GZIP中的LZ77压缩算法
什么是LZ77压缩算法?
ZIP中的LZ77思想
LZ77压缩和解压缩介绍
#ZIP:
LZ77重复语句层面的压缩+huffman字节层面的压缩
#什么是LZ77压缩算法?
1977年由两个以色列人提出的基于重复语句层面的一种通用的压缩算法。通用:对文件没有要求。
最终是将重复语句替换成更短的<距离,长度,先行缓冲区匹配字符的下一个字符>,以达到压缩的目的。
mnoabczefabc123abczefgh
mnoabczef(6,3,1)23(12,4,z)efgh
找到一个字符串后,需要将先行缓冲区字符的下一个字符按照原子符的方式写入压缩文件,下一次匹配efg
#ZIP中的LZ77思想
实际是在LZ77上进行的变形,并没有使用<距离,长度,先行缓冲区匹配字符的下一个字符>三元组的方式替换重复语句,而采用<距离,长度>对。
##缓冲区–64k
如果进行压缩,必须要将文件中的压缩数据读取到程序中缓冲区中,因此程序中必须要有缓冲区。
但是真正的压缩,是在一个比较大的窗口中进行的,窗口越大,找到匹配的可能性就越大,但不是无限大,
因为无限大实,存在两个问题:
- 空间成本:窗口越大,需要的内存空间就越大
- 时间成本:窗口越大,查找匹配串时需要耗费的时间也就越多
因此,GZIP决定,窗口的大小取为64K,分为两部分,一个WSIZE大小为32K,如下图所示:

如果先行缓冲区中的数据少于一个MIN_LOOKAHEAD时,将右
窗口中的数据搬移到左窗口,给右窗口中重新补充32K的数据,继续压缩,直到压缩结束。
MIN_LOOKAHEAD=MAX_NATCH + 1;即:保证待压缩区域至少有一个字节以及该字节的一个匹配长度
###查找缓冲区:
1.该部分数据包已经压缩到压缩文件中
2.待压缩数据对应的一个字符串将来要在该区域中找重复
3.随着压缩的进行查找缓冲区不断的增大
###先行缓冲区:
1.待压缩数据
2.每次从该区域中取字符串,然后在查找缓冲区中找匹配
3.随着压缩的进行,先行缓冲区在不断地缩小
##<距离,长度>对-----3个字节
##距离–2个字节
缓冲区越大,查找到重复率就更高。
理论上应该在整个查找缓冲区64k中匹配,但实际不会这样做,根据实际情况,真正匹配是一个WSIZE–32k–两个字节
??为什么匹配距离越来越远查找重复不太好
重复一般都具有局部原理性,重复一般不会太远,虽然在整个缓冲区中查找,找到的匹配的概率会更大,但是会严重增大查找的效率,为了提升一点点压缩比率,但是程序压缩效率大大牺牲。
##长度–1个字节[0,255]
??为什么匹配字符串的长度用一个字节存储[0,255]
一个字节可带表的最大值位255,255理论已经较长,如果匹配长度超过255,长度必须要通过两个字节进行存储,而正常文件中的匹配长度可能都小于255,一个字节就可以存储,如果采用两个字节进行存储时,会对压缩率有一定影响。
##匹配串长度–3个字符或3个字符以上字符进行匹配
1个字符–>肯定不h会找匹配
2个字符–>r如果找到匹配长度是2个字符,会是压缩文件变大
3个字符或以上字符才开始替换:
// 最小匹配长度
static const size_t MIN_MATCH = 3;
// 最大匹配长度
// GZIP认为:
// 而一个字节能够表示的范围是[0, 255], --[3,258]
//如果让0表示匹配长度为3个字符,1表示匹配长度为 4个字符,...,
//则一个字节最多可以表示的匹配长度为255+3=258
//,即最长的匹配长度,
// 如果某个匹配长度超过258,则拆成两个匹配来进行表示
static const size_t MAX_MATCH = 258;
##如何快速找匹配
1.暴力匹配–三个三个查找,效率太低O(n^2)
2.采用哈希的思想—大大提高查找匹配串的效率
使用哈希“桶”保存每三个相邻字符构成的字符串中首字符的窗口索引。
压缩过程中遇新字符的操作:
1.利用哈希函数计算该字符与其紧跟其后的两个字符构成字符串的哈希地址。
2.将该字符串中的首字符在窗口中的索引插入上述计算出哈希位置的哈希桶中,返回插入之前该桶的状态。
3.根据2返回的状态监测是否找到匹配串。如果当前桶为空,说明未找到匹配;
否则:可能找到匹配,再定位到匹配串位置详细进行匹配即可;
##哈希桶的大小–32k-WSIZE
