sparkCore之sparkRDD常用算子
前言: sparkRDD的操作,从宏观上分为:Transformation和Action,但是具体的还以分为:输入算子、变换算子、缓存算子,以及行动算子。
官网地址:
https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
一、Transformation
先来官网的常用Transformation算子的截图:
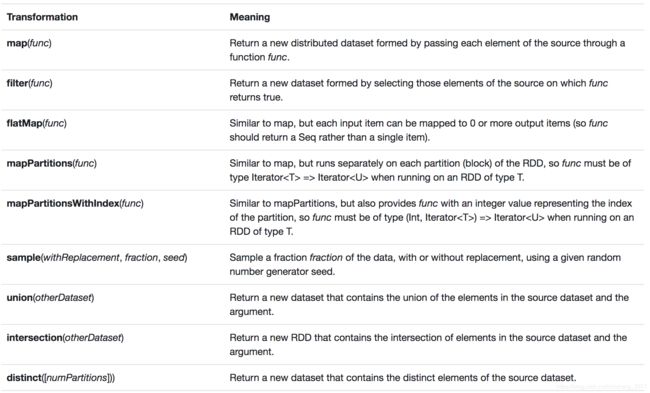
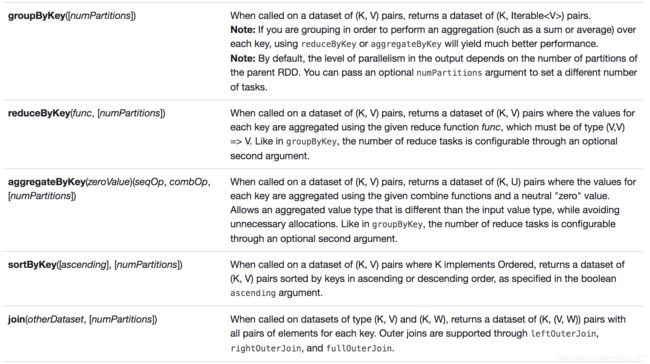

下面呢,咱们也来列举几个常用的Transformation算子
1、flatMap
flatMap是Spark RDD中的转换算子,对RDD中的每一个元素都执行,前后元素的对应关系是OneToMany。也就是说,对一个元素执行RDD的操作,可以产生多个元素。
:
/**
* 主要作用就是做拆分
* one2many
* 将字符串进行单词的拆分
*/
def flatMapOps: Unit = {
val conf = new SparkConf()
.setAppName("SparkFlatmap")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(
"yao xin xin",
"zhang zha ping"
)
val listRDD = sc.parallelize(list)
val wordsRDD = listRDD.flatMap(line => line.split("\\s+"))
wordsRDD.foreach(println)
sc.stop()
}
2、map
map是Spark RDD中的转换算子,对RDD中的每一个元素都执行,前后元素的对应关系是OneToOne。也就是说,对一个元素执行RDD的操作,可以产生一个元素。
:
/**
* 将集合中的每一个元素*7
*/
def mapOps(): Unit = {
val conf = new SparkConf()
.setAppName("SparkMap")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = 1 to 7
val listRDD = sc.parallelize(list)
val retRDD = listRDD.map(_ * 7)
retRDD.foreach(println)
}
3、filter
对RDD中的每一个元素执行对应的func函数,保留该func函数返回值为true的元素,组成一个新的RDD,过滤掉返回值为false的元素。
:
//通过filter算子将list中以0结尾的学生筛选出来
def filterOps(): Unit ={
val conf = new SparkConf()
.setAppName("SparkFilter")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val stuList = List(
"1 zhangsan 18 0",
"2 lisi 28 1",
"3 wangwu 16 0",
"4 xiaobai 23 1"
)
val stuRDD:RDD[String] = sc.parallelize(stuList)
stuRDD.filter(_.endsWith("0")).foreach(println)
}
4、sample
sample是Spark中的抽样算子,从RDD中抽取一定比例的数据,接收三个参数:
withReplacement: Boolean, true有放回的抽样, false无放回的抽样
fraction:Double,样本空间大小,占总大小的比例的分数的表现形式,20%->0.2
seed: Long ,抽样过程中的随机数种子。
注意:该抽样算子sample是非准确式的抽样,比如加入rdd中有1000个记录,抽取0.2的数据,按理结果应该有200个,真实结果可能会在200上下左右浮动。
sample算子的作用就是,对整体空间做一个大概的预估,key或者数据的分布情况,在解决数据倾斜的时候有着非常重要的角色。
:
def sampleOps(): Unit ={
val conf = new SparkConf()
.setAppName("SparkSample")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val numList = 1 to 1000
val numRDD = sc.parallelize(numList)
numRDD.sample(false,0.2).foreach(println)
}
5、union
在spark中的union操作,作用和DB中的union all的作用相同,不会去重。
union:返回两张表中去重之后的结果
union all:返回两张表的所有结果。
:
def unionOps(): Unit ={
val conf = new SparkConf()
.setAppName("SparkUnion")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list1 = 1 to 10
val list2 = 8 to 15
val rdd1 = sc.parallelize(list1)
val rdd2 = sc.parallelize(list2)
val unionRDD = rdd1.union(rdd2)
unionRDD.foreach(println)
}
这个上张结果图大家看看吧:

6、join
join是表的关联操作,这里的表示泛化的概念,只要是数据集都可以理解为表。
那么join有哪些操作呢?
