PySpark 基础知识-RDD 弹性分布式数据集 和 DataFrame
1.RDD(弹性分布式数据集)创建
- 第一种:读取一个外部数据集。比如,从本地文件加载数据集,或者从HDFS文件系统、HBase、Amazon S3等外部数据源中加载数据集。
- 第二种:调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
>>> data = sc.parallelize(range(10))
>>> data.collect()
[Stage 0:> (0 + 4) / 4]
[Stage 0:==============> (1 + 3) / 4]
[Stage 0:=============================> (2 + 2) / 4]
[Stage 0:============================================> (3 + 1) / 4]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]自定义分区数量
>>> data1 = sc.parallelize(range(10), 5)
>>> data1.foreach(print)
[Stage 6:> (0 + 4) / 5]
4
5
[Stage 6:===========> (1 + 4) / 5]
6
7
[Stage 6:=======================> (2 + 3) / 5]
2
3
[Stage 6:===================================> (3 + 2) / 5]
0
1
[Stage 6:===============================================> (4 + 1) / 5]
8
92.从HDFS创建:
line = sc.textFile('hdfs://localhost:9000/user/mashu/rdd/word_rdd.txt')
line = sc.textFile('./rdd/word_rdd.txt')
line = sc.textFile('/user/mashu/rdd/word_rdd.txt')从外部文件:
>>> data_from_file = sc.textFile('D:\data\data1.txt')
>>> data_from_file.take(2)
[Stage 1:> (0 + 1) / 1]
['blue black white', '1 2 3 ']2.RDD操作(transformation 和 action)
- 转换(Transformation): 基于现有的数据集创建一个新的数据集。
- 行动(Action):在数据集上进行运算,返回计算值。
1.转换
filter(func):筛选出满足函数func的元素,并返回一个新的数据集
>>> data = sc.parallelize(range(10))
>>> data_filter = data.filter(lambda x: x%2 == 0).collect()
[Stage 7:> (0 + 4) / 4]
[Stage 7:==============> (1 + 3) / 4]
[Stage 7:=============================> (2 + 2) / 4]
[Stage 7:============================================> (3 + 1) / 4]
>>> data_filter
[0, 2, 4, 6, 8]map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
>>> data_map = data.map(lambda x: x *2)
>>> data_map.collect()
[Stage 8:> (0 + 4) / 4]
[Stage 8:==============> (1 + 3) / 4]
[Stage 8:=============================> (2 + 2) / 4]
[Stage 8:============================================> (3 + 1) / 4]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> list = ['Hadoop','Spark','Hive','Spark', 'Spark']
>>> rdd_list = sc.parallelize(list)
>>> map_list = rdd_list.map(lambda x: (x, 1))
>>> map_list.foreach(print)
[Stage 25:> (0
('Spark', 1)
('Spark', 1)
('Spark', 1)
('Hive', 1)
('Hadoop', 1)
>>> map_list.reduceByKey(lambda x, y: x+y).foreach(print)
('Hadoop', 1)
('Spark', 3)
('Hive', 1)flatMap(func):与map()相似
>>> data_flatmap = data.flatMap(lambda x: (x, x+100))
>>> data_flatmap.collect()
[Stage 9:> (0 + 4) / 4]
[Stage 9:==============> (1 + 3) / 4]
[Stage 9:=============================> (2 + 2) / 4]
[Stage 9:============================================> (3 + 1) / 4]
[0, 100, 1, 101, 2, 102, 3, 103, 4, 104, 5, 105, 6, 106, 7, 107, 8, 108, 9, 109]尽量少使用,使用reduceByKey代替
groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合
>>> data_new = sc.parallelize([('a', 4),('b', 3),('c', 2),('a', 8),('d', 2),('b, 1),('d',3)])
>>> data_key = data_new.reduceByKey(lambda x, y: x+y)
>>> data_key.collect()
