【深度学习】【python】用于image caption的rnn程序怎么实现 中文注释版
【深度学习】【python】用于image caption的rnn程序怎么实现 中文注释版
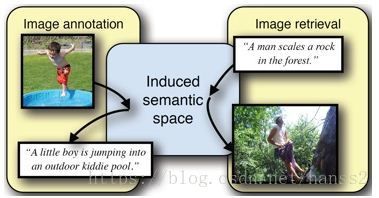
说明
这里用到了cnn做特征提取,另外,只展示了rnn怎么实现,数据读取预处理和cnn部分省略了,参考这个韩国人的代码:https://github.com/byeongjokim/generate-caption-of-frame
程序
rnn部分:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""用于image-caption的rnn模型的定义"""
import tensorflow as tf
import config
class RNN():
def __init__(self, image, num_words, dim_h=config.dim_hidden, max_len=config.max_len):
# 初始化rnn层;
print("init RNN layers")
# 定义图片;
self.image = image
# rnn隐含层维度;
self.dim_h = dim_h
# 词袋容量;
self.num_words = num_words
# 句子最大长度;
self.max_len = max_len
# 图片的输入门参数;
self.W_Img2h = tf.Variable(tf.random_uniform([4096, dim_h], -0.1, 0.1), name="W_Img2h")
self.B_Img2h = tf.Variable(tf.zeros([dim_h]), name="B_Img2h")
# 单词的输入门参数;
self.W_W2E = tf.Variable(tf.random_uniform([num_words, dim_h], -0.1, 0.1), name="W_W2E")
self.B_W2E = tf.Variable(tf.zeros([dim_h]), name="B_W2E")
# 单词的输出门参数;
self.W_E2W = tf.Variable(tf.random_uniform([dim_h, num_words], -0.1, 0.1), name="W_E2W")
self.B_E2W = tf.Variable(tf.zeros([num_words]), name="B_E2W")
# 定义rnn层;
self.rnn_cell = tf.nn.rnn_cell.BasicLSTMCell(dim_h)
# 换用lstm;
#self.rnn_cell = tf.nn.rnn_cell.BasicLSTMCell(dim_h, forget_bias=0.0)
def train_model(self, sentence, label, mask):
loss = 0
#for m, h init
state = (tf.zeros([config.batch_size, self.dim_h]), tf.zeros([config.batch_size, self.dim_h]))
# 对每一个max_len个单词中的每一个单词;
for i in range(self.max_len):
# 假如是第一个单词;
if(i == 0):
# x = image*W + B(即先输入图片信息到 x);
x = tf.matmul(self.image, self.W_Img2h) + self.B_Img2h
# 不是第一个单词;
else:
# tf.nn.embedding_lookup(params, ids);用法主要是选取一个张量(params)里面索引(ids)对应的元素;
# (即输入单词i之前的语义信息到 x);
x = tf.nn.embedding_lookup(self.W_W2E, sentence[:,i-1]) + self.B_W2E
# 计算一次前向传播;
# x即本次输入;state保存的是上一步的输出;
output, state = self.rnn_cell(x, state)
# 不是第一个单词(从此处开始是计算loss);
if i > 0:
# 获取这个单词的one-hot标签;
one_hot_label = label[:, i]
# 输出单词;(将词向量映射到word上);
predicted = tf.matmul(output, self.W_E2W) + self.B_E2W
# 计算模型预测predicted与真实标签one_hot_label的差异loss;
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=predicted, labels=one_hot_label)
#cross_entropy = cross_entropy * mask[:, i]
# 最终代价;
current_loss = tf.reduce_sum(cross_entropy)
# 累计代价;
loss = loss + current_loss
loss = loss #/ tf.reduce_sum(mask[:,1:])
return loss
def predict_model(self, start):
"""
-----------变量说明-----------------
目的:利用句子头标识和图片推导这个图的描述;
:参数 start : str, 输入句子头表示;
"""
# 初始化state;
state = (tf.zeros([1, self.dim_h]), tf.zeros([1, self.dim_h]))
# x = image*W + B(即先输入图片信息到 x);
x = tf.matmul(self.image, self.W_Img2h) + self.B_Img2h
# 初始化句子的单词列表(要返回的结果);
result = []
# 做一次前向传播;
output, state = self.rnn_cell(x, state)
# 输入sentence_start;
x = tf.nn.embedding_lookup(self.W_W2E, [start]) + self.B_W2E
# 在最大长度max_len的约束下产生一句话(该结束时会产生sentence_end结束,长度不足max_len);
for i in range(self.max_len):
# 做一次前向传播;
output, state = self.rnn_cell(x, state)
# 转化为单词结果;
predicted = tf.matmul(output, self.W_E2W) + self.B_E2W
# 取最大的元素对应的下标代表的词;
predicted_word = tf.argmax(predicted, 1)
# 将predicted_word的语义信息关联到变量 x;
x = tf.nn.embedding_lookup(self.W_W2E, predicted_word) + self.B_W2E
# 将结果加入到句子;
result.append(predicted_word)
# 返回结果;
return result主程序:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""主程序:构建、训练模型+测试"""
import tensorflow as tf
import numpy as np
import random
import config
from data import Flickr_Data
from cnn import CNN
from rnn import RNN
class Model():
"""模型类,定义模型结构."""
