Deep Learning in Autonomous Driving Cars
Deep Learning in Autonomous Driving Cars
- Forewords:
- Section 1: Introduction to autonomous driving technology
- Section 2: Application of deep learning algorithms in autonomous driving
- 2.1 Application of convolutional neural networks in environmental perception
- 2.2 Application of reinforcement learning algorithms in behavioral decision
- Section 3: Potential social and ethical issues associated with deep learning and autonomous driving
- Conclusion
- References
Forewords:
Both autonomous driving technology and deep learning have been extremely prevalent topics for a few years. What will happen when these two great ideas are combined? In this blog, I will introduce some deep learning algorithms form the perspective of autonomous driving. The whole blog can be divided into three sections. In the first section, the background knowledge of autonomous driving technology is introduced. In the second section, two prevalent deep learning technologies (convolutional neural networks and reinforcement learning) and the way they can be applied in solving autonomous driving tasks are introduced. In the third section, I will discuss some potential social and ethical problems brought by the application of deep learning in autonomous driving.
Section 1: Introduction to autonomous driving technology
Since the birth of mankind, each technological revolution has been accompanied by the liberation of a large number of productive forces and drastic changes in people’s lifestyles. About 12000 years ago, when the agricultural revolution began, much of the productivity in human society is liberated from the daily food gatherings. Men no longer have to risk their lives to hunt large animals, and women can sit at home for easier everyday tasks. About 160 years ago, thanks to the industrial revolution, most of the labor force was liberated from farmland and entered factories. Human productivity and living standards (average life expectancy, per capita carbon emissions, etc.) have therefore increased by thousands of times. Just as no one would have thought of the earth-shaking changes that the steam engine brought to human society at the beginning of the industrial revolution, with the development of information technology in recent years, we are likely to have entered a brand-new technological revolution-the artificial intelligence revolution. Just like the previous agricultural revolution and industrial revolution, the artificial intelligence revolution will affect all aspects of human society from the shallow to the deep. In this blog, I would like to talk about autonomous driving technology, which sounds not that sci-fi but still could have great impact on our life. Imagine that in the near future you will no longer have to spend weeks or even months learning to drive a car. Not only that, your personal driver (that is, your car itself) will have more driving skills and the lowest error rate than any previous human driver. You can finally free your hands and eyes during the journey, and your car will send you to your destination safely and comfortably. How cool will that be! More surprisingly, this dream is not that far from our life. Back in 2014, SAE (the Society of Automotive Engineers) established the first well known classification standard for autonomous driving. In a recent version released in 2018 [1], autonomous driving technique can be divided into six levels: L0 (no driving automation), L1(driver assistance), L2(partial driving automation), L3(conditional driving automation), L4(high driving automation) and L5 (full driving automation).
Nowadays, most of cars in the market are able to achieve L1. As suggested by the name (driver assistance), L1 level autonomous driving technology is essentially a driver assistance system. General components of such a driver assistance system include ABS (Anti-lock Braking System), ESC (Electronic Stability Control), ACC (Adaptive Cruise Control), etc. Moreover, many well-known car manufacturers have already equipped their products with L2 system. Autonomous driving systems in this level should be able to perform steering and acceleration automatically and simultaneously. However, the driver still needs to pay attention on the road condition and be well prepared to take over the control whenever necessary. The Super Cruise system developed by Cadillac is a good example of L2 autonomous driving system. This system was initially equipped on Cadillac CT6 model since 2017 (figure 1 [2]).

