旅行场景下的个性化营销平台揭秘
分享嘉宾:弘轶、寻潇、溪怀@飞猪
编辑整理:郭嘉伟
内容来源:DataFunTalk
导读:个性化投放的"无人驾驶"平台何以自动化支持上千个场景的千人千面投放?商家、运营、小二,我们如何做到极致赋能和提效?面对旅行场景下用户需求低频、行为稀疏,特别是在营销活动大促期间,用户量迅速增长,用户的冷启动问题更加严峻,如何提高冷启动用户的推荐效果成为关键。另外,面对旅行场景下的丰富多样的的货品需求依赖关系,我们如何来组织和呈现给用户?阿里飞猪个性化推荐团队将通过本文,为大家带来旅行场景下的个性化营销平台揭秘。
主要分享内容包括:
-
背景
-
个性化营销平台架构
-
个性化营销平台算法
01
背景介绍
飞猪专注于在旅行场景。个性化营销团队承接飞猪日常场景和会场场景,我们会给用户呈现千人千面的个性化投放。
1. 日常场景

飞猪App上有众多页面。上图最左的首页界面中,上方是Banner,下方是猜你喜欢。由首页的入口可以进入各频道页,包括周边游、飞猪门票、旅游度假等。各频道页有不同的投放模块,这些全都由个性化营销平台承接。
2. 会场场景
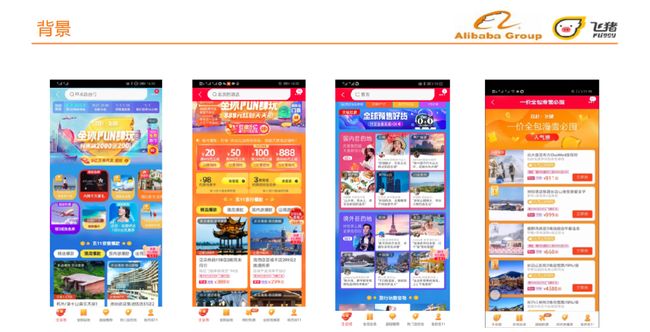
每年的双十一、六一八、五一、春运、暑促等会场中,个性化营销团队承接各场景模块,包括主会场、全部会场、目的地会场、一些榜单会场等。
3. 挑战和难点
面对众多页面和众多模块,个性化营销存在如下几点挑战和难点:
-
投放页面和模块多样化;
-
投放物料多种异构数据源;
-
运营干预配置多样化;
-
如何统一个性化投放模型来赋能提效。
02
个性化营销平台架构
个性化营销平台架构的设计主要包括以下内容:
1. 场景抽象
![]()
我们首先对上节讲到的日常场景和会场场景进行场景抽象,抽象出的场景包括:入口、单Tab场景、多Tab场景、胶囊、主题榜单、单物料投放、多物料混投、LBS推荐、周边推荐和实时热榜等。
-
入口:点击后可直接进入商品详情页,我们认为不是入口,否则我们定义为入口;
-
单物料投放:只投放一种物料,如只投放商品或只投放酒店;
-
多物料混投:投放页面可能有出现商品、酒店、门票、POI等多种物料;
-
LBS推荐:基于用户定位的推荐。
2. 功能抽象
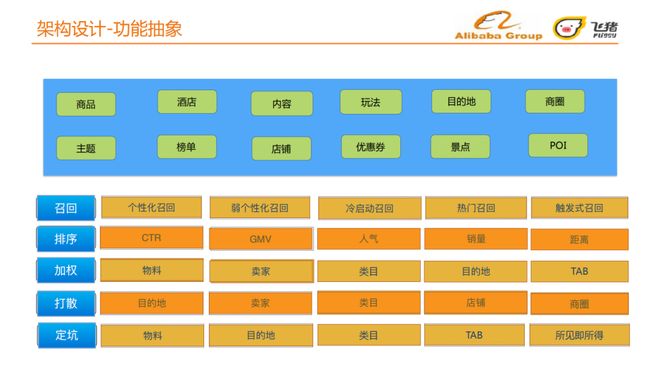
个性化营销平台可以投放的物料包括:商品、酒店、内容、玩法、目的地、商圈、主题、榜单、店铺、优惠券、景点、POI等。
投放的功能包括:召回、排序、加权、打散、定坑。
-
召回:常规的个性化召回、弱个性化召回、冷启动召回、热门召回、触发式召回;
-
排序:综合考虑多个维度,如点击率CTR、成交量GMV、人气、销量、距离等;
-
加权:为赋能运营,对爆款或者新品给予一定的扶持;
-
打散:保证呈现结果多样化;
-
定坑:基于某些营销目的,针对爆款、热品给用户进行定向的前置推送。
3. 链路抽象
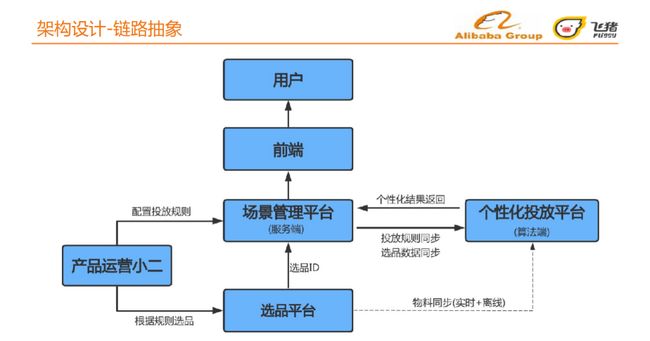
