Apache Kafka开源流式KSQL实战
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多惊喜


大数据技术与架构
点击右侧关注,大数据开发领域最强公众号!


暴走大数据
点击右侧关注,暴走大数据!

背景
Kafka早期作为一个日志消息系统,很受运维欢迎的,配合ELK玩起来很happy,在kafka慢慢的转向流式平台的过程中,开发也慢慢介入了,一些业务系统也开始和kafka对接起来了,也还是很受大家欢迎的,由于业务需要,一部分小白也就免不了接触kafka了,这些小白总是会按奈不住好奇心,要精确的查看kafka中的某一条数据,作为服务提供方,我也很方啊,该怎么怼?业务方不敢得罪啊,只能写consumer去消费,然后人肉查询。
需求
有什么方法能直接查询kafka中已有的数据呢?那时候presto就映入眼帘了,初步探索后发现presto确实强大,和我们在用的impala有的一拼,支持的数据源也更多,什么redis、mongo、kafka都可以用sql来查询,真是救星啊,这样那群小白就可以直接使用presto来查询里面的数据了。不过presto在不开发插件的情况下,对kafka的数据有格式要求,支持json、avro。但是我只是想用sql查询kafka,而presto功能过于强大,必然整个框架就显得比较厚重了,功能多嘛。有什么轻量级的工具呢?
介绍
某一天,kafka的亲儿子KSQL就诞生了,KSQL是一个用于Apache kafka的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL接口,用于处理Kafka的数据,可以让我们在流数据上持续执行 SQL 查询,KSQL支持广泛的强大的流处理操作,包括聚合、连接、窗口、会话等等。
KSQL在内部使用Kafka的Streams API,并且它们共享与Kafka流处理相同的核心抽象,KSQL有两个核心抽象,它们对应于到Kafka Streams中的两个核心抽象,让你可以处理kafka的topic数据。
架构
部署架构
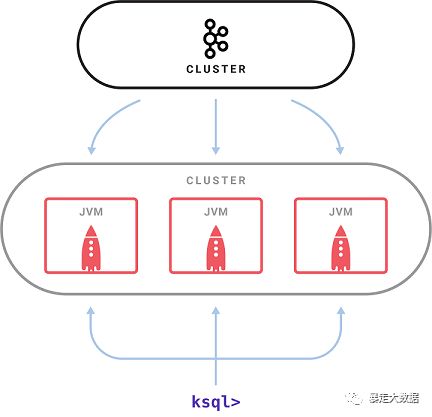
由一个KSQL服务器进程执行查询。一组KSQL进程可以作为集群运行。可以通过启动更多的KSQL实例来动态添加更多的处理能力。这些KSQL实例是容错的,如果一个实例失败了,其他的就会接管它的工作。查询是使用交互式的KSQL命令行客户端启动的,该客户端通过REST API向集群发送命令。命令行允许检查可用的stream和table,发出新的查询,检查状态并终止正在运行的查询。KSQL内部是使用Kafka的stream API构建的,它继承了它的弹性可伸缩性、先进的状态管理和容错功能,并支持Kafka最近引入的一次性处理语义。KSQL服务器将此嵌入到一个分布式SQL引擎中(包括一些用于查询性能的自动字节代码生成)和一个用于查询和控制的REST API。
处理架构
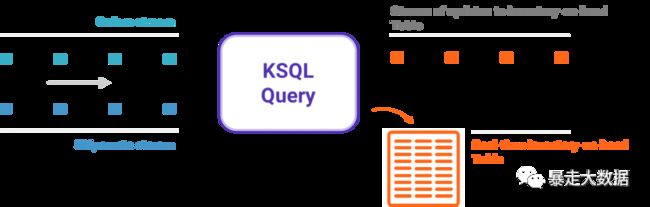
抽象概念
KSQL简化了流应用程序,它集成了stream和table的概念,允许使用表示现在发生的事件的stream来连接表示当前状态的table。Apache Kafka中的一个topic可以表示为KSQL中的STREAM或TABLE,具体取决于topic处理的预期语义。下面看看两个核心的解读。
stream:流是无限制的结构化数据序列,stream中的fact是不可变的,这意味着可以将新fact插入到stream中,但是现有fact永远不会被更新或删除。stream可以从Kafka topic创建,或者从现有的stream和table中派生。
table:一个table是一个stream或另一个table的视图,它代表了一个不断变化的fact的集合,它相当于传统的数据库表,但通过流化等流语义来丰富。表中的事实是可变的,这意味着可以将新的事实插入到表中,现有的事实可以被更新或删除。可以从Kafka主题中创建表,也可以从现有的流和表中派生表。
部署
ksql支持kafka0.11之后的版本,在confluent的V3和V4版本中默认并没有加入ksql server程序,当然V3和V4是支持ksql的,在V5版本中已经默认加入ksql了,为了方便演示,我们使用confluent kafka V5版本演示,zk和kafka也是单实例启动。
下载