三个字符总共可以组成224种取值(即16M),桶的个数需要224个,而索引大小占2个字节,总共桶占32M字节,是一个非常大的开销。
随着窗口的移动,表中的数据会不断过时,维护这么大的表,会降低程序运行的效率。因此本文哈希桶的个数设置为:215(即32k)
// 哈希桶的个数为2^15
const USH HASH_BITS = 15;
// 哈希表的大小
const USH HASH_SIZE = (1 << HASH_BITS);
// 哈希掩码:主要作用是将右窗数据往左窗搬移时,
//用来更新哈希表中数据,具体参见后文
const USH HASH_MASK = HASH_SIZE - 1;
##哈希表的结构
哈希表由一整块连续的内存构成,分为两个部分,每部分大小为WSIZE(32k).
(原由:原本需要224个哈希桶,现在减少为215个,必然会产生哈希冲突。如果采用开散列解决,链表中的节点要不断申请与释放,而且浪费空间,影响呈现效率)
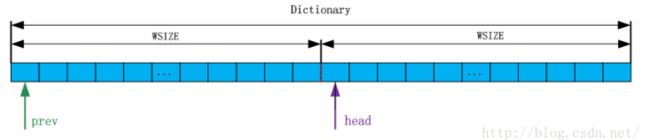
1.prev指向该字典整个内存的起始位置,head=prev+WSIZE,内存是连续的,
所以prev和head可以看作两个数组,即prev[]和head[].
2.head数组用来保存三个字符串首字符的索引(下标)位置,head的索引为三个字符通过哈希函数计算的哈希值。
而prev就是解决哈希冲突
##哈希函数
哈希函数原则:简单、离散。因此本文哈希函数设计如下:
A(4,5) + A(6,7,8) ^ B(1,2,3) + B(4,5) + B(6,7,8) ^ C(1,2,3) + C(4,5,6,7,8)
说明:A 指 3 个字节中的第 1 个字节,B 指第 2 个字节,C 指第 3 个字节,
A(4,5) 指第一个字节的第 4,5 位二进制码,“^”是二进制位的异或操作,
“+”是“连接”而不是“加”,“^”优先于“+”)
这样使 3 个字节都尽量“参与”到最后的结果中来,而且每个结果值 h 都等于 ((前1个h << 5) ^ c)取右 15位。
// hashAddr: 上一个字符串计算出的哈希地址
// ch:当前字符
// 本次的哈希地址是在前一次哈希地址基础上,再结合当前字符ch计算出来的
// HASH_MASK为WSIZE-1,&上掩码主要是为了防止哈希地址越界
void HashTable::HashFunc(USH& hashAddr, UCH ch)
{
hashAddr = (((hashAddr) << H_SHIFT()) ^ (ch)) & HASH_MASK;
} U
SH HashTable::H_SHIFT()
{
return (HASH_BITS + MIN_MATCH - 1) / MIN_MATCH;
}
##哈希表的构建(插入字符串)
哈希表的构建即将字符串插入到哈希表种,该过程伴随着压缩过程一块进行:
1.获取当前字符ch(假设其再窗口位置为pos)
2.用ch之后紧邻的两个字符构成当前串curStr
3.插入curStr
//hashAddr:上一次哈希地址 ch先行缓冲区第一个字符
//pos:ch在滑动窗口中的位置 matchHead:如果匹配,保存匹配串的起始位置
void HashTable::InsertString(USH& hashAddr,UCH ch,USH pos,USH& matchHead)
{
//计算哈希地址
HashFunc(hashAddr,ch);
//随着压缩的不断进行,pos肯定会大于WSIZE,与上WMASK保证不越界
_prev[pos&WMASK]=_head[hashAddr];
matchHead=_head[hashAddr];
_head[hashAddr]=pos;
}
##matchHead带出匹配链的起始位置

##查找最长匹配
字符串插入后,如果matchHead为空,表示未遇到匹配串。如果matchHead不为空,表示在查找缓冲区出现过该字符串,此时,顺着匹配链查找所有的匹配串,直到找到最长匹配。
//匹配:是在查找缓冲区中进行的,查找缓冲区中可能会找到多个匹配
//输出:需要最长的匹配
//注意:可能遇到环状链--解决:设置最大的匹配次数
// 匹配是在MAX_DIST范围内进行匹配,太远的距离则不进行匹配