我们将链路抽象为6个模块:产品运行端、选品平台、场景管理平台、个性化投放平台、前端、用户。
-
产品运营端:运营端基于自身的行业理解,根据规则选品,为选品平台筛选出商品池 、酒店池等,并配置场景管理平台的投放规则;
-
选品平台:生成选品ID后提供给场景管理平台,将物料采取实时加离线的方式同步到个性化投放平台;
-
场景管理平台:将投放规则和选品数据同步到个性化投放平台,接收个性化投放平台返回的个性化结果;
-
个性化投放平台:基于选品池和投放规则,给出千人千面的个性化结果返回场景管理平台;
-
前端:接收场景管理平台的结果,将内容呈现给用户。
4. 个性化投放
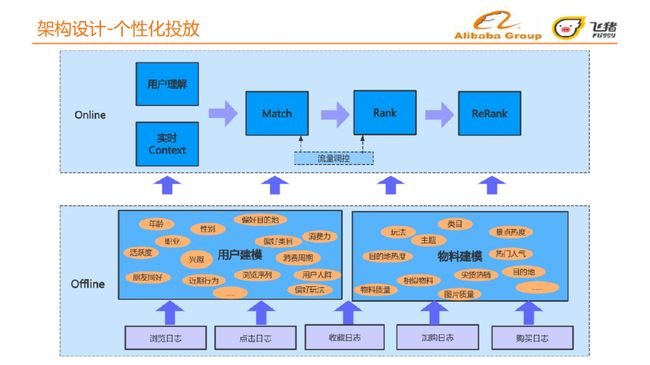
本节我们将介绍个性化投放平台如何构建人货匹配的个性化方案。图中从下向上依次是离线和在线处理过程。
-
离线处理会基于用户历史行为数据,对用户和物料进行建模。
-
在线处理首先进行用户理解和实时的上下文分析,目的是更精准的人货实时匹配,即个性化召回。物料召回后平台会进行匹配和排序,匹配和排序之间会有流量调控,目的是对新品 、爆款、尖货等给予一定的扶持。排序结果会结合运营的投放规则进行更加精准的重排序最终呈现给用户。
4. 用户建模
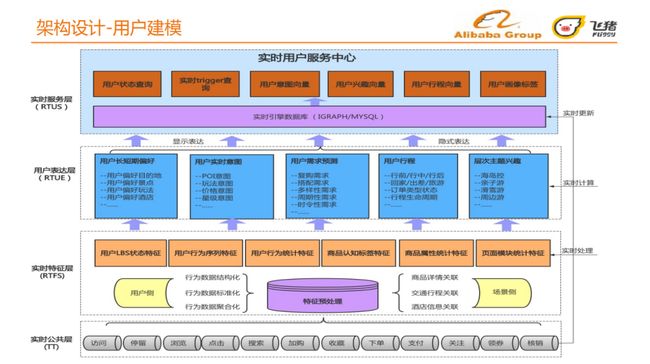
用户建模过程如图所示,从最底层往上依次是:实时公共层、实时特征层、用户表达层和实时服务层,其中用户表达层是我们的核心工作。
-
实时公共层:收集用户行为数据并落盘;
-
实时特征层:进行特征预处理,对用户行为数据进行结构化、标准化和聚合化,对宝贝建立关联,生成模型需要的特征表达,如用户LBS状态特征、商品认知标签特征、页面模块统计特征等;
-
用户表达层:基于实时特征层的原始特征进行加工、提纯、聚合,生产用户的特征表达,包括:用户长短期偏好、用户实时意图、用户需求预测、用户行程、层次主题兴趣;
-
实时服务层:平台在该层对外输出服务,输出的功能主要包括:用户状态查询、实时trigger查询、用户意图向量、用户兴趣向量、用户行程向量、用户画像标签,其中向量为隐式表达,用户画像标签为显式表达。
5. 全域流量调控
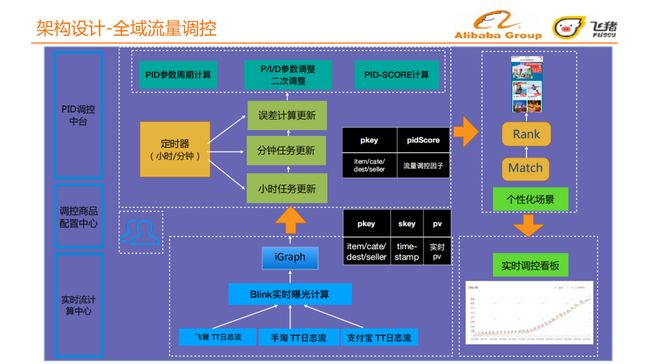
全域流量调控过程如图所示,从最底层往上依次是:实时流计算中心、调控商品配置中心、 PID调控中台 。
-
实时流计算中心:监控飞猪、手淘、支付宝三端的实时行为,根据实时日志流获取不同物料不同粒度下的实时PV,不同物料包括:不同item 、不同类目、不同目的地、不同卖家;
-
调控商品配置中心:主要由运营来参与,运营在日常或会场中需 要对一些爆款商品做一定的流量扶持,如热门的目的地,热门的行业,运营基于曝光流量和实时PV决策 是否给予更多的流量,算法方也会给予一个相应的建议,比如有的买家销量高人气高,算法会相应的提高权重,运营结合算法的策略在平台进行配置;
-