# 定义训练超参数;
lr = None
epoch = None
batch_size = None
# 模型存储路径;
chk = './_model/rCNN.ckpt'
def __init__(self):
"""构造函数"""
# 训练参数来自config.py;
self.lr = config.learning_rate
self.epoch = config.epoch
self.batch_size = config.batch_size
def get_data(self):
"""获取数据"""
# 数据获取类实例(来自data.py);
data = Flickr_Data(config.image_path, config.token_path, 224, 224)
# 获取数据;
train_data, test_data, self.w2i, self.i2w = data.make_data()
# 训练数据;
# 句子开头标识;
self.start = self.w2i["SENTENCE_START"]
# 图片数据;
self.train_X = np.array([i['image'] for i in train_data])
# label对应的单词index;
self.train_Y = np.array([i['0_label'] for i in train_data])
# label对应的单词vector;
self.train_L = np.array([i['0_label_'] for i in train_data])
# 完成数据读取;
print("made_data")
# 返回测试数据;
return test_data
def make_model(self, attend):
"""模型结构"""
# 输入图片的占位符;
self.input_image = tf.placeholder(tf.float32, [None, 224, 224, 3])
# 输入句子的占位符;
self.sentences = tf.placeholder(tf.int32, [None, config.max_len])
# 输入标签的占位符(单词的index);
self.label = tf.placeholder(tf.int32, [None, config.max_len, len(self.w2i)])
# 这里mask本可用于训练模型时cross entropy对不同单词的权重调整(注意力机制);
self.mask = tf.placeholder(tf.float32, [None, config.max_len])
# 定义CNN类(来自cnn.py);
cnn = CNN(attend=attend)
# input_image经cnn的输出;
cnn_model = cnn.layers(self.input_image)
# 定义rnn实例(将cnn的输出输入rnn);
rnn = RNN(image=cnn_model, num_words=len(self.w2i))
# 计算rnn的损失(应该说这个损失也被用于逐层回传调整cnn的参数);
self.loss = rnn.train_model(self.sentences, self.label, self.mask)
# 获取对于该图片的预测;
self.pred = rnn.predict_model(self.start)
# 定义训练句柄;
self.train_op = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(self.loss)
# 完成模型定义;
print("made model")
# 运行类实例;
self.sess = tf.Session()
# 模型存储;
self.saver = tf.train.Saver()
# 定义临界模型;
ckpt = tf.train.get_checkpoint_state('./_model')
# 保存当前训练进度;
# 假如有之前的保存记录;
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
# 保存;
print("restore the sess!!")
#self.sess.run(tf.global_variables_initializer())
# 将状态sess存到路径chk;
self.saver.restore(self.sess, self.chk)
# 还没有保存过;
else:
# 参数初始化、然后存储;
self.sess.run(tf.global_variables_initializer())
def train(self):
"""模型训练"""
# 输出训练详情;
print("There is ",len(self.train_X)," train data")
print("epoch: ", self.epoch)
print("batch_size: ", self.batch_size)
# batch的数量;
total_batch = int(len(self.train_X) / self.batch_size)
# 如果单个批次大小大于训练数据量;
if (total_batch == 0):
# 就只进行一次batch训练;
total_batch = 1
# 每一次迭代;
for e in range(self.epoch):
# 初始化此次迭代的代价;
total_cost = 0.0
# j记录的是每个batch训练数据的开始位置;
j = 0
# 每一个batch;
for i in range(total_batch):
# 如果本次所需训练数据越界;
if (j + self.batch_size > len(self.train_X)):
# 就只取训练数据到所有数据尾部;
batch_x = self.train_X[j:]
batch_y = self.train_Y[j:]
batch_l = self.train_L[j:]
# 没有越界;
else:
# 取batch_size大小的数据段;
batch_x = self.train_X[j:j + self.batch_size]
batch_y = self.train_Y[j:j + self.batch_size]
batch_l = self.train_L[j:j + self.batch_size]
# 更新j到下一个批次开头;
j = j + self.batch_size
# current_mask_matrix就是用于调节输出权重的矩阵;
current_mask_matrix = np.zeros((batch_y.shape[0], batch_y.shape[1]))
# 跑loss计算和训练;
_, loss_value = self.sess.run([self.train_op, self.loss], feed_dict={
self.input_image : batch_x,
self.sentences : batch_y,
self.label : batch_l,
self.mask : current_mask_matrix
})
# 累计代价;
total_cost = total_cost + loss_value
# 输出代价;
print(str(e+1), ", total Cost: ", total_cost)
print("======================================\n")
self.saver.save(self.sess, self.chk)
def predict(self, test_data):
"""用于预测"""
# 当前图片名;
image_name = test_data["image_name"]
# 当前图片;
test_X = test_data['image']
# 当前图片的描述;
test_Y = test_data['0_label']
# 输出当前图片名;
print("image_name: ", image_name)
# 获取当前描述语句的单词形式(test_Y保存的是单词的index);
label = [self.i2w[i] for i in test_Y]
# 开头设为' ';
label = ' '.join(label)
# 输出描述;
print(label,"\n")
# 获取预测的result;
result = self.sess.run(self.pred, feed_dict={
self.input_image: [test_X],
})
# np.hstack()是堆叠函数,相当于调整矩阵shape;
result = np.hstack(result)
# 当前描述语句的单词形式(result保存的是单词的index);
result = [self.i2w[i] for i in result]
# 开头加' ';
result = ' '.join(result)
# 输出;
print(result, "\n")
return ''
# 主函数部分;
# 构造模型;
m = Model()
# 获取测试数据;
test_data = m.get_data()
# 模型初始化;
m.make_model(attend=0)
# 训练;
m.train()
# 随机选一个图片;
ind = random.randint(0, len(test_data))
# 给出它的描述;
m.predict(test_data[ind])