>>> [('b', 4), ('c', 2), ('a', 12), ('d', 5)]countByKey()
>>> data_new.countByKey().items()
[Stage 12:> (0 + 4) / 4]
dict_items([('a', 2), ('b', 2), ('c', 1), ('d', 2)])sample() 返回数据中随机抽样的数据集
>>> data_sample = data.sample(False, 0.2, 666)
>>> data_sample.collect()
[Stage 17:> (0 + 4) / 4
[Stage 17:==============> (1 + 3) / 4
[Stage 17:=============================> (2 + 2) / 4
[Stage 17:===========================================> (3 + 1) / 4
[3, 8]
data_sample = data.sample(False, 0.1, 666) #参数1 采样是否被替换;采样率;随机种子2. action操作
count() 返回数据集中的元素个数collect() 以数组的形式返回数据集中的所有元素,转换到硬盘中,速度慢first() 返回数据集中的第一个元素take(n) 以数组的形式返回数据集中的前n个元素reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素foreach(func) 将数据集中的每个元素传递到函数func中运行
>>> data.count()
[Stage 18:> (0 + 4) / 4]
[Stage 18:==============> (1 + 3) / 4]
[Stage 18:=============================> (2 + 2) / 4]
[Stage 18:===========================================> (3 + 1) / 4]
10
>>>
>>> data.collect()
[Stage 19:> (0 + 4) / 4]
[Stage 19:==============> (1 + 3) / 4]
[Stage 19:=============================> (2 + 2) / 4]
[Stage 19:===========================================> (3 + 1) / 4]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
>>> data.first()
[Stage 20:> (0 + 1) / 1]
0
>>>
>>> data.take(3)
[Stage 21:> (0 + 1) / 1]
[Stage 22:> (0 + 1) / 1]
[0, 1, 2]
>>>
>>> data.reduce(lambda x, y: x+y)
[Stage 23:> (0 + 4) / 4]
[Stage 23:==============> (1 + 3) / 4]
[Stage 23:=============================> (2 + 2) / 4]
[Stage 23:===========================================> (3 + 1) / 4]
45
>>>
>>> data.foreach(print)
[Stage 24:> (0 + 4) / 4]
0
1
[Stage 24:==============> (1 + 3) / 4]
2
3
4
[Stage 24:=============================> (2 + 2) / 4]
7
8
9
[Stage 24:===========================================> (3 + 1) / 4]
5
6小练习:
1.统计单词出现的数量,并按照数量从大到小进行排序。
from pyspark import SparkConf, SparkContext
conf = SparkConf()
sc = SparkContext(conf=conf)
file = r'D:\data\data3.txt'
rdd = sc.textFile(file)
rdd.flatMap(lambda line: line.split('\t')).collect()
#['spark', 'scala', 'python', 'spark', 'scala', 'hadoop', 'java']
rdd.flatMap(lambda line: line.split('\t')).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x+y).map(lambda x:(x[1], x[0])).sortByKey(False).\
map(lambda x: (x[1], x[0])).collect()
#[('scala', 2), ('spark', 2), ('python', 1), ('hadoop', 1), ('java', 1)]2.计算平均值
file2 = r'D:\data\data4.txt'
rdd_age = sc.textFile(file2)
rdd_age.collect()
['1 12',
'2 14',
'3 20',
'4 89',
'5 28',
'6 25',
'7 34',
'8 67',
'9 58',
'10 18']
rdd_list = rdd_age.map(lambda line: line.split(' ')[1])
n = rdd_list.count()
sum = rdd_list.map(lambda x: int(x)).reduce(lambda x, y: x+y) #先将字符转换成int 型
avg = sum / n
avg36.53.DataFrame
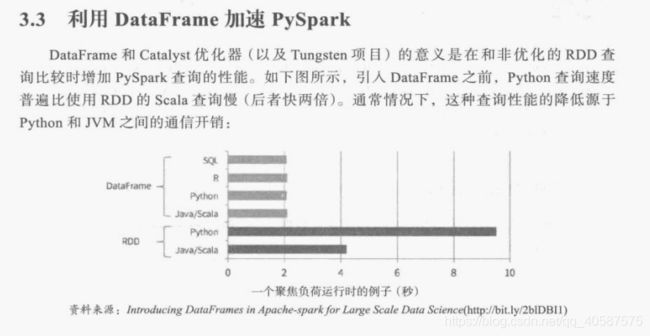
DataFrame与RDD 的区别
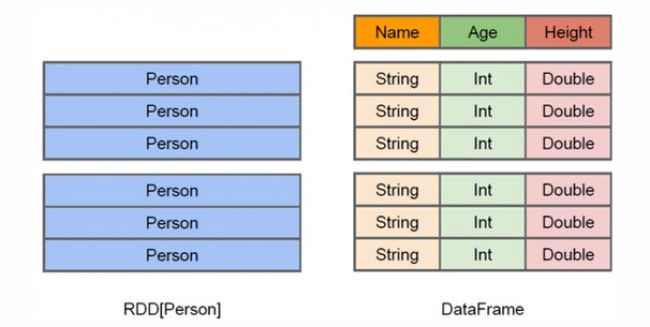
从上面的图中可以看出DataFrame和RDD的区别。RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。(from:http://dblab.xmu.edu.cn/blog/1718-2/)