PID调控中台:使用一个改进的PID算法,通过小时任务更新、分钟任务更新和误差计算更新生成能够影响个性化流量推荐的调控因子,该调控因子作用在个性化场景上,具体来说作用在匹配阶段和排序阶段,最终影响页面上物料投放的流量。
整体的流量调控结果反应在实时调控看板上,可以及时做到自适应的反馈和流量调整。
6. 整体方案
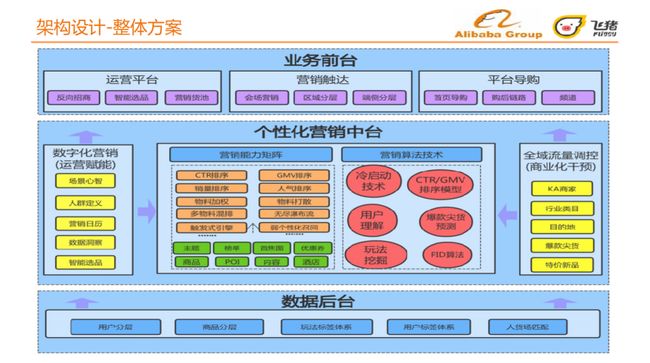
整体方案集成如图所示,从最底层往上依次是:数据后台、个性化营销中台、业务前台。
-
数据后台:用户分层、商品分层、玩法标签体系、用户标签体系、人货场匹配;
-
个性化营销中台:营销能力矩阵、营销算法技术、数字化营销、全域流量调控
-
业务前台:基于营销中台,提供运营平台、营销触达、平台导购。
03
个性化营销平台算法
下面我们将介绍飞猪个性化营销平台算法:
-
用户session理解
-
用户冷启动技术
-
旅游玩法标签体系建设
1. 用户session理解
① 背景
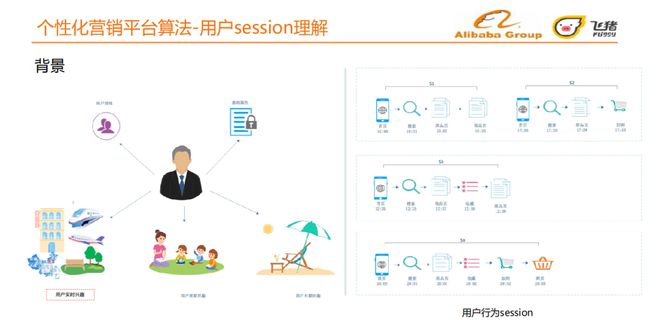
旅行场景下,用户兴趣可能来源于多方面:用户基础属性、用户群体属性、用户实时兴趣、用户周期兴趣、用户长期兴趣。
-
用户基础属性:年龄、性别、购买力、地理属性等,其中地理属性包括用户所在地是几线城市,用户是在老家还是新的工作地等。
-
用户群体:用户是白领或学生,用户朋友圈的组成等。
本次我们会重点介绍用户实时兴趣的挖掘,也就是用户session理解。
用户session 中会有以下行为:首页、搜索、商品页、收藏、加购、购买。完整的session从进入首页直到完成购买,期间可能发生若干次搜索、商品页、收藏、加购行为。但是常见session并不完整,往往未完成购买就会退出APP。针对不同的session,我们会进行session理解。
② 用户行为网络抽象
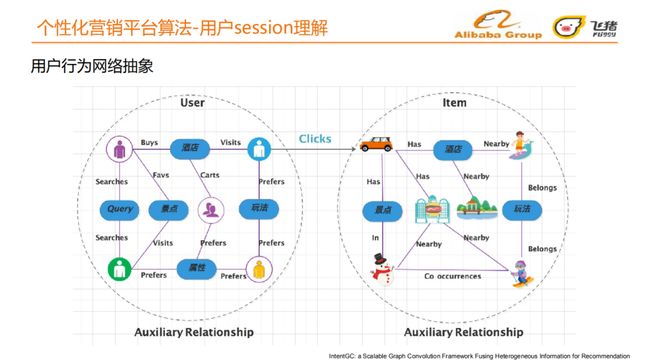
用户行为session中产生一次点击Item的行为,有很多附加关系可以利用,这种附加关系可以用异构图的形式表现[1]。
-
用户侧可以构成一张关系图:提交Query 、加购商品,收藏景点等,用户还会有一些自身的属性 ,如年龄性别等。
-
Item侧也可以构成关系图:以门票为例,门票即一个景点,景点旁可能有酒店、景点本身有一些玩法元素,景点可能有专车接送之类的服务元素。
③ 用户行为构建图网络
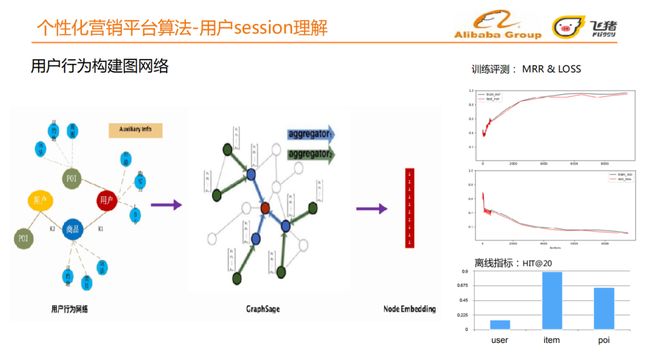
我们根据上节的抽象,构建了用户行为网络。具体来说,我们将用户到商品的行为抽象为一个网络结构图,采取了GraphSAGE[2]的做法,训练主要节点的Embedding。主要节点有用户、商品、POI。用户本身有一些属性,如年龄、LBS、购买力等也会作为附加节点和主要节点建立边。
-
训练评测:MRR接近0.96,loss低于0.15。
-
离线评测:取HIT@20这个指标,User命中率不高,可能因为User链特别大,整体数据稀疏导致。对Item和POI的命中率都较高,Item约为 0.88,POI约为0.65。
