Django框架
1、django框架、flask框架和Tornado框架的区别?
django框架,内置组件多,自身功能强大,是一个大而全的框架,ORM、Admin、中间件、Form、ModelFrom、信号、缓存、csrf等
flask框架,内置组件少,但第三方丰富,可扩展性强,是一个微小型框架,组件有flask-session、flask-SQLAlchemy、wtforms、flask-migrate、flask-script、blinker
相同点:
两个框架都是基于wsgi协议实现的,只是默认使用的wsgi模块不一样。 django:wsgiref模块 flask:werkzurg模块
不同点:他们各自处理请求的方式不同:
django: 通过将请求封装成Request对象,在依次通过中间件,在视图中通过参数进行传递。
flask:通过上下文管理实现。
Tornado框架:
Tornado是一个轻量级的Web框架,主要功能:异步非阻塞+内置WebSocket
2、django框架的请求周期
a. wsgi, 创建socket服务端,用于接收用户请求并对请求进行初次封装。
b. 中间件,对所有请求在到来之前,响应之前定制一些操作。
c. 路由匹配,在url和视图函数对应关系中,根据当前请求url找到相应的函数。
d. 执行视图函数,业务处理【通过ORM去数据库中获取数据,再去拿到模板,然后将数据和模板进行渲染】
e. 再经过所有中间件
f. 通过wsgi将响应返回给用户。

2.1浏览器上输入地址,回车然后发生了什么? => Http请求生命周期
1、进行域名解析获取ip, 先去本地域名服务器,如果没有再去根域名服务器
2、连接成功
3、浏览器发送数据
4、服务器接受到数据后处理并响应给浏览器
-服务器在次过程中处理流程较多,-django,flask等
3、什么是WSGI?与uWSGI的区别
WSGI是web服务网关接口--->应用程序(web框架)与web服务器之间的一种接口
实现了wsgi协议的模块本质:编写了socket服务端,用来监听用户请求,如果有请求到来,则将请求进行一次封装,然后交给 web框架来进行下一步处理。
模块有:-wsgiref -werkzurg -uwsgi
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换
代码上线时,使用uWSGI:
1、nginx 做为代理服务器:负责静态资源发送(js、css、图片等)、动态请求转发以及结果的回复;
2、uWSGI 做为后端服务器:负责接收 nginx 请求转发并处理后发给 Django 应用以及接收 Django 应用返回信息转发给 nginx;
3、Django 应用收到请求后处理数据并渲染相应的返回页面给 uWSGI 服务器。
4、中间件
作用:对所有的请求进行批量处理,可以在视图函数执行前后进行自定义操作
应用:
-用户登录验证 --->如果使用装饰器,就必须给每个函数都添加,太繁琐
-权限处理 --->用户登录成功,将该用户所有的权限写入session中,每次访问时判断该用户是否有权限访问当前的url,这样就可以将判断用户是否用权限的操作放入中间中
-内置应用
-session
-csrf --->跨站请求伪造,防止用户直接向服务端发送POST请求。中间件拦截检验是否携带crsf_token
-全局缓存 --->如果设置了缓存,则请求进来,通过中间件后,则直接去缓存中取数据,然后响应,如果此时的缓存中没有数据,则走路由匹配、视图函数,但是在响应时会先将数据放入到缓存当中
-跨域
-cors --->浏览器的同源策略(不同的域名或不同的端口)前后端分离时,本地开发测试使用
5、csrf原理
1、浏览器向服务端发送GET请求,获取csrf_token: form表单中隐藏的input标签+保存到cookie中(通过算法)
2、再次发送POST请求时,需要携带之前发给浏览器的csrf_token,用次crsf_token与cookie中的crsf_token做验证
3、进行验证:在process_view中验证(因为只有在process_view中,才能得到视图函数,判断函数是否需要验证(加装饰器可以避免验证))
6、方法
porcess_request
porcess_view
porcess_template_response 只有在视图函数的返回值中有render方法时才调用此方法
porcess_excepion 处理异常
porcess_response
7、发送POST请求的方法
- form表单
- ajax提交
- requests.post()


方法一: $.ajax({ url:'/index', type:'POST', #携带csrf_token data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'} }) 方法二: 前提:引入jquery + 引入jquery.cookie $.ajax({ url: 'xx', type:'POST', data:{name:'oldboyedu'}, #添加请求头 headers:{ X-CSRFToken: $.cookie('csrftoken') }, dataType:'json', // arg = JSON.parse('{"k1":123}') success:function(arg){ } }) 方法三:使用ajaxSetup, "button" οnclick="Do1();" value="Do it"/> "button" οnclick="Do2();" value="Do it"/> "button" οnclick="Do3();" value="Do it"/>
8、基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
data headers ajaxSetup()
9、路由
1、路由分发include:二级路由
2、路由系统中name的作用:反向解析
url(r'^home', views.home, name='home')
在模板中使用 {% url 'home' %}
在视图中使用 reverse(“home”)
10、 MTV和MVC
MVC: model view(模块) controller (视图)
MTV: model tempalte view
11、视图
1、CBV和FBV区别:
本质上是没有什么区别的,因为它们都是通过对函数进行操作的,而CBV是通过.as_views()方法返回view函数,view函数再调用dispatch(), 在dispstch方法中在通过反射执行get、post、put、patch、delete方法的
2、处理csrf认证及CBV添加装饰器
普通装饰器可以加在get、post等方法上
csrf装饰器放在dispatch()上或直接加在类上
局部避免csrf的方式: from django.views.decorators.csrf import csrf_exempt from django.utils.decorators import method_decorator 针对FBV: @csrf_exempt def foo(request): return HttpResponse("foo") 针对CBV: # 方式1 @method_decorator(csrf_exempt,name="dispatch") class IndexView(View): # 方式2 @method_decorator(csrf_exempt) def dispatch(self, request, *args, **kwargs): print("hello world") # 执行父类的dispatch方法 res=super(IndexView,self).dispatch(request, *args, **kwargs) print("hello boy") return res @method_decoretor(装饰器函数) 添加装饰器 def post(self,request,*args,**kwargs): return HttpResponse('OK')
12、Django中request对象什么时候创建的?
当请求进来时,将请求相关的数据封装到environ中,django项目启动时,执行__call__,将environ赋值给request对象
wsgi: from wsgiref.simple_server import make_server def run_server(environ, start_response): """ environ: 封装了请求相关的数据 start_response:用于设置响应头相关数据 """ start_response('200 OK', [('Content-Type', 'text/html')]) return [bytes('Hello, web!
