关于MNIST手写数字识别的几种实现方式
文章概要
由于我最近刚刚学习深度学习,就打算从深度学习中的“Hello world”(MNIST)开始,本文将包含以下几个内容
- SVM实现手写数字识别
- 感知机实现手写数字识别
- AlexNet实现手写数字识别
关于数据集
MNIST数据集的下载链接
从官网的介绍中,我们发现
| CLASSIFIER | TEST ERROR RATE (%) |
|---|---|
| SVM, Gaussian Kernel | 1.4 |
| 2-layer NN, 300 hidden units, mean square error | 4.7 |
| Convolutional net LeNet-4 | 1.1 |
这里,我这是挑几个跟我实现方法相关的例子,大部分模型在MNIST上的分类精度都超过了95%。为了更直观观察算法之间的差异,也可以使用内容更加复杂的Fashion-MNIST,可以参考动手学深度学习


训练样本是60000张(10类),测试样本是10000张(10张)
从官网的介绍来看,数据的存储格式是大端模式(比如我们常见的字节高位在内存的高地址,低位在内存的低地址,而大端模式是相反的过程)。

解压到项目文件夹中
关于SVM
关于SVM的介绍,有一些博客讲解的非常详细了,这里推荐一些讲解非常好的博客
【ML】支持向量机(SVM)从入门到放弃再到掌握
SVM入门经典讲解(相当好)
加载数据集
'''
返回标签和图像的np数组
'''
def load_mnist(path,kind='train'):
# 路径,相当于字符串拼接
labels_path = os.path.join(path,'%s-labels.idx1-ubyte'%kind) # 标签路径
images_path = os.path.join(path, '%s-images.idx3-ubyte' % kind) # 图像路径
with open(labels_path, 'rb') as lbpath:
# 标签8位
magic, n = struct.unpack('>II', lbpath.read(8)) #读取一个字节
labels = np.fromfile(lbpath, dtype=np.uint8)
with open(images_path,'rb') as imgpath:
# 大端模式,数据16位
magic, num, rows, cols = struct.unpack(">IIII", imgpath.read(16)) # 读取两个字节
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
return images,labels
进行训练
'''
采用sklearn的svm函数
'''
X_train, y_train = load_mnist('', kind='train') # 加载训练集
test_images, test_labels = load_mnist('',kind='t10k') # 加载测试集
X = preprocessing.StandardScaler().fit_transform(X_train)
X_train = X[0:60000] # 训练60000张
y_train = y_train[0:60000]
print('time is ' + time.strftime('%Y-%m-%d %H:%M:%S'))
model_svc = svm.SVC(kernel = 'sigmoid',gamma='scale') # 使用sigmoid核
model_svc.fit(X_train,y_train)
print('time is ' + time.strftime('%Y-%m-%d %H:%M:%S'))
x = preprocessing.StandardScaler().fit_transform(test_images)
x_test = x[0:10000]
y_pred = test_labels[0:10000]
print(model_svc.score(x_test, y_pred)) # 根据训练的模型,进行分类得分计算
y = model_svc.predict(x) # 进行预测,能得到一个结果
输出结果

