Pytorch入门笔记
从这一篇博客开始,自己准备了解并且记录一些pytorch的内容。以下记录的可能不是很连贯,主要作为自己温习的笔记。
Pytorch的官方入门文档,本文记录了自己学习文档的内容。这是中文翻译的文档,很多地方可能词不达意,但是可以作为参考。这篇中文文档也不错。
tutorial
Neural Networks
本节介绍了一个类似ALEXNET的网络结构,来说明如何利用torch搭建一个NN。图如下:

可以看到输入是图片,1*32*32,然后连接2个卷积层池化层,然后链接3个全连接层,实现代码如下:代码中的一些函数的细节可以参看我下面对torch.NN的介绍。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 去掉batchsize,然后把所有维度拉展。
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的后保留其他所有维度, 若x是[4,5,6], 则x.size()[1:]为[5,6]
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
结果如下:
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
我们只需要定义 forward 函数,backward函数会在使用autograd时自动定义,backward函数用来计算导数(这一块可以去官方文档查阅)。我们可以在 forward 函数中使用任何针对张量的操作和计算。
一个模型的可学习参数可以通过net.parameters()返回
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
输出:
10
torch.Size([6, 1, 5, 5])
10的含义是,我们定义了2个卷积层和3个全连接层,每层都有偏置,所以自然是10了。
让我们尝试一个随机的32x32的输入。注意:这个网络(LeNet)的期待输入是32x32的张量。如果使用MNIST数据集来训练这个网络,要把图片大小重新调整到32x32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
输出:
tensor([[ 0.0399, -0.0856, 0.0668, 0.0915, 0.0453, -0.0680, -0.1024, 0.0493,
-0.1043, -0.1267]], grad_fn=<AddmmBackward>)
这里有一个问题,为什么是32*32呢?其它的不行吗?比如64*64,答案是不行的。因为我们在代码forward中已经限制死了,即在全连接fc1之前,写明了:
self.fc1 = nn.Linear(16 * 5 * 5, 120)
即必须保证池化层之后,flat向量是400,即16 * 5 * 5。我们可以结合NN的图看的更明白。如果我们使用了其它尺寸,如64*64,那么在经过我们定义好的卷积和池化后,大小就不再是
16 * 5 * 5了。当然,pytorch代码不会这么死板,我们当然可以定义灵活的维度,有机会再补充。
注意:
torch.nn只支持小批量处理(mini-batches)。整个torch.nn包只支持小批量样本的输入,不支持单个样本的输入。
比如,nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width
如果是一个单独的样本,只需要使用input.unsqueeze(0)来添加一个“假的”批大小维度。
Training a Classifier
参考TRAINING A CLASSIFIER
通常来说,当必须处理图像、文本、音频或视频数据时,可以使用python标准库将数据加载到numpy数组里, 然后将这个数组转化成torch.*Tensor。
对于图片,有Pillow,OpenCV等包可以使用
对于音频,有scipy和librosa等包可以使用
对于文本,不管是原生python的或者是基于Cython的文本,可以使用NLTK和SpaCy
特别对于视觉方面,我们创建了一个包,名字叫torchvision,其中包含了针对Imagenet、CIFAR10、MNIST等常用数据集的数据加载器(data loaders),还有对图像数据转换的操作,即torchvision.datasets和torch.utils.data.DataLoader。
这提供了极大的便利,可以避免编写样板代码。
在这个教程中,我们将使用CIFAR10数据集,它有如下的分类:“飞机”,“汽车”,“鸟”,“猫”,“鹿”,“狗”,“青蛙”,“马”,“船”,“卡车”等。在CIFAR-10里面的图片数据大小是3x32x32,即:三通道彩色图像,图像大小是32x32像素。
以下是一个完整的读取数据,处理,训练和测试的例子。
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 14 09:56:32 2020
@author: anshuai1
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度, 若x是[4,5,6], 则x.size()[1:]为[5,6]
num_features = 1
for s in size:
num_features *= s
return num_features
########################################################################################################
# 1.加载并标准化CIFAR10
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0) # 一次读4个图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 输出图像的函数
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 随机获取训练图片
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 显示图片
imshow(torchvision.utils.make_grid(images))
# 打印图片标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
########################################################################################################
# 2. 定义一个卷积神经网络
net = Net()
########################################################################################################
# 3.定义损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
########################################################################################################
# 4.训练网络
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
########################################################################################################
#5.使用测试数据测试网络
dataiter = iter(testloader)
images, labels = dataiter.next()
# 输出图片
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# 加载保存的模型
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
# 网络在整个数据集上表现的怎么样
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
# 哪些是表现好的类呢?哪些是表现的差的类呢?
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
代码中有几处需要注意的:
1、在训练阶段:先loss.backward()后optimizer.step(),为什么这么做呢。可以参考Pytorch optimizer.step() 和loss.backward()和scheduler.step()的关系与区别 (Pytorch 代码讲解)
2、更多模型保存的细节可以参看SERIALIZATION SEMANTICS
torch.NN
Convolution layers
Conv2d
卷积操作需要先了解,具体可参考博文。
在torch中的Conv2d有一些参数可能不是很熟悉,其实都是一些已有的概念。我们这里讲解下Conv2d,nn.Conv2d是二维卷积方法,相对应的还有一维卷积方法nn.Conv1d,常用于文本数据的处理,而nn.Conv2d一般用于二维图像。参考文献【1】是官方文档,接口如下:
class torch.nn.Conv2d(in_channels,
out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=True)
参数解释:

channels这个概念其实在各种框架中常见,意思就是通道数,一般的RGB图片,channels 数量是 3 (红、绿、蓝);而monochrome图片,channels 数量是 1。 如果从这个图中,我们就更容易明白:一般 channels 的含义是,每个卷积层中卷积核的数量。 因此,in_channels和out_channels的意思我们就明白了。如果仍不明白,参考文献【2】说的很清楚。
kernel size: 就是卷积核的大小,可以是int或者是tuple,即可以是3,或者是(3,5)
stride: 步长
padding和padding_mode:比较简单
dilation:控制 kernel 点之间的空间距离。这个看着定义有点抽象,看下面的图就理解了
groups: 分组卷积,意思是将对应的输入通道与输出通道数进行分组, 默认值为1, 也就是说默认输出输入的所有通道各为一组。
比如输入数据大小为90x100x100x32,通道数32,要经过一个3x3x48的卷积,group默认是1,就是全连接的卷积层。
如果group是2,那么对应要将输入的32个通道分成2个16的通道,将输出的48个通道分成2个24的通道。对输出的2个24的通道,第一个24通道与输入的第一个16通道进行全卷积,第二个24通道与输入的第二个16通道进行全卷积。
极端情况下,输入输出通道数相同,比如为24,group大小也为24,那么每个输出卷积核,只与输入的对应的通道进行卷积
到这里,参数就已经介绍完毕了。
在官方文档中,还介绍了尺寸计算的方式。如果我们已经完全理解了参数的含义,下面的公式也是显而易见的:

N N N是样本数, C i n C_{in} Cin是通道数, H i n H_{in} Hin是像素高度, W i n W_{in} Win是像素宽度。
Linear layers
Linear
接口如下:
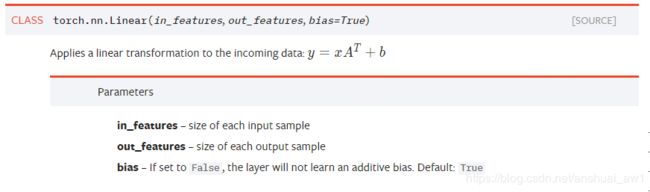
代码说明一下:
import torch
x = torch.randn(128, 20) # 输入的维度是(128,20)
m = torch.nn.Linear(20, 30) # 20,30是指维度
output = m(x)
print('m.weight.shape:\n ', m.weight.shape)
print('m.bias.shape:\n', m.bias.shape)
print('output.shape:\n', output.shape)
# ans = torch.mm(input,torch.t(m.weight))+m.bias 等价于下面的
ans = torch.mm(x, m.weight.t()) + m.bias
print('ans.shape:\n', ans.shape)
print(torch.equal(ans, output))
结果:
m.weight.shape:
torch.Size([30, 20])
m.bias.shape:
torch.Size([30])
output.shape:
torch.Size([128, 30])
ans.shape:
torch.Size([128, 30])
True
权重的大小是30*20,即下一层的神经元的个数在前,上一层的在后。只是约定而已。
参考文献
【1】https://pytorch.org/docs/stable/nn.html#convolution-layers
【2】从零学习PyTorch nn.Conv2d的参数用法 channel含义详解
Tensor Views
在pytorch中view函数的作用为重构张量的维度,相当于numpy中resize()的功能,但是用法可能不太一样。如下例所示
>>> import torch
>>> tt1=torch.tensor([-0.3623, -0.6115, 0.7283, 0.4699, 2.3261, 0.1599])
>>> result=tt1.view(3,2)
>>> result
tensor([[-0.3623, -0.6115],
[ 0.7283, 0.4699],
[ 2.3261, 0.1599]])
1 torch.view(参数a,参数b,…)
在上面例子中参数a=3和参数b=2决定了将一维的tt1重构成3x2维的张量。
2 有的时候会出现torch.view(-1)或者torch.view(参数a,-1)这种情况。
>>> import torch
>>> tt2=torch.tensor([[-0.3623, -0.6115],
... [ 0.7283, 0.4699],
... [ 2.3261, 0.1599]])
>>> result=tt2.view(-1)
>>> result
tensor([-0.3623, -0.6115, 0.7283, 0.4699, 2.3261, 0.1599])
由上面的案例可以看到,如果是torch.view(-1),则原张量会变成一维的结构。
>>> import torch
>>> tt3=torch.tensor([[-0.3623, -0.6115],
... [ 0.7283, 0.4699],
... [ 2.3261, 0.1599]])
>>> result=tt3.view(2,-1)
>>> result
tensor([[-0.3623, -0.6115, 0.7283],
[ 0.4699, 2.3261, 0.1599]])
由上面的案例可以看到,如果是torch.view(参数a,-1),则表示在参数b未知,参数a已知的情况下自动补齐列向量长度,在这个例子中a=2,tt3总共由6个元素,则b=6/2=3。
参考文献
【1】https://pytorch.org/docs/stable/tensors.html#torch.Tensor.view
【2】Pytorch-view的用法
torchVision
torchvision.transforms
Compose
为了方便进行数据的操作,pytorch团队提供了一个torchvision.transforms包,我们可以用transforms进行以下操作:
- PIL.Image/numpy.ndarray与Tensor的相互转化;
- 归一化;
- 对PIL.Image进行裁剪、缩放等操作。
通常,在使用torchvision.transforms,我们通常使用transforms.Compose将transforms组合在一起。
具体的可以参考【pytorch】图像基本操作 和TORCHVISION.TRANSFORMS ,Pytorch之深入torchvision.transforms.ToTensor与ToPILImage这3篇文档。
我们这里简单说下功能2:归一化
归一化对神经网络的训练是非常重要的,那么我们如何归一化到[-1.0, -1.0]呢?只需要:
transform2 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5))
]
)
transforms.ToTensor()将数据转化为[0,1],再利用transforms.Normalize使用如下公式进行归一化:
channel=(channel-mean)/std
即可归一化到[-1,1]