创建DataFrame
有点类似pandas 的DataFrame
>>> stringJSONRDD = sc.parallelize(("""
... { "id": "123",
... "name": "Katie",
... "age": 19,
... "eyeColor": "brown"
... }""",
... """{
... "id": "234",
... "name": "Michael",
... "age": 22,
... "eyeColor": "green"
... }""",
... """{
... "id": "345",
... "name": "Simone",
... "age": 23,
... "eyeColor": "blue"
... }""")
... )
>>>
>>> df = spark.read.json(stringJSONRDD)
>>> df.show()
[Stage 29:> (0 + 1
[Stage 30:> (0 + 3
[Stage 30:===================> (1 + 2
+---+--------+---+-------+
|age|eyeColor| id| name|
+---+--------+---+-------+
| 19| brown|123| Katie|
| 22| green|234|Michael|
| 23| blue|345| Simone|
+---+--------+---+-------+
#使用sql 语句进行查询
>>> spark.sql("select age, id from swimmersJSON").show()
[Stage 20:> (0 + 1) / 1]
[Stage 21:> (0 + 3) / 3]
+---+---+
|age| id|
+---+---+
| 19|123|
| 22|234|
| 23|345|
+---+---+
RDD转换成DataFrame,并设置列数据的结构
#RDD 转换成 DataFrame
from pyspark.sql.types import *
stringCSVRDD = sc.parallelize([(123, 'Katie', 19, 'brown'), (234, 'Michael', 22, 'green'), (345, 'Simone', 23, 'blue')])
stringCSVRDD.collect()
[(123, 'Katie', 19, 'brown'),
(234, 'Michael', 22, 'green'),
(345, 'Simone', 23, 'blue')]from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
# sc = SparkContext("local")
spark = SparkSession(sc)
schemaString = "id name age eyeColor"
# 1.字段名称 2.字段数据类型 3.数据是否可以为空
schema = StructType([
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("age", LongType(), True),
StructField("eyeColor", StringType(), True)
])
swimmers = spark.createDataFrame(stringCSVRDD, schema)
swimmers.createOrReplaceGlobalTempView("swimmers") #创建临时视图
swimmers.show()+---+-------+---+--------+
| id| name|age|eyeColor|
+---+-------+---+--------+
|123| Katie| 19| brown|
|234|Michael| 22| green|
|345| Simone| 23| blue|
+---+-------+---+--------+swimmers.select("name", "eyeColor").filter("eyeColor like 'b%'").show()+------+--------+
| name|eyeColor|
+------+--------+
| Katie| brown|
|Simone| blue|
+------+--------+printSchema():打印信息
>>> df.printSchema()
root
|-- age: long (nullable = true)
|-- eyeColor: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)
select(df.id,df.name).show():选择指定列
>>> df.select(df.id, df.name).show()
[Stage 31:>
[Stage 32:>
+---+-------+
| id| name|
+---+-------+
|123| Katie|
|234|Michael|
|345| Simone|
+---+-------+filter(df.age > 20 ).show():过滤
>>> df.filter(df.age > 20).show()
[Stage 33:>
[Stage 34:>
+---+--------+---+-------+
|age|eyeColor| id| name|
+---+--------+---+-------+
| 22| green|234|Michael|
| 23| blue|345| Simone|
+---+--------+---+-------+groupBy("age").mean().show():分组聚合
>>> df.groupBy('name').mean().show()
[Stage 45:>
[Stage 45:==============>
+-------+--------+
| name|avg(age)|
+-------+--------+
| Katie| 19.0|
|Michael| 22.0|
| Simone| 23.0|
+-------+--------+sort(df.age.desc()).show(): / asc() 排序
>>> df.sort(df.age.desc()).show()
[Stage 55:>
+---+--------+---+-------+