④ 用户行为session表达
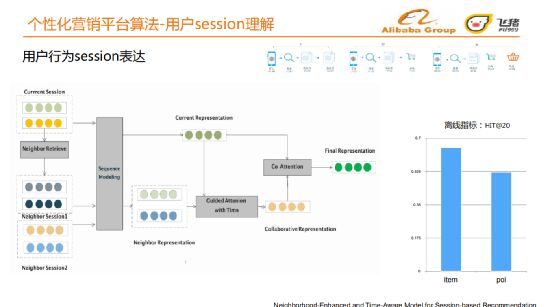
基于上节介绍的用户行为session中的节点向量表达,我们进而构建用户行为session的表达[3]。我们首先检索与当前session有协同信息的邻居session。邻居检索:根据当前session有哪些item,粗筛出有相同item的session,再根据最大覆盖原则选出自身有多个item和当前session相同的邻居session。
当前session的通过long-term加short-term方式学习到当前表达:
-
long-term:attention机制
-
short-term:当前session最近一次行为过的item的节点的embedding
-
由long-term和short-term一起经过一个全连接生成当前表达
邻居session通过global encoder加local encoder方式学习邻居表达:
-
global encoder:每个邻居session通过GRU生成表达
-
local encoder:所有邻居session做一个聚合
邻居表达通过Guided Attention with Time-aware机制经当前表达指导提出取协同表达后,当前表达和协同表达通过Co Attention机制学习到最终表达。离线在item集上评测,HIT@20 约为0.6,POI上约为0.49。
2. 用户冷启动技术
① 背景
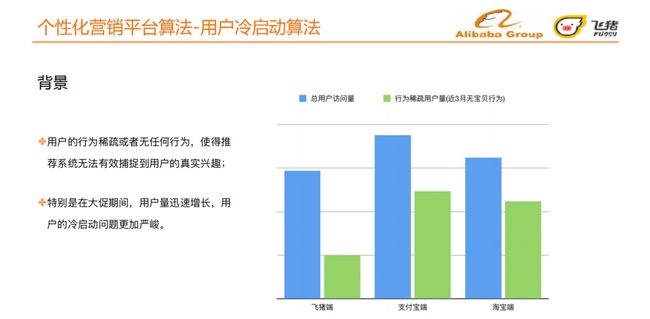
我们将近最近3月没有任何行为的用户划分为冷启动用户 ,冷启动用户在飞猪、淘宝、支付宝三端占比都很高。用户的行为稀疏或者无任何行为,使得推荐系统无法有效捕捉到用户的真实兴趣,特别是在大促期间,用户量迅速增长,用户的冷启动问题更加严峻。
② 基于层次主题知识的召回
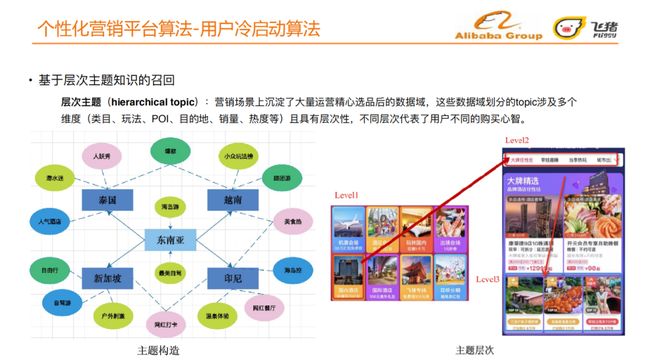
营销场景上沉淀了⼤量运营根据行业知识精⼼选品后的数据域,这些数据域划分的topic涉及多个维度 ( 类⽬、玩法、POI、⽬的地、销量、热度等 ) 且具有层次性,不同层次代表了⽤户不同的购买心智。
以图中右侧为例,从level 1中可以获得用户对于类目的偏好,从level2中可以获得用户对于不同玩法的偏好。我们在不同层次学习用户不同的购买心智,通过不同数据域的偏好去映射得到用户可能偏好的一些宝贝。
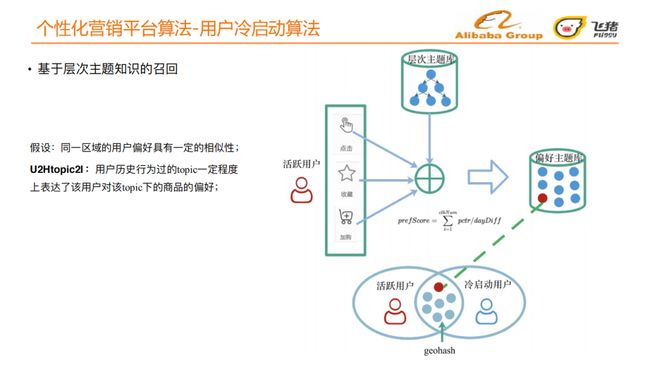
航旅背景下,目的地是重点考虑的维度。同一区域的用户,朋友、亲属关系往往比较集中,分布比较一致,同⼀区域的⽤户偏好具有⼀定相似性这一现象更加明显。
我们据此提出U2Htopic2I:
-
选取一批飞猪的活跃用户 ,根据活跃用户的点击、收藏、加购行为得出一个用户对层次主题的偏好打分,考虑到航旅背景的特点,我们对用户的行为加入了时间衰减因子,最终得到一个偏好主题库;