//在找的过程中,需要将每次找到的匹配结果进行比较,找到最长匹配
USH LZ77::LongestMatch(USH matchHead, USH& MatchDist,USH start)
{
USH curMatchLen = 0; //一次匹配的长度
USH maxMatchLen = 0; //最大的匹配长度
UCH maxMatchCount = 255; //最大的匹配次数,解决环状链
USH curMatchStart = 0; //当前匹配在查找缓冲区的起始位置
//在先行缓冲区中查找缓冲区时,不能太远不能超过MAX_DIST
USH limit = start > MAX_DIST ? start - MAX_DIST : 0;
do
{
//匹配范围
//先行缓冲区的起始位置和结尾位置
UCH* pstart = _pWin + start;
UCH* pend = pstart + MAX_MATCH;
//查找缓冲区匹配串的起始
UCH* pMatchStart = _pWin + matchHead;
curMatchLen = 0;
//可以进行本次匹配
while (pstart < pend && *pstart == *pMatchStart)
{
curMatchLen++;
pstart++;
pMatchStart++;
}
//一次匹配结束
if (curMatchLen > maxMatchLen)
{
maxMatchLen = curMatchLen;
curMatchStart = matchHead;
}
} while ((matchHead=_ht.GetNext(matchHead))>limit && maxMatchCount--);//防止死循环maxMatchCount--
MatchDist = start - curMatchStart;
return maxMatchLen;
}
##如何区分<距离,长度>对与源文件中的数字
解决方式:向压缩文件中写数据时用0和1来进行标记区分,比如0代表源字符,1代表<距离,长度>对。
源文件:mnoabczxyuvmabc123456abczxydefgh
压缩后:mnoabczxyuvm(9,3)123456(18,6)defgh
但是在真正压缩结果中,<距离,长度>对实际是没有括号的
mnoabczxyuvm93123456186defgh
如何区分<距离,长度>对与源文件中的数字?
标记信息:00000000 00001000 00010000 0
0:代表源字符 1:代表<距离,长度>对中的距离。
-->解压缩时遇到1说明该字符是<距离,长度>对中的距离,
说明下一个字符代表长度,即对长度的字符无需标记。
【Huffman思想是先将标记信息写在压缩文件中,再写入压缩数据,但是在LZ77算法中,标记信息的大小无法提前知道(标记信息和压缩数据同时进行),需要一个标记文件先记录其标记信息,待压缩数据读完后,再将标记信息写入到压缩数据之后,并且还要记录标记信息的总大小和源文件的总大小,方便解压缩操作】
//chFlage:该字节中的每个比特位用来区分当前字节是源字符还是长度?
//0--》源字符 1--》长度
//bitCount:该字节中多少个比特位已经被设置
//isCharOrLen:代表该字节是源字符还是长度
void LZ77::WriteFlage(FILE* fOutF, UCH& chFlage, UCH& bitCount, bool isLen)
{
chFlage <<= 1;
if (isLen)
chFlage |= 1;
bitCount++;
if (bitCount == 8)
{
//将该标记写入到压缩文件中
fputc(chFlage, fOutF);
chFlage = 0;
bitCount = 0;
}
}
注意:在压缩算法中,读到文件末尾时,必须判断标记信息最后一个比特位是否够8位,如果不够左移(8-bitCount)位。
//标记位数如果不够8个比特位:110 00000
if (bitCount > 0 && bitCount < 8)
{
chFlage <<= (8 - bitCount);
fputc(chFlage, fOutF);
}
##滑动窗口数据不够怎么办?