交叉连接:across join 写sql的时候有表的关联,但是没有on的连接字段,这会造成笛卡尔积。
select a.* , b.* from A a across join B b
内连接: inner(通常可省略) join,又被称为等值连接,返回左右表中都有的内容。
select a.* , b.* from A a inner join B b on a.id = b.aid;
select a.* , b.* from A a, B b where a.id = b.aid;
外连接 outer join 非等值连接
左外连接:left outer join 返回左表所有数据,右表没有显示为null
select a.* , b.* from A a left outer join B b on a.id = b.aid;
右外连接: right outer join返回右表所有数据,左表没有显示为null
select a.* , b.* from A a right outer join B b on a.id = b.aid;
半连接 semi join
全连接 full outer join 全连接: left outer join + right outer join
说明:经过内连接join操作之后的数据是确定的。外连接操作之的数据是确定的吗?不确定,有可能有,有可能没有,所以数据类型是-----Option。
:
/**
* stu表
* id name age class
* 成绩表
* id sid course score
*
* 查询有成绩的学生的所有的信息-->inner
* select
s.*, s1.*
from stu s
inner join score s1 on s.id = s1.sid
* 查询所有学生的成绩
* select
* s.*, s1.*
* from stu s
* left join s1 on on s.id = s1.sid
* 所有的join操作,必须要求的RDD的类型时
* K就是关联字段
*/
def joinOps(): Unit ={
val conf = new SparkConf()
.setAppName("SparkJoin")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val stu = List(
"1 zhangsan 22 bj",
"2 lisi 25 bj",
"3 wangwu 24 sz",
"4 liliu 18 wh"
)
val scores = List(
"1 1 math 82",
"2 1 english 0",
"3 2 chinese 85.5",
"4 3 PE 99",
"5 10 math 99"
)
val stuRDD = sc.parallelize(stu)
val scoresRDD = sc.parallelize(scores)
//查询所有学生的信息
val sid2StuInfoRDD:RDD[(String,String)] = stuRDD.map(stuLine =>{
val sid = stuLine.substring(0,1)
val stuInfo = stuLine.substring(1).trim
(sid,stuInfo)
})
val sid2ScoreInfo:RDD[(String,String)] = scoresRDD.map(scoreLine =>{
val fields = scoreLine.split("\\s+")
val sid = fields(1)
val scoreInfo = fields(2)+" "+fields(3)
(sid,scoreInfo)
})
val joinedRDD:RDD[(String, (String, String))] = sid2StuInfoRDD.join(sid2ScoreInfo)
joinedRDD.foreach(println)
println("-------------------------------------------")
joinedRDD.foreach{case (sid,(stuInfo,scoreInfo)) =>{
println(s"sid:${sid}\tstuInfo:${stuInfo}\tscoreInfo:${scoreInfo}")
}
}
println("-------------------------------------------")
val leftJoined:RDD[(String, (String, Option[String]))] = sid2StuInfoRDD.leftOuterJoin(sid2ScoreInfo)
leftJoined.foreach{case (sid, (stuInfo, option)) => {
println(s"sid:${sid}\tstuInfo:${stuInfo}\tscoreInfo:${option.getOrElse(null)}")
}}
}
7、groupByKey
对rdd中的数据按照key进行分组,首先必须要有key,rdd的数据类型就必须是(K, V),经过分组之后相同的key的数据拉取到一起,组成了一个集合。
(K, V).groupByKey() --> (K, Iterable[V])
不建议使用这个groupByKey,可以使用reduceByKey或者aggregateByKey来代替groupByKey。因为性能差,没有本地combiner。
:
def groupByKeyOps(): Unit ={
val conf = new SparkConf()
.setAppName("Sparkgbk")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val stu = List(
"1 zhangsan 22 class-bj",
"2 lisi 25 class-bj",
"3 zhangsi 24 class-sz",
"4 wangwu 18 class-wh",
"5 zhoujielun 18 class-wh",
"4 zhangxixi 18 class-sz"
)
val stuRDD:RDD[String] = sc.parallelize(stu)
val class2Info:RDD[(String, String)] = stuRDD.map(stuLine => {
val clazz = stuLine.substring(stuLine.indexOf("class"))
val info = stuLine.substring(0, stuLine.indexOf("class")).trim
(clazz, info)
})
val gbkRDD:RDD[(String, Iterable[String])] = class2Info.groupByKey()