-
将冷启动用户的区域性映射到偏好主题库上,从而召回用户可能偏好的主题,以及偏好主题下对应的宝贝信息。
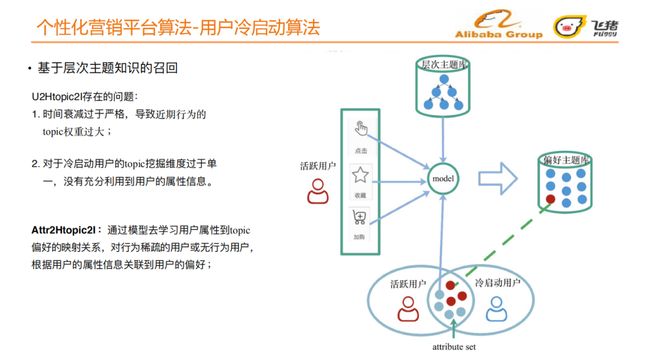
U2Htopic2I存在的问题:
-
时间衰减过于严格,导致近期⾏为的topic权重过⼤,并且该权重很难人工去调节;
-
对于冷启动⽤户的topic挖掘维度过于单 ⼀,没有充分利⽤到⽤户的属性信息。
我们据此提出Attr2Htopic2I:通过模型去学习⽤户属性到topic偏好的映射关系,对⾏为稀疏的⽤户或⽆⾏为⽤户, 根据⽤户的属性信息关联到⽤户的偏好。
Attr2Htopic2I同样是选取一批飞猪活跃用户,与U2Htopic2I不同在于,通过模型去预测历史活跃用户对层次主题的偏好。通过冷启动用户的属性集,将其映射到偏好主题库上,从而召回用户可能感兴趣的宝贝。
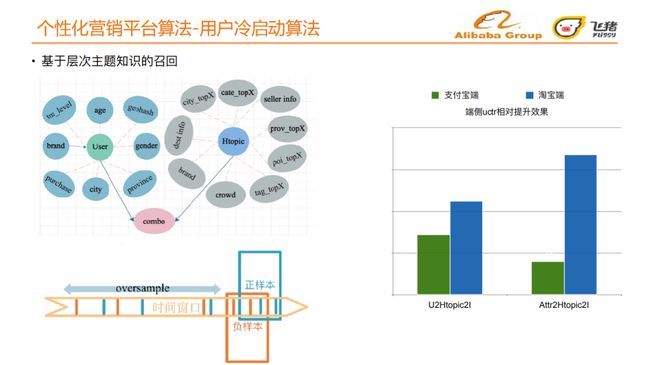
用户侧我们提取用户的静态信息,因为对冷启动用户而言,我们只能利用到用户的基本属性,如年龄、性别、区域信息、购买力等。层次主题一侧我们提取层次主题的标签信息,如人群、品牌、目的地区域、玩法等。
用户历史行为过的层次主题的数据量极大,为使模型更好地学习用户的层次主题偏好我们采取如下方式构造样本空间,增大正负样本的差异性:
-
正样本:用户最近行为过,且点击率比较高的层次主题;
-
负样本:最近曝光较多,但用户没有产生点击的样本。
线上测试结果显示,U2Htopic2I在淘宝端带来了2个点的提升,Attr2Htopic2I在U2Htopic2I的基础上,在淘宝端带来4个点的提升,效果明显。
③ 基于用户跨域映射的召回

背景:三端稀疏⾏为⽤户占⽐33.9% ( fliggy )、69.0% ( taobao )、65.8% ( alipay ),仅采⽤飞猪本场景数据难以覆盖这么⼤⽐例的冷启动⽤户。
思想:跨领域特征映射,将⽤户在淘宝的⾏为特征向量映射到飞猪⾏为特征向量。
数据有效性和想法可行性:
-
飞猪用户和手淘用户的交集比例很高;
-
手淘端的部分宝贝行为和航旅宝贝具有一定的关联性,如一个用户近期在手淘端有沙滩鞋、沙滩裤、泳装等行为,我们认为该用户可能有海滨度假的需求,当他来到飞猪端时,我们就给他投放相应的宝贝。
模型构造:
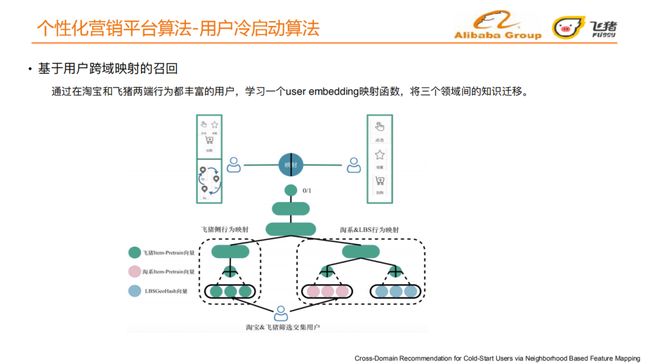
通过在淘宝和飞猪两端⾏为都丰富的⽤户,学习⼀个user embedding映射函数,将三个领域间的知识迁移[4]。用户在淘宝端的用户画像,除了用户的点击收藏加购外,我们引入了对于航旅场景下非常重要的用户LBS行为序列信息。用户飞猪端行为序列生成飞猪侧向量表达,用户在手淘端的行为序列、LBS属性和用户属性信息生成手淘端向量表达。上述两个表达共同输入一个两层的全连接网络,学习到user的embedding。