随着滑动窗口的不断移动,右窗中的数据不足MIN_LOOKAHEAD时怎么办?【MIN_LOOKAHEAD=MAX_NATCH + 1;即:保证待压缩区域至少有一个字节以及该字节的一个匹配长度】
解决方式:在压缩时,如果文件没有读到结尾,为了保证最大匹配,必须保持先行缓冲区至少有MIN_LOOKAHEAD的源数据。
具体操作:将右窗口中的数据搬移到左窗口,给右窗口中重新补充32K的数据,继续压缩,直到压缩结束。
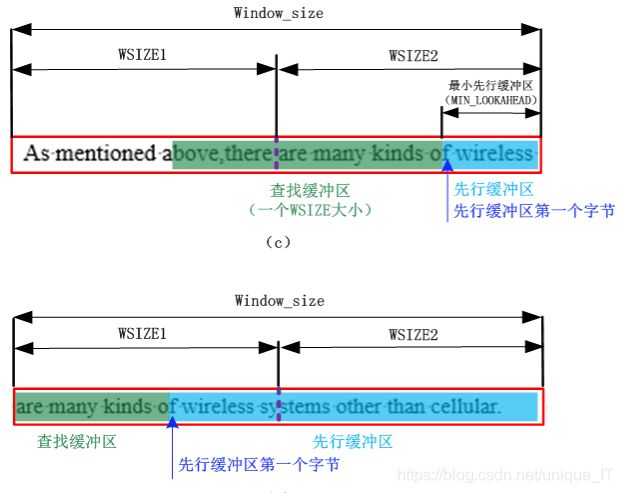
注意:窗口中的数据移动,此时必须更新哈希表
void LZ77::FillWindow(FILE* fIn, size_t& lookAhead, USH& start)
{
//压缩已经进行到右窗,先行缓冲区剩余的数据不够MIN_LOOKAHEAD
if (start >= WSIZE)
{
//1.将右窗的数据搬移到左窗
memcpy(_pWin, _pWin + WSIZE, WSIZE);
start -= WSIZE;
//2.更新哈希表
_ht.Updata();
//3.向右窗中补充WSIZE个的待压缩数据
if (!feof(fIn))
lookAhead = fread(_pWin + WSIZE, 1, WSIZE, fIn);
}
}
void LZHashTable::Updata()
{
for (USH i = 0; i < WSIZE; i++)
{
//先更新head
if (_head[i] >= WSIZE)
_head[i] -= WSIZE;
else
_head[i] = 0;
//更新prev
if (_prev[i] >= WSIZE)
_prev[i] -= WSIZE;
else
_prev[i] = 0;
}
}
#LZ77压缩和解压缩介绍:
##压缩
1.打开待压缩文件(注意:必须按照二进制格式打开,因为用户进行压缩的文件不确定)
2.获取文件大小,如果文件大小小于3个字节,则不进行压缩
3.读取一个窗口的数据,即64k
4.用前两个字符计算第一个字符与其后面两个字符构成字符串哈希地址的一部分,因为哈希地址是通过三个字节计算出来的,先用前两个字节计算出一部分,在压缩时,再结合第三个字节算出第一个字符串完整的哈希地址
5.循环开始压缩a.计算哈希地址,将该字符串首字符在窗口中的位置插入到哈希桶中,并返回该桶的状态matchHead
b.根据matchHead检测是否找到匹配如果matchHead等于0,未找到匹配,表示该三个字符在前文中没有出现过,将该当前字符作为源字符写道压缩文件中
如果matchHead不等于0,表示找到匹配,matchHead代表匹配链的首地址,从哈希桶matchHead位置开始找最长匹配,找到后用该(距离,长度)对替换该字符串写到压缩文件中,然后将该替换串中三个字符一组添加到哈希表中。
6.如果窗口中的数据小于MIN_LOOKAHEAD时,将有窗口中的数据搬移到左窗口,从文件中读取一个窗口的数据放置到右窗,更新哈希表,继续压缩,直到压缩结束。
void LZ77::CompressFile(const std::string& strFilePath)
{
FILE* fIn = fopen(strFilePath.c_str(), "rb");
if (nullptr == fIn)
{
cout << "打开文件失败" << endl;
return;
}
//获取文件大小
fseek(fIn,0 , SEEK_END);
ULL fileSize=ftell(fIn);
//1.如果源文件的大小小于MIN_MATCH,则不进行处理
if (fileSize < MIN_MATCH)
{
cout << "文件太小,不压缩" << endl;
return;
}
//从压缩文件中读取一个缓冲区的数据到窗口中
fseek(fIn, 0, SEEK_SET);
size_t lookAhead=fread(_pWin, 1, 2 * WSIZE, fIn);
USH start = 0;
USH hashAddr = 0;
//abcdef..先把前两个字符读到缓冲区