gbkRDD.foreach{case (clazz, info) => {
println(s"${clazz}--->${info}")
}
}
println("-----------------------------------------")
//ClassTag是类型的标记接口
val gbRDD:RDD[(String, Iterable[String])] = stuRDD.groupBy(stuLine => stuLine.substring(stuLine.indexOf("class")))(
ClassTag.Object.asInstanceOf[ClassTag[String]]
)
gbRDD.foreach{case (clazz, info) => {
println(s"${clazz} ===> ${info}")
}}
}
8、reduceByKey
按照key执行reduce操作,也要求数据类型(K, V) —> (K, V)
:
def rbkOps(): Unit = {
val conf = new SparkConf()
.setAppName("Sparkrbk")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(
"zhang san san",
"zhao zhao ling"
)
val listRDD = sc.parallelize(list)
val wordsRDD = listRDD.flatMap(line => line.split("\\s+"))
val pairsRDD:RDD[(String, Int)]= wordsRDD.map((_, 1))
val rbkRDD:RDD[(String, Int)] = pairsRDD.reduceByKey(_+_)
rbkRDD.foreach(println)
}
9、distinct
去重,即sql中的关键字distinct。
:
def distinctOps(): Unit = {
val conf = new SparkConf()
.setAppName("SparkDistinct")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(
"张三",
"张三",
"张三",
"张三"
)
val listRDD:RDD[String] = sc.parallelize(list)
//numPartitions:在去重的时候指定几个分区-->task,也就是说同时运行几个task来进行去重
listRDD.distinct(4).foreach(println)
}
10、combineByKey(很重要)
reduceByKey和groupByKey底层都是通过combineByKeyWithClassTag来实现的,有一个简写方式combineByKey。
意为按照key进行聚合combine操作,聚合操作有很多,groupBy、reduceBy、count等等。
自定义的combineByKey。通过学习combineBykey模拟reduceByKey和groupByKey来理解什么是分布式计算。
10.1combineByKey模拟reduceByKey
:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
object CombineByKey2ReduceBykey {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("cbk2rb")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(
"hello you hello me",
"hello you hello me",
"me an you"
)
val listRDD = sc.parallelize(list)
val pairRDD:RDD[(String,Int)] =
listRDD.flatMap(_.split("\\s+")).map((_,1))
//
println("------------传统rbk操作--------------")
pairRDD.reduceByKey(_+_).foreach(println)
println("------------combineByKey模拟rbk操作--------------")
pairRDD.combineByKey(createCombiner,mergeValue,mergeCombiners).foreach(println)
//初始化聚合的结果类型
def createCombiner(value: Int): Int ={
value
}
//分区内的聚合操作(map端的操作)
def mergeValue(sum: Int,value: Int): Int ={
sum + value
}
//分区间的聚合操作(reduce端的操作)
def mergeCombiners(sum1:Int,sum2:Int): Int ={
sum1+sum2
}
}
}
10.2combineByKey模拟groupByKey
:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.mutable.ArrayBuffer
object CombineByKey2GroupByKeyOps {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("cbk2gbk")
.setMaster("local[2]")
val sc = new SparkContext(conf)
val stu = List(
"1 zhangsan 22 bd-bj",
"2 lisi 25 bd-bj",
"8 wangwu 24 bd-sz",
"3 zhangyaoshi 24 bd-sz",
"4 hudada 18 bd-wh",
"6 chenpingan 25 bd-bj",
"7 zhaoguang 25 bd-bj",
"5 zhaoyun 18 bd-wh",
"4 zhangfei 18 bd-sz"
)
//按照班级进行分组-->sql中的groupBy
val stuRDD=sc.parallelize(stu)
val class2Info:RDD[(String,String)]=stuRDD.map(stuLine =>{
val clazz = stuLine.substring(stuLine.indexOf("bd"))
(clazz,stuLine)
})
//class2Info.saveAsTextFile("file:///Users/wangjinqi/Desktop/out")
val gbkRDD:RDD[(String,Iterable[String])]=class2Info.groupByKey()
println("---------传统的gbk操作---------")
gbkRDD.foreach{case(clazz,info)=>{
println(s"${clazz}--->${info}")
}
}
println("-------combineByKey模拟gbk操作----------")
class2Info.combineByKey(
(info:String) => createCombiner(info),
(buffer:ArrayBuffer[String], info:String) => mergeValue(buffer, info),
(buffer1:ArrayBuffer[String], buffer2:ArrayBuffer[String]) => mergeCombiners(buffer1, buffer2)
).foreach(println)
sc.stop()
}
/*
初始化操作,确定聚合操作之后的结果类型
在每一个分区内相同的key,需要调用一次该操作,并将其中的一个元素用于初始化操作
*/
def createCombiner(info:String):ArrayBuffer[String] ={
println("createCobiner--->info:"+info)
val ab = ArrayBuffer[String]()
ab.append(info)
ab
}
/**
* 分区内的相同key的聚合操作
*
*/
def mergeValue(ab:ArrayBuffer[String],info:String): ArrayBuffer[String] ={
println(s"mergeValue--->ab:${ab.mkString(",")}---info:${info}")
ab.append(info)
ab
}
/**
* 分区间的相同key的聚合操作
*/
def mergeCombiners(ab1:ArrayBuffer[String],ab2:ArrayBuffer[String]): ArrayBuffer[String] ={
println(s"mergeCombiners------>ab1:${ab1.mkString(",")}---ab2:${ab2.mkString(",")}")
ab1 ++ ab2
}
}
11、aggregateByKey(很重要)
aggregateBykey本质和combineByKey一样的。使用方面,只是在参数传递的方面略有差异。
11.1 aggregateBykey模拟groupByKey
:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.mutable.ArrayBuffer
object AggregateByKey2GroupByKeyOps {
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("abk2gbk")
.setMaster("local[2]")
//thread -- task--->partition(block)
val sc = new SparkContext(conf)
val stu = List(
"1 liushuai 22 bd-bj",
"2 zhangsan 25 bd-bj",
"8 lisi 24 bd-sz",
"3 wangwu 24 bd-sz",
"4 zhangfei 18 bd-wh",
"6 caocao 25 bd-bj",
"7 zhugekongming 25 bd-bj",
"5 zhouyu 18 bd-wh",
"4 xiaoqiao 18 bd-sz"
)
//按照班级进行分组 -->sql中的groupBy
val stuRDD = sc.parallelize(stu)
val class2Info:RDD[(String,String)]=stuRDD.map{stuLine =>{
val clazz = stuLine.substring(stuLine.indexOf("bd"))
(clazz,stuLine)
}}
val gbkRDD:RDD[(String,Iterable[String])]=class2Info.groupByKey()
println("-----------传统的gbk操作--------------")
gbkRDD.foreach{case(clazz,info)=>{
println(s"${clazz}--->${info}")
}
}
println("-----------aggregateByKey模拟gbk操作--------------")
class2Info.aggregateByKey(ArrayBuffer[String]())(seqOp, combOp).foreach(println)
}
def seqOp(ab:ArrayBuffer[String],info:String):ArrayBuffer[String] ={
ab.append(info)
ab
}
def combOp(ab1:ArrayBuffer[String],ab2:ArrayBuffer[String]):ArrayBuffer[String]={
ab1 ++ ab2
}
}
11.2.aggregateBykey模拟reduceByKey
:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
object _05AggregateByKey2ReduceByKeyOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("abk2rbk")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(
"hello you hello me",
"hello you shit me",
"hello you oh shit",
"me you hello me"
)
val listRDD = sc.parallelize(list)
val pairsRDD:RDD[(String, Int)] = listRDD.flatMap(_.split("\\s+")).map((_, 1))
//reduceByKey
println("-----------传统的rbk操作--------------")
pairsRDD.reduceByKey(_+_).foreach(println)
println("-----------combineByKey模拟rbk操作--------------")
pairsRDD.aggregateByKey(0)(seqOp, combOp).foreach(println)
