MySQL 基础 ————高频函数总结
一、MySQL函数调用方式
函数调用的基本语法:
SELECT 函数(实参列表) [FROM 表]其中,对于函数,需要重点关注三点:
1、函数的名称
2、参数列表
3、函数功能
二、函数的分类
在 MySQL中,函数分为两类:1、单行函数;2、分组函数。
2.1 单行函数
单行函数有 concat、length、ifnull 等。单行函数下还有多种分类。
2.1.1 字符函数
字符函数的参数类型就是 varchar 。常用的字符函数有:
1、大小写控制函数:LOWER()、UPPER()。
SELECT
LOWER('MORTY'),
UPPER('morty') ;
2、字符控制函数:
CHAR_LENGTH(str) : 返回字符串的字符个数。
select
char_length('中国') 字符数,
CHAR_LENGTH('Morty') 字符数,
CHARACTER_LENGTH('中国') 字符数,
length('中国') 字节数;
tip:查看字符集的语句:SHOW VARIABLES LIKE '%char%';
CONCAT(str1, str2, ...) : 拼接多个字符串
SELECT
CONCAT('中国', '-', '香港') 地市,
CONCAT('Jack', '_', 'Morty') 姓名,
CONCAT(UPPER('Hello'), ' ', LOWER('WORLD')) 问候 ;
SUBSTR(str, pos [, len]) : 截取字符串,下标从 1 开始,len代表需要截取字符数,不指定则截取到最后。
SELECT
'中国人民共和国建国70周年' 原始,
SUBSTR('中国人民共和国建国70周年', 2) 截取后,
SUBSTR('中国人民共和国建国70周年',3, 5) 截取后;
# 姓名中首字符大写
SELECT
emp_name 原始,
CONCAT(
UPPER(SUBSTR(emp_name, 1, 1)),
LOWER(SUBSTR(emp_name, 2))
) last_name
FROM
emp 
INSTR(str, substr) : 返回子串第一次出现的索引,如果找不到返回 0
SELECT
INSTR('我和我的祖国', '祖国') 第一次出现,
INSTR('我和我的祖国', '中国') 没有子串;
TRIM(str) : 去掉前后空格
SELECT TRIM(' 我们 不一 样 ') 去前后空格;
LPAD(str, len, padstr) : 左补指定字符串,且总长度是 len 个字符。注意,padstr 可以是多个字符,但最终字符数必须是 len。RPAD(...) 右补同理。
SELECT
LPAD('美景东方小区', 10, 'abc') 左补多个字符,
LPAD('美景东方小区', 10, '*') '左补*';
REPLACE(str, fromstr, tostr) : 替换子串
SELECT REPLACE('王建国,你好', '王', '李') 替换;
也可以修改字段内的个别文字,如:
UPDATE 表名 SET 列名 = REPLACE(列名, '原内容', '新内容') WHERE 条件;
2.1.2 数学函数
1、ROUND(x [, d]) 四舍五入(计算规则:先算绝对值,在加正负号),如果是两个参数,则第二个参数代表保留小数点后位数。
SELECT ROUND(1.65), ROUND(-1.45), ROUND(-1.5);
SELECT ROUND(1.65, 1), ROUND(-1.453, 2);
2、CEIL(x) 向上取整,返回 >= 该参数的最近整数,FLOOR(x) 向下取整,返回 <= 该参数的最近整数。
SELECT FLOOR(1.52), CEIL(1.00), CEIL(-1.02);
3、TRUNCATE(x, d) : 小数截取,保留小数后指定位数。
SELECT TRUNCATE(1.65, 1);![]()
4、MOD(a, b) : 取余运算。不论正负,都可以套用公式:a - a/b * b,除法运算要取整。规律:结果值符号与被除数相同。mod()运算与 % 的效果是相同的。
SELECT MOD(10, 3), MOD(-10, 3), MOD(-10, -3), -10 % -3;![]()
5、RAND() :取得 [0, 1) 之间的随机数,可以配合其他函数一起使用,另外,该函数可以接收一个种子值,这个种子值会对应一个不变的随机数,只要种值不变,生成的随机数就不会改变。另外,获取 [ a, b ] 之间的整数公式是:
FLOOR(a + RAND() * (b - a + 1))
SELECT
RAND(1),
RAND(1),
RAND(),
RAND(),
FLOOR(RAND() * 100) 组合;![]()
2.1.3 日期函数
1、获取当前系统时间,获取当前日期,获取当前时间,获取年份:
SELECT
NOW(),
CURDATE(),
CURTIME(),
YEAR('2019-10-20') 年,
YEAR(NOW()) 年,
YEAR(CURDATE()) 年,
YEAR(CURTIME()) 年 ;![]()
2、获取月份:MONTH()、MONTHNAME()、其他的日、时、分、秒 类似。
SELECT
MONTH(NOW()),
MONTH(CURTIME()),
MONTHNAME('2019-10-20') ;
3、STR_TO_DATE(str, format) 将日期字符串按照指定格式解析为日期
SELECT * FROM emp WHERE hiredate = '2019-10-15';
SELECT * FROM emp WHERE hiredate = STR_TO_DATE('10-15 2019', '%m%d %Y');
4、DATE_FORMAT(date, format) 日期格式化
SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日') 日期格式化;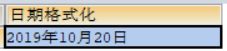
SELECT
LEFT(
DATE_FORMAT(
CURRENT_TIMESTAMP(3),
'%Y-%m-%d %H:%i:%s.%f'
),
23
) 当前时间 ; ![]()
5、DATEDIFF(expr1, expr2) 相差天数
SELECT DATEDIFF(NOW(), '2019-10-18') 相差天数;2.1.4 其他函数
1、VERSION() 版本号
2、DATABASE() 查看当前数据库
3、USER() 查看当前用户
4、PASSWORD(str) 给字符串加密,类似还有MD5(str) 等。
SELECT
VERSION(),
DATABASE(),
USER(),
PASSWORD('123'),
MD5('123') ;![]()
2.1.5 流程控制函数
1、IF(expr1, expr2, expr3) 三目运算符
SELECT
IF(1 = 1, 'true', FALSE) 真,
IF(1 = 2, 'true', FALSE) 假,
IF(FALSE = 0, 'true', FALSE) 真;![]()
2、IFNULL(a, b) 判空,若a 为 null ,则输出 b ,否则直接输出 a.