for (USH i = 0; i < MIN_MATCH - 1; ++i)
_ht.HashFunc(hashAddr,_pWin[i]);
//压缩
FILE* fOUT = fopen("11.lzp", "wb");
assert(fOUT);
//与查找最长匹配相关的变量
USH matchHead = 0;
USH curMatchLength = 0;//最大可以保存258
USH curMatchDist = 0;
//与写标记相关的变量
UCH chFlage = 0;
UCH bitCount = 0;
bool isLen = false;
//写标记的文件
FILE* fOutF = fopen("12.txt", "wb");
assert(fOutF);
//当前缓冲区中剩余字节的个数
while (lookAhead)
{
//1.将当前三个字符(start,start+1,start+2)插入到哈希表中,并获取匹配链的头
_ht.Insert(matchHead, _pWin[start + 2],start,hashAddr);
curMatchLength = 0;
curMatchDist = 0;
//2.验证在查找缓冲区中是否找到匹配,如果有匹配,找最长匹配
if (matchHead)
{
//顺着匹配链找最长匹配,最终带出<长度,距离>对
curMatchLength = LongestMatch(matchHead, curMatchDist,start);
}
//3.验证是否找到匹配
if (curMatchLength < MIN_MATCH)
{
//在查找缓冲区中未找到重复的字符串
//将start位置的字符写入到压缩文件中
fputc(_pWin[start], fOUT);
//写当前源字符对应的标记
WriteFlage(fOutF, chFlage, bitCount, false);
++start;
lookAhead--;
}
else
{
//找到匹配
//将<长度,距离>对写入到压缩文件中
//写长度
UCH chLen = curMatchLength - 3;
fputc(curMatchLength-3, fOUT);
//写距离
fwrite(&curMatchDist, sizeof(curMatchDist), 1, fOUT);
//写当前源字符对应的标记
WriteFlage(fOutF, chFlage, bitCount, true);
//更新先行缓冲区剩余的字节数
lookAhead-=curMatchLength;
//将已经匹配的字符串按照三个一组插入到哈希表中
--curMatchLength;//当前字符串已经插入
while (curMatchLength)
{
start++;
_ht.Insert(matchHead, _pWin[start+2], start, hashAddr);
curMatchLength--;
}
start++;//在start中循环少加一次
}
//检测先行缓冲区中剩余的个数
if (lookAhead <= MIN_LOOKAHEAD)
{
FillWindow(fIn,lookAhead,start);
}
}
//标记位数如果不够8个比特位:110 00000
if (bitCount > 0 && bitCount < 8)
{
chFlage <<= (8 - bitCount);
fputc(chFlage, fOutF);
}
fclose(fOutF);
//将压缩文件和标记信息文件合并;先关闭文件指针fOutF,因为没有刷新到缓冲区中,无法读到数据
MerageFile(fOUT, fileSize);
fclose(fIn);
fclose(fOUT);
//将用来保存标记信息的临时文件删除
}
##压缩格式数据保存
压缩数据+标记信息+标记信息字节数+文件大小
在压缩过程中,压缩数据和标记信息分别写入两个文件中(因为在压缩之前不能统计标记信息的大小,压缩数据和标记信息是同时进行的)。
待压缩数据走到末尾时,再将标记信息写入到压缩文件之后
为了在解压缩时区分文件中的字符是压缩数据还是标记长度,必须记录标记信息的大小和文件的大小.