训练时,我们选取在飞猪端和淘宝端都有行为的交集用户。线上召回时,我们把冷启动用户在手淘端的行为序列、用户属性和LBS信息输入网络,得到一个隐藏层的embedding,作为用户在飞猪端的用户画像。根据隐藏层的embedding,计算其与宝贝embedding向量的相似度,召回飞猪端与其相似度最高的top@N的宝贝。
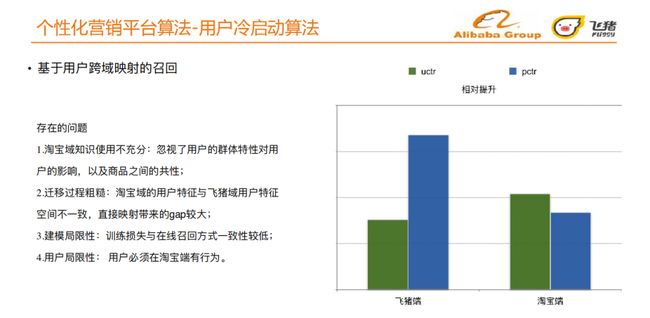
上面的方法在飞猪端带来1到2个百分点的uctr提升,在淘宝端带来了2个百分点的uctr提升。但是同时也存在以下几个问题:
-
淘宝域知识使⽤不充分:忽视了⽤户的群体特性对⽤户的影响,以及商品之间的共性;
-
迁移过程粗糙:淘宝域的⽤户特征与⻜飞猪域⽤户特征空间不⼀致,直接映射带来的gap较⼤;
-
建模局限性:训练损失与在线召回⽅式⼀致性较低;
-
⽤户局限性:⽤户必须在淘宝端有⾏为。
④ 基于异构关系的冷启动建模
我们将用户与用户、用户与宝贝、宝贝与宝贝之间这种不同的关系称为异构关系[5]。
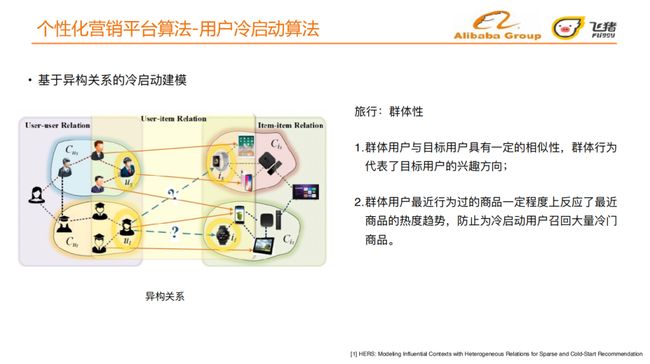
旅行具有群体性:
-
群体⽤户与⽬标⽤户具有⼀定的相似性,群体⾏为代表了⽬标⽤户的兴趣⽅向;
-
群体⽤户最近⾏为过的商品⼀定程度上反应了最近商品的热度趋势,防⽌为冷启动⽤户召回⼤量冷⻔商品。
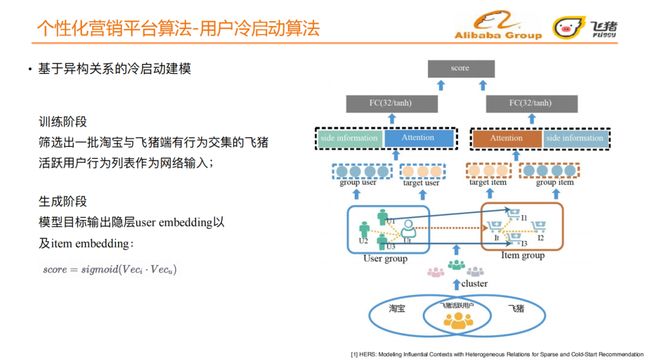
训练阶段:
筛选出一批淘宝和飞猪双端的活跃用户,将活跃用户在淘宝端的用户行为序列和LBS信息通过聚类得到user group;将user group最近行为过的历史宝贝和目标宝贝组成一个item group,通过这种方式引入了用户与用户、用户与宝贝以及宝贝与宝贝之间的异构关系;分别将这两个group输入attention网络中,学习目标用户和user group之间的相似度,目标宝贝和item group之间的相似度,再分别加上用户侧的side information以及宝贝侧的side information;再分别经过一个全连接网络,得到user embedding和item embedding;最后计算embedding向量之间的相似度。
生成阶段:
将冷启动用户在淘宝端的行为序列、LBS信息及user侧的属性信息输入网络;得到模型⽬标输出隐层user embedding以及item embedding;利用user embedding和item embedding对冷启动用户进行召回,返回top@N的宝贝推荐。
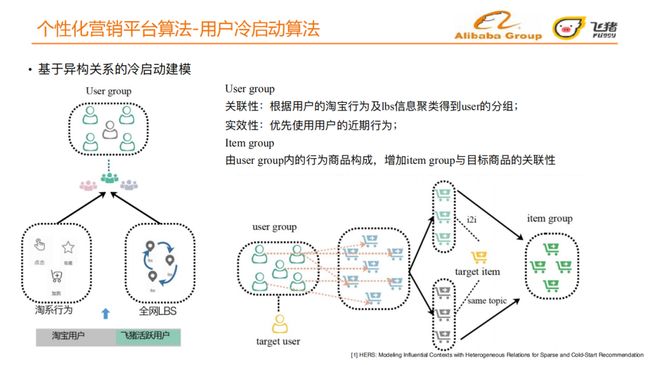
我们进一步介绍user group和item group的构建。
user group:
-
关联性:根据⽤户的淘宝⾏为及lbs信息聚类得到user group,判断user group最近行为过的宝贝是否与目标宝贝是同一主题,或者看user group行为过的宝贝是否在目标宝贝i2i可召回列表中;
-
实效性:优先使⽤⽤户的近期⾏为。
item group:
-