wget https://packages.confluent.io/archive/5.0/confluent-oss-5.0.0-2.11.tar.gz tar zxvf confluent-oss-5.0.0-2.11.tar.gz -C /opt/programs/confluent_5.0.0
启动zk
cd /opt/programs/confluent_5.0.0
bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties启动kafka
cd /opt/programs/confluent_5.0.0
bin/kafka-server-start -daemon etc/kafka/server.properties创建topic和data
confluent自带了一个ksql-datagen工具,可以创建和产生相关的topic和数据,ksql-datagen可以指定的参数如下:
[bootstrap-server= (defaults to localhost:9092)]
[quickstart= (case-insensitive; one of 'orders', 'users', or 'pageviews')]
schema=
[schemaRegistryUrl= (defaults to http://localhost:8081)]
format= (case-insensitive; one of 'avro', 'json', or 'delimited')
topic=
key=
[iterations= (defaults to 1,000,000)]
[maxInterval= (defaults to 500)]
[propertiesFile=] 创建pageviews,数据格式为delimited
cd /opt/programs/confluent_5.0.0/bin
./ksql-datagen quickstart=pageviews format=delimited topic=pageviews maxInterval=500ps:以上命令会源源不断在stdin上输出数据,就是工具自己产生的数据,如下样例
8001 --> ([ 1539063767860 | 'User_6' | 'Page_77' ]) ts:1539063767860
8011 --> ([ 1539063767981 | 'User_9' | 'Page_75' ]) ts:1539063767981
8021 --> ([ 1539063768086 | 'User_5' | 'Page_16' ]) ts:1539063768086不过使用consumer消费出来的数据是如下样式
1539066430530,User_5,Page_29
1539066430915,User_6,Page_74
1539066431192,User_4,Page_28
1539066431621,User_6,Page_38
1539066431772,User_7,Page_29
1539066432122,User_8,Page_34创建users,数据格式为json
cd /opt/programs/confluent_5.0.0/bin
./ksql-datagen quickstart=users format=json topic=users maxInterval=100ps:以上命令会源源不断在stdin上输出数据,就是工具自己产生的数据,如下样例
User_5 --> ([ 1517896551436 | 'User_5' | 'Region_5' | 'MALE' ]) ts:1539063787413
User_7 --> ([ 1513998830510 | 'User_7' | 'Region_4' | 'MALE' ]) ts:1539063787430
User_6 --> ([ 1514865642822 | 'User_6' | 'Region_2' | 'MALE' ]) ts:1539063787481不过使用consumer消费出来的数据是如下样式
{"registertime":1507118206666,"userid":"User_6","regionid":"Region_7","gender":"OTHER"}
{"registertime":1506192314325,"userid":"User_1","regionid":"Region_1","gender":"MALE"}