', encoding='utf-8'), ] if __name__ == '__main__': httpd = make_server('', 8000, run_server) httpd.serve_forever() Django源码: class WSGIHandler(base.BaseHandler): request_class = WSGIRequest def __init__(self, *args, **kwargs): super(WSGIHandler, self).__init__(*args, **kwargs) self.load_middleware() def __call__(self, environ, start_response): # 请求刚进来之后 # set_script_prefix(get_script_name(environ)) signals.request_started.send(sender=self.__class__, environ=environ) request = self.request_class(environ) response = self.get_response(request) response._handler_class = self.__class__ status = '%d %s' % (response.status_code, response.reason_phrase) response_headers = [(str(k), str(v)) for k, v in response.items()] for c in response.cookies.values(): response_headers.append((str('Set-Cookie'), str(c.output(header='')))) start_response(force_str(status), response_headers) if getattr(response, 'file_to_stream', None) is not None and environ.get('wsgi.file_wrapper'): response = environ['wsgi.file_wrapper'](response.file_to_stream) return response
13、 遇见的问题
- CBV时添加csrf装饰器,是添加在dispatch上
- 多数据库配置 allow_relation方法 进行连表
14、ORM
1、增、删、改、查
增: models.UserInfo.objects.create() obj = models.UserInfo(name='xx') obj.save() models.UserInfo.objects.bulk_create([models.UserInfo(name='xx'),models.UserInfo(name='xx')]) 删: models.UserInfo.objects.all().delete() 改: models.UserInfo.objects.all().update(age=18) #在原来的基础上添加1000 models.UserInfo.objects.all().update(salary=F('salary')+1000) 查: filter()· 找不到返回[] exclude() 排除 values() 字典 values_list() 元祖 order_by() order_by('-id') anotate() 用于实现聚合group by查询 aggregate() 聚合函数 exsit() 是否有结果 reverse() 反转 distinct() 去重 返回具体的对象 first() laste() get() 找不到报错
2、value余value_list
value 返回一个字典
value_list 返回一元祖 (flat=Ture 此时返回一个列表)
3、F、Q
(1)F 用于比较,数字自增
# 查询评论数大于收藏数的书籍 from django.db.models import F Book.objects.filter(commnetNum__lt=F('keepNum')) #将每一本书的价格提高30元 Book.objects.all().update(price=F("price")+30)
(2)Q 主要是构造复杂的查询条件。查询条件为or(|),and($)
查询作者名是小仙女或小魔女的 models.Book.objects.filter(Q(authors__name="小仙女")|Q(authors__name="小魔女"))
4、性能优化
(1)select related
1、select_related主要针一对一和多对一关系进行优化。
2、select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
class Usertype(models.Model): title = models.CharField(max_length=32) class UserInfo(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) ut = models.ForeignKey(to='UserType') # 1次SQL # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: print(item.name) # n+1次SQL # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: # select * from usertype where id = item.id print(item.name,item.ut.title) # 1次SQL # select * from userinfo inner join usertype on userinfo.ut_id = usertype.id objs = UserInfo.obejcts.all().select_related('ut') for item in objs: print(item.name,item.ut.title)
(2)prftatch related
1、对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化
2、prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。(如果链表过多,也会影响效率)
(3)only 仅取一条记录中指定的数据(queryset[obj,obj,obj]) models.UserInfo.objects.only('username','id')
(4)defer 排除一条记录指定的数据 (queryset[obj,obj]) models.UserInfo.objects.defer('username','id')
5、执行原生SQL
(1)extra 构造查询条件,如子查询
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
(2)raw 执行sql语句
models.UserInfo.objects.raw('select * from userinfo')
(3)execute
1.执行自定义SQL # from django.db import connection, connections # cursor = connection.cursor() # cursor = connections['default'].cursor() # cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # row = cursor.fetchone()
5、using 指定数据库
参考示例
15、django中如何实现orm表中添加数据时创建一条日志记录
使用信号
16、 orm中的db first 与code first的区别?
db first :先创建数据库,再更新表模型
code first:先写表模型,再更新数据库
17、django中如何根据数据库表生成model中的类
1、settings中设置连接数据库
2、python manage.py inspectdb > app/models.py
18、模板
1、模板继承:{% extends 'layouts.html' %}
2、自定义方法
- filter 只能传递两个参数,可以在if、for语句中使用
- simple_tag 可以无线传参,不能在if for中使用
- inclusion_tags 可以使用模板和后端数据
3、xss攻击:|safe mark_safe
19、From和ModelFrom的作用、区别、应用场景
作用: -用户请求数据格式验证
-生产HTML标签
区别:-From需要自己写字段
-ModelFrom通过Meta定义
场景:凡是需要进行表单数据验证的 如:登录验证
20、django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新
重写__init__和使用ModelChoiceField字段类型
from django.forms import Form from django.forms import fields 方法一:重新__init__ class UserForm(Form): name = fields.CharField(label='用户名',max_length=32) email = fields.EmailField(label='邮箱') ut_id = fields.ChoiceField( # choices=[(1,'二笔用户'),(2,'闷骚')] choices=[] ) def __init__(self,*args,**kwargs): super(UserForm,self).__init__(*args,**kwargs) # 每次实例化,重新去数据库获取数据并更新 self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title') def user(request): if request.method == "GET": form = UserForm() return render(request,'user.html',{'form':form}) 方法二:使用ModelChoiceField字段 from django.forms import Form from django.forms import fields from django.forms.models import ModelChoiceField class UserForm(Form): name = fields.CharField(label='用户名',max_length=32) email = fields.EmailField(label='邮箱') ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
21、django的Model中的ForeignKey字段中的on_delete参数有什么作用
表关系是OneToOne,ForeignKey时,有on_delete参数,主要为了避免两个表里的数据不一致问题(关联表中的对象被删除后,此时表中的对象情况)
