数据库事务和索引的简单理解
转于https://zhuanlan.zhihu.com/p/43493165
https://www.cnblogs.com/aspwebchh/p/6652855.html
事务
总的来说,事务就是在数据库增删查改的过程中,保证数据的正确和安全。
过程中可能会产生以下的问题
a.事务给a账户+1亿元,b账户-1亿元,如果这个事务崩溃,就要进行事务回滚保证数据正确。 需要原子性来保证。
c.只有合法的数据(按照关系约束和函数约束)才能写入数据库
i.事务t1修改a的数据,此时事务t2来读取a的数据,但是后来事务a失败,导致了回滚,此时事务2读到的是脏数据。需要隔离性
d.事务给数据库写入数据的时候,崩溃了,要保证或者写入磁盘,或者回滚。需要持久性对应事务的四个特性
a.原子性:事务要么完成要么取消。
c.一致性:合法数据不会凭空取消产生,依赖于原子性和隔离性。
i.隔离形:不论事务t1,t2谁先完成,最后必须保持数据只有一种可能
d.持久性:如果事务刚刚提交,就崩溃了,数据会保存在数据库中。
根本问题就是:不同事务对数据a的写操作,同时修改,导致不一致,引发回滚,使得数据产生错误。
- 解决:
a.原子性:事务全部完成后再提交。
i.隔离性:引入隔离机制,需要确保同时只有一个事务在修改数据,所以引入互斥锁
1 先获得了锁,然后才能修改对应的数据A
2 事务完成后释放锁,给下一个要修改数据A的事务
3 同一时间,只能有一个事务持有数据A的互斥锁
4 没有获取到锁的事务,需要等待锁释放所以,在事务中更新某条数据获得的互斥锁,只有在事务提交或失败之后才会释放,在此之前,其他事务是只能读,不能写这条数据的。
这就是隔离性的关键,针对隔离性的强度,有以下四的级别:
此处不赘述,细节再查询。
d.持久性:事务会保证数据不会丢,当数据库因不可抗拒的原因奔溃后重启,它会保证:
1 成功提交的事务,数据会保存到磁盘
2 未提交的事务,相应的数据会回滚所以引入了事务日志,来记录每一条操作。
举一个数据库恢复的例子
当数据库从崩溃中恢复时,会有以下几个步骤:
1 解析存在的事务日志,分析哪些事务需要回滚,哪些需要写盘
(还没来得及写盘,数据库就崩溃了)。
2 Redo,进行写盘。检测对应数据所在数据页的LSN,如果数据页
的LSN>=事务操作的LSN,说明已经写过盘,不然进行写盘操作。
3 Undo, 按照LSN倒序进行回滚经过这几个阶段,在数据库恢复后,可以达到奔溃前的状态,也保证了数据的一致性。
索引
https://blog.csdn.net/waeceo/article/details/78702584这篇文章很深入
https://www.cnblogs.com/shanshanlaichi/p/6568097.html
简单来说,索引是用来优化数据库的查找效率用的。
聚集索引:一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。
非聚集索引:一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
以一个例子说明上述区别:
比如查字典,通过拼音查某个字,这个字所在页数上下都是那个拼音,这个正文本身
就按照一定规则排序,就叫做聚集索引;然后按照部首查字典,查到某一个的该字后,
你发现这个字的上下并不都是那个部首,这种目录纯粹是目录,正文纯粹是正文的情况
叫做非聚集索引。所以:每个表只能有一个聚集索引,因为目录只能按照一种方法进行物理顺序的排序。
- 何时使用哪种索引
事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某
范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这
时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,
因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的
开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,
然后再根据页码查到具体内容。- 索引的使用
主键作为聚集索引,是一种极大的浪费;虽然sql server将主键作为默认的聚集索引;但是选择恰当的字段作为聚集索引,会极大的提升数据库的效率。聚集索引要求的:“既不能绝大多数都相同,又不能只有极少数相同”的规则
B树,B+树
https://blog.csdn.net/baidu_35570545/article/details/53907614
- B树(Balance树),可以减少定位中的所经历的过程,一般用于数据库的索引,效率较高。
由于索引很难都在内存中(CPU中读取效率低),为了充分利用内存中的索引页面,减少对于磁盘的IO读取;B树相对于红黑树或者二叉平衡树的优点就是尽力减少树高(每个关键字都有数据且,中间节点子节点(m/2,m)),
B+树木:每个非叶子结点的关键字数等于其孩子数,也就是说关键字数等于指针数;
- 所有数据都在叶子结点上.
利用B+树,实现聚集索引和非聚集索引

以上非聚集索引,逻辑顺序与物理顺序不同
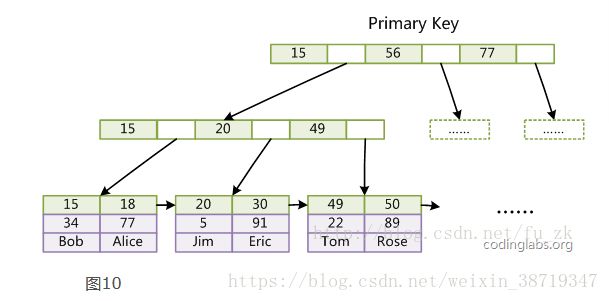
以上聚集索引,索引的逻辑顺序就是物理顺序
一个没加主键的表更像我们印象中的表,而加了主键的表,那么他的存储结构就可以变为树状结构,即平衡树。整个表就变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
用平衡树来查询,效率提高很快,然而增删改查则会效率下降,因为需要维持平衡树的操作。
非聚集索引 ,同样采用平衡树,不过各个节点的值来自索引字段,假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
需要再看!!!!!!!!!!!!!!!!!!!1