{"registertime":1489277749526,"userid":"User_6","regionid":"Region_4","gender":"FEMALE"}
{"registertime":1497188917765,"userid":"User_9","regionid":"Region_3","gender":"OTHER"}
{"registertime":1493121964253,"userid":"User_4","regionid":"Region_3","gender":"MALE"}
{"registertime":1515609444511,"userid":"User_5","regionid":"Region_9","gender":"FEMALE"}启动ksql
cd /opt/programs/confluent_5.0.0
bin/ksql-server-start -daemon etc/ksql/ksql-server.properties连接ksql
cd /opt/programs/confluent_5.0.0
bin/ksql http://10.205.151.145:8088 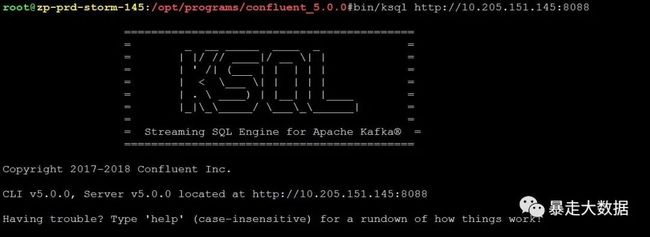
创建stream和table
stream
根据topic pageviews创建一个stream pageviews_original,value_format为DELIMITED
ksql>CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH \
(kafka_topic='pageviews', value_format='DELIMITED');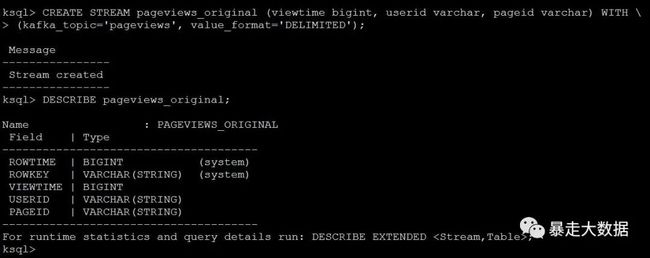
table
根据topic users创建一个table users_original,value_format为json
ksql>CREATE TABLE users_original (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR) WITH \
(kafka_topic='users', value_format='JSON', key = 'userid');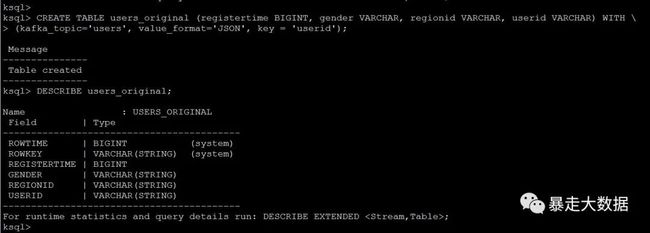
查询数据
ksql> SELECT * FROM USERS_ORIGINAL LIMIT 3;
ksql> SELECT * FROM pageviews_original LIMIT 3;
ps:ksql默认是从kafka最新的数据查询消费的,如果你想从开头查询,则需要在会话上进行设置:SET 'auto.offset.reset' = 'earliest';
持久化查询
持久化查询可以源源不断的把查询出的数据发送到你指定的topic中去,查询的时候在select前面添加create stream关键字即可创建持久化查询。
创建查询
ksql> CREATE STREAM pageviews2 AS SELECT userid FROM pageviews_original;
查询新stream
ksql> SHOW STREAMS;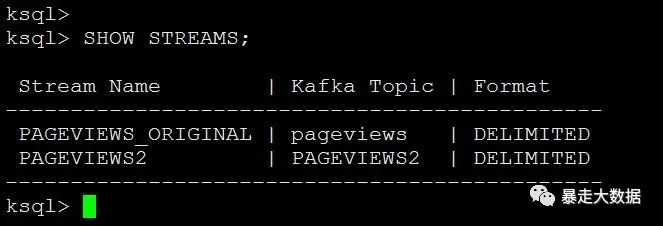
ps:可以看到新创建了stream PAGEVIEWS2,并且创建了topic PAGEVIEWS2
查询执行任务
ksql> SHOW QUERIES;
ps:可以看到ID为CSAS_PAGEVIEWS2_0的任务在执行,并且有显示执行的语句
消费新数据
cd /opt/programs/confluent_5.0.0/bin
./kafka-console-consumer --bootstrap-server 10.205.151.145:9092 --from-beginning --topic
PAGEVIEWS2
ps:可以看到PAGEVIEWS2 topic里面正是我们通过select筛选出来的数据
终止查询任务
ksql> TERMINATE CSAS_PAGEVIEWS2_0;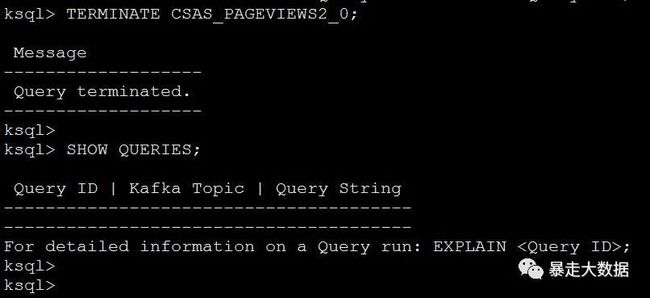
欢迎点赞+收藏
欢迎转发至朋友圈