Django2.0里model外键和一对一的on_delete参数 在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错: TypeError: __init__() missing 1 required positional argument: 'on_delete' 举例说明: user=models.OneToOneField(User) owner=models.ForeignKey(UserProfile) 需要改成: user=models.OneToOneField(User,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值 owner=models.ForeignKey(UserProfile,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值 参数说明: on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值 CASCADE:此值设置,是级联删除。 PROTECT:此值设置,是会报完整性错误。 SET_NULL:此值设置,会把外键设置为null,前提是允许为null。 SET_DEFAULT:此值设置,会把设置为外键的默认值。 SET():此值设置,会调用外面的值,可以是一个函数。
22、为什么要用缓存
将常用且不太频繁修改的数据放入缓存。
以后用户再来访问,先去缓存查看是否存在,如果有就返回
否则,去数据库中获取并返回给用户(再加入到缓存,以便下次访问)
23、django中的缓存
Django中提供了6种缓存方式:
--开发调试(不加缓存)
--内存
--文件
--数据库
--Memcache缓存(python-memcached模块)
--Memcache缓存(pylibmc模块)
安装第三方组件支持redis:
django-redis组件 设置settings文件
设置缓存:
-全站缓存(中间件)
-视图函数缓存
-局部模板缓存
24、django中的信号
信号:django框架内部为开发者预留下的一些自定制的钩子,只要在某个信号中注册了函数,则django内部执行时会自动触发注册在信号中的函数
Model signals pre_init # django的modal执行其构造方法前,自动触发 post_init # django的modal执行其构造方法后,自动触发 pre_save # django的modal对象保存前,自动触发 post_save # django的modal对象保存后,自动触发 pre_delete # django的modal对象删除前,自动触发 post_delete # django的modal对象删除后,自动触发 m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发 class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发 Management signals pre_migrate # 执行migrate命令前,自动触发 post_migrate # 执行migrate命令后,自动触发 Request/response signals request_started # 请求到来前,自动触发 request_finished # 请求结束后,自动触发 got_request_exception # 请求异常后,自动触发 Test signals setting_changed # 使用test测试修改配置文件时,自动触发 template_rendered # 使用test测试渲染模板时,自动触发 Database Wrappers connection_created # 创建数据库连接时,自动触发
应用场景:数据库中表中的数据发生变化时,日志记录
25、序列化
内置:
from django.core import serializers #queryset = [obj,obj,obj] ret = models.BookType.objects.all() data = serializers.serialize("json", ret)
json:
- json.dumps(ensure_ascii=False) #中文乱码
- json.dumps( cls=JSONEncoder) #自定义JSONEncoder,序列化特殊数据类型
26、admin
对表数据进行增删改查 知识点:单例模式
- 为公司定制更适用于自己的组件: stark组件
27、ContentType
contenttype是django中的一个app,它可以将django下所有app下的表记录下来
一张表可以动态的和N张表进行FK
应用:课程和专题课与间隔策略进行关联
28、django-debug-toolbar的作用
一、查看访问的速度、数据库的行为、cache命中等信息。
二、尤其在Mysql访问等的分析上大有用处(sql查询速度)
29、django中如何实现单元测试?
单元测试(Unittest)文本测试(Doctest)
rest_framework框架
30、restfull规范理解
- restful就是一套编写接口的协议,协议规定了如何规范编写接口以及设置返回值、状态码等信息。 - 最显著的特点: restful: 给定一个url,根据method不同在后端做不同的处理,比如:post 创建数据、get获取数据、put和patch修改数据、delete删除数据。 使用django中的URL: 就必须给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/ - 其他的: - 版本,来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数 - 状态码,200/300/400/500 - url中尽量使用名词,restful也可以称为“面向资源编程” - api标示: api.luffycity.com (专用域名) www.luffycity.com/api/(主域名下,api功能简单时)
- 协议 https - 域名 - www.oldboy.com/api 主域名 - api.oldboy.com 子域名 - 版本: - url:www.oldboy.com/api/v1 - 请求头中也可以加 - URL资源,名词 - www.oldboy.com/api/v1/student - 请求方式: - GET/POST/PUT/DELETE/PATCH/OPTIONS/HEADERS/TRACE - 返回值: - www.oldboy.com/api/v1/student/ -> 结果集 - www.oldboy.com/api/v1/student/1/ -> 单个对象 - URL添加条件 - www.oldboy.com/api/v1/student?page=11&size=9 - 状态码: - 200 - 300 - 301 - 302 - 400 - 403 - 404 - 500 - 错误信息 { code:1000, meg:'xxxx' } - hyperlink { id:1 name: ‘xiangl’, type: http://www.xxx.com/api/v1/type/1/ }
31. 你的restful是怎么学的?
- -因为之前公司要写一个前后端分离的项目
- 所以就通过查看有关restful相关的技术类文档和视频,如: 阮一峰的博客学
32、为什么要使用rest_framework
---rest—framework框架内部帮助我们提供了很多组件,我们只需要通过配置就可以完成相应操作,如: - 序列化,可以做用户请求数据校验+queryset对象的序列化称为json - 解析器,获取用户请求数据request.data,会自动根据content-type请求头的不能对数据进行解析 - 分页,将从数据库获取到的数据在页面进行分页显示。 还有其他: - 认证 - 权限 - 访问频率控制
---也可以使用django的CBV来实现,只是需要编写大量的代码,降低开发效率。
33、认证流程
1、编写:写类并实现authticate()
- 方法中可以定义三种返回值:
-(user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
2、流程:
- 请求进来走dispatch方法,在dispatch方法中,执行initial()中执行perform_authentication(request)方法,
- 在认证中执行request.user
34、频率
- 请求进来走dispatch方法,在dispatch方法中,执行initial()中执行check_throttles(request)方法,
def check_throttles(self, request): """ Check if request should be throttled. Raises an appropriate exception if the request is throttled. """ #遍历throttle对象列表 for throttle in self.get_throttles(): #根据allow_request()的返回值进行下一步操作,返回True的话不执行下面代码,标识不限流,返回False的话执行下面代码,还可以抛出异常 if not throttle.allow_request(request, self): #返回False的话执行 self.throttled(request, throttle.wait())
- 匿名用户,根据用户IP或代理IP作为标识进行记录,为每一个用户在redis中创建一个列表
每个用户再来访问时,需要先去记录中剔除以及过期时间,再根据列表的长度判断是否可以继续访问。 匿名用户IP在防火墙中进行设置
- 注册用户,根据用户名或邮箱进行判断
每个用户再来访问时,需要先去记录列表中剔除过期时间,再根据列表的长度判断是否可以继续访问。
1分钟:40-60次
35、视图中都可以继承哪些类
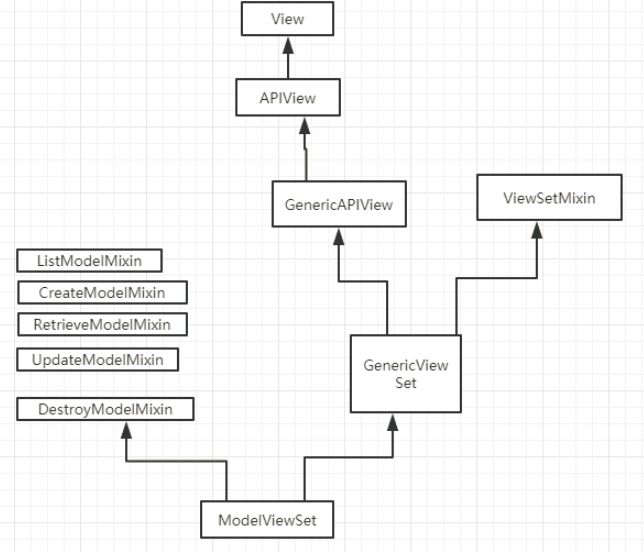
rest-frmawork视图中可以直接继承10种类,外加View(object),可以大致分为三大部分
1、 继承 APIView(View) 次类属于rest framework中原始类,内部只是帮助我们实现了基本功能:认证、权限、频率控制,但凡涉及到数据库、分页等操作都需要手动去完成 2、 继承 GenericViewSet(ViewSetMixin, generics.GenericAPIView)
class GenericAPIView(APIView)
def post(...):
pass
继承此类,路由中的as_view()需要填写对应关系 .as_view({'get':'list','post':'create'}),一般使用此类进行编写,可扩展性强 在内部也帮助我们提供了一些方便的方法: - get_queryset - get_object - get_serializer 注意:要设置queryset字段,否则会跑出断言的异常。 3、 继承 ModelViewSet()
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。此类封装了大量的组件,操作起来简单,但是扩展性较差 示例:如果只提供增加功能,只继承一下类即可
- mixins.CreateModelMixin,GenericViewSet class TestView(mixins.CreateModelMixin,GenericViewSet): serializer_class = XXXXXXX
36、接口的幂等性?