由user group内的⾏为商品构成,增加item group与⽬标商品的关联性
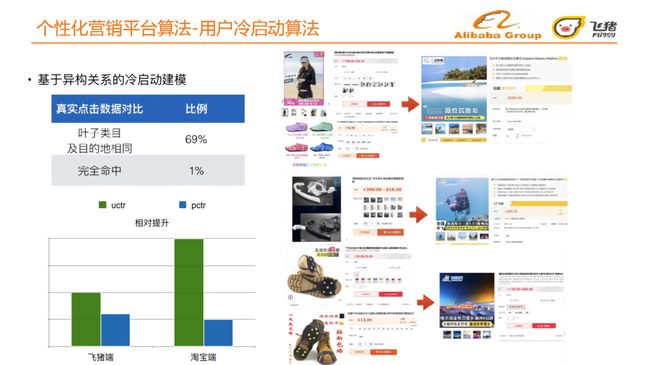
离线评估,我们从真实点击数据对比中看出,叶子类目及目的地相同的比例达到69%,完全命中的比例达到1%。上图右侧我们列举了几个线上真实召回的案例,如用户在淘宝端行为过潜水镜、沙滩鞋,我们则召回了关于海岛、潜水方面的宝贝,用户在淘宝端行为过防滑鞋套,我们据此召回了雪乡相关的宝贝。
3. 旅游玩法标签体系建设
我们将分为4个方面介绍玩法标签体系建设:玩法标签生产与挖掘、玩法标签树建设、玩法标签树挂载、玩法标签的应用。
① 玩法标签挖掘与生产
难点和挑战:数据覆盖更全面、更准确,同时精细化地绑定到宝贝上。
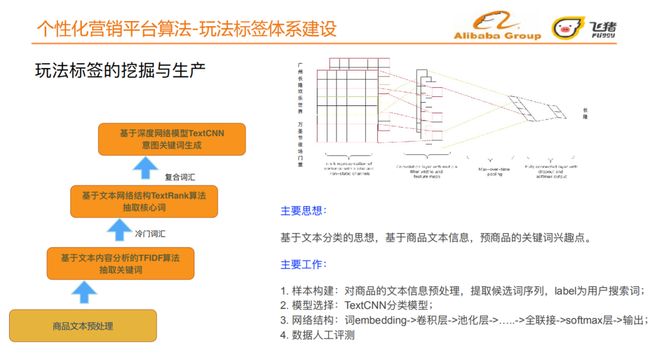
玩法标签的挖掘与生产的迭代过程:
-
基于⽂本内容分析的TF-IDF算法抽取关键词
-
基于⽂本⽹络结构TextRank算法抽取核⼼词
-
基于深度⽹络模型TextCNN 意图关键词⽣成
主要思想:基于⽂本分类的思想,基于商品⽂本信息,预测商品的关键词兴趣点
主要⼯作:
-
样本构建:对商品的⽂本信息预处理,提取候选词序列,label为⽤户搜索词
-
模型选择:TextCNN分类模型
-
⽹络结构:词embedding->卷积层->池化层->…..->全联接->softmax层->输出
-
数据⼈⼯评测
② 统一的玩法标签树体系
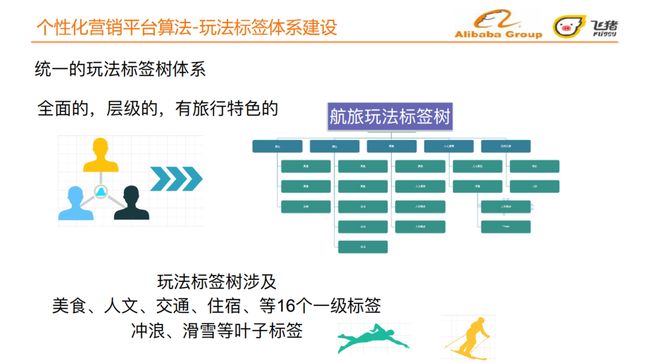
在挖掘和生产了大量符合用户感知的玩法标签后,我们需要构建全⾯的,层级的,有旅⾏特⾊的统⼀玩法标签树体系。我们借助行业运营的经验与知识,构建了自由的航旅玩法标签树,其中涉及了美食、⼈⽂、交通、住宿等16个⼀级标签,叶子结点则包括冲浪、滑雪等具体玩法。
③ 玩法标签的挂载
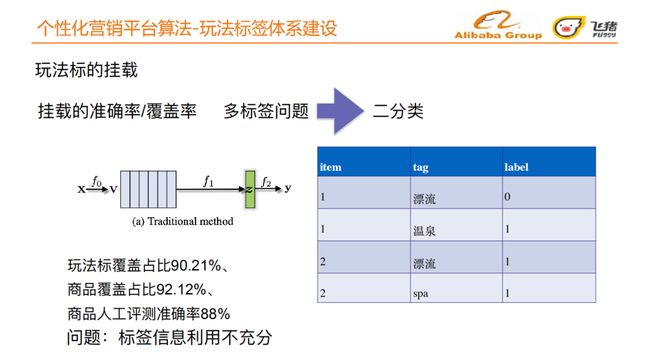
在构建好玩法标签树之后,我们需要将标签准确的挂载到宝贝之上。一个宝贝可以拥有多个玩法标签,玩法标签挂载本质上是一个多标签问题,我们将其拆解为多个二分类问题。飞猪团队最初采取传统的机器学习方法。我们取得了玩法标覆盖占⽐90.21%、 商品覆盖占⽐92.12%、 商品⼈⼯评测准确率88%的结果。传统方法存在标签信息利用不充分的问题,人工评测准确率依然有可提高的空间。
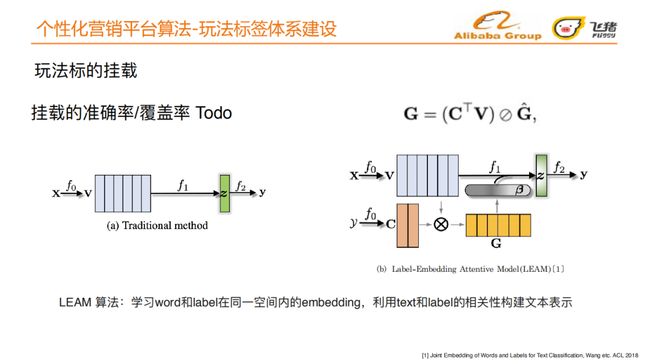
传统方法将挂载过程拆成3个部分,f0是学习文本关键词的embedding,f1是抽象出整个文本的embedding,f2是一个挂载模型,全程都没有利用到标签信息。
我们采用LEAM[6] 算法:学习word和label在同⼀空间内的embedding,利⽤text和label的相关性构建⽂本表示,提高挂载准确率。

我们将玩法标签准确挂载在宝贝上后,可以有如下应用:
-
将飞猪常⽤的场景数据结构化沉淀出玩法标签
-
