Netty源码阅读之编码器简析
上回主要聊了一下Netty中的解码器,那么既然有解码,也必须得聊下编码过程了,下面将对Netty中的编码器作一下总结:
1.编码器简介
作为解码的逆过程,编码的目的主要是将消息转换为字节或者消息,Netty中主要使用了MessageToByteEncoder这个抽象类来规定处理编码的一些流程,不妨先来看下该类的UML:
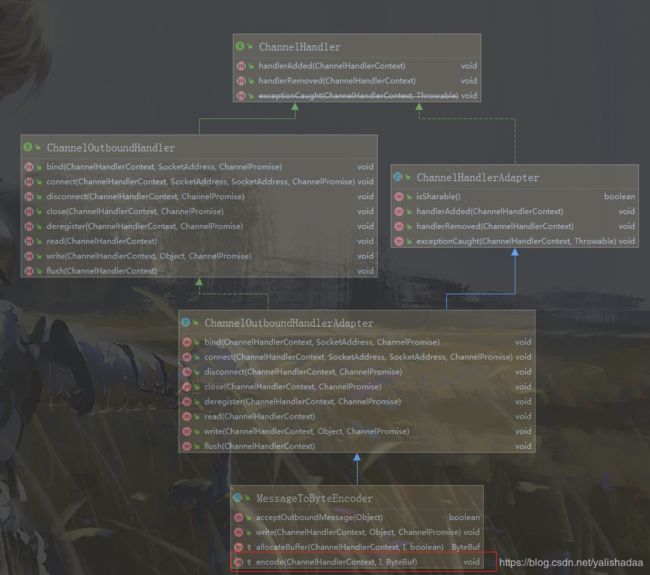
可以看出编码器其实也只是一类特殊的ChannelHandler,使用encode()方法来处理编码相关的逻辑,不妨先自定义一个编码器然后写一段demo:
1.1 自定义编码器实现:
public class MyEncoder extends MessageToByteEncoder {
@Override
protected void encode(ChannelHandlerContext ctx, Packet msg, ByteBuf out) throws Exception {
out.writeInt(msg.getLength());
out.writeBytes(new StringBuilder(msg.getIpAddress())
.append(msg.getRoteName()).toString().getBytes());
}
} 1.2 自定义Handler:
public class PacketHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
Packet packet = new Packet("route01","172.159.1.12");
ctx.writeAndFlush(packet);
}
}public final class Server {
public static void main(String[] args) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new PacketEncoder());
ch.pipeline().addLast(new PacketHandler());
}
});
ChannelFuture f = b.bind(8099).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
} 1.3 对应的流程图:

2.writeAndFlush()流程解析
在自定义Handler传输数据的时候,我们通常会调用ctx.writeAndFlush(msg)方法从tail节点开始一直往前传递到对应的解码器中(见上图),查看其源代码:
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
if (msg == null) {
throw new NullPointerException("msg");
}
if (!validatePromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return promise;
}
write(msg, true, promise);
return promise;
}主要关注一下write()方法:
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}若flush为true,那么调用next.invokeWriteAndFlush(m, promise)方法,反之则调用next.invokeWrite(m, promise)方法,这两个方法又有什么区别呢?我们继续往下查看:
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}这边同时进行了write以及flash的操作,在看下invokeWrite()方法:
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}这里主要缺少了flush的操作。
3.write()方法简要分析
在MessageToByteEncoder`这个类中,主要是需要关注一下write()方法,在编码器中主要是通过这个类将数据存放到对应的ByteBuf中
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (acceptOutboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
buf = allocateBuffer(ctx, cast, preferDirect);
try {
encode(ctx, cast, buf);
} finally {
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
ctx.write(buf, promise);
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
if (buf != null) {
buf.release();
}
}
}上边的代码主要是以下的几个流程,首先调用acceptOutboundMessage()方法来匹配当前的对象,如果当前的节点能够处理,那么继续往下,反之则返回给其他的节点进行处理;若继续往下执行,则进行内存的分配,随后调用encode()方法进行编码,接下来调用ReferenceCountUtil工具进行对象的释放,再继续往下传播数据,最后进行内存的释放。
4. buffer队列机制简介
经过前面的流程分析,可知如果当前节点无法处理会一直往前传递write事件,但如果一直传递到头结点都处理不了将怎么办呢?
