spark-shell启动命令详细解析1
环境:
spark 2.3.3
scala 2.11.8
Java 1.8.0_141
执行spark-shell命令后,会启动spark-shell交互命令行窗口:

那么spark-shell命令的启动流程是怎样的呢?
下面让我们来一步一步分析
首先,查看${SPARK_HOME}/bin/spark-shell启动脚本
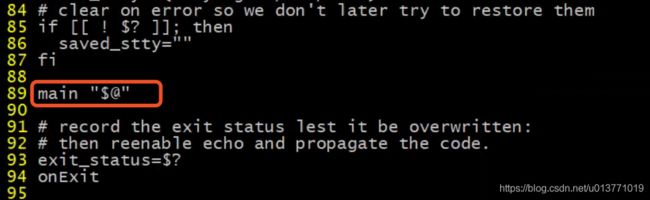
可以看到,spark-shell脚本使用启动参数调用main方法
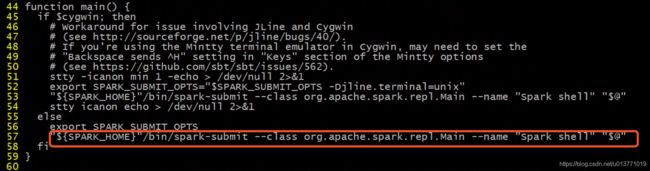
spark-shell脚本中的main方法最终会调用命令:
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
那么此时会执行spark-submit脚本,会将
--class org.apache.spark.repl.Main --name "Spark shell"
参数和spark-shell启动参数
"$@"
一起传递给spark-submit脚本
查看${SPARK_HOME}/bin/spark-submit脚本:
最终会通过命令:
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
调用org.apache.spark.deploy.SparkSubmit类。(这里${SPARK_HOME}/bin/spark-class 脚本不再分析)
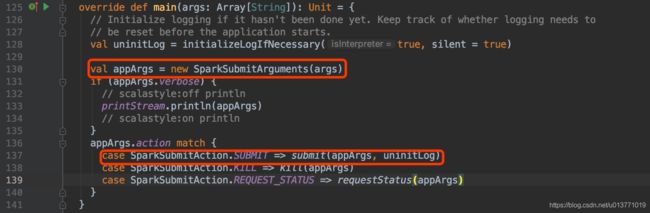
下面查看org.apache.spark.deploy.SparkSubmit类的main方法
首先解析传递的参数,然后根据appArgs.action 匹配相应的动作.
而appArgs.action的设置是在org.apache.spark.deploy.SparkSubmitArguments
var action: SparkSubmitAction = null
…
// Action should be SUBMIT unless otherwise specified
action = Option(action).getOrElse(SUBMIT)
可以看到,由于我们没有传递action参数,所以默认是SUBMIT,所以org.apache.spark.deploy.SparkSubmit的main方法会调用submit方法
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
( 即Spark WebUI的堆栈信息—> org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137) )
下面看org.apache.spark.deploy.SparkSubmit$submit方法
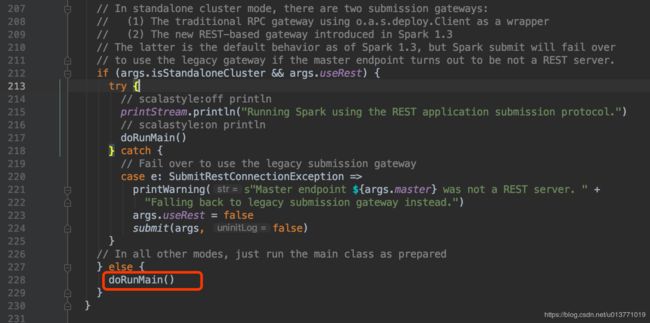
可以看到org.apache.spark.deploy.SparkSubmit$submit方法中最后会调用submit方法中定义的doRunMain方法,然后调用runMain方法
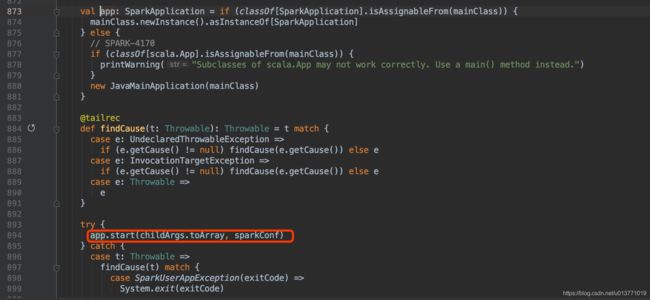
而在runMain方法中,会根据传递的childMainClass通过反射回去class,然后通过new JavaMainApplication(mainClass)启动,这里的class就是${SPARK_HOME}/bin/spark-shell脚本中指定的org.apache.spark.repl.Main
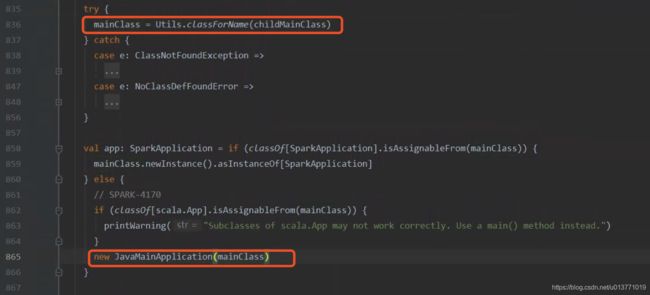
然后通过JavaMainApplication$start方法启动org.apache.spark.repl.Main类:
在JavaMainApplication$start方法中
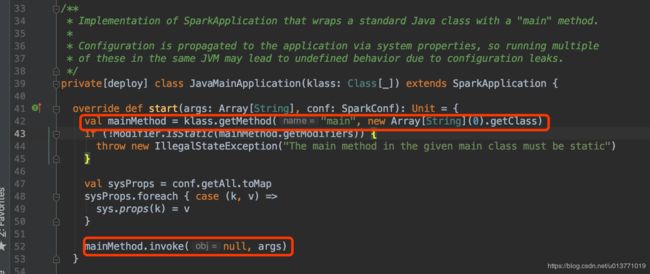
通过反射,调用org.apache.spark.repl.Main$main方法
下面我们看下org.apache.spark.repl.Main类
但是,在idea中没有搜到这个类,原来这个类在
spark-repl_2.12依赖里面
在maven中添加依赖
再次查找,就能找到这个类org.apache.spark.repl.Main

