第17天:NLP实战(一)——爬取语料及其简单分析
《乘风破浪的姐姐》数据爬取与分析
首先和大家说一声抱歉,好久没更新了,最近实在是太忙了,抽不出时间来写博客,还请大家见谅,以后只有有时间就尽量共享自己学到的东西,并且保证写的每篇文章都是实用、高质量的。最近一直在准备秋招的笔试和面试,并且也在学习自然语言处理(NLP)相关知识,知识点学的差不多了,接下来就是各种实战了。在最近连续的几天,我会持续给大家更新有关NLP相关的实践,毕竟理论最终是用到实战上的。
在正文开始之前,给大家唠一下有关今年算法工程师或者NLP工程师相关的就业前景,最近,我一直在准备秋招,今年的算法岗竞争特别激烈,部分公司的算法岗比例高达40:1,用最近知乎上的一篇文章《如何看待2021年秋招算法岗灰飞烟灭?》一点多不过分。都赶上公务员了。因此,好多公司的要求还是蛮高的。大多数要求都是:
- 基础要求:
1、硕士以上计算机相关的专业
2、有强悍的编程能力,精通数据结构与算法。
2、熟悉机器学习、深度学习的相关知识。尤其是熟练掌握逻辑回归、朴素贝叶斯、高斯分布、集成学习、K-NN、K-Means等相关的算法
3、精通但不限于一门的编程语言,包括C/JAVA/Python/R/Go等语言
4、熟悉至少一种以上的深度学习框架,包括Tnesorflow、pytorch、caffe、keras等- 加分要求:
1、在研究生期间在顶级期刊发表过论文优先
2、做过相关的上线的项目优先
3、能够较快的复现最新论文的代码实现
4、有很强的抗压能力以及团队精神
以下是各大公司相关岗位的招聘要求:




最近,本人一直在学习NLP技术,给大家分享一个学习算法相关的平台,那就是百度AI Studio,里面有很多免费的课程,不仅有理论还有实战。今天给大家介绍的这个实战小项目,就是来自于百度,提供免费的GPU,还有相关的比赛,真的很不错,大家感兴趣的可以去学习。接下来开始正文。
项目背景:
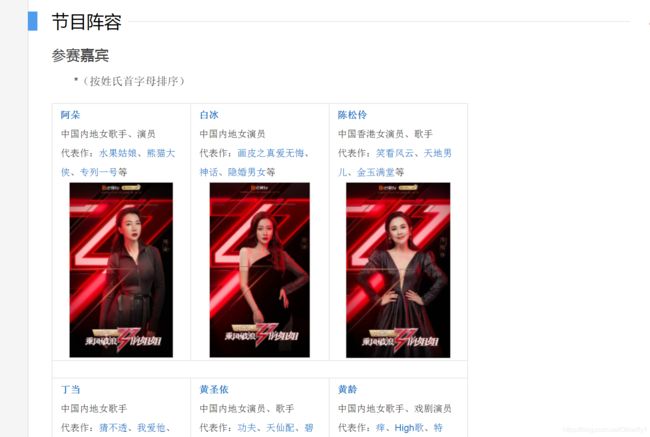
最近,《乘风破浪的姐姐》在网上比较火,因此我们本次就的通过对《乘风破浪姐姐》数据的相关爬取,分析每位参赛选手的相关信息。
任务描述:
本次实践使用Python来爬取百度百科中《乘风破浪的姐姐》所有选手的信息,并进行可视化分析。首先就是通过百度来搜索《乘风破浪的姐姐》百度百科,本次的爬取数据就是来自于这里。
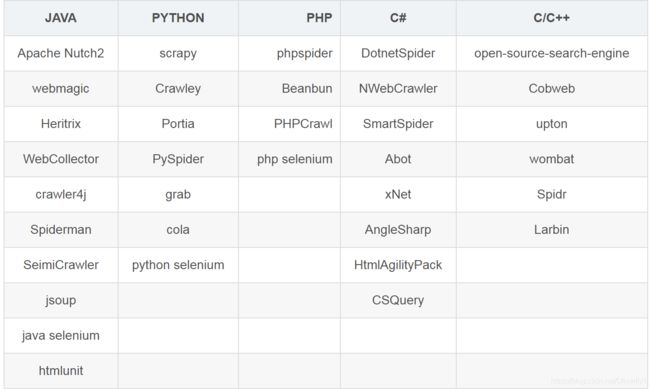
爬虫对于我们自然语言处理也是特别重要,首先我们就是获取数据,获取数据其中最重要的渠道就是通过网上爬取数据,这是前提。爬虫的框架有很多,包括scrapy、Crawley 、PySpider以及selenium,各大框架都有各自的适用场景以及相应的语言,本文由于篇幅限制就不做详细展示了,读者要是想了解详情,可查阅此文章。主要流行的框架主要如下:
我们正常上网过程:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
爬虫也是和我们上网一个流程,具体如下:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
爬虫的具体过程如下:
- 1.发送请求(requests模块)
- 2.获取响应数据(服务器返回)
- 3.解析并提取数据(BeautifulSoup查找或者re正则)
- 4.保存数据
由于本文不是主要介绍爬虫。为了本文读者的广泛性,因此我们用了最为简单request+BeautifulSoup框架来作为本次的爬虫框架。在这里需要说明的是本次实验的request是python自带的库,而BeautifulSoup则是第三方库,需要我们安装。安装极其简单,主需要用pip安装即可,由于下载较慢,需要我们豆瓣安装源,这里害的我们安装lxml 用来保存我们的格式。还得安装一些我们分析数据可视化的第三方库,包括numpy、pandas、matplotlib。具体如下:
pip install pip install beautifulsoup4 -i https://pypi.douban.com/simple
pip install lxml -i https://pypi.douban.com/simple
pip install matplotlib -i https://pypi.douban.com/simple
pip install numpy -i https://pypi.douban.com/simple
pip install pandas -i https://pypi.douban.com/simple
pip3 install jupyter -i https://pypi.douban.com/simple
本文实践的环境:
win7+python(3.7)+jupyter notebook
实践
爬取数据
这里需要说明的是,我们将爬取的数据放在F:\python_program\Paddle_Training\OneDay_basicKnowledge路径下。
一、爬取《乘风破浪的姐姐》相关信息,返回页面数据
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
def crawl_wiki_data():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://baike.baidu.com/item/乘风破浪的姐姐'
try:
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
tables = soup.find_all('table')
crawl_table_title = "按姓氏首字母排序"
for table in tables:
table_titles = table.find_previous('div')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
二、对爬取的页面数据进行相应解析,并以JSON文件格式进行保存。
def parse_wiki_data(table_html):
bs = BeautifulSoup(str(table_html),'lxml')
all_trs = bs.find_all('tr')
stars = []
for tr in all_trs:
all_tds = tr.find_all('td')
for td in all_tds:
star = {}
if td.find('a'):
if td.find_next('a'):
star["name"]=td.find_next('a').text
star['link'] = 'https://baike.baidu.com' + td.find_next('a').get('href')
elif td.find_next('div'):
star["name"]=td.find_next('div').find('a').text
star['link'] = 'https://baike.baidu.com' + td.find_next('div').find('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('F:\python_program\Paddle_Training\OneDay_basicKnowledge' + 'stars.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
三、爬取每个选手的百度百科页面的信息,并进行保存
def crawl_everyone_wiki_urls():
with open('F:\python_program\Paddle_Training\OneDay_basicKnowledge' + 'stars.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
response = requests.get(link,headers=headers)
bs = BeautifulSoup(response.text,'lxml')
base_info_div = bs.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '民族':
star_info['nation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '星座':
star_info['constellation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '血型':
star_info['blood_type'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '身高':
height_str = str(dt.find_next('dd').text)
star_info['height'] = str(height_str[0:height_str.rfind('cm')]).replace("\n","")
if "".join(str(dt.text).split()) == '体重':
star_info['weight'] = str(dt.find_next('dd').text).replace("\n","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
if bs.select('.summary-pic a'):
pic_list_url = bs.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
pic_list_response = requests.get(pic_list_url,headers=headers)
bs = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html=bs.select('.pic-list img ')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html.get('src')
pic_urls.append(pic_url)
down_save_pic(name,pic_urls)
json_data = json.loads(str(star_infos).replace("\'","\""))
with open('F:\python_program\Paddle_Training\OneDay_basicKnowledge' + 'stars_info.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
def down_save_pic(name,pic_urls):
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
except Exception as e:
print(e)
continue
四、数据爬取主程序
if __name__ == '__main__':
html = crawl_wiki_data()
parse_wiki_data(html)
crawl_everyone_wiki_urls()
print("所有信息爬取完成!")