SELECT
*,
IFNULL(manager_id, 0) 去NULL
FROM
`emp` ;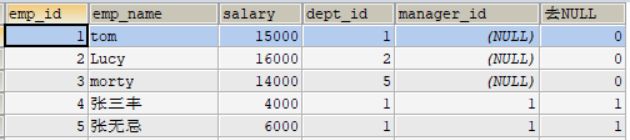
3、CASE...WHEN 类似 switch 和 多重 if。
案例,查询高中老师的工资,由于学校偏理科,为积极引进文科老师,所有文科老师根据学科享有一定的工资加成:
SELECT
t.`teacher_id`, t.`teacher_name`, l.`lesson_name`,
t.salary 原始工资,
IFNULL(
CASE l.`lesson_name`
WHEN '语文' THEN salary * 0.1
WHEN '外语' THEN salary * 0.2
WHEN '政治' THEN salary * 0.3
WHEN '历史' THEN salary * 0.5
WHEN '生物' THEN salary * 0.3
END, 0.0
) 工资加成
FROM
teacher t, lesson l
WHERE t.`lesson` = l.`lesson_id` ;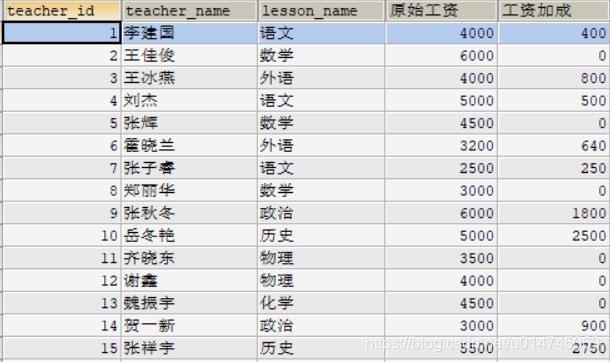
2.2 分组函数(聚合函数)
分组函数一般用作统计使用,又称组函数、聚合函数 或 统计函数。
2.2.1 高频分组函数
1、SUM() 求和函数
2、AVG() 求平均值
3、MIN()、MAX() 求最大最小值
4、COUNT(column) 求某列非 NULL 值的记录个数
SELECT
SUM(salary),
ROUND(AVG(salary), 2),
MIN(salary),
MAX(salary),
COUNT(salary)
FROM
teacher ;![]()
这些函数的特点:
1、SUM、AVG 用于处理数值型
2、MAX、MIN、COUNT 可以用于处理任何类型
3、所有的分组函数都忽略 NULL 值。
2.2.2 与 DISTINCT 的搭配用法
所有的分组函数都可以与DISTINCT关键字进行搭配使用。
SELECT
SUM(salary) 原求和,
SUM(DISTINCT salary) 去重求和,
COUNT(salary) 原工资数量,
COUNT(DISTINCT salary) 去重工资种类
FROM
teacher ;
2.2.3 COUNT 函数详解
COUNT() 函数除了可以统计指定字段非null 的行数,除了可以统计指定字段非null 的行数:
SELECT COUNT(*) 学生总数 FROM student;
另外,在 COUNT()参数中加一个常量值,相当于在表中加了一列,然后统计这个列的记录数。比如:SELECT COUNT(1) FROM 表名; 或者SELECT COUNT(2)、SELECT COUNT('xxx')等,都是同样的意思。
但是,效率上,需要分具体的数据库引擎来看:
MYISAM 存储引擎下,COUNT(*)效率最高,因为其内部有一个计数器,会直接返回行号。
INNODB引擎下,COUNT(*) 和 COUNT(1) 效率差不多,但是比 COUNT(字段) 效率高,因为查询字段的 COUNT(column) 函数需要判断是否为null。
因此,一般情况下,如果要进行全记录数量统计,直接使用 COUNT(*) 是最好的选择。
2.2.4 和分组函数一同查询的字段
由于分组函数查询结果都是一个值,因此不能和某些可以查询出多行的字段一同查询,比如:
SELECT AVG(salary), id FROM emp; # 这条语句虽然不会报错,但是其结果不具备太大意义这种SQL语句虽然不会报错,但是已经不具有什么意义了。因此,与分组函数可以一同查询的字段一般是 GROUP BY 后的字段。
综上,就是关于MySQL中高频函数的总结和测试,后期如果遇到更多的函数,也会在这里追加总结的。欢迎文末留言。