其实上面这些class类的调用堆栈信息,可以在spark的webUI上看到
spark-shell启动的时候,会提示webUI的地址:
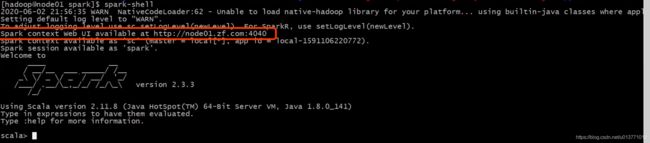
Spark context Web UI available at http://node01.zf.com:4040
打开这个地址:

然后点击Executors tab
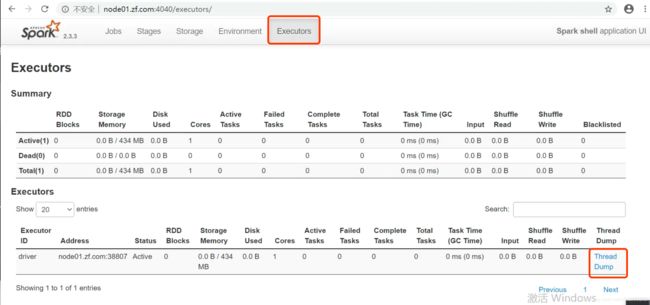
然后点击driver对应的Thread Dump,在打开页面中点击Thread ID=1的线程,会展开堆栈调用信息。我们上面说的调用链信息都在里面。