Android 进阶——持久化存储序列化方案Serializable和IPC及内存序列化方案Parcelable详解与应用
文章大纲
- 引言
- 一、文件的本质
- 二、序列化和反序列化概述
- 1、序列化和反序列化的定义
- 2、序列化和反序列化的意义
- 三、Serializable
- 1、Serializable 概述
- 2、JDK中序列化和反序列化的方法
- 3、序列化和反序列化的具体策略
- 3.1、仅仅实现了Serializable接口
- 3.2、实现了Serializable接口,还实现了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out)方法
- 3.3、实现了Externalnalizable接口且实现readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法
- 4、实现序列化和反序列化
- 四、Parcelable
- 1、Parcel
- 1.1、Parcel 概述
- 1.2、Parcel 重要的方法
- 1.2.1、直接操作原始基本类型的方法
- 1.2.2、读写原始基本类型组成的数组的方法
- 1.2.3、用于读写标准的Java容器类的方法
- 2、android.os.Parcelable概述
- 2.1、把类的信息和数据都写入Parcel,以使将来能使用合适的类装载器重新构造类的实例的方法
- 2.2、读取时必须能知道数据属于哪个类并传入正确的Parcelable.Creator来创建对象而不是直接构造新对象的方法(推荐)
- 3、Parcelable 序列化和反序列化的实现
- 3.1、实现参数为Parcel 类型的构造方法
- 3.2、重写writeToParcel方法
- 3.3、声明定义用于反序列化的CREATOR成员
- 五、Parcelable 小结
引言
相信序列化实战,所有开发者都经历过的,常见的JSON、XML、Protobuf、Serializable和Parcelable等等这些本质上都属于序列化,那么为什么必须要进行序列化才能进行数据通信呢?
一、文件的本质
众所周知对于我们计算机来说,一切文件的本质都是比特序列(byte序列),文件就是由一个个0或1组成的位(比特byte,每一个逻辑0或者1便是一个位)组合而成,其中8位(byte)为一组即一个字节(Byte)。操作系统在处理解析不同类型的文件,根据各自不同的协议,把比特序列解析为具体的格式,比如说解析到是文本文件时按照UTF-8进行编码(这个UTF-8就是协议,就是操作系统理解的上下文)等等,所以文件=byte序列+上下文(协议)。
对于Linux来说,一切都是文件,文件也是一个高层的抽象,设备是一种特殊的文件。
二、序列化和反序列化概述
List和Map也可以序列化,前提是它们存储每一个元素都是可序列化的。
1、序列化和反序列化的定义
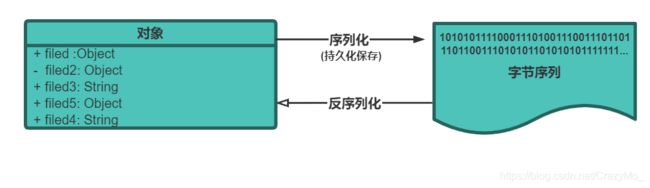
Java序列化就是指把Java对象转换为字节序列(二进制流序列)的过程;而Java反序列化就是指把字节序列恢复为Java对象的过程。
2、序列化和反序列化的意义
序列化时可以确保在传递和保存对象时,保证对象的完整性和可传递性,对象转换为有序字节序列,以便在网络上传输或者持久化保存在本地文件中;而反序列化的主要是在程序中根据字节序列中保存的对象状态及描述信息,通过反序列化得到相应的对象。简而言之,通过序列化和反序列化,我们可以对对象进行持久化保存和便捷传输并复原。
三、Serializable
1、Serializable 概述
Serializable 序列化接口是Java 提供的原生序列化方案,他是一个空接口,为对象提供标准的序列化和反序列化操作。
public interface Serializable {
}
使用 Serializable 来实现序列化操作十分简单,只需要在定义类时实现Serializable 接口并在类中声明一个long 类型静态常量serialVersionUID,其中serialVersionUID值可以是任意值,建议根据当前类自动生成其hash值。因为serialVersionUID 是系统同于确保反序列化安全的一种机制,原则上只有反序列化和序列化时的serialVersionUID一直才可以进行序列化。序列化时系统会保存当前的serialVersionUID值,在反序列化时就会首先进行serialVersionUID验证。验证通过则进行后续操作。如果不指定这个静态常量,反序列化时当前类的结构有所改变(比如增加或者删除了某些成员),那么系统会重新计算当前类的hash值并赋值给serialVersionUID,导致当前类的serialVersionUID与序列化时的不一样进而产生反序列化失败引起的异常。
如果类的结构发生了本质的改变,比如说重构了类名、修改了现有成员的类型和名称,即使serialVersionUID 验证通过了,反序列化也会失败。
默认的序列化过程中,静态变量(属于类不属于对象)和被transiend 关键字标记的成员变量均不参与序列化过程。
2、JDK中序列化和反序列化的方法
JDK中提供了两个类:java.io.ObjectInputStream对象输入流和java.io.ObjectOutputStream 对象输出流:
| 类 | 方法 | 说明 |
|---|---|---|
| ObjectInputStream | Object readObject() | 从输入流中读取字节序列,然后将字节序列反序列化为一个对象并返回。 |
| ObjectOutputStream | void writeObject(Object obj) | 将将传入的obj对象进行序列化,把得到的字节序列写入到目标输出流中进行输出。 |
3、序列化和反序列化的具体策略
利用Serializable 实现序列化和反序列化有多种形式,不同的方式java.io.ObjectInputStream对象输入流和java.io.ObjectOutputStream 采取的策略不同:
3.1、仅仅实现了Serializable接口
- ObjectOutputStream对对象的非transient的实例变量进行序列化。