对一个接口通过1次访问之后,再对该接口进行N次相同的访问时,对资源不造影响,那么就认为接口具有幂等性。(主要是第二次访问时是否会造成伤害)
比如:
GET, 第一次获取结果、第二次也是获取结果对资源都不会造成影响,幂等。
POST,第一次新增数据,第二次也会再次新增,非幂等。
PUT, 第一次更新数据,第二次不会再次更新,幂等。
PATCH,第一次更新数据,第二次不会再次更新,非幂等。
DELTE,第一次删除数据,第二次不在再删除,幂等。
37、assert的作用
条件成立,程序继续执行,否则抛异常
应用场景:rest_framework中继承类时,1、定义queryset 2、渲染器使用JSON
flask框架
1、 Flask内置功能依赖
0、基于wsgi协议下werkzurg模块
1、路由 @app.route("/login",method=["GET","POST"])
2、视图 使用FBV
3、session 将签名的session保存到cookie中
4、特殊装饰器(类似于中间件) @before_request @after_request
5、message(闪现) 基于Session(先将数据写入session,在session.pop("xx"))实现的用于保存数据的集合,其特点是:使用一次就删除。
6、模板 使用jinja2
7、Blueprint(蓝图) 1、项目问价目录的划分 2、可以统一划分一类url 3、基于before_request(装饰器)现实一类url的功能
2、Flask第三方组件
flask:
-flask-session 默认放入cookie,可以放入redis
-flask-migrate 数据化迁移
-flask-script 自定义命令
-blinker 信号
公共: DBUtils 数据库连接池
wtforms 表单验证+生成HTML标签
sqlalchemy 类似于django的orm
自定义:Auth 参考falsk-login
3、 threading.local 作用?
为每一个线程开辟一条内存空间,用来存储数据
作用:为每一个线程开辟一块空间进行数据存储 from threading import local from threading import Thread import time # 示例化local对象 ret=local() def task(s): global ret ret.value=s time.sleep(2) print(ret.value) # 开启10个线程 for i in range(10): t=Thread(target=task,args=(i,)) t.start()
4、 Flask上下文管理流程以及和django比较?
简单来说,falsk上下文管理可以分为三个阶段: 1、请求进来时,将请求相关的数据放入上下文管理中 2、视图函数中,去上下文管理中取值,并操作 3、请求响应,保存session,要将上下文管理中的数据清除 详细点来说: 1、请求刚进来,将request,session封装在RequestContext类中,将app,g封装在AppContext类中,并通过LocalStack将requestcontext和appcontext放入Local类中 2、视图函数中,通过localproxy类中调用偏函数--->localstack--->local取值 3、请求响应应时,先执行save.session()再各自执行pop(),将local中的数据清除
threading local和封装
5、Flask中的session是什么时候创建,什么时候销毁的?
1、当请求进来时,会将requset和session封装为一个RequestContext对象,通过LocalStack将RequestContext放入到Local对象中,
2、因为请求第一次来session是空值,所以执行open_session,给session(uuid4())赋值,再通过视图函数处理,
3、请求响应时执行save.session,将签名session写入cookie中,再去Local中的将数值pop掉。
6、Localstack作用
将local对象中的数据维护成一个栈【ctx,ctx】(先进后出) { “协程或线程的唯一标识”: { stack:[ctx,ctx,ctx,] } } 为什么维护成一个栈? 1、当是web应用时:不管是单线程还是多线程,栈中只有一个数据 - 服务端单线程: { 111:{stack: [ctx, ]} } - 服务端多线程: { 111:{stack: [ctx, ]} 112:{stack: [ctx, ]} } 2、离线脚本和多app嵌套时:可以在栈中放入多个数据,在任何情况下都可以获取到当前app请求对应的响应 with app01.app_context(): print(current_app) with app02.app_context(): print(current_app) print(current_app)
7、 Flask中的g的作用?
g 相当于一次请求的全局变量,可以对g进行相应的扩展(将用户的权限赋值给g; 认证,将登陆用户的标识赋值给g)
-请求进来时,将g和app封装为一个APPContext类,在通过LocalStack将Appcontext放入Local中,
-视图函数中,通过localproxy-->偏函数-->LocalStack-->local中取值,
-响应时将local中的g数据删除:
8、 Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
RequestContext
AppContext
LocalStack
Local
LocalProxy
9、 Flask中多app应用是怎么完成?
#对url进行处理和分发 from flask import Flask from werkzeug.wsgi import DispatcherMiddleware from werkzeug.serving import run_simple app01 = Flask('app01') app02 = Flask('app02') @app01.route('/login') def login(): return 'app01.login' @app02.route('/index') def index(): return 'app02.index' # 访问"login"--->"http://localhost:5000/login" # 访问"index"--->"http://localhost:5000/app02/index" dm = DispatcherMiddleware(app01, { '/app02': app02, }) if __name__ == '__main__': run_simple('localhost', 5000, dm)
10、 原生SQL和ORM的区别?
orm关系对象映射
sql语句编写较为复杂,开发效率低,但是查询速度快
orm操作方便,可提高开发效率,相对sql语句查询速度低
11、SQLAlchemy中的 session 的创建有几种方式
1、直接创建session,多线程时需要为每个线程创建session
2、基于scoped_session创建 session = scoped_session(Session) ,多线程时内部会自动为每个线程创建session (好像是threading.local)
12、SQLAlchemy如何执行原生SQL?