//pairsRDD.aggregateByKey(0)((sum1, i) => sum1 + i, (sum, sum1) => sum + sum1).foreach(println)
//pairsRDD.aggregateByKey(0)(_+_, _+_).foreach(println)
sc.stop()
}
def seqOp(sum:Int, i:Int): Int = {
sum + i
}
def combOp(sum1:Int, sum2:Int): Int = {
sum1 + sum2
}
}
二、Action
action操作,是行动算子,是触发spark作业执行的动因。
同样,还是先来官网的常用Action算子的截图:


1、foreach
一般foreach的执行方式是foreach(func),对数据集的每个元素运行函数func。
2、collect
以数组的形式将所有数据集合的结果拉取到客户端,慎用,避免出现OOM,一般在使用该算子之前需要进行一个filter过滤掉部分数据或者使用take来决定需要拉取数据的量。
3、count
返回元素集合的数据条数
4、saveAsTextFile/saveAsHadoopFile/saveAsHadoopAPIFile
:
/*
saveAsTextFile
将rdd以普通文本的方式进行存储,存储的格式()
*/
// retRDD.saveAsTextFile("file:///E:/data/out/astf")
/*
saveAsSequenceFile
将rdd以sequenceFile的格式存储
*/
// retRDD.saveAsSequenceFile("file:///E:/data/out/sequ", Option(classOf[DefaultCodec]))
/*
saveAsHadoopFile
saveAsNewHadoopAPIFile
都是使用的hadoop的格式化输出OutputFormat 这两个方法的区别主要就是OutputFormat的区别
saveAsHadoopFile --> org.apache.hadoop.mapred.OutputFormat
saveAsNewHadoopAPIFile --> org.apache.hadoop.mapreduce.OutputFormat
*/
retRDD.saveAsNewAPIHadoopFile("file:///E:/data/out/hadoop",
classOf[Text],
classOf[IntWritable],
classOf[TextOutputFormat[Text, IntWritable]]
)
5、take(n)/frist/takeOrdered
take获取集合中的前N个值,take(1)=first,如果说这个集合是有序的,take(n)–等效于–>TopN
takeOrdered是使用RDD的自然顺序或自定义比较器返回RDD的前n个元素。
:
println("-------take(2)-------------")
retRDD.take(2).foreach(println)
println("-------first-------------")
println(retRDD.first())
println("--------takeOrdered----------------------")
implicit val order = new Ordering[(String, Int)](){
override def compare(x: (String, Int), y: (String, Int)) = {
var ret = y._2.compareTo(x._2)
if(ret == 0) {
ret = y._1.compareTo(x._1)
}
ret
}
}
retRDD.takeOrdered(5).foreach(println)
6、countByKey
:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
object countByKeyOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("actionOps")
.setMaster("local[1]")
val sc = new SparkContext(conf)
val list = List(
"hello you hello me",
"hello you shit me",
"hello you oh shit",
"me you hello me"
)
val listRDD = sc.parallelize(list)
val pairsRDD: RDD[(String, Int)] = listRDD.flatMap(_.split("\\s+")).map((_, 1))
val retRDD: RDD[(String, Int)] = pairsRDD.reduceByKey(_ + _)
//通过每个key出现的次数
val k2counts = pairsRDD.countByKey()
for ((k, v) <- k2counts) {
println(s"${k}---$v")
}
//使用groupByKey、reduceByKey、countByKey --->wordcount
println("-----------------------------------")
val gbks = pairsRDD.groupByKey()
// gbks.foreach(println)
gbks.map { case (key, values) => (key, values.size) }.foreach(println)
}
}
7、reduce
reduceByKey是一个transformation,reduce是一个action。需要注意区分!
:
object reduceOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("actionOps")
.setMaster("local[1]")
val sc = new SparkContext(conf)
val list = List(
"hello you hello me",
"hello you shit me",
"hello you oh shit",
"me you hello me"
)
val listRDD = sc.parallelize(list)
val pairsRDD: RDD[(String, Int)] = listRDD.flatMap(_.split("\\s+")).map((_, 1))
val sum = pairsRDD.values.reduce(_+_)
println(sum)
}
}