BERT融合知识图谱之模型及代码浅析
- 出品:贪心科技AI
- 作者:高阶NLP6期学员,吕工匠
最近小编在做一个文本分类的项目,相比一般的文本分类任务,其挑战之处在于:
1)特征很少:训练数据的文本很短,3~5个字符
2)类别很多:>3000个
3)部分文本包含某垂直领域中具有长尾特性、不易理解的知识
本项目目前的SOTA效果基于BERT实现,但是由于BERT没有有效融入外部知识,因此,对于部分冷门文本,特别是包含某一垂直领域结构化知识信息的文本,模型很难学习到理想的语义表示。所以本项目下一步的优化方向,主要是考虑将知识融入到模型中联合去训练,以提高模型在专业知识领域的泛化能力。为此,小编做了一些调研,附带源码解析等干货,打包分享给大家~
说在前面
谷歌BERT等这种基于大规模语料,先通过无监督预训练方式,再通过垂直领域的业务数据进行微调,训练出的语言模型可以自适应的解决许多特定的业务问题,在很多领域取得了不错的效果。这种预训练+微调的方式,几乎成为了各大厂解决NLP、CV等特定业务问题的标配方案。但即便是如此高级的语言模型,对着这些一串串冰冷的字符和标签,也难以100%理解透彻,模型“肚子”里没有点墨水,能学习到的语义相当有限。
这个时候,我们很有必要为模型请上一名教师,而这名老师呢,刚好对该垂直领域的业务数据十分了解,他会在模型进行训练的时候,手把手的教学,直接告诉模型某个重要单词(实体)的意思,甚至会告诉它有哪些相关的单词(上下位的实体,近义实体等),单词和单词之间有着什么样的关系等等。在老师的教导下,模型可以很快理解这些冰冷的字符串,并且会作出更理智的判断,当然就能更完美的完成下游任务啦。
所以接下来我们要“创造”出拥有以上技能的老师,幸运的是,得益于过去一年NLP技术井喷式的发展,学术界和工业界的大佬们,基于BERT提出了一些结合知识图谱的混合模型方案,为我们量身打造出了这样“老师”:比如北大-腾讯联合推出知识赋能的K-BERT模型、百度提出的通过知识集成增强语义表示的模型ERNIE、清华和华为提出的信息实体的增强语义模型ERNIE。
模型及代码浅析
K-BERT的思路很简单,主要是对于数据集的丰富改造,并且创新性地提出了Visible Matrix机制来决定token间的attention系数,采用Mask-Transformer实现特征抽取。具体来说就是:对于文本中的实体,首先在知识库中链接相关知识(三元组)加入到文本中,并使用一定的策略:软位置(Soft-position)和可见矩阵(Visible Matrix),两者作用分别是标记token的位置和标记token之间是否相互影响,然后通过Tranformer编码器微调完成训练,其模型架构如下。
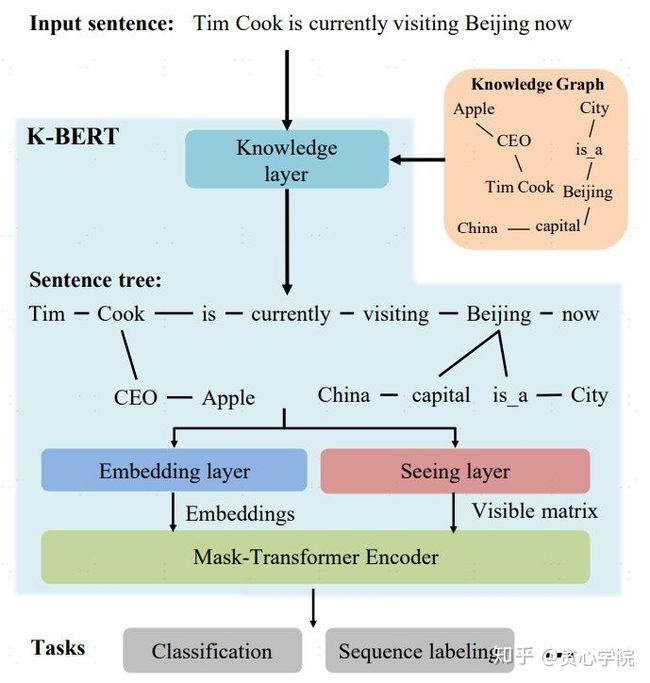
Visible Matrix的设计算是K-BERT一大亮点,它是Mask-Transformer具体的实现手段。直接举个例子:比如,上图的Beijing这个token,当模型计算它的emb时,序列中的token:CEO、Apple,对Beijing没有任何影响,因为它们和Beijing不是同一个枝干的上下文。
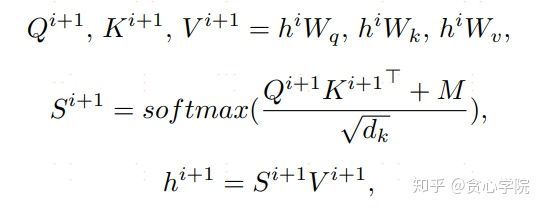
具体的实现方法是基于传统self-attention做了简单修改,计算token之间的attention系数时,引入了一个参数M,当两个token处于同一枝干时,M等于0,否则为负无穷,这样就能确保同枝干的token正常互相作用,而不在同一枝干的token互不影响。
ERNIE模型由于重名,为便于区分,这里将百度版记做(bd_ERNIE),清华版记做(qh_ERNIE)。bd_ERNIE并没用直接输入外部的知识信息,相比谷歌BERT,它是通过改变masking策略的方式,隐式地去学习诸如实体关系、实体属性等知识信息。它先通过词法分析工具,对token进行字、词、实体的粒度进行切分,然后根据切分边界token化处理,在进行mask操作时,和bert不同,它也会mask一些连续的、包含多个字符的词或实体,这样理论上模型就更容易学习到字以外的知识。