13、SQLAchemy中如何为表设置引擎和字符编码?
14、SQLAchemy中如何设置联合唯一索引?
15、解释Flask框架中的Local对象和threading.local对象的区别?
Local中可以使用协程中的唯一标识作为栈中的key,粒度更细
16、Flask中 blinker 是什么?
信号
request_started = _signals.signal('request-started') # 请求到来前执行 request_finished = _signals.signal('request-finished') # 请求结束后执行 before_render_template = _signals.signal('before-render-template') # 模板渲染前执行 template_rendered = _signals.signal('template-rendered') # 模板渲染后执行 got_request_exception = _signals.signal('got-request-exception') # 请求执行出现异常时执行 request_tearing_down = _signals.signal('request-tearing-down') # 请求执行完毕后自动执行(无论成功与否) appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 请求上下文执行完毕后自动执行(无论成功与否) appcontext_pushed = _signals.signal('appcontext-pushed') # 请求上下文push时执行 appcontext_popped = _signals.signal('appcontext-popped') # 请求上下文pop时执行 message_flashed = _signals.signal('message-flashed') # 调用flask在其中添加数据时,自动触发
17、栈
class Stack(object): def __init__(self,size): self.stack=[] self.size=size def isfull(self): """ 判读栈空 :return: """ if len(self.stack)==0: return True else: return False def isempty(self): """ 判断栈满 :return: """ if len(self.stack)==self.size: return False else: return True def top(self,*args): if not self.isempty(): raise Exception("已满") else: self.stack.append(*args) def pop(self): if self.isfull(): raise Exception("已空") else: self.stack.pop() if __name__=="__main__": s=Stack(4) # for i in range(7): # s.top(i) # print(s.stack) for j in range(6): s.pop() print(s.stack)
18、优先级队列
import heapq class PriorityQueue(object): #实现一个优先级队列,每次pop优先级最高的元素 def __init__(self): self.queue = [] self.index = 0 def push(self,item,priority): # 将priority和index结合使用,在priority相同的时候比较index,pop先进入队列的元素 heapq.heappush(self.queue,(priority,self.index,item)) self.index += 1 def pop(self): return heapq.heappop(self.queue)[-1] if __name__ == '__main__': pqueue = PriorityQueue() pqueue.push('d',2) pqueue.push('f',3) pqueue.push('a',6) pqueue.push('s',4) pqueue.push('cao',9) print(pqueue.queue) print(pqueue.pop()) print(pqueue.queue) print(pqueue.pop()) print(pqueue.pop()) print(pqueue.pop())
Tornado框架
1、简述Tornado框架的特点。
异步非阻塞+websocket
2、简述Tornado框架中Future对象的作用?
异步非阻塞本质:装饰器+Futrue
目标:通过一个线程处理N个并发请求。 使用支持tornado异步非阻塞的单独模块: MySQL Redis SQLALchemy Tornado异步非阻塞本质:
视图函数yield一个futrue对象,
futrue对象默认: self._done = False ,请求未完成 self._result = None ,请求完成后返回值,用于传递给回调函数使用。 tornado就会一直去检测futrue对象的_done是否已经变成True。 如果IO请求执行完毕,自动会调用future的set_result方法: self._result = result self._done = True
3、Tornado中静态文件是如何处理的?
如:
static_url()自动去配置的路径下找commons.css文件
4、Tornado操作MySQL使用的模块?
torndb、mysqldb
5、Tornado操作redis使用的模块?
Tornado-redis
6、简述Tornado框架的适用场景
web聊天室,在线投票,处理高并发任务
redis
1、redis
redis它是将数据放在缓存中的,相比将数据放入到硬盘上,他的访问速度更快,并且可以将缓存中的数据定时更新到硬板中,同时增加了数据的安全性,它支持五大数据类型,字符串、数组、哈希、集合、有序集合
2、redis和memcached的区别
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,这样能保证数据的持久性。 2)、数据支持类型 Memcache只支持字符串类型 Redis支持五大数据类型
3)持久化、高可用、分布式
redis支持数据持久化(RDB,AOF)、高可用、分布式
memcached不支持,自己搭建
3、五种数据类型
方法
应用场景:
字符串:rest farmework中的session, open_session.setex() save_session.get()
列表 消息队列、频率、调度器、
哈希 购物车
集合 url去重
有序集合 调度器的有优先级,排行榜
3、用redis做过什么?
-购物车信息(商品设置超时时间)
-django-session
-rest frmawork 中的访问频率
-基于flask的websocket做的实时投票,使用redis做消息队列
-scrapy框架
-URL去重 set()
-调度器 先进先出、后进先出、优先级
-pipelines 类似于生产者消费者模型
-起始url 将起始url放入缓存中
-商品的热点信息
-计数器 将修改的数据放入redis中再定时更新到数据库中
-排序 有序集合
4、redis中数据库默认是多少个db 及作用?
0-15个库,默认的db0单库
5、python操作redis模块
CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100} # "PASSWORD": "密码", } }, } SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎 SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置
5、为什么redis要做主从复制?
目的:是对redis做高可用,为每一个redis实例创建一个备份称为slave,主redis进行写操作,从redis做读操作,并且让主和从之间进行数据同步,
优点:
- 性能提高,从分担了主的压力。保证了数据的安全性
- 高可用,一旦主redis挂了,直接让从代替主。
存在问题:当主挂了之后,需要人为操作将从变成主。
数据同步机制:
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。
redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
6、redis的sentinel是什么?
1、自动在主从redis之间进行切换
2、检测主从中 主是否挂掉,且超过一半的sentinel检测到主挂掉之后才进行切换将从redis变为主redis。
3、如果主修复好了,再次启动时候,会变成从。
7、redis的cluster是什么?
集群方案: - redis cluster 官方提供的集群方案。 - codis,豌豆荚技术团队。 - twemproxy,Twiter技术团队。
-程序 (一致性哈希 hash-ring) redis cluster的原理? - 基于分布式集群来完成。(不同任务交给不同的redis处理) - redis将所有能放置数据的地方创建了 16384 个哈希槽。 - 如果设置集群的话,就可以为每个实例分配哈希槽: - 192.168.1.20【0-5000】 - 192.168.1.21【5001-10000】 - 192.168.1.22【10001-16384】 - 以后想要在redis中写值时, set k1 123 将k1通过crc16的算法,将k1转换成一个数字。然后再将该数字和16384求余,如果得到的余数 3000,那么就将该值写入到 192.168.1.20 实例中。
8、什么是codis和twemproxy及作用?