爬取的内容以及相关路径如下:

数据分析
一、绘制每位选手年龄分布柱状图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
%matplotlib inline
with open('F:\python_program\Paddle_Training\OneDay_basicKnowledge/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
birth_days = []
for star in json_array:
if 'birth_day' in dict(star).keys():
birth_day = star['birth_day']
if len(birth_day) == 4:
birth_days.append(birth_day)
birth_days.sort()
print(birth_days)
birth_days_list = []
count_list = []
for birth_day in birth_days:
if birth_day not in birth_days_list:
count = birth_days.count(birth_day)
birth_days_list.append(birth_day)
count_list.append(count)
print(birth_days_list)
print(count_list)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(15,8))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=birth_days_list,
facecolor='#9999ff',edgecolor='white')
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
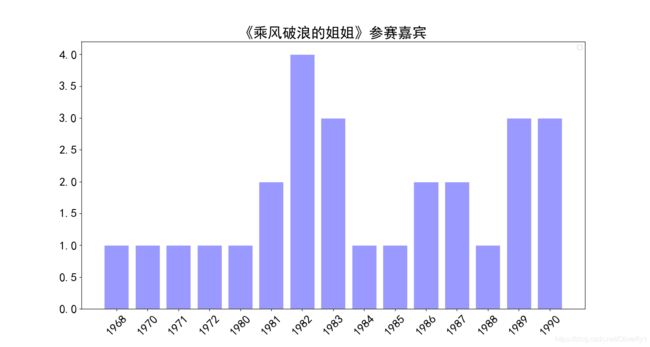
plt.title('''《乘风破浪的姐姐》参赛嘉宾''',fontsize = 24)
plt.savefig('F:\python_program\Paddle_Training\OneDay_basicKnowledge/result/bar_result01.jpg')
plt.show()
具体效果如图所示:
接下来我们利用numpy以及pandas工具将其进行再次数据分析。
import numpy as np
import json
import matplotlib.font_manager as font_manager
import pandas as pd
%matplotlib inline
df = pd.read_json('F:\python_program\Paddle_Training\OneDay_basicKnowledge\stars_info.json',dtype = {'birth_day' : str})
df = df[df['birth_day'].map(len) == 4]
grouped=df['name'].groupby(df['birth_day'])
s = grouped.count()
birth_days_list = s.index
count_list = s.values
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(15,8))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=birth_days_list,
facecolor='#9999ff',edgecolor='white')
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
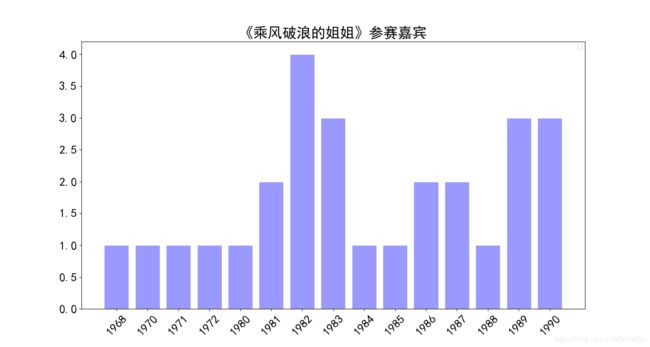
plt.title('''《乘风破浪的姐姐》参赛嘉宾''',fontsize = 24)
plt.savefig('F:\python_program\Paddle_Training\OneDay_basicKnowledge\bar_result02.jpg')
plt.show()
具体效果如图所示:
二、绘制每位选手体重饼状图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
%matplotlib inline
with open('F:\python_program\Paddle_Training\OneDay_basicKnowledge\stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
weights = []
counts = []
for star in json_array:
if 'weight' in dict(star).keys():
weight = float(star['weight'][0:2])
weights.append(weight)
print(weights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
size4 = 0
for weight in weights:
if weight <=45:
size1 += 1
