName.eq("Joe"),
qb.or(Properties.YearOfBirth.gt(1970),
qb.and(Properties.YearOfBirth.eq(1970), Properties.MonthOfBirth.ge(10))));
List youngJoes = qb.list();很简单吧。这里需要说明的是,这些eq,gt,ge…都是维护在每个实体类的属性字段里的。
public class Property {
public final int ordinal;
public final Class type;
public final String name;
public final boolean primaryKey;
public final String columnName;
public Property(int ordinal, Class type, String name, boolean primaryKey, String columnName) {
this.ordinal = ordinal;
this.type = type;
this.name = name;
this.primaryKey = primaryKey;
this.columnName = columnName;
}
/** Creates an "equal ('=')" condition for this property. */
public WhereCondition eq(Object value) {
return new PropertyCondition(this, "=?", value);
}
/** Creates an "not equal ('<>')" condition for this property. */
public WhereCondition notEq(Object value) {
return new PropertyCondition(this, "<>?", value);
}
/** Creates an "LIKE" condition for this property. */
public WhereCondition like(String value) {
return new PropertyCondition(this, " LIKE ?", value);
}
/** Creates an "BETWEEN ... AND ..." condition for this property. */
public WhereCondition between(Object value1, Object value2) {
Object[] values = { value1, value2 };
return new PropertyCondition(this, " BETWEEN ? AND ?", values);
}
/** Creates an "IN (..., ..., ...)" condition for this property. */
public WhereCondition in(Object... inValues) {
StringBuilder condition = new StringBuilder(" IN (");
SqlUtils.appendPlaceholders(condition, inValues.length).append(')');
return new PropertyCondition(this, condition.toString(), inValues);
}
/** Creates an "IN (..., ..., ...)" condition for this property. */
public WhereCondition in(Collection inValues) {
return in(inValues.toArray());
}
/** Creates an "NOT IN (..., ..., ...)" condition for this property. */
public WhereCondition notIn(Object... notInValues) {
StringBuilder condition = new StringBuilder(" NOT IN (");
SqlUtils.appendPlaceholders(condition, notInValues.length).append(')');
return new PropertyCondition(this, condition.toString(), notInValues);
}
/** Creates an "NOT IN (..., ..., ...)" condition for this property. */
public WhereCondition notIn(Collection notInValues) {
return notIn(notInValues.toArray());
}
/** Creates an "greater than ('>')" condition for this property. */
public WhereCondition gt(Object value) {
return new PropertyCondition(this, ">?", value);
}
/** Creates an "less than ('<')" condition for this property. */
public WhereCondition lt(Object value) {
return new PropertyCondition(this, ", value);
}
/** Creates an "greater or equal ('>=')" condition for this property. */
public WhereCondition ge(Object value) {
return new PropertyCondition(this, ">=?", value);
}
/** Creates an "less or equal ('<=')" condition for this property. */
public WhereCondition le(Object value) {
return new PropertyCondition(this, "<=?", value);
}
/** Creates an "IS NULL" condition for this property. */
public WhereCondition isNull() {
return new PropertyCondition(this, " IS NULL");
}
/** Creates an "IS NOT NULL" condition for this property. */
public WhereCondition isNotNull() {
return new PropertyCondition(this, " IS NOT NULL");
}
}这部分代码注释很清晰,忘了可以去查看。
QueryBuilder内部是使用Query类去查询的。这部分东西挺多,我直接贴下官方的文档的翻译:
官方文档
Query 和 LazyList
Query类代表一个可以多次执行的查询。当你使用QueryBuilder之一的方法去获取结果的时候,QueryBuilder内部使用了Query 类。
如果你想运行更多相同的查询,你应该调用build(),去创建Query。
greenDao支持唯一的结果和结果列表。如果你想得到一个唯一的结果,可以调用Query或者QueryBuilder的unique()方法,这样在没有匹配条件的时候会返回一个唯一的结果,而不是null。如果你希望禁止用例中返回null,可以调用uniqueOrThrow(),该方法会保证返回一个非null的实体。否则就会抛出一个DaoException。
如果你期望一次性返回多个实体,可以使用以下方法:
list():所有的实体被加载到内存中。该结果通常是一个没有magic involved的ArrayList。使用起来最简单。
listLazy():实体按照需求加载进入内存。一旦列表中的一个元素被第一次访问,它将被加载同时缓存以便以后使用。必须close。
ListLasyUncached(): 一个“虚拟”的实体列表:任何对列表元素的访问都会导致从数据库中加载,必须close。
listIterator(): 遍历通过需要的时候加载(lazily)获得的结果,数据没有缓存,必须close。
listLazy, listLazyUncached 和 listIterator类使用了greenDao的LazyList类。为了根据需求加载数据,它持有了一个数据库cursor的引用。
这是做是为了确保关闭 lazy list和iterators(通常在try/finally 代码块中)。
一旦有的元素被访问或者遍历过,来自lsitLazy()的cache lazy list和来自listIterator()方法的lazy iterator将会自动关闭cursor。
然而,如果list的处理过早的完成了,你应该调用 close()手动关闭。
多次执行查询
一旦你使用QueryBuilder构建了一个query,该query对象以后可以被重复使用。这种方式比总是重复创建query对象要高效。
如果query的参数没有变更,你只需要再次调用list/unique方法即可。如果有参数变更,你就需要调用setParameter方法处理每一个变更的参数。
现在,个别参数由基于零的参数索引寻址。该下标基于你传递到querybuilder的参数。
看示例:
Query query = userDao.queryBuilder().where(
Properties.FirstName.eq("Joe"), Properties.YearOfBirth.eq(1970))
.build();
List joesOf1970 = query.list();
......