实现redis分布式集群
9、什么是一致性哈希?Python中是否有相应模块?
一致性哈希:是一种分布式算法,将任务均匀的分布到不同的服务器上,常用于负载均衡,
hash_ring 将key利用crc32------>数字------>数字和服务器数取余-------->放入服务器对应的数值区间
10、redis是否可以做持久化?
RDB持久化 -每隔一段时间对redis进行一次持久化(基于时间点快照的方式,复用方式进行数据持久化) -效率较高,数据不完整,安全性不高 AOF持久化
-把所有命令保存起来,如果想到重新生成到redis,那么就要把命令重新执行一次。
-效率相对较低,安全性较高
11、redis的过期策略
.1、MySQL ⾥里里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据
voltile-lru: 从已设置过期时间的数据集(server.db[i].expires)中挑选最近频率最少数据淘汰 volatile-ttl: 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 allkeys-lru: 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 allkeys-random: 从数据集(server.db[i].dict)中任意选择数据淘汰 no-enviction(驱逐):禁止驱逐数据
12、redis的分布式锁实现。
单太redis时,可以使用watch
对多台redis进行操作时,加锁并设置超时时间,保证在此期间只有你一个人对redis操作,
----流程
- 写值{key:"sfdfff"}加锁并设置超时时间 - 超过一半的redis实例设置成功,就表示加锁完成。
-解锁 执行lua脚本,用key检测每个redis中是否有次key,有则删除
- 使用:安装redlock-py from redlock import Redlock Redlock算法 dlm = Redlock( [ {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, ] ) # 加锁,acquire my_lock = dlm.lock("my_resource_name",10000) if my_lock: # J进行操作 # 解锁,release dlm.unlock(my_lock) else: print('获取锁失败')
13、检测数据:watch
监听一个数据,下次提交时,如果中间有人对此数据修改,则会报错
- 通过redis的watch实现 import redis conn = redis.Redis(host='127.0.0.1',port=6379) # conn.set('count',1000) val = conn.get('count') print(val) with conn.pipeline(transaction=True) as pipe: # 先监视,自己的值没有被修改过 conn.watch('count') # 事务开始 pipe.multi() old_count = conn.get('count') count = int(old_count) print('现在剩余的商品有:%s',count) input("问媳妇让不让买?") pipe.set('count', count - 1) # 执行,把所有命令一次性推送过去 pipe.execute()
14、事务
将一部分执行命令进行批量操作,
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) conn = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = conn.pipeline(transaction=True) # 开始事务 pipe.multi() pipe.set('name', 'alex') pipe.set('role', 'sb') pipe.lpush('roless', 'sb') # 提交 pipe.execute()
15、发布者与订阅者、消息队列
发布者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) conn.publish('104.9MH', "hahahahahaha") 订阅者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) pub = conn.pubsub() pub.subscribe('104.9MH') while True: msg= pub.parse_response() print(msg)
发布订阅:只要发布者发布任务则所有订阅者都会接受到此任务。
消息队列:队列中放一个任务,则只有一个进程取任务
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。
所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
16、如何基于redis实现消息队列?
在线投票
17、写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列
import heapq class PriorityQueue(object): """实现一个优先级队列,每次pop优先级最高的元素""" def __init__(self): self._queue = [] self._index = 0 def push(self,item,priority): # 将priority和index结合使用,在priority相同的时候比较index,pop先进入队列的元素 heapq.heappush(self._queue,(-priority,self._index,item)) self._index += 1 def pop(self): return heapq.heappop(self._queue)[-1] if __name__ == '__main__': pqueue = PriorityQueue() pqueue.push('d',2) pqueue.push('f',3) pqueue.push('a',6) pqueue.push('s',2) print(pqueue.pop()) print(pqueue.pop()) print(pqueue.pop()) print(pqueue.pop())
18、如果一个字典在redis中保存了10w个值,我需要将所有值全部循环并显示,请问如何实现?
def list_scan_iter(name,count=3): start = 0 while True: result = conn.lrange(name, start, start+count-1) start += count if not result: break for item in result: yield item for val in list_scan_iter('num_list'): print(val)
列表、集合、有序集合使用scan_iter
19、如何高效的找到redis中所有以oldboy开头的key?
keys(pattern="*") # 根据模型获取redis的name # 更多: # KEYS * 匹配数据库中所有 key 。 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
Http协议
1、Http协议
1、Http协议是基于tcp协议之上的短连接、无状态请求,规定数据之间\r\n分割,请求头与请求体\r\n\r\n分割
2、请求头:Host Content-Type User_Agent method referer Date cookie
3、状态码
成功 200 成功 202 服务器已接受请求,但尚未处理 重定向: 301 永久重定向 302 临时重定向 客户端: 400 客户端请求有语法错误,不能被服务器所理解 401 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 服务器收到请求,但是拒绝提供服务 404 请求资源不存在,eg:输入了错误的URL 服务器: 500 服务器发生不可预期的错误 503 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
4、请求方式
1 GET 请求指定的页面信息,并返回实体主体。 2 HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 5 DELETE 请求服务器删除指定的页面。 6 CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 7 OPTIONS 允许客户端查看服务器的性能。 8 TRACE 回显服务器收到的请求,主要用于测试或诊断。
2、 HTTPS
Http: 80端
https: 443端口
- 自定义证书
- 服务端:创建一对证书
- 客户端:必须携带证书
- 购买证书
- 服务端: 创建一对证书,-将公钥交给机构
- 客户端: 去机构获取证书,数据加密后发给咱们的服务单
3、什么是websocket
1、websocket协议是基于http的协议之上的,只是客户端与服务端建立连接之后将不再断开,实现服务端向客户端主动发送请求
-进行数据通信前先进行校验(握手)
-发送的数据都是加密的
2、websocket本质
-
首先,客户端发起 http请求,经过3次握手后,建立起TCP连接;http请求里存放WebSocket支持的版本号等信息,如:Upgrade、Connection、WebSocket-Version等;
-
然后,服务器收到客户端的握手请求后,同样采用HTTP协议回馈数据;
-
最后,客户端收到连接成功的消息后,开始借助于TCP传输信道进行全双工通信。
1、创建一个建立连接之后不断开的socket 2、创建连接(握手) -客户端向服务端发送请求 -服务端获取请求头中的Sec-WebSocket-key的值,将此值+magic_string(魔法字符串)进行hashlib和base64加密 -构造响应头,里面包含Sec-WebSocket-Accept: 加密后的值 -返送给客户端 -客户端再拿到加密的数据,解密进行验证 3、连接建立成功后:建立双工通道(同一时间,即可发送数据也可接受数据),进行数据通信 -发送的数据都是加密的,解密后,根据payload_len的值获取内容(payload_len的值相当于报头) -payload_len <=125 -payload_len ==126 -payload_len ==127 -将获取的内容分为 -mask_key -数据 根据mask_key和数据进行位运算,最后解析出数据
3、websocket的应用----可是实现客户端实时监听服务端的数据变化的操作
如:实时消息推送
- 轮询 优点:代码简单; 缺点:请求次数多,服务器压力大,消息延迟。 - 长轮询 优点:实时接收数据,兼容性好; 缺点:请求次数相对轮询减少。 - websocket 优点:代码简单,不再反复创建连接。 缺点:兼容性差,不支持IE。
4、websocket与http协议的联系 ?