我们训练了60000张,同时采用sigmoid核,但是正确率并没有达到95%。我尝试改变一下核函数。
model_svc = GridSearchCV(SVC(), param_grid={"C": [0.1, 1, 10], "gamma": [1, 0.1, 0.01]}, cv=4)
感知机
多层感知机
深度学习入门-感知机
本文采用的感知机模型是多层感知机,实现起来比较简单
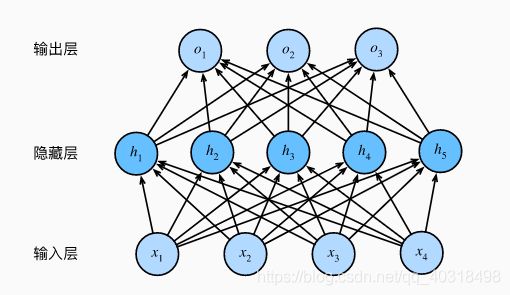
训练模型
batch_size = 200
num_inputs = 784 # 28x28
num_hiddens = 256 # 隐藏层的个数
lr = 0.01 # 学习率
'''
定义模型
'''
net = nn.Sequential()
net.add(nn.Dense(num_hiddens,activation ='relu'),nn.Dense(num_outputs)) # 定义2层感知机模型
net.initialize(init.Normal(sigma=0.01))
'''
交叉熵损失函数
'''
loss = gloss.SoftmaxCrossEntropyLoss()
train_iter, train_labels = load_mnist('', kind='train') # 6000x10,28x28
Test_of_imgs, Test_of_imgs_labels = load_mnist('',kind='t10k') # 上面的加载函数
# net.collect_params会初始化所有参数,采用梯度下降
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': lr, 'momentum': 0, 'wd': 0})
'''
训练好模型后,需要测试准确率
'''
def evaluate_accuracy(net):
acc_sum,n = 0.0,0
X = nd.array(Test_of_imgs)
y = nd.array(Test_of_imgs_labels)
y = y.astype('float32')
acc_sum +=(net(X).argmax(axis=1)==y).sum().asscalar()
n +=y.size
return acc_sum/n
num_epochs = 20
X = nd.array(train_iter) # 训练矩阵
y = nd.array(train_labels) # 标签
def train():
loss_list = [] # 损失函数的值
acc_list = [] # 训练准确率
test_acc_list = [] # 测试准确率
print("训练开始")
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
# 一次训练batch_size的数据.
for time in range(int(60000/batch_size)): # 0 - 43
# 0-42
Train_iter = train_iter[time*batch_size:time*batch_size+batch_size]
Train_labels = train_labels[time*batch_size:time*batch_size+batch_size]
X = nd.array(Train_iter) # 训练矩阵
y = nd.array(Train_labels) # 标签
with d2l.autograd.record():
y_hat = net(X)
l = loss(y_hat, y).sum() #损失函数
l.backward()
if trainer is None:
d2l.sgd(params, lr, batch_size)
else:
trainer.step(batch_size)
y = y.astype('float32')
train_l_sum += l.asscalar() # 训练总损失
# y_hat is 4000x10
# 行中的最大值axis
#print(y_hat.argmax(axis=1))
train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar() # 分类正确的数量
n += y.size # 总样本
test_acc = evaluate_accuracy(net)
loss_list.append(train_l_sum / n)
acc_list.append(train_acc_sum / n)
test_acc_list.append(test_acc)
if (epoch%5==0):
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f,n is %d'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc,n))
return loss_list,acc_list,test_acc_list
train()
训练结果
隐藏层的个数 = 256

从上图可以看出来,随着训练次数的增加,损失函数的值先下降后上升,准确率也一样(波动性比较大),说明函数可能出现过拟合的现象(也可能是模型的选择不好)
训练准确率最大达到81.0%,测试准确率最大达到79.6%
隐藏层个数300
参考手写数字识别

随着训练轮数的增加,发现损失函数的值在下降,训练和测试的准确率基本往上提高。
训练准确率最大达到91.5%,测试准确率最大达到91.3%
采样丢弃层,丢弃概率0.2
在第一个全连接层后添加丢弃层(nn.Dropout(0.2))
网络参数过多,可能会出现过拟合的现象,参考 丢弃法