- ObjcetInputStream对对象的非transient的实例变量进行反序列化。
3.2、实现了Serializable接口,还实现了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out)方法
- ObjectOutputStream调用Student对象的writeObject(ObjectOutputStream out)的方法进行序列化。
- ObjectInputStream会调用Student对象的readObject(ObjectInputStream in)的方法进行反序列化。
JDK中的ArrayDeque< E > 就是这类。
3.3、实现了Externalnalizable接口且实现readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法
- ObjectOutputStream调用对象的writeExternal(ObjectOutput out))的方法进行序列化。
- ObjectInputStream会调用对象的readExternal(ObjectInput in)的方法进行反序列化。
4、实现序列化和反序列化
//序列化
Bean bean=new Bean(100,"cmo");
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("bean.oot"));
oos.writeObject(bean);
oos.close();
//反序列化
FileInputStream fis = new FileInputStream("bean.oot");
ObjectInputStream ois = new ObjectInputStream(fis);
Bean bean2 = (Bean2) ois.readObject();
四、Parcelable
android.os.Parcelable 是Android 针对自身系统某些场景特意定制的高效的序列化方案,在Android中只要实现了android.os.Parcelable接口就可以通过Intent和Binder 进行数据通信。Parcelable接口的实现类是通过Parcel写入和恢复数据的且必须要有一个非空的静态变量 CREATOR。
AIDL中可以传递Set集合类型的数据吗?建议带着这个疑问好好看下文。为什么?
1、Parcel
1.1、Parcel 概述
Container for a message (data and object references) that can be sent through an IBinder
Parcel提供了一套native机制,将序列化之后的数据先写入到一个共享内存中,其他进程通过Binder机制就可以从这块共享内存中读出字节流,并反序列化成对象。Parcel类可以看成是一个存放序列化数据的容器并能通过Binder传递(Binder机制就利用了Parcel类来进行客户端与服务端数据交互)。Android在Java层和C++层都实现了Parcel,Java 层的Parcel 仅仅是相当于代理角色通过JNI 代理调用android_os_Parcel.cpp对应的方法。(Parcel在C/C++中其实是一块连续的内存,会自动根据需要自动扩展大小)。Parcel可以包含原始数据类型(通过各种对应的方法writeInt(),writeFloat()等写入),也可以包含Parcelable对象。重要的是还包含了一个活动的IBinder对象的引用(可以让对端直接接收到指向这个引用的代理IBinder对象),Parcel 更多详情由于篇幅问题不便展开。
Parcel不是一般目的的序列化机制。这个类被设计用于高性能的IPC传输。因此不适合把Parcel写入永久化存储中,因为Parcel中的数据类型的实现的改变会导致旧版的数据不可读。
1.2、Parcel 重要的方法
1.2.1、直接操作原始基本类型的方法
writeByte(byte), readByte(), writeDouble(double), readDouble(), writeFloat(float), readFloat(), writeInt(int), readInt(), writeLong(long), readLong(), writeString(String), readString()。
1.2.2、读写原始基本类型组成的数组的方法
在向数组写数据时先写入数组的长度再写入数据,而读数组的方法可以将数据读到已存在的数组中,也可以创建并返回一个新数组,形如:
- writeBooleanArray(boolean[]), readBooleanArray(boolean[]), createBooleanArray()
- writeByteArray(byte[]), writeByteArray(byte[], int, int), readByteArray(byte[]), createByteArray()
- writeCharArray(char[]), readCharArray(char[]), createCharArray()
- writeDoubleArray(double[]), readDoubleArray(double[]), createDoubleArray()
- writeFloatArray(float[]), readFloatArray(float[]), createFloatArray()
- writeIntArray(int[]), readIntArray(int[]), createIntArray()
- writeLongArray(long[]), readLongArray(long[]), createLongArray()
- writeStringArray(String[]), readStringArray(String[]), createStringArray().
- writeSparseBooleanArray(SparseBooleanArray), readSparseBooleanArray().
