ElasticSearch入门(1)——了解ES
ElasticSearch入门(1)——了解ES
文章目录
- ElasticSearch入门(1)——了解ES
- 1. Lucene
- 2. ElasticSearch
- 1. ES开启跨域
- 2. 索引 - index
- 3. 类型 - type
- 4. 文档 - document
- 5. 分片 - shared
- 6. 集群 - cluster
- 7. 节点 - Node
- 3. IK分词器
- 1. ik_smart - 最少切分
- 2. ik_max_word - 最细粒度划分
- 3. 增加自定义字典
- 4. 请求方式
- 1. PUT
- 2. GET
- 3. POST
- 5. 倒排索引
- 1. 定义
- 2. 概念
- 1. 单词 - Term
- 2. 单词字典 - Term Dictionary
- 3. 单词索引 - Term Index
- 4. 倒排列表 - Posting List
- 3. 类比MyISAM
1. Lucene
了解ES之前,首先要了解Lucene。Lucene是一套信息检索工具包,jar包,不包含搜索引擎系统。而ElasticSearch 是基于 Lucene 做了一些封装和增强。
Lucene定义:
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
2. ElasticSearch
ElasticSearch定义:
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
启动ES
1. ES开启跨域
yml中添加:
http.cors.enabled : true
http.cors.allow-origin : “*”
2. 索引 - index
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。
3. 类型 - type
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。
4. 文档 - document
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
5. 分片 - shared
简单来讲就是咱们在ES中所有数据的文件块,也是数据的最小单元块,整个ES集群的核心就是对所有分片的分布、索引、负载、路由等达到惊人的速度
注意: 索引建立后,分片个数是不可以更改的
6. 集群 - cluster
一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力
7. 节点 - Node
一个运行中的 Elasticsearch 实例称为一个节点。
ES集群中的节点有三种不同的类型:
主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
3. IK分词器
查看不同的分词器
1. ik_smart - 最少切分
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
}
]
}
2. ik_max_word - 最细粒度划分
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "国共",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "共产党",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "共产",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "党",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 5
}
]
}
3. 增加自定义字典
- ik分词器config包下的
IKAnalyzer.cfg.xml增加配置 - config包下写xxx.dic,和xml文件中配置的名字相同
- 在xxx.dic中写字典词
GET _analyze
{
"analyzer": "ik_smart"
, "text": "狂神说"
}
{
"tokens" : [
{
"token" : "狂神说",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
}
]
}
4. 请求方式
| method | url | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
1. PUT

- _index:索引
- _type:类型
- _id:文档id
- _version:版本
- result:当前状态
- _shards:
指定数据类型

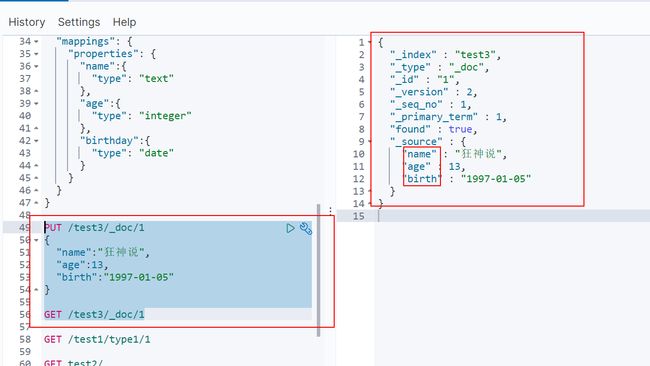
2. GET
获取索引信息
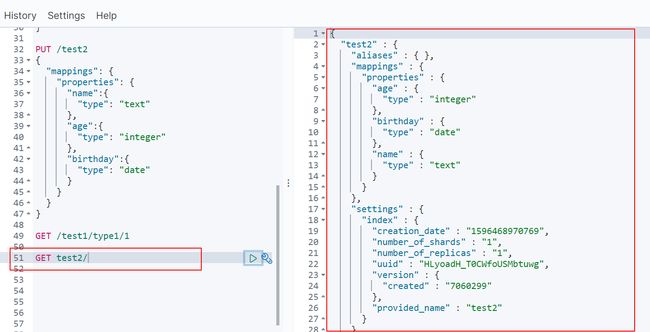
获取索引情况
# GET -cat 可以获得很多信息
GET _cat/indices?v

3. POST
数据修改
- PUT直接暴力覆盖
- POST更新

所有的请求都是基于RESTFUL风格实现的
5. 倒排索引
推荐:https://www.cnblogs.com/cjsblog/p/10327673.html
1. 定义
一切设计都是为了提高搜索的性能。
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
其实就是直接PUT一个JSON的对象,这个对象有多个字段,在插入这些数据到索引的同时,Elasticsearch还为这些字段建立索引——倒排索引,因为Elasticsearch最核心功能是搜索。

由上图可知,value指的是关键词,而key指的是包含关键词的文章的id。
2. 概念
1. 单词 - Term
一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term
2. 单词字典 - Term Dictionary
顾名思义,它里面维护的是Term,可以理解为Term的集合
3. 单词索引 - Term Index
为了更快的找到某个单词,我们为单词建立索引
4. 倒排列表 - Posting List
倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
(PS:实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Python中的元组,或者Java中的对象)
(PS:如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引)
3. 类比MyISAM
Elasticsearch分别为每个字段都建立了一个倒排索引。
只要知道文档ID,就能快速找到文档。可是,要怎样通过我们给定的关键词快速找到这个Term呢?当然是建索引了,为Terms建立索引,最好的就是B-Tree索引(PS:MySQL就是B树索引最好的例子)。
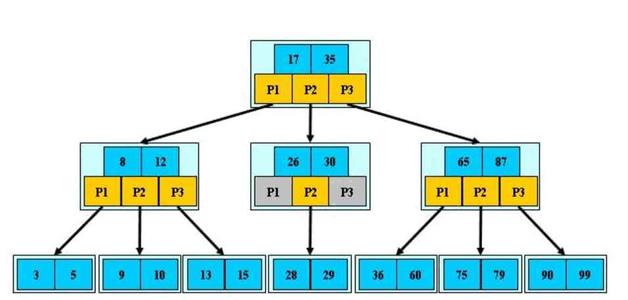

查找Term的过程跟在MyISAM中记录ID的过程大致是一样的,MyISAM中,索引和数据是分开,通过索引可以找到记录的地址,进而可以找到这条记录。
在倒排索引中,通过Term索引可以找到Term在Term Dictionary中的位置,进而找到Posting List,有了倒排列表就可以根据ID找到文档了
类比MyISAM的话,Term Index相当于索引文件,Term Dictionary相当于数据文件。可以把Term Index和Term Dictionary看成一步,就是找Term。因此,可以这样理解倒排索引:通过单词找到对应的倒排列表,根据倒排列表中的倒排项进而可以找到文档记录


倒排索引的再次力推:https://www.cnblogs.com/cjsblog/p/10327673.html