转换算子(TransFormation)和执行算子(Action)
目录:
- 一、转换算子(TransFormation)
- 二、执行算子(Action)
一、转换算子(TransFormation)
func:function
- map(func)
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成

- mapPartitions(func)
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T(泛型)的RDD运行时,
func的函数必须是Iterator[T]=>Iterator[U].
假设RDD有N个元素,有M个分区,那么map函数被调用N次,而mapPartitions则被调用M次,一个函数一次处理所有分区
def mappatitions(): Unit = {
val conf = new SparkConf().setAppName("cogroup").setMaster("local[*]")
val sc = new SparkContext(conf)
val a = sc.parallelize(1 to 9, 3)
def doubleFunc(iter: Iterator[Int]): Iterator[Int] = {
var res = List[Int]()
while (iter.hasNext) {
val cur = iter.next;
res.::=((cur * 2))
}
res.iterator
}
val result = a.mapPartitions(doubleFunc)
result.collect().foreach(println)
}
- mapPartitionsWithIndex(func)
类似于mapPartitions,但func带有一个整数表示分片的索引值,因此类型为T的RDD运行时,
func的函数类型必须是(Int,Iterator[T]) => Iterator[U]
def mappatitionswithindex() {
val conf = new SparkConf().setAppName("mappatitionswithindex").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.makeRDD(1 to 10, 2)
val rdd2: RDD[String] = rdd1.mapPartitionsWithIndex((x, iter) => {
var result = List[String]()
result.::=(x + "|" + iter.toList)
result.iterator
})
val res: Array[String] = rdd2.collect()
for (x <- res) {
println(x)
}
}
- glom()
将每一个分区形成一个数组,形成新的RDD类型=>RDD[Array[T]]

- filter(func)
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
// 创建RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5))
// 获得所有的偶数。
val num: RDD[Int] = rdd.filter(aaa => aaa % 2==0 )
num.foreach(line => println(line))
- flatMap(func)
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)

- sample(withReplacement,fraction,seed)
以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。
例如:从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1,2,3的其中一个起始值)

- distinct([numTasks])
对RDD进行去重后返回一个新的RDD。默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
def distinct(): Unit = {
val conf = new SparkConf().setAppName("distinct").setMaster("local[*]")
val sc = new SparkContext(conf)
val distinctRdd = sc.parallelize(List(1, 2, 1, 5, 2, 9, 6, 1))
val res: RDD[Int] = distinctRdd.distinct(2)
// distinct 中的参数numTask 表示 数据先对2整除,其他的依次余1,余2,余3 。局部无序,整体有序。
res.foreach(println)
}
- partitionBy
对RDD进行分区操作,如果原有的partionRDD和现有的partitionRDD是一致的话就不进行分区,否则会生成ShuffleRDD。
def partitonBy2repatition(): Unit = {
val conf = new SparkConf().setAppName("localTest").setMaster("local[4]")
val sc = new SparkContext(conf)
//设置4个分区;
val rdd = sc.parallelize(List("hello", "jason", "what", "are", "you", "doing", "hi", "jason", "do", "you", "eat", "dinner", "hello", "jason", "do", "you", "have", "some", "time", "hello", "jason", "time", "do", "you", "jason", "jason"), 4)
val word_count = rdd.flatMap(_.split(",")).map((_, 1))
//重分区为10个;
val rep = word_count.repartition(10)
rep.foreachPartition(pair => {
println("第几个分区-------------" + TaskContext.get.partitionId)
pair.foreach(p => {
println(p)
})
})
println("************************************************************************************************")
//重分区为10;
val parby = word_count.partitionBy(new HashPartitioner(10))
parby.foreachPartition(pair => {
println("第几个分区-------------" + TaskContext.get.partitionId)
pair.foreach(p => {
println(p)
})
})
}
-
coalesce(numPartitions)
重新分区,第一个参数是要分多少区,第二个参数是否shuffle,默认false(分区多变少),true(分区少变多)

-
repartition(numPartitions)
重新分区,必须shuffle 参数是要分多少区

-
repartitionAndSortWithinPartitions(partitioner)
重新分区+排序,比先分区再排序效率要高 对K/V的RDD进行操作 -
sortBy(func,[ascending],[numTasks])
用func先对数据进行处理,按照处理后的数据比较结果排序。第一个参数是根据什么排序,第二个是怎么排序 false倒序,第三个排序后分区数,默认和原RDD一致