Figure 1 Cadillac CT6, equipped with Super Cruise system
After entering the super cruise mode, drivers can free their hands and feet from driving and their vehicles will automatically keep a proper distance from the vehicle in front and drive along the centerline of the road. In addition, as a L2 autonomous driving system, Cadillac Super Cruise requires the driver to keep their attention on the road in front by using a miniature camera. Another famous L2 autonomous driving system is Autopilot (Tesla). Furthermore, there is a L3 level autonomous driving system on the market: Traffic Jam Pilot (Audi). This autonomous driving module was initially equipped on Audi A8 in 2017. After entering the autonomous driving mode, the vehicle will be able to keep driving on a highway or multi-lane highway with oncoming traffic barriers at speeds up to 60km per hour. The reason why Traffic Jam Pilot was classified as a L3 autonomous driving system is that unlike Autopilot and Super Cruise, the driver does not need to pay attention to the road condition anymore and the car is fully in charge of itself once you enter autonomous driving mode. More surprisingly, Alphabet’s (GOOGL.O) Waymo have launched a L4 autonomous driving taxi service in Arizona (US) since last year (2019) after testing their autonomous driving technique on 600 vehicles, 10 million miles on public roads in and around 25 U.S. cities. On a Waymo One taxi, theoretically no human driver is needed anymore when the taxi is moving in a specific area (although in reality there will be a human driver sitting behind the steering wheel in case of an emergency). In general, most of the self-driving cars on the market currently belong to the L2 level. The L3 level of autonomous driving technology is less popular because it involves the transfer of control of people and vehicles. Some major autonomous driving technology companies are working to advance L4 level autonomous driving technology. The L5 technology, which truly realizes fully autonomous driving, is still far from practical applications.
So far, we have seen that autonomous driving vehicles are not far from our lives, but how does those autonomous driving vehicles drive themselves? In practical, autonomous driving technology can be divided into three subtasks: environment perception, behavioral decision (policy making) and vehicle control [3]. Among them, artificial intelligence is mainly involved in the first two tasks, so I will mainly talk about the first two tasks.
Environment perception, as the name suggests, smart vehicles need to sense the environment around itself so that a good policy can be made based on this information. Information need to be gathered in this phase includes the volume, location, velocity and acceleration of vehicles and passengers around the car, the information contained in road signs, speed limit signs and traffic lights, the road conditions in front of the vehicle, etc. Basically, most of these problems can be classified as (or transferred into) an object detection problem. To solve this object detection problem, usually many types of different sensors will be involved, including radar, lidar, cameras, etc. After that, raw data collected by those sensors will be preprocessed and then passed to segmentation and classification algorithms so that different objects can be detected. More details will be included in the second part of this blog.
The second task to be addressed to realizing autonomous driving is behavioral decision (policy making). That is to say, having the state information provided by the environment perception module, the smart vehicle needs now to work out a control command (acceleration, slow down, etc.) to the vehicle control module so that the car can arrived at its destination as soon as possible under the premise of ensuring safety and comfort. This task is normally divided into three layers (From macro to concrete): route planning layer, behavioral layer and motion planning layer. Route planning is to generate a route from departure point to destination considering the road condition nearby. This is not a problem anymore since we have a lot of professional navigation software (like google map) to use nowadays. The aim of behavioral layer is to provide a concrete behavioral decision (overtaking, lane changing, following, etc.) given the route and the information provided by the environmental awareness module (location and speed of surrounding cars, road signs, etc.). A lot of machine learning algorithms are available in this layer, including finite state machine, decision tree, inference system, artificial neural network, value-based reinforcement learning algorithm. At last, in the motion planning layer, a trajectory that meets a series of constrains will be generated based on the output command of the behavioral layer and the environmental information provided by the environmental awareness module. This trajectory will be the final output of the behavior decision module and the input of the vehicle control module.
Section 2: Application of deep learning algorithms in autonomous driving
Now we have a general understanding of how self-driving cars work. Let’s take a closer look at how artificial intelligence (machine learning) technology can help us solve engineering problems in the field of autonomous driving. Due to the page limit, I will mainly focus on the application of CNNs in solving environmental perception task and the application of reinforcement learning algorithms in solving behavioral decision task.