//将压缩文件和标记信息文件合并
void LZ77::MerageFile(FILE* fOUT, ULL fileSize)
{
//1.读取标记信息文件中内容,然后将结果写入到压缩文件中
FILE* fInF = fopen("12.txt", "rb");
size_t flagSize = 0;
UCH* pReadbuff = new UCH[1024];
while (true)
{
size_t rdSize = fread(pReadbuff, 1, 1024, fInF);
if (0 == rdSize)
break;
fwrite(pReadbuff, 1, rdSize, fOUT);
flagSize += rdSize;
}
//2.保存标记信息的字节数 && 保存文件的大小
fwrite(&flagSize, sizeof(flagSize), 1, fOUT);
fwrite(&fileSize, sizeof(fileSize), 1, fOUT);
delete[] pReadbuff;
fclose(fInF);
}
##解压缩
1.先从压缩文件中读取标记信息和文件的源文件的大小
2.定义两个文件流指针,分别指向压缩数据和标记信息
3读取标记信息,对标记信息进行分析如果当前标记是0,表示源字符,从压缩数据中读取一个字节,直接写入到解压缩文件中
如果当前标记是1,表示遇到<距离,长度>对,从压缩数据中读取一个两个字节表示距离,读取下一个字节表示长度,构建<距离,长度>对,然后从解压缩过的结果中找到匹配长度4.获取下一个标记,直到所有的标记解析完
void LZ77::UNCompressFile(const std::string& strFilePath)
{
//打开压缩文件
FILE* fInD = fopen(strFilePath.c_str(), "rb");//指向压缩数据的指针
if (nullptr == fInD)
{
cout << "压缩文件失败" << endl;
return;
}
//操作标记数据的文件指针
FILE* fInF = fopen(strFilePath.c_str(), "rb");//指向标记信息的指针
if (nullptr == fInF)
{
fclose(fInD);
cout << "压缩文件失败" << endl;
return;
}
//获取源文件的大小
ULL fileSize = 0;
fseek(fInF, 0 - sizeof(fileSize), SEEK_END);
fread(&fileSize, sizeof(fileSize), 1, fInF);
//获取标记信息的大小
size_t flagSize = 0;
fseek(fInF, 0-sizeof(fileSize)-sizeof(flagSize), SEEK_END);
fread(&flagSize, sizeof(flagSize), 1, fInF);
//将读取标记信息文件的指针移动到保存标记数据的起始位置
fseek(fInF, 0 - sizeof(flagSize) -sizeof(fileSize)- flagSize, SEEK_END);
//写解压缩的数据
FILE* fOut = fopen("14.txt", "wb");
assert(fOut);
FILE* fR = fopen("14.txt", "rb");//定位前文中匹配的文件指针
assert(fR);
UCH bitCount = 0;
UCH chFlage = 0;
ULL encodeCount = 0;
while (encodeCount<fileSize)
{
//读取标记
if (0 == bitCount)
{
chFlage=fgetc(fInF);//从指向标记信息文件指针中读取8个比特位的标记信息
bitCount = 8;
}
if (chFlage & 0x80)
{
//距离长度对
USH matchLen = fgetc(fInD)+3;
USH matchDist = 0;
fread(&matchDist, sizeof(matchDist), 1, fInD);//fInD指向压缩数据的指针
//清空缓冲区,系统会将缓冲的数据写入到文件中
fflush(fOut);
//更新解码的字节数大小
encodeCount += matchLen;
//定位前文中匹配的文件指针
//fR:读取前文匹配串中的内容
UCH ch;
fseek(fR, 0-matchDist, SEEK_END);
while (matchLen)
{
ch = fgetc(fR);
fputc(ch, fOut);
matchLen--;
//在还原长度距离对时,一定要清空缓冲区,否则会还原出错
fflush(fOut);
}
}
else
{
//源字符
UCH ch = fgetc(fInD);
fputc(ch, fOut);
encodeCount += 1;
}
chFlage <<= 1;
bitCount--;
}
fclose(fInD);
fclose(fInF);
fclose(fOut);
fclose(fR);
}
源码链接:
https://github.com/uniquefairty/C-Code/tree/master/HuffmanTreeZip