elif 45 < weight <= 50:
size2 += 1
elif 50 < weight <= 55:
size3 += 1
else:
size4 += 1
labels = '<=45kg', '45~50kg', '50~55kg', '>55kg'
sizes = [size1, size2, size3, size4]
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True)
ax1.axis('equal')
plt.savefig('F:\python_program\Paddle_Training\OneDay_basicKnowledge\pie_result01.jpg')
plt.show()
具体效果如图所示:
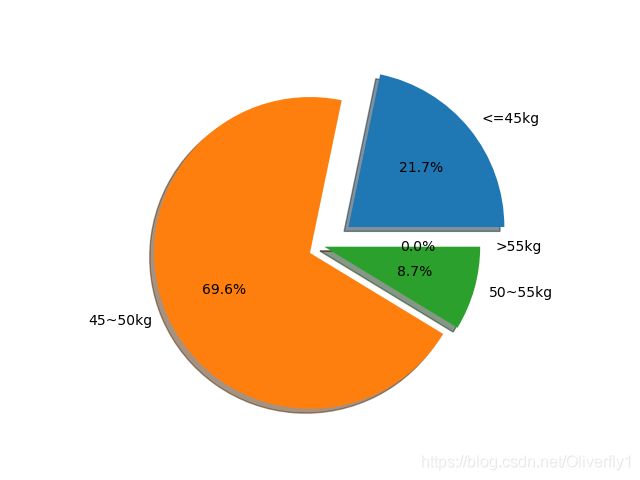
接下来我们利用numpy以及pandas工具将其进行再次数据分析。
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
import pandas as pd
%matplotlib inline
df = pd.read_json('F:\python_program\Paddle_Training\OneDay_basicKnowledge\stars_info.json')
print(df)
weights=df['weight']
arrs = weights.values
arrs = [x for x in arrs if not pd.isnull(x)]
for i in range(len(arrs)):
arrs[i] = float(arrs[i][0:2])
bin=[0,45,50,55,100]
se1=pd.cut(arrs,bin)
print(se1)
pd.value_counts(se1)
sizes = pd.value_counts(se1)
print(sizes)
labels = '45~50kg', '<=45kg','50~55kg', '>55kg'
explode = (0.2, 0.1, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
plt.savefig('F:\python_program\Paddle_Training\OneDay_basicKnowledge\pie_result02.jpg')
plt.show()
具体效果如图所示:
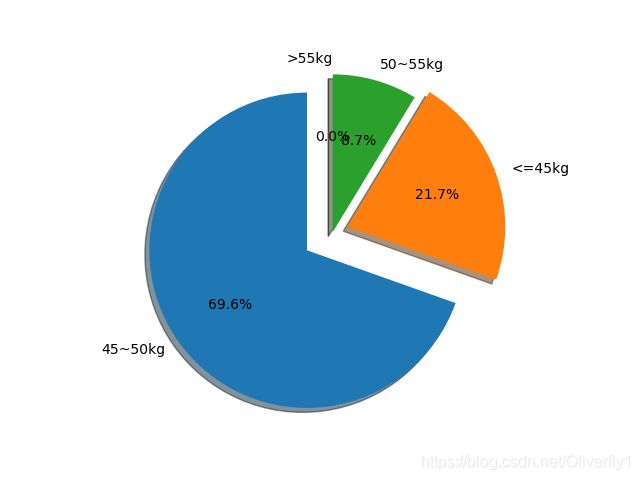
绘制每位选手身高饼状图
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
with open('F:/python_program/Paddle_Training/OneDay_basicKnowledge/stars_info.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
heights = []
counts = []
for star in json_array:
if 'height' in dict(star).keys():
height = float(star['height'][0:3])
heights.append(height)
print(heights)
size_list = []
count_list = []
size1 = 0
size2 = 0
size3 = 0
for height in heights:
if 165 < height <= 170:
size1 += 1
elif height <= 165:
size2 += 1
else:
size3 += 1
labels = '165~170cm', '<=165cm', '>170cm'
sizes = [size1,size2,size3]
explode = (0.1, 0.1, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels,startangle=90, autopct='%1.1f%%',
shadow=True, wedgeprops={'linewidth': 1, 'edgecolor': "black"})
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('《乘风破浪的姐姐》明星身高分布图')
plt.legend(['高挑','适中','大长腿'],loc = 'upper right')
ax1.axis('equal')
plt.savefig('homework_picture.png')
plt.show()
具体效果如图所示:
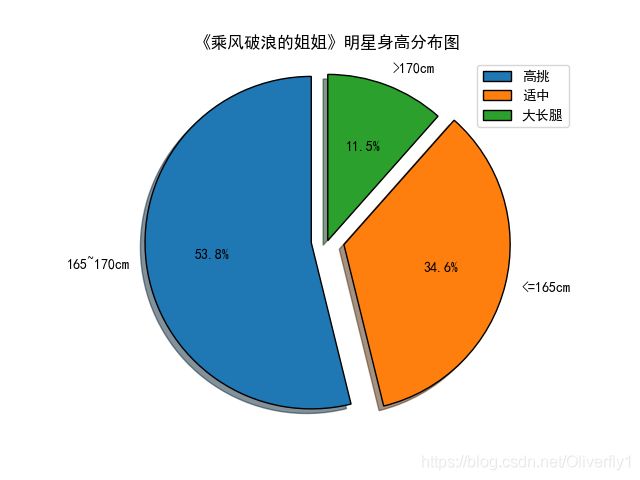
总结
本文刚开始给大家大致的聊了一下今年算法岗和NLP岗位的就业情况并且大致介绍了一下各大公司对算法岗的相关招聘信息,总之今年算法岗的就业形势不容乐观,并且难度在不断上升。总之革命尚未成功,同志还需努力。接下来就是通过最近很火的《乘风破浪姐姐》作为数据对其进行简单的数据分析。这些代码均可运行,希望大家在有时间的情况下,可以动手运行一遍,感受一下数据的爬取过程以及数据的分析过程。接下来的几天都会陆续给大家更新相关的时间内容,练习完之后感觉收获满满。加油,希望我们都学友所获。