训练准确率最大达到93.0%,测试准确率最大达到95.4%
尝试增加一层隐藏层
隐藏层1 = 300
隐藏层2 = 128

可以看出增加了一层隐藏层的效果比没有增加一层的效果要好很多。
训练准确率最大达到100%,测试准确率最大达到98.3%
| 网络 | 训练准确率(20轮) | 测试准确率(20轮) |
|---|---|---|
| 隐藏层1 = 256 | 81.0% | 79.6% |
| 隐藏层1 = 300 | 91.5% | 91.3% |
| 隐藏层1 = 256,丢弃层1丢弃概率0.2 | 93.0% | 95.4% |
| 隐藏层1 = 300,隐藏层2 = 128 | 100% | 98.3% |
| 隐藏层1 = 256,丢弃层1丢弃概率0.2;隐藏层2 = 128 | 99.4% | 98.3% |
卷积神经网络
本文采用的神经网络模型是LeNet
吴恩达神经网络和深度学习
深度学习笔记(六)卷积神经网络

简单讲,输入层是32x32(本文是28x28),后接入一个卷积层,通道数6,核大小是5。接入一个步长为2,核大小是2的最大池化层,那么输出就是14x14x6。再接入一个卷积层,通道数是16,核大小是5。接入一个步长为2,核大小是2的最大池化层,那么输出就是5x5x16。接入一个全连接层,第一次是120,第二层是84,最后输出的类别是10。
数据加载
X_train, y_train = load_mnist("", kind="train") # 数据加载,np格式
X_test, y_test = load_mnist("", kind="t10k")
X_train = X_train.reshape((-1,1,28,28)) # 卷积层是28x28而不是786
X_test = X_test.reshape((-1,1,28,28))
X_train = nd.array(X_train) # 使用mxnet,转换成nd格式
X_test = nd.array(X_test)
y_train = nd.array(y_train)
y_test = nd.array(y_test)
一开始X_train的形状是(60000,784),转换成(60000,28,28),三维就够了,为什么是60000x1x28x28呢?
定义网络模型
'''
卷积层的定义
'''
def net():
net = nn.Sequential()
# 输入28x28
# 第一层之后就是28-5+1 = 24x24x6
# 池化层之后应该就是12x12x6
# 第三层之后就是12-5+1 = 8x8x16
# 池化层之后就是4x4x16
net.add(nn.Conv2D(channels=6,kernel_size =5,activation='sigmoid'),
nn.MaxPool2D(pool_size=2,strides =2),
nn.Conv2D(channels = 16, kernel_size = 5, activation = 'sigmoid'),
nn.MaxPool2D(pool_size =2 , strides = 2),
nn.Dense(120, activation='sigmoid'),
nn.Dense(84, activation='sigmoid'),
nn.Dense(10))
return net
训练模型
def train(batch_size,trainer,num_epochs):
print('training on')
loss_list = []
acc_list = []
test_acc_list = []
loss = gloss.SoftmaxCrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
# 训练集是60000张,那么我们每次取batch_size 的大小.
for i in range(int(60000/batch_size)):
X = X_train[i * batch_size: i * batch_size + batch_size]
y = y_train[i * batch_size: i * batch_size + batch_size]
with autograd.record():
y_hat = net(X)
l = loss(y_hat,y).sum()
l.backward()
trainer.step(batch_size)
y = y.astype('float32')
train_l_sum += l.asscalar()
train_acc_sum +=(y_hat.argmax(axis=1)==y).sum().asscalar()
n += y.size
test_acc = evaluate_accuracy(net)
loss_list.append(train_l_sum / n)
acc_list.append(train_acc_sum / n)
test_acc_list.append(test_acc)
print('epoch %d,loss %.4f,train acc %.3f,test acc %.3f,time %.1f sec'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc, time.time() - start))
return loss_list, acc_list, test_acc_list
训练结果

训练准确率最大达到98.6%,测试准确率最大达到98.4%
当然,也可以使用其他模型,比如AlexNet等等。这里我不做演示处理。
后续
在后续的过程中,将打算使用这三种方式识别一下模型更加复杂的Fashion-MNIST和车牌的识别,当然也包括更多的轮数等等。这些源码将会在最近的更新中上传到我的github中。
由于我处理刚学习阶段,难免会出现常识性错误,恳请各位大牛批评指正。我写下此笔记的目的是为了方便以后复习使用。