query.setParameter(0, "Maria");
query.setParameter(1, 1977);
List mariasOf1977 = query.list();在多个线程中执行查询
如果你在多线程中使用了查询,你必须调用query的 forCurrentThread()为当前的线程获得一个query实例。从greenDAO 1.3开始,
query的实例化被绑定到了那些创建query的线程身上。这样做保证了query对象设置参数时的安全性,避免其他线程的干扰。如果其他线程
试着在query对象上设置参数或者执行查询绑定到了其它线程,将会抛出异常。这样一来,你就不需要一个同步语句了。
事实上你应该避免使用lock,因为如果在并发的事务中使用了同一个query对象,可能会导致死锁。
为了完全避免那些潜在的死锁问题,greenDAO 1.3 引入了forCurrentThread方法,它会返回一个query对象的thread—local实例,该实例
在当前的线程中使用是安全的。当每一次调用 forCueerntThread()的时候,该参数会在builder构建query的时候,设置到初始化参数上。
原始的查询
这里有两种方式执行原始的SQL去获取实体。较好的一种方式是使用QueryBuilder 和 WhereCondition.StringCondition。
使用这个方法,你可以为 query builder 的 WHERE 子句传递任何SQL片段。
下面是一个笨拙的例子展示如果使用这种方式进行一个替代联合查询的子查询。
Query query = userDao.queryBuilder().where(
new StringCondition("_ID IN " +
"(SELECT USER_ID FROM USER_MESSAGE WHERE READ_FLAG = 0)").build();该示例中query Builder没有提供你需要的特性,你可以回到原始的queryRaw或者queryRawCreate方法。它们允许你传递原始的SQL字符串,这些字符串会被添加到SELECT 和实体列后面。这种方式,你可以拥有一个 WHERE 和 ORDER BY 语句查询实体。这种实体表可以通过别名“T”引用。
下面的例子展示了如何创建一个query:使用联合获取名为“admin”的group的users
Query query = userDao.queryRawCreate( ", GROUP G WHERE G.NAME=? AND T.GROUP_ID=G._ID", "admin"); 提示:
你可以通过生成的常量引用表或者列名。这样建议是为了避免错别字,因为编译器会检验这些名字。在任何实体的DAO,你可以发现 TABLENAME 持有着数据库的名字和一个内部类“Properties”.它的所有属性都是常量。
删除查询
批量删除不删除单独的实体,但所有的实体要匹配一些准则。为了执行批量删除,创建一个QueryBuilder,调用它的buildDelete方法,它会返回一个DeleteQuery。
这部分的API可能会在以后有所变化,比如添加一些更加便利的方法。记住,批量删除现在不会影响到identity scope中的实体。在它们被通过ID访问之前(load 方法)
如果它们被缓存了,你可以激活那些将要被删除的实体。如果导致了一些使用的问题。你可以考虑清除identity scope。
查询故障处理
如果你的query没有返回期望的结果,这里有两个静态的flag,可以开启QueryBuilder身上的SQL和参数的log。
QueryBuilder.LOG_SQL = true;
QueryBuilder.LOG_VALUES = true;它们会在任何build方法调用的时候打印出SQL命令和传入的值。这样你可以对你的期望值进行对比,或许也能够帮助你复制SQL语句到某些
SQLite 数据库的查看器中,执行并获取结果,以便进行比较。
OK,拷贝粘贴完毕~~
关于上面的官网部分内容,大家只要有个概念就行,等到时候真正需要这方面需求的时候,再去深入也不迟,我其实也是很多的不明白。如果不爽,那就去看源码。
接着继续看我的小新闻应用,关于查询,里面用到的很简单:
@Override
public void searchNews(String key) {
List newses = mNewsDao.queryBuilder()
.where(NewsDao.Properties.Title.like("%"+key+"%")).list();
mNewsListFragment.listUpdate(newses);
} 当然你可以添加个order,按照时间排序。
至此,关于GreenDao的核心api:
insert…
delete…
update…
querybuild…
就介绍到这。
如果想看整个工程的代码,请点击:代码入口