第二次作业:卷积神经网络 part 2
MobileNet V1
MobileNets模型基于深度可分解的卷积,它可以将标准卷积分解成一个深度卷积和一个点卷积(1 × 1卷积核)。深度卷积将每个卷积核应用到每一个通道,而1 × 1卷积用来组合通道卷积的输出。这种分解可以有效减少计算量,降低模型大小。
depthwise convolution和 group convolution是类似的,depth-wise convolution是一个卷积核负责一部分 feature map,每个 feature map只被一个卷积核卷积;group convolution是一组卷积核负责一组 feature map,每组 feature map只被一组卷积核卷积。Depthwise 卷积的参数为: 3 × 3 × 3 = 27,如下所示:

Pointwise不同之处在于卷积核的尺寸为1×1×k,k为输入通道的数量。所以,这里的卷积运算会将上一层的feature map加权融合,有几个filter就有几个feature map,参数数量为:1 × 1 × 3 × 4 = 12,如下图所示:

深度可分解的卷积结构如图所示:

MobileNet V1代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
输出结果:
Epoch: 10 Minibatch: 301 loss: 0.542
Finished Training
模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
输出结果:
Accuracy of the network on the 10000 test images: 77.23 %
MobileNet V2
MobileNet V1 的主要问题: 结构非常简单,但是没有使用RestNet里的residual learning;另一方面,Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的。
MobileNet V2 的主要改动一:设计了Inverted residual block

先用1x1降通道过ReLU,再3x3空间卷积过ReLU,再用1x1卷积过ReLU恢复通道,并和输入相加。之所以要1x1卷积降通道,是为了减少计算量,不然中间的3x3空间卷积计算量太大。所以Residual block是沙漏形,两边宽中间窄。
但是,现在我们中间的3x3卷积变为了Depthwise的了,计算量很少了,所以通道可以多一点,效果更好,所以通过1x1卷积先提升通道数,再Depthwise的3x3空间卷积,再用1x1卷积降低维度。两端的通道数都很小,所以1x1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是是Depthwise的卷积,计算量也不大。作者称之为Inverted residual block,两边窄中间宽,像柳叶,较小的计算量得到较好的性能。
MobileNet V2 的主要改动二:去掉输出部分的ReLU6
在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率。Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了(注意下图中标红的部分没有ReLU)。
# Conv When `groups == in_channels` and `out_channels == K * in_channels`,
# where `K` is a positive integer, this operation is also termed in
# literature as depthwise convolution.
class Block(nn.Module):
def __init__(self, in_planes, out_planes, expand,stride=1):
super(Block, self).__init__()
self.stride = stride
planes = expand*in_planes
self.ex = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn0 = nn.BatchNorm2d(planes)
self.conv1 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn0(self.ex(x)))
out = F.relu(self.bn(self.conv1(out)))
out = self.bn2(self.conv2(out))
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
class MobileNet(nn.Module):
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layer = self._make_layers(in_plane=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_plane):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_plane, out_planes, expansion, stride))
in_plane = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, kernel_size=4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out

HybridSN 高光谱分类
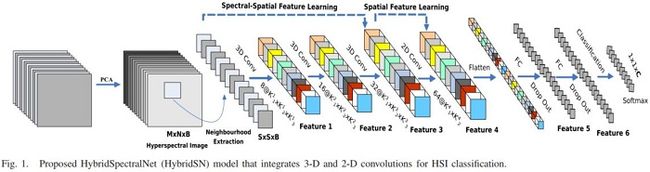
论文构建了一个 混合网络 解决高光谱图像分类问题,首先用 3D卷积,然后使用 2D卷积
HybridSN模型如图所示:
class_num = 16
class HybridSN(nn.Module):
# ''' your code here '''
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
self.conv4 = nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0)
self.linear1 = nn.Linear(18496, 256)
self.drop = nn.Dropout(0.4)
self.linear2 = nn.Linear(256, 128)
self.drop2 = nn.Dropout(0.4)
self.linear3 = nn.Linear(128, 16)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out = out.view(out.size(0), -1, out.size(2), out.size(3))
out = F.relu(self.conv4(out))
out = out.view(out.size(0), -1)
out = F.relu(self.drop(self.linear1(out)))
out = F.relu(self.drop2(self.linear2(out)))
out = self.linear3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
运行结果:
论文阅读
《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
提出了一个前馈去噪卷积神经网络(DnCNN)用于图像的去噪,使用了更深的结构、残差学习算法、正则化和批量归一化等方法提高去噪性能。DnCNN不是直接输出去噪图像,而是噪声观察和潜在干净图像之间的差异,去除潜在的干净的图像。
传统方法与DnCNN的比对:
-
传统方法
- 通过建模图像先验,建立去噪模型,这涉及复杂的优化,并且耗时,模型一般非凸,并且需要手动设计参数,很难达到最优去噪性能。
- 为了克服先验方法局限性,判别学习方法学习图像先验模型能够摆脱迭代优化过程,但在捕获图像结构的所有特征上受到限制,并且许多手动参数被涉及到以及模型被盲图像去噪限制。
-
DnCNN
- 非常深的结构提高利用图像特征的容量和灵活方面是非常有效的。
- 训练CNN的正则化和学习方面取得了相当大的进展,ReLU、批量归一化、残差学习,提高去噪性能。
- 可以训练单个DnCNN模型进行盲高斯去噪,并且比针对特定噪声水平训练的竞争方法获得更好的性能。
残差学习和批量归一化:
- 论上更深的网络可以得到更好的结果。但是通过简单的叠加层的方式来增加网络深度,可能引来梯度消失/梯度爆炸的问题以及网络退化问题,残差网络就可以让网络层次很深的时候,网络依然有很好的性能和效率。
- 内部协变量移位大大降低了小批量SGD的训练效率,其批量归一化通过在每层中的非线性之前引入归一化步骤和缩放和移位步骤来减轻内部协变量偏移。
DnCNN模型结构:

如图所示,网络结构为三种不同类型的层组成:
-
Conv+ReLU:使用64个大小为3×3×c的滤波器被用于生成64个特征图。然后将整流的线性单元(ReLU)用于非线性。
-
Conv+BN+ReLU:64个大小的过滤器,并且将批量归一化加在卷积和ReLU之间。
-
Conv:c个大小为3×3×64的滤波器被用于重建输出。
《Squeeze-and-Excitation Networks》
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。SENet的工作流程如图所示:
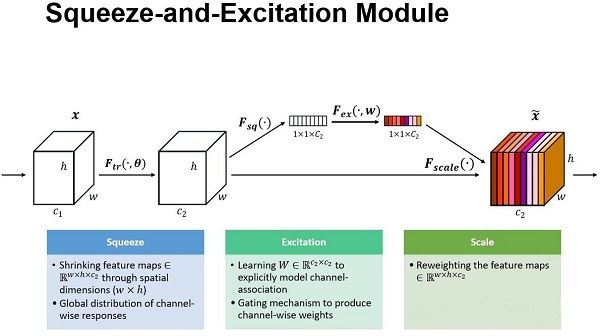
SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入和输出,这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上,作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。下面来看下SENet的一些细节:
-
Squeeze部分。GAP有很多算法,作者用了最简单的求平均的方法,将空间上所有点的信息都平均成了一个值。这么做是因为最终的scale是对整个通道作用的,这就得基于通道的整体信息来计算scale。另外作者要利用的是通道间的相关性,而不是空间分布中的相关性,用GAP屏蔽掉空间上的分布信息能让scale的计算更加准确。
-
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。
《Deep Supervised Cross-modal Retrieval》
文章提出了一种新的跨模态检索方法——深度监督跨模态检索(DSCMR)。它的目的是找到一个共同的表示空间,在这个空间中可以直接比较来自不同模式的样本。具体来说,DSCMR最大限度地减少了标签空间和公共表示空间的识别损失,以监督模型学习的识别特征。在此基础上,利用权值共享策略消除多媒体数据在公共表示空间中的交叉模态差异,学习模态不变特征。
模型的结构如图所示:
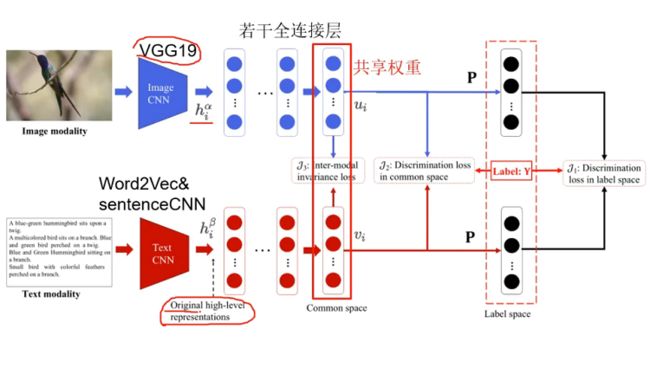
从图中可以看出,该方法包含两个子网络,一个用于图像模态,另一个用于文本模态,并且它们是以端到端的方式进行训练的。将图像和文本分别输入到两个子网络中,得到原始的高级语义表示。然后,在它们的顶部分别添加一些全连接层,将来自不同模式的样本映射到一个公共表示空间。最后,利用参数为P的线性分类器预测每个样本的类别。
模型中的代价函数为:
