前言
继上一部丧尸佳作《釜山行》,最近韩国又推出一部丧尸题材电影《活着》,引起网友的热烈关注,据说和《釜山行》不相上下,作为丧尸题材的忠实影迷,小编想看一下《活着》这部电影的影评,来衡量是否真值得观看!

PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取
可以免费领取源码、项目实战视频、PDF文件等
01-代码实现用户登录
本来小编打算爬取豆瓣电影官网的“已看”用户的全部热门影评,但是未登录的情况下只能爬取前200条数据,于是要用代码实现豆瓣登录:
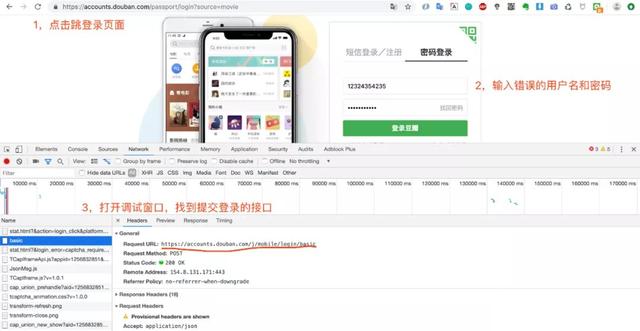
https://accounts.douban.com/j/mobile/login/basic
是我们需要的登录网址,接下来就来实现豆瓣用户登录:
# 导入包 import random import requests import re import os import time import jieba from PIL import Image import numpy as np from wordcloud import WordCloud, STOPWORDS import matplotlib.pyplot as plt # 不同的代理IP,代理ip的类型必须和请求url的协议头保持一致 proxy_list = [ {"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'} ] # 随机获取代理IP proxy = random.choice(proxy_list) # 生成Session对象,用于保存cookie,保存会话状态 s = requests.Session() def login_douban(): """ 登录豆瓣 :return: """ # 登录的url login_url = 'https://accounts.douban.com/j/mobile/login/basic' # 请求头 headers = {'User-Agent': 'Mozilla/5.0', 'Referer': 'https://accounts.douban.com/passport/login?source=movie'} #用户名密码 data = {'name': '你的用户名', 'password': '你的密码', 'remember': 'false'} # 不记住密码 try: r = s.post(login_url, headers=headers, data=data, proxies=proxy) r.raise_for_status() return True except: print("登录失败!") # 打印请求结果 print(r.text)
实现豆瓣用户登录
注意:这里需要提供一个IP代理池列表proxy_list,以防爬取一半IP被禁(小编“深受其害”)
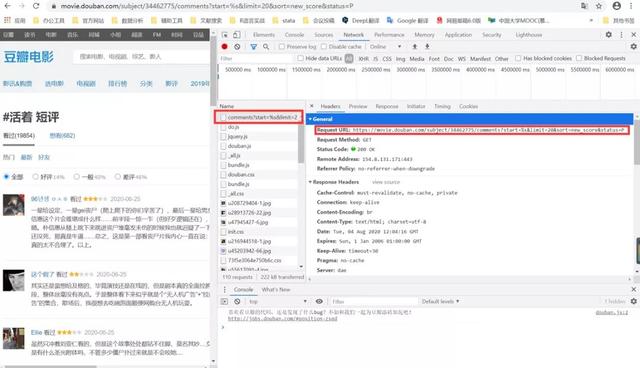
02-找到影评接口,爬取数据
打开开发者工具看下网页源代码,找到影评接口,如下:
https://movie.douban.com/subject/34462775/comments?start=%s&limit=20&sort=new_score&status=P
其中34462775是该电影的专属id,start代表页面起始页。此文只为做影评分析演示,小编只爬取了截止2020/8/4日晚8点前500页的热门评论。

影评数据接口
发现每一页影评的不同在于“start=?”的起始数字不一样,第二页的数字为start=20,于是我们可以开始爬取数据了。
COMMENT_FILE_PATH = 'huozhe.txt' def spider_comment(start): """ 简单爬取 :param start: 0 :return: 20 """ comment_url = "https://movie.douban.com/subject/34462775/comments?start=%s&limit=20&sort=new_score&status=P" % str(start) headers = {'User-Agent': 'Mozilla/5.0'} try: r = s.get(comment_url, headers=headers) r.raise_for_status() except: print("数据请求失败,start=" + str(start)) # 爬取 comments = re.findall('(.*)', r.text) # 写入数据 with open(COMMENT_FILE_PATH, 'a+', encoding=r.encoding) as file: file.writelines('\n'.join(comments)) def batch_spider_comment(): """ 批量爬取数据 :return: 《活着》所有影评 """ # 写入数据前清空之前的数据 if os.path.exists(COMMENT_FILE_PATH): os.remove(COMMENT_FILE_PATH) page = 0 while page <= 500: # 所有热门评论为19826条,截止2020/8/4,每页显示20条,这里规定页数,只爬取一半的数据 spider_comment(page) print("爬取第" + str(page) + "页") page += 1 # 模拟用户浏览,防止被禁IP time.sleep(random.random()*3) print("爬取完毕") # 调用 if __name__ == '__main__': if login_douban(): batch_spider_comment()
批量爬取数据
爬取完的数据存储在“huozhe.txt”文件~内容如下:

爬取的影评文本结果
03-词云分析
为了分析短评,我们采用jieba对短评进行了分词,然后做出词云图。
def cut_word(): """ 对影评分词 :return:分词后的数据 """ with open(COMMENT_FILE_PATH, encoding='utf-8') as file: comment_txt = file.read() wordlist = jieba.cut(comment_txt, cut_all=True) wl = " ".join(wordlist) print(wl) return wl WC_MASK_IMG = 'wc_mask.jpg' #词云背景模板 def create_word_cloud(): """ 生成词云 :return: """ # 设置词云形状图片 wc_mask = np.array(Image.open(WC_MASK_IMG)) # 数据清洗列表 stop_words = ['女主角', '主角', '直升机', '直升', '升机', '哈哈哈', '哈哈', '哈哈哈哈', '无人机', '无人', '什么', '就是', '不是', '但是', '还是', '只是', '这样', '这个', '虽然', '而且'] with open("wcstopwords.txt", "r", encoding="utf-8") as f_stopwords: # 这里从网上下载的stopword词库存储在wcstopwords.txt,读取 for word in f_stopwords: stop_words.append(word.replace("\n", "")) # 设置词云的一些配置 wc = WordCloud(background_color='white', max_words=80, mask=wc_mask, max_font_size=50, min_font_size=5, scale=2, random_state=42, stopwords=stop_words, font_path='PingFang Regular.ttf') # 词云字体 # 生成词云 wc.generate(cut_word()) wc.to_file('doubanhuozhe.png') plt.imshow(wc, interpolation='bilinear') plt.axis("off") plt.figure() plt.show() # 调用 if __name__ == '__main__': create_word_cloud()
分词并可视化词云
词云结果图如下:

直观来看,和《釜山行》一样,《活着》这部电影是关于韩国丧尸题材、逃生的剧情,有好评(“演技在线”)也有差评(“莫名其妙”),但明显差评居多。总体来说,本部影片并没有什么亮点,两位知名演员或许吸引了一部分热度,实力和演技观众也给予肯定,就剧情而言单薄了许多,看来不值得去看。
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:田妍