qh_ERNIE是由清华大学的张正彦、韩旭、刘知远、孙茂松和来自华为诺亚方舟实验室的蒋欣、刘群联合发布的一项研究,该研究结合大规模语料库和知识图谱训练出增强版的语言表征模型,该模型可以同时充分利用词汇、句法和知识信息。模型的架构如下图所示。
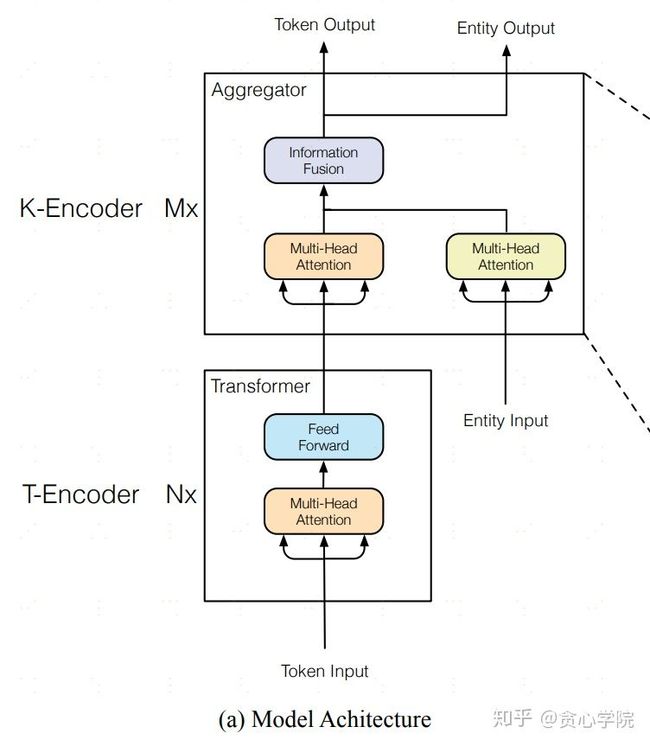
K-Encoder是实现token emb和实体emb显式融合的模块,展开如下图:

该模型对比bd_ERNIE更复杂一些,首先它通过TransE等图算法学习到实体的emb,再将它显式的融入到模型中。如上面的架构图所示,第一层对应代码中的BertLayer_sim,即T-Encoder,其实就是BERT的Encoder层,论文先采用5层BertLayer_sim来对Token进行编码。
BertLayer_sim的主体代码:
self.attention = BertAttention_simple(config) # 对token emb进行self-attention
self.intermediate = BertIntermediate_simple(config) #一个线性层+激活函数
self.output = BertOutput_simple(config)#一个线性层+Layernorm+dropout
其中BertAttention_simple()包含两部分:
self.self = BertSelfAttention(config)
self.output = BertSelfOutput(config)
分别实现对token的emb表示和性能提升礼包(mlp+Layernorm+dropout),前者实际上就是BERT 的self-attention那一套,这个很多前辈都有详细介绍过。
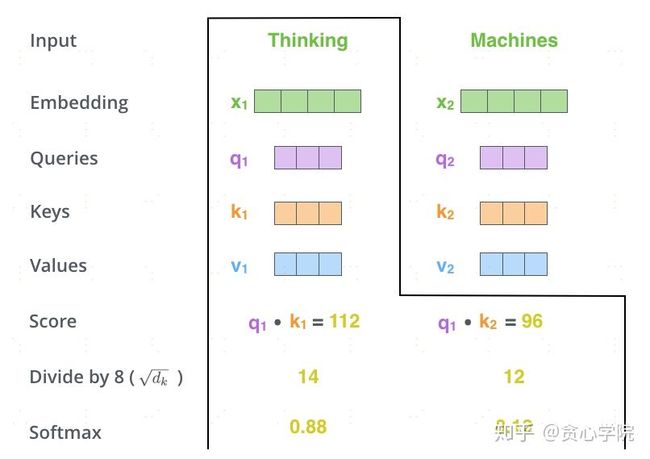
其源码如下:
def forward(self, hidden_states, attention_mask):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer其中,token的三大向量:query、key、value实际上是对token的emb再经过一层线性层而已:
self.query = nn.Linear(config.hidden_size, self.all_head_size)
对于Layernorm,这里多说两句,深度神经网络模型的训练之所以比较困难,其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了获取最优效果,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
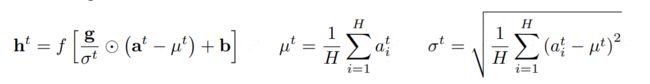
而Layernorm就是为了解决这个问题的有效手段,其计算公式如上,我们知道它是通过综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
再往上就是K-Encoder混合层(BertLayer_Mix),该层的主要作用是将Token emb和实体emb进行融合,融合的过程中要注意实体和token的对齐,由于实体的位置是实体第一个token的位置,所以如果实体的token大于1个,实体的emb会和实体对应的第一个token的emb进行融合,仅1层搞定。从代码来看,BertLayer_Mix的实体emb是没有经过multi-self attention,而是原汁原味的和token emb融合。
BertLayer_Mix()实现融合的入口如下:
intermediate_output = self.intermediate(attention_output, attention_output_ent)其中,attention_output是token的emb,刚刚经过一层multi-self attention后,就干柴烈火的和实体的emb(attention_output_ent)融合在一起了。因为在数据预处理阶段实体的序列长度和token的序列长度是一致的,如何只保留实体的emb?这里将实体序列*ent_mask((32,256,100)*(32,256,1)),张量ent_mask中,实体位置的元素为1,其他为0,这样就只保留了实体的emb,避免下面求和时影响其他token的emb。
attention_output_ent = hidden_states_ent * ent_mask
在intermediate()融合入口函数中,是分别将token emb和实体emb经过一层mlp后,直接相加求和,再经过一层gelu激活函数即可:
def forward(self, hidden_states, hidden_states_ent):
hidden_states_ = self.dense(hidden_states)
hidden_states_ent_ = self.dense_ent(hidden_states_ent)
hidden_states = self.intermediate_act_fn(hidden_states_+hidden_states_ent_) #(32,256,3072)
return hidden_states#, hidden_states_ent
再往上就是BertLayer_norm层,这部分采用了6层网络,和BertLayer_Mix的区别在于,实体的emb是经过multi-self attention后再和token emb相融合的。
为了使得模型能够学到更多的知识信息,在预训练阶段,qh_ERNIE和bd_ERNIE两个模型都额外加入了预测mask实体的任务,不过前者是根据token以及其它实体,从一些给定的实体序列中找出概率最大的那个,而后者则是直接根据上下文的token来预测实体对应的每个token。总体来说k-bert实现起来比较easy,其优化的角度也很直观;bd_ERNIE创新性不高,但相对于传统masking策略的确是一大进步;qh_ERNIE对知识图谱的质量要求较高,只有丰富的节点交融,图算法才能学好节点的emb,但由于和token emb不属于同一空间,融合时难免会产生“排异”反应,但从实验结果来看,还是值得我们进一步深入研究的。
文献
1)Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
2)Liu W, Zhou P, Zhao Z, et al. K-bert: Enabling language representation with knowledge graph[J]. arXiv preprint arXiv:1909.07606, 2019.
3)Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced language representation with informative entities[J]. arXiv preprint arXiv:1905.07129, 2019.
4)Sun Y, Wang S, Li Y, et al. Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
更多干货,请关注“贪心科技AI”公众号。