将这些结构化数据之间通过玩法标签建⽴关联匹配关系
-
玩法标签圈⼈、圈品投放
-
玩法主题⽣产、按场景玩法主题组织的投放
在实际的搜索界面,我们的标签会作为market-in set展示。
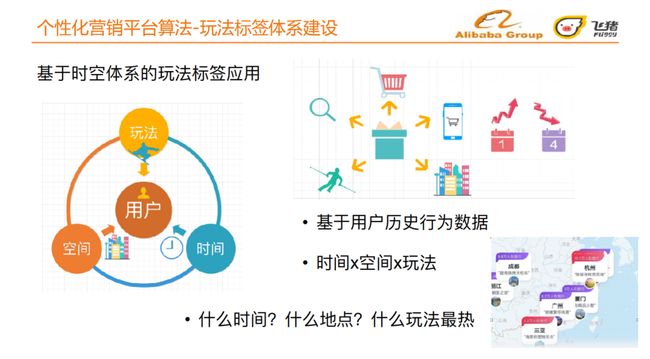
进一步,我们希望在时空的场景下,结合玩法进行更深层次的应用。我们会基于用户历史行为数据,得到宝贝每一天的点击、收藏、加购,宝贝的目的地等信息,并且宝贝已挂载相应的玩法标签。我们进一步借助时序分析的方法,得到该宝贝在什么时间、什么地点、什么玩法是最热门的,从而更好的服务用户在时间、空间、玩法三个维度辅助用户出行。
04
参考文献
[1]. Zhao, Jun, et al. "IntentGC: a Scalable Graph Convolution Framework Fusing Heterogeneous Information for Recommendation." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
[2]. Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." Advances in neural information processing systems. 2017.
[3]. Lv, Yang, Liangsheng Zhuang, and Pengyu Luo. "Neighborhood-Enhanced and Time-Aware Model for Session-based Recommendation." arXiv preprint arXiv:1909.11252 (2019).
[4]. Wang, Xinghua, et al. "Cross-domain recommendation for cold-start users via neighborhood based feature mapping." International Conference on Database Systems for Advanced Applications. Springer, Cham, 2018.
[5]. Hu, Liang, et al. "Hers: Modeling influential contexts with heterogeneous relations for sparse and cold-start recommendation." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
[6]. Wang, Guoyin, et al. "Joint embedding of words and labels for text classification." arXiv preprint arXiv:1805.04174 (2018).