-
union(otherDataset)
对原RDD和参数RDD求并集后返回一个新的RDD(不去重)

-
subtract(otherDataset)
去除两个RDD中相同的元素,不同的存入新的RDD保留下来

-
intersection(otherDataset)
对原RDD和参数RDD求交集后返回一个新的RDD

-
cartesian(otherDataset)
原RDD和参数RDD的笛卡尔积

-
pipe(command,[envVars])
管道(调用外部程序),对于每个分区,都执行一个perl后者shell脚本,返回输出的RDD
Shell脚本pipe.sh:
#!/bin/sh
echo "AA"
while read LINE; do
echo ">>>"${LINE}
Done
----------------------------------------------------
scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),1)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[50] at parallelize at :24
scala> rdd.pipe("/home/bigdata/pipe.sh").collect()
res18: Array[String] = Array(AA, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
scala> val rdd = sc.parallelize(List("hi","Hello","how","are","you"),2)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[52] at parallelize at :24
scala> rdd.pipe("/home/bigdata/pipe.sh").collect()
res19: Array[String] = Array(AA, >>>hi, >>>Hello, AA, >>>how, >>>are, >>>you)
- join(otherDataset,[numTasks])
在类型为(k,v)和(k,w)的RDD上调用,返回一个相同key对应的所有元素对在一起的(k,(v,w))的RDD 相当于内连接(求交集)
def join() {
val conf = new SparkConf()
.setAppName("join")
.setMaster("local")
val sc = new SparkContext(conf)
val studentList = Array(
Tuple2(1, "leo"),
Tuple2(2, "jack"),
Tuple2(3, "tom"));
val scoreList = Array(
Tuple2(1, 100),
Tuple2(2, 90),
Tuple2(3, 60));
val students = sc.parallelize(studentList);
val scores = sc.parallelize(scoreList);
val studentScores = students.join(scores)
studentScores.foreach(studentScore => {
println("student id: " + studentScore._1);
println("student name: " + studentScore._2._1)
println("student socre: " + studentScore._2._2)
println("=======================================")
})
}
def join2(): Unit = {
val conf = new SparkConf()
.setAppName("join2")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val idName = sc.parallelize(Array((1, "zhangsan"), (2, "lisi"), (3, "wangwu")))
val idAge = sc.parallelize(Array((1, 30), (2, 29), (4, 21)))
//idName.join(idAge).collect().foreach(println)
//val result: RDD[(Int, (String, Int))] = idName.join(idAge)
//左外连接 idName.leftOuterJoin(idAge).collect().foreach(println)
//右外连接 idName.rightOuterJoin(idAge).collect().foreach(println)
//全连接
idName.fullOuterJoin(idAge).collect().foreach(println)
// result.collect().foreach(res => {
// println("学生ID"+res._1)
// println("学生姓名:"+res._2._1)
// println("学生成绩:"+res._2._2)
// println("=============================================")
// })
}
- cogroup(otherDataset,[numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterator,Iterator))类型的RDD
def cogroup(): Unit = {
val conf = new SparkConf()
.setAppName("cogroup")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val idName = sc.parallelize(Array((1, "zhangsan"), (2, "lisi")))
val idScore = sc.parallelize(Array((1, 100), (2, 90), (2, 95)))
idName.cogroup(idScore).foreach(
res => {
println("id\t" + res._1)
println("name\t" + res._2._1)
println("score\t" + res._2._2)
println("=============================")
}
)
}
- reduceByKey(func,[numTasks])
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置
def reduceByKey(): Unit ={
val conf = new SparkConf().setAppName("cogroup").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List(("jack",1),("tom",5),("jack",5),("tom",6),("jack",7)))
val result: Array[(String, Int)] = rdd.reduceByKey((x,y)=>(x+y)).collect()
for((x:String,y:Int) <- result){
println(x+" "+y)
}
}
- groupByKey([numTasks])
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
def groupByKey(): Unit ={
val conf = new SparkConf() .setAppName("groupByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List(("jack",1),("tom",5),("jack",5),("tom",6),("jack",7)))
rdd.groupByKey().collect().foreach(x=>{
println("姓名:"+x._1+" 分数"+x._2)
})
rdd.groupByKey().map(x=>{
val name = x._1
var sum = 0
for(y<- x._2 ){
sum += y
}
(name,sum)
}).collect().foreach(println)
}
- combineByKey(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
对相同的Key,把Value合并成一个集合返回。
参数说明:
createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就 和之前的某个元素的键相同。如果这是一个新的元素,combineByKey() 会使用一个叫作 createCombiner() 的函数来创建
那个键对应的累加器的初始值
mergeValue: 如果这是一个在处理当前分区之前已经遇到的键, 它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并
mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
def combineByKey(): Unit ={
val conf = new SparkConf().setAppName("combinerByKey").setMaster("local[*]")
val sc = new SparkContext(conf)
// 求出每个字母的平均值。
/*
createCombiner: V => C, 创建一个合并对象。a:(90,1)
mergeValue: (C, V) => C, a(170,2) 区内合并
mergeCombiners: (C, C) => C, a(76 1) a(246,3) 全区合并。
*/
val rdd1: RDD[(String, Int)] = sc.makeRDD(Array(("a",90),("a",80),("b",46),("b",58),("b",29),("c",58),("c",90),("d",91),("a",76)))
val rdd3: RDD[(String, (Int, Int))] = rdd1.combineByKey(
v => (v, 1), // (90,1)
(c: (Int, Int), v) => (c._1 + v, c._2 + 1),
(c1: (Int, Int), c2: (Int, Int)) => (c1._1 + c2._1, c1._2 + c2._2)
)
//rdd3.map(x=>(x._1+"平均值"+(x._2._1/x._2._2))).collect().foreach(println)
rdd3.map{case(x:String,(y:Int,z:Int))=>(x,(y/z))}.collect().foreach(println)
- aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(+,+) 对k/y的RDD进行操作