2.1 Application of convolutional neural networks in environmental perception
Let’s start from the environmental perception part. As I said in the first part, the main part of the environmental perception task is essentially an object detection problem. When it comes to object detection, the first combination that comes to our minds might be cameras plus convolutional neural networks (CNN).
I believe many people have heard of the famous names of convolutional neural networks. Since 2012 when the well-known CNN architecture AlexNet [4] was proposed, a new round of artificial intelligence boom has begun worldwide. The structure of a very basic CNN is shown below (figure 2 [5]). CNNs usually can be divided into two parts.
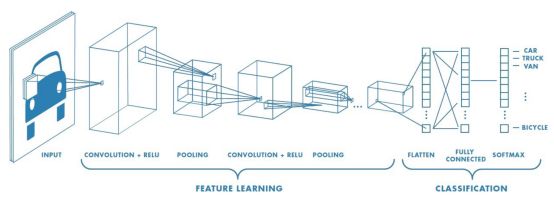
Figure 2 The basic structure of a convolutional neural network
The first part of a CNN is essentially a feature extraction network. It usually contains several convolutional blocks, each consist of one or more convolutional layer and their activation layer. For each convolution layer, a convolution kernel is used to capture local features from previous layer. Each convolution kernel corresponds to a specific local feature of the input image. This feature can be a very simple feature (horizontal edges, vertical edges, etc.) in shallower convolutional layers or very complex feature (a blurry human face, etc.) in deeper convolutional layers. After each convolutional layer, an activation layer (in which an activation function will be applied to every pixels of the output of the convolutional layer) is used to introduce non-linear factors to enhance the ability of neural networks to describe non-linear data. At the end of each convolutional block, a pooling layer (usually max pooling) is introduced to reduce the amount of data while further extracting main features. The second part of a CNN is a classifier, which is used to classify the input feature based on the features extracted by previous convolution blocks. In the figure above, the classifier is actually a fully connected neural network consists of a few fully connected layers and a softmax layer. A point worth noting is that the above figure only shows the very basic structure of a CNN. Commonly used CNN in recent years usually involves many more advance architectures like batch normalization layer, shortcut connection, etc.
In practical, cameras and CNN has already been used to address many different environmental perception tasks for autonomous driving tasks, especially in tasks like lane line detection and traffic sign detection. This is because lane line marks and traffic sign are designed for human visions and therefore cannot be detected by lidars and radars effectively. A point worth noting is that applying CNN directly on the image captured by cameras does not solve this problem. This is because CNN itself can only solve object classification problems, but not object detection problems, where we not only need to tell people what is in the image, but also tell people where is it in the image. Fortunately, we already have many CNN based object detection algorithms to use, including Faster R-CNN [6], YOLO [7], DenseBox [8], etc. Among them, Faster R-CNN is one of the main stream object detection algorithm in recent years. When using Faster R-CNN, initially the input image will be proposed by a series of convolutional layers, activation layers and pooling layers and a feature map corresponds to each input image will be produced. After this step, each pixel (across several channels) in the feature map represents a specific area in the original image. Then, the feature map will be passed to another neural network called region proposal network. In the region proposal network, k anchors will be attached to each pixel (across several channels) and each combination of pixel and anchor will be classified as positive (if there is an object in the specific anchor) or negative (if there is not an object in the specific anchor) by a softmax regressor. In addition, bounding box regression will be implemented to tune the position and size of those positive anchors. Then, the output of the region proposal network will be passed to a proposal layer and proposed regions will be represented by a vector looks like [x1, y1, x2, y2], where (x1,y1) and (x2, y2) are the coordinates of up left point and bottom right point of the proposed region in the original input image. At last, a ROI pooling layer is used to map the proposed region onto the feature map and a classifier composed of fully connected layers and softmax layer is used to classify the object in each proposed region. At the same time, bounding box regression will be carried again to further tune the position and the size of each anchor box. An overview of a classic VGG 16 based Faster R-CNN network is shown below (figure