Netty使用了一个buffer队列的机制解决了这个问题:
来看下AbstractChannel中的write()方法:
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
// If the outboundBuffer is null we know the channel was closed and so
// need to fail the future right away. If it is not null the handling of the rest
// will be done in flush0()
// See https://github.com/netty/netty/issues/2362
safeSetFailure(promise, WRITE_CLOSED_CHANNEL_EXCEPTION);
// release message now to prevent resource-leak
ReferenceCountUtil.release(msg);
return;
}
int size;
try {
msg = filterOutboundMessage(msg);
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
outboundBuffer.addMessage(msg, size, promise);
}找到io.netty.channel.nio.AbstractNioByteChannel#filterOutboundMessage这个方法:
protected final Object filterOutboundMessage(Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
if (buf.isDirect()) {
return msg;
}
return newDirectBuffer(buf);
}
if (msg instanceof FileRegion) {
return msg;
}
throw new UnsupportedOperationException(
"unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES);
}通过这个方法将ByteBuf对象(即 msg参数)转换为转为堆外内存,随后通过调用outboundBuffer.addMessage()方法将对外内存插入到写缓冲队列中:
public void addMessage(Object msg, int size, ChannelPromise promise) {
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
if (tailEntry == null) {
flushedEntry = null;
tailEntry = entry;
} else {
Entry tail = tailEntry;
tail.next = entry;
tailEntry = entry;
}
if (unflushedEntry == null) {
unflushedEntry = entry;
}
// increment pending bytes after adding message to the unflushed arrays.
// See https://github.com/netty/netty/issues/1619
incrementPendingOutboundBytes(size, false);
}这里维护了一个单项链表的结构,会不断的新传递过来的ByteBuf插入到链表尾部。
随后将调用incrementPendingOutboundBytes()这个函数设置写状态,其中channel.config().getWriteBufferHighWaterMark()默认被定义为64字节。
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
}
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
setUnwritable(invokeLater);
}
}
上边只是将数据更新到了缓冲队列中,但是暂时还没有通过socket传递出去,这部分的流程主要是在缓冲队列的刷新流程中体现io.netty.channel.ChannelOutboundBuffer#addFlush:
private Entry flushedEntry;//标记已经flush的指针
private Entry unflushedEntry;//标记未flush的指针
private Entry tailEntry;//标记尾结点的指针
public void addFlush() {
// There is no need to process all entries if there was already a flush before and no new messages
// where added in the meantime.
//
// See https://github.com/netty/netty/issues/2577
Entry entry = unflushedEntry;
if (entry != null) {
if (flushedEntry == null) {
// there is no flushedEntry yet, so start with the entry
flushedEntry = entry;
}
do {
flushed ++;
if (!entry.promise.setUncancellable()) {
// Was cancelled so make sure we free up memory and notify about the freed bytes
int pending = entry.cancel();
decrementPendingOutboundBytes(pending, false, true);
}
entry = entry.next;
} while (entry != null);
// All flushed so reset unflushedEntry
unflushedEntry = null;
}
}
首先是刷新标志并设置为写状态,之后通过调用io.netty.channel.nio.AbstractNioByteChannel#doWrite()方法遍历缓冲队列,过滤ByteBuf,最后调用jdk自旋锁自旋写数据到socket中,这边的自旋次数设置为16次:
private volatile int writeSpinCount = 16;5. 总结
至此,关于Netty的编码流程分析完毕,周日快乐~