|age|eyeColor| id| name|
+---+--------+---+-------+
| 23| blue|345| Simone|
| 22| green|234|Michael|
| 19| brown|123| Katie|
+---+--------+---+-------+
>>> df.sort(df.age.asc()).show()
[Stage 56:>
+---+--------+---+-------+
|age|eyeColor| id| name|
+---+--------+---+-------+
| 19| brown|123| Katie|
| 22| green|234|Michael|
| 23| blue|345| Simone|
+---+--------+---+-------+其他:
# 读取数据并创建DataFrame
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Python Spark Regression").config("spark.some.config.option", "some-value").getOrCreate()
# 创建 DataFrame
file = r'D:\data\spark\hour.csv'
data = spark.read.format('csv').option("header", "true").load(file)
data.show(5)+-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ |instant| dteday|season| yr|mnth| hr|holiday|weekday|workingday|weathersit|temp| atemp| hum|windspeed|casual|registered|cnt| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ | 1|2011-01-01| 1| 0| 1| 0| 0| 6| 0| 1|0.24|0.2879|0.81| 0| 3| 13| 16| | 2|2011-01-01| 1| 0| 1| 1| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 8| 32| 40| | 3|2011-01-01| 1| 0| 1| 2| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 5| 27| 32| | 4|2011-01-01| 1| 0| 1| 3| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 3| 10| 13| | 5|2011-01-01| 1| 0| 1| 4| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 0| 1| 1| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ only showing top 5 rows
data.select("*").distinct().count()
data.dropna().count()
data.dropDuplicates().count()
from pyspark.sql.functions import isnan, isnull
data1 = data.filter(isnull("instant"))
data1.count()》增加一列
data = data.withColumn("new_cnt", data.cnt / 2.0)
data.show(5)+-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+-------+ |instant| dteday|season| yr|mnth| hr|holiday|weekday|workingday|weathersit|temp| atemp| hum|windspeed|casual|registered|cnt|new_cnt| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+-------+ | 1|2011-01-01| 1| 0| 1| 0| 0| 6| 0| 1|0.24|0.2879|0.81| 0| 3| 13| 16| 8.0| | 2|2011-01-01| 1| 0| 1| 1| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 8| 32| 40| 20.0| | 3|2011-01-01| 1| 0| 1| 2| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 5| 27| 32| 16.0| | 4|2011-01-01| 1| 0| 1| 3| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 3| 10| 13| 6.5| | 5|2011-01-01| 1| 0| 1| 4| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 0| 1| 1| 0.5| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+-------+ only showing top 5 rows
# 应用于多个函数
data.groupby("season").agg(F.min("cnt"), F.mean("cnt"), F.sum("cnt")).show(5)+------+--------+------------------+---------+ |season|min(cnt)| avg(cnt)| sum(cnt)| +------+--------+------------------+---------+ | 3| 1|236.01623665480426|1061129.0| | 1| 1|111.11456859971712| 471348.0| | 4| 1|198.86885633270322| 841613.0| | 2| 1|208.34406894987526| 918589.0| +------+--------+------------------+---------+