- foldByKey(zeroValue)(seqOp)
该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:+

- sortByKey([ascending], [numTasks])
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD

- mapValues
针对于(K,V)形式的类型只对V进行操作

二、执行算子(Action)
- reduce(func)
reduce将RDD中元素两两传递给输入函数,同时产生一个新值,新值与RDD中下一个元素再被传递给输入函数,直到最后只有一个值为止。(通过func函数聚集RDD中的所有元素)

- collect()
将一个RDD以一个Array数组形式返回其中的所有元素。

- count()
返回数据集中元素个数,默认Long类型。

- first()
返回数据集的第一个元素(类似于take(1))

- take(n)
返回一个包含数据集前n个元素的数组(从0下标到n-1下标的元素),不排序。

- takeSample(withReplacement, num, [seed])
对于一个数据集进行随机抽样,返回一个包含num个随机抽样元素的数组,withReplacement表示是否有放回抽样,参数seed指定生成随机数的种子。
该方法仅在预期结果数组很小的情况下使用,因为所有数据都被加载到driver端的内存中。

7. takeOrdered(n,[ordering])
返回RDD中前n个元素,并按默认顺序排序(升序)或者按自定义比较器顺序排序。

8. aggregate (zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。

9. fold(num)(func)
折叠操作,aggregate的简化操作,seqop和combop一样。

10. saveAsTextFile(path)
将dataSet中元素以文本文件的形式写入本地文件系统或者HDFS等。Spark将对每个元素调用toString方法,将数据元素转换为文本文件中的一行记录。
若将文件保存到本地文件系统,那么只会保存在executor所在机器的本地目录。


11. saveAsSequenceFile(path)
将dataSet中元素以Hadoop SequenceFile的形式写入本地文件系统或者HDFS等。(对pairRDD操作)
算子使用和saveAsTextFile(path)一致。
-
saveAsObjectFile(path)
将数据集中元素以ObjectFile形式写入本地文件系统或者HDFS等。
算子使用和saveAsTextFile(path)一致。 -
countByKey()
用于统计RDD[K,V]中每个K的数量,返回具有每个key的计数的(k,int)pairs的hashMap。
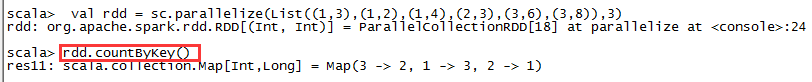
-
foreach(func)
对数据集中每一个元素运行函数function。