相同点:
1、websocket和http都是基于TCP协议的
2、都是属于应用层的
不同点:
-
WebSocket是双向通信协议,模拟Socket协议,可以双向发送或接受信息。HTTP是单向的。
-
WebSocket是需要浏览器和服务器握手进行建立连接的。而http是浏览器发起向服务器的连接,服务器预先并不知道这个连接。
联系:
1、WebSocket在建立握手时,数据是通过HTTP传输的。但是建立之后,在真正传输时候是不需要HTTP协议的。
5、三大框架如何实现websocket
- django: channel
- flask: gevent-websocket
- tornado: 内置
6、轮询与长轮询
1、轮询
通过定时器让客户端每隔几秒就向服务端发送一次请求
2、长轮询
客户端向服务端发送一次请求,浏览器会将次请求夯住一段时间,如果有数据返回则立即响应,如果在此时间内没有数据返回则断开连接,客户端再次发送请求
ps:利用queue和redis实现夯住请求
3、轮询的目的
因为http请求是短连接无状态的,服务端无法实时向客户端发送请求
所以客户端可以利用轮询和长轮询向服务端实时发送请求
7、如何创建响应式布局?
一个网站可以兼容多个终端(根据分辨率不同自动匹配)
@media (min-width: 768px){ .pg-header{ background-color: green; } } @media (min-width: 992px){ .pg-header{ background-color: pink; } }
8、你曾经使用过哪些前端框架?
Jquery
BootStrap
vue.js Angular.js React.js
9、什么是ajax请求?并使用jQuery和XMLHttpRequest对象实现一个ajax请求。
ajax:异步请求+局部刷新
jquery:$.ajax()
xml : var xmlHttp = new XMLHttpRequest()
10、vuex的作用?
vuex维护了一个“全局变量" 基于vue_cookies可以做用户登录、注销
使用Vuex只需执行 Vue.use(Vuex),并在Vue的配置中传入一个store对象的示例(vue.store)
10、vue中的路由(router)的拦截器的作用?
可以做权限
11、axios的作用?
类似于ajax
12、列举vue的常见指令。
v-html 插入html
v-text 在元素中插入值
v-if v-else
v-show
v-for
v-on 监听
v-bind 绑定
v-model 把input的值和变量绑定了,实现了数据和视图的双向绑定
13、简述jsonp及实现原理?
自定义一个script标签,调用回调函数, 后端返回一个函数()
jsop只能get请求
14、是什么cors ?
添加响应头
Git
1、git常见命令作用:
https://www.cnblogs.com/caochao-/articles/8823080.html
2、简述以下git中stash命令作用以及相关其他命令。
3、git 中 merge 和 rebase命令 的区别。
merge:会将不同分支的提交合并成一个新的节点,之前的提交分开显示,注重历史信息、可以看出每个分支信息,基于时间点 , 遇到冲突,手动解决,再次提交
rebase:将两个分支的提交结果融合成线性,不会产生新的节点,注重开发过程, 遇到冲突,手动解决,继续操作
参考
4、公司如何基于git做的协同开发?
1、你们公司的代码review分支怎么做?谁来做? 答:组长创建review分支,我们小功能开发完之后,合并到review分支 交给老大(小组长)来看, 你组长不开发代码吗? 他开发代码,但是它只开发核心的东西,任务比较少。 或者抽出时间,我们一起做这个事情 2、你们公司协同开发是怎么协同开发的? 每个人都有自己的分支,阶段性代码完成之后,合并到review,然后交给老大看
6、git如何实现v1.0 、v2.0 等版本的管理?
在命令行中,使用“git tag –a tagname –m “comment”可以快速创建一个标签。需要注意,命令行创建的标签只存在本地Git库中,还需要使用Git push –tags指令发布到TFS服务器的Git库中
参考
7、什么是gitlab?
gitlab是公司自己搭建的项目代码管理平台
8、github和gitlab的区别?
gitHub是一个面向开源及私有软件项目的托管平台
gitlab是公司自己搭建的项目托管平台
9、如何为github上牛逼的开源项目贡献代码?
10、git中 ".gitignore"文件的作用?
设置哪些文件不需要添加到版本管理中 (比如Python的.pyc文件和一些包含密码的配置文件等)
11、什么是敏捷开发?
敏捷开发:是一种以人为核心、迭代、循序渐进的开发方式。
它并不是一门技术,而是一种开发方式,也就是一种软件开发的流程。它会指导我们用规定的环节去一步一步完成项目的开发。因为它采用的是迭代式开发,所以这种开发方式的主要驱动核心是人
12、简述 jenkins 工具的作用?
Jenkins 是一个可扩展的持续集成引擎。
主要用于:
- 持续、自动地构建/测试软件项目。
- 监控一些定时执行的任务。
13、公司如何实现代码发布?
nginx+uwsgi+django
参考
14、简述 RabbitMQ、Kafka、ZeroMQ的区别?
参考
15、RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
参考
为了预防消息丢失,rabbitmq提供了ack,即工作进程在收到消息并处理后,发送ack给rabbitmq,告知rabbitmq这时候可以把该消息从队列中删除了。如果工作进程挂掉 了,rabbitmq没有收到ack,那么会把该消息 重新分发给其他工作进程。不需要设置timeout,即使该任务需要很长时间也可以处理。
ack默认是开启的,工作进程显示指定了no_ack=True
16、RabbitMQ如何对消息做持久化?