1.2.3、用于读写标准的Java容器类的方法
writeArray(Object[]), readArray(ClassLoader), writeList(List), readList(List, ClassLoader), readArrayList(ClassLoader), writeMap(Map), readMap(Map, ClassLoader), writeSparseArray(SparseArray), readSparseArray(ClassLoader)。
2、android.os.Parcelable概述
Parcelable是通过Parcel实现了read和write的方法,从而实现序列化和反序列化。简而言之,相较于普通的getter和setter方法,Parcelable的类似操作是通过Parcel 对象对应的方法完成的。Parcelable为对象从Parcel中读写自己提供了极其高效的协议,并提供了两种类别的方法:
2.1、把类的信息和数据都写入Parcel,以使将来能使用合适的类装载器重新构造类的实例的方法
形如writeParcelable(Parcelable, int) 和 readParcelable(ClassLoader) 或 writeParcelableArray(T[], int) and readParcelableArray(ClassLoader) 等方法
2.2、读取时必须能知道数据属于哪个类并传入正确的Parcelable.Creator来创建对象而不是直接构造新对象的方法(推荐)
riteTypedArray(T[], int), writeTypedList(List), readTypedArray(T[], Parcelable.Creator) and readTypedList(List, Parcelable.Creator)这些方法不会写入类的信息因此更高效。
直接调用Parcelable.writeToParcel()和Parcelable.Creator.createFromParcel()方法读写单个Parcelable对象最高效。
public interface Parcelable {
/** @hide */
@IntDef(flag = true, prefix = { "PARCELABLE_" }, value = {
PARCELABLE_WRITE_RETURN_VALUE,
PARCELABLE_ELIDE_DUPLICATES,
})
@Retention(RetentionPolicy.SOURCE)
public @interface WriteFlags {}
/**
* writeToParcel方法的标记位,表示当前对象需要作为返回值返回,不能立即释放
*/
public static final int PARCELABLE_WRITE_RETURN_VALUE = 0x0001;
/**
* 标识父对象会管理内部状态中重复的数据
* @hide
*/
public static final int PARCELABLE_ELIDE_DUPLICATES = 0x0002;
/*
* 用于 describeContents() 方法的位掩码,每一位都代表着一种对象类型
*/
public static final int CONTENTS_FILE_DESCRIPTOR = 0x0001;
/** @hide */
@IntDef(flag = true, prefix = { "CONTENTS_" }, value = {
CONTENTS_FILE_DESCRIPTOR,
})
@Retention(RetentionPolicy.SOURCE)
public @interface ContentsFlags {}
/**
* 描述当前 Parcelable 实例的对象类型,比如说,如果对象中有文件描述符,这个方法就会返回上面的 * CONTENTS_FILE_DESCRIPTOR,其他情况会返回一个位掩码
*/
public @ContentsFlags int describeContents();
/**
* Flatten this object in to a Parcel.
* 将对象转换成一个 Parcel 对象 参数中 dest 表示要写入的 Parcel 对象
* @param dest The Parcel in which the object should be written.
* @param flags Additional flags about how the object should be written. 表示这个对象将如何写入
* May be 0 or {@link #PARCELABLE_WRITE_RETURN_VALUE}.
*/
public void writeToParcel(Parcel dest, @WriteFlags int flags);
/**
* Interface that must be implemented and provided as a public CREATOR
* field that generates instances of your Parcelable class from a Parcel.
* 实现类必须有一个 Creator 属性,用于反序列化,将 Parcel 对象转换为 Parcelable
*/
public interface Creator<T> {
/**
* Create a new instance of the Parcelable class, instantiating it
* from the given Parcel whose data had previously been written by
* {@link Parcelable#writeToParcel Parcelable.writeToParcel()}.
*
* @param source The Parcel to read the object's data from.
* @return Returns a new instance of the Parcelable class.
*/
public T createFromParcel(Parcel source);
/**
* Create a new array of the Parcelable class.
*
* @param size Size of the array.
* @return Returns an array of the Parcelable class, with every entry
* initialized to null.
*/
public T[] newArray(int size);
}
/**
* Specialization of {@link Creator} that allows you to receive the
* ClassLoader the object is being created in.
* 对象创建时提供的一个创建器
*/
public interface ClassLoaderCreator<T> extends Creator<T> {
/**
* Create a new instance of the Parcelable class, instantiating it
* from the given Parcel whose data had previously been written by
* {@link Parcelable#writeToParcel Parcelable.writeToParcel()} and
* using the given ClassLoader.
* 使用类加载器和之前序列化成的 Parcel 对象反序列化一个对象
* @param source The Parcel to read the object's data from.
* @param loader The ClassLoader that this object is being created in.
* @return Returns a new instance of the Parcelable class.
*/
public T createFromParcel(Parcel source, ClassLoader loader);
}
}
| 方法 | 说明 |
|---|---|
| T createFromParcel(Parcel source) | 从序列化后的Parcel对象中反序列化创建原始对象 |
| writeToParcel(Parcel out,int flags) | 将当前对象写入Parcel中,flag取值为0或者1 |
| @ContentsFlags int describeContents() | 返回当前对象的内容描述,若含有文件描述符,返回1;否则返回0 |
实现了 Parcelable 接口的类在序列化和反序列化时会被转换为 Parcel 类型的数据 。
3、Parcelable 序列化和反序列化的实现
实现Parcelable 接口时默认必须实现三部分:
- 参数为Parcel 类型的构造方法(是交由CREATOR去调用的)
- writeToParcel方法
- 定义CREATOR成员变量,用于反序列化
/**
* @author : Crazy.Mo
*/
public class User implements Parcelable {
private String name;
private long id;
private String card;
public User(String name, long id, String card) {
this.name = name;
this.id = id;
this.card = card;
}
protected User(Parcel in) {
//顺序要和write时一致
this.name=in.readString();
this.id=in.readLong();
this.card=in.readString();
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeLong(id);
dest.writeString(card);
}
@Override
public int describeContents() {
return 0;
}
public static final Creator<User> CREATOR = new Creator<User>() {
@Override
public User createFromParcel(Parcel in) {
//从序列化对象中,获取原始的对象
return new User(in);
}
@Override
public User[] newArray(int size) {
//创建指定长度的原始对象数组
return new User[size];
}
};
}
3.1、实现参数为Parcel 类型的构造方法
这个构造方法主要是交由CREATOR 调用的,本质上就是通过传入的Parcel 对象,根据成员变量的类型,调用各自对应的readXxx方法完成成员变量的赋值,特别地若成员变量中包含其他Parcelable的对象,那么在反序列化时需要当前线程的上下文类加载器(否则会报ClassNotFound 异常),因此在处理此类问题时候,在这个构造方法里还必须传入当前线程上下文类加载器到readParcelable方法中。
//获取当前线程上下文类加载器的几种方式:
getClass().getClassLoader();
Thread.currentThread().getContextClassLoader();
User.class.getClassLoader();
3.2、重写writeToParcel方法
一系列的序列化操作都是经由writeToParcel方法进而调用Parcel native层的一系列对应的writeXxx方法实现的,所以这里的实现很简单基本上就是通过传入的Parcel对象调用对应的writeXxx方法,特别地write的顺序应与read时的顺序一致,即与反序列化时read的顺序一致。
private String name;
private long id;
private String card;
private User(Parcel in) {
//顺序要和write时一致
this.name=in.readString();
this.id=in.readLong();
this.card=in.readString();
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeLong(id);
dest.writeString(card);
}
3.3、声明定义用于反序列化的CREATOR成员
Android Studio 已经很智能了,基本上不用做额外的处理,这是反序列化时需要使用到的。其内部表明了如何创建序列化数组和对象,本质上就是调用Parcel 的readXxx方法完成的。
五、Parcelable 小结
- 仅在使用内存序列化的时Parcelable比Serializable的性能高,Binder和Intent传值。
- 从一定程度来说,Parcelable的序列化和反序列化都是由用户自己去实现的,不需要去进行边界计算,而Serializable 是由系统(JVM)去完成序列化和反序列化的逻辑的,需要一些额外的计算(比如边界判定等)。
- Parcelable不宜应用于持久化存储的需求上,持久化存储还是选择 Serializable
- Parcelable不宜应用于网络通信的需求上,因为Parcelable 不是通用的序列化机制。
- Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC(内存回收)。
/**
* @author : Crazy.Mo
*/
public class MyParcelable implements Parcelable {
private User user;
//记得初始化
private List<String> list=new ArrayList<>(16);
private List<User> usrs=new ArrayList<>(16);
protected MyParcelable(Parcel in) {
this.user=in.readParcelable(User.class.getClassLoader());
in.readStringList(list);
//in.readList(usrs,User.class.getClassLoader()); //对应writeList
//对应writeTypedList
in.readTypedList(usrs,User.CREATOR);
//对应writeTypedList
//usrs=in.createTypedArrayList(User.CREATOR);
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeParcelable(user,0);
dest.writeStringList(list);
//dest.writeList(usrs); 把类的信息和数据都写入Parcel,以使将来能使用合适的类装载器重新构造类的实例
dest.writeTypedList(usrs);
}
@Override
public int describeContents() {
return 0;
}
public static final Creator<MyParcelable> CREATOR = new Creator<MyParcelable>() {
@Override
public MyParcelable createFromParcel(Parcel in) {
return new MyParcelable(in);
}
@Override
public MyParcelable[] newArray(int size) {
return new MyParcelable[size];
}
};
}