1、创建队列和发送消息时将设置durable=Ture,如果在接收到消息还没有存储时,消息也有可能丢失,就必须配置publisher confirm
channel.queue_declare(queue='task_queue', durable=True)
2、返回一个ack,进程收到消息并处理完任务后,发给rabbitmq一个ack表示任务已经完成,可以删除该任务
3、镜像队列:将queue镜像到cluster中其他的节点之上。在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性
17、RabbitMQ如何控制消息被消费的顺序?
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2 去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列(同时也保证了公平的消费分发)
18、以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic。
amqp协议中的核心思想就是生产者和消费者隔离,生产者从不直接将消息发送给队列。
生产者通常不知道是否一个消息会被发送到队列中,只是将消息发送到一个交换机。
先由Exchange来接收,然后Exchange按照特定的策略转发到Queue进行存储。
同理,消费者也是如此。Exchange 就类似于一个交换机,转发各个消息分发到相应的队列中。
type=fanout 类似发布者订阅者模式,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中
type=direct 队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
type=topic 队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
发送者路由值 队列中 old.boy.python old.* -- 不匹配 *表示匹配一个 old.boy.python old.# -- 匹配 #表示匹配0个或多个
19、简述 celery 是什么以及应用场景?
celery是python开发的一个分布式任务队列模块,本身本不支持消息传递,依赖于redis、rabbitmq(官方推荐)
1、当用户触发一个操作需要较长时间才能执行完成的任务时,就可以交给Celery异步执行,执行完再返回给用户。这段时间用户不需要等待,提高了网站的整体吞吐量和响应时间。
2、定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
20、简述celery运行机制。
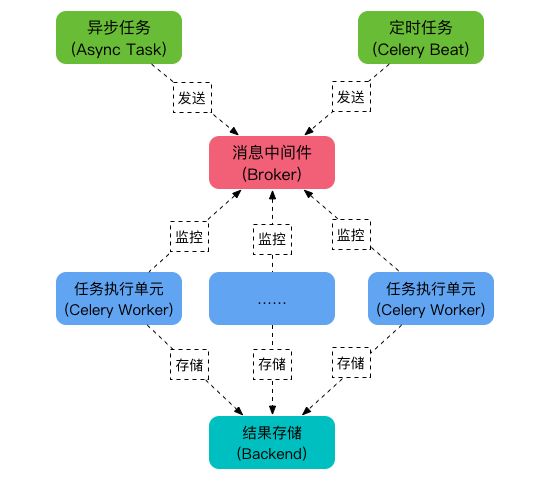
任务模块 Task
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
消息中间件 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
任务执行单元 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, redis 和 MongoDB 等。
21、celery如何实现定时任务?
1、配置文件,设置beat_schedule
2、程序控制 通过 crontab 的对象
参考
22、简述 celery多任务结构目录?
参考
23、celery中装饰器 @app.task 和 @shared_task的区别?
@shared_task为所有的celery对象,创建任务
@app.task为单个celery对象创建任务
scrapy框架
1、简述 requests模块的作用及基本使用?
获取网站html或xml文本
2、简述 beautifulsoup模块的作用及基本使用?
将html或xml标签进行解析
参考
3、简述 seleninu模块的作用及基本使用?
Selenium 是一个用于Web应用程序测试的工具,他的测试直接运行在浏览器上,模拟真实用户,按照代码做出点击、输入、打开等操作
爬虫中使用他是为了解决requests无法解决javascript动态问题
参考
4、scrapy框架中各组件的工作流程?
参考
5、在scrapy框架中如何设置代理(两种方法)?
6、scrapy框架中如何实现大文件的下载?
7、scrapy中如何实现限速?
8、scrapy中如何实现暂定爬虫?
9、scrapy中如何进行自定制命令?
10、scrapy中如何实现的记录爬虫的深度?
11、scrapy中的pipelines工作原理?
爬虫spiders中 yield item
12、scrapy的pipelines如何丢弃一个item对象?
raise DropItem()
13、简述scrapy中爬虫中间件和下载中间件的作用?
14、scrapy-redis组件的作用?
实现了分布式爬虫,有url去重、调度器、数据持久化
15、scrapy-redis组件中如何实现的任务的去重?
16、scrapy-redis的调度器如何实现任务的深度优先和广度优先?
广度优先:先进先出(默认)有序集合
深度优先:先进后出
17、简述 vitualenv 及应用场景?
vitualenv 是一个独立的python虚拟环境
如:当前项目依赖的是一个版本,但是另一个项目依赖的是另一个版本,这样就会造成依赖冲突,而virtualenv就是解决这种情况的,virtualenv通过创建一个虚拟化的python运行环境,将我们所需的依赖安装进去的,不同项目之间相互不干扰
参考
18、简述 pipreqs 及应用场景?
可以通过对项目目录扫描,自动发现使用了那些类库,并且自动生成依赖清单。
pipreqs ./ 生成requirements.txt
杂七杂八
1、在Python中使用过什么代码检查工具?
pylint
2、简述 saltstack、ansible、fabric、puppet工具的作用?
3、B Tree和B+ Tree的区别?
4、请列举常见排序并通过代码实现任意三种。
选择、插入、
5、请列举常见查找并通过代码实现任意三种。
6、请列举你熟悉的设计模式?
7、有没有刷过leetcode?
没有
8、列举熟悉的的Linux命令。
点击
9、公司线上服务器是什么系统?
公司开发环境: 1. windows - 在windows上开发【坑】 - 代码部署在linux :centos 2. 双系统 - windows - linux: ubuntu+桌面版 - linux: centos+桌面版 - 代码部署在linux :centos 3. mac - linux:mac - 代码部署在linux :centos 4. vim开发 - 通过vim在:centos - 代码部署在linux :centos
10、解释 PV、UV 的含义?
PV:访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。
UV:独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客
11、解释 QPS的含义?
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量
TPS:是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
12、supervisor的作用?
Supervisor是一个进程管理工具
用途就是有一个进程需要每时每刻不断的跑,但是这个进程又有可能由于各种原因有可能中断。当进程中断的时候我希望能自动重新启动它,此时,用到Supervisor的fork/exec的方式
13、简述SSH的整个过程。
将传输的数据加密并压缩,客户端提供了口令验证和密钥验证
14、有问题都去那些找解决方案?
stackoverflow
git
知乎
思否
bing
15、是否有关注什么技术类的公众号?
python之禅
码农翻身
django官方文档
rabbiitMQ官方文档
django rest framework 官方文档
16、最近在研究什么新技术?
opentack
docker
人工智能API,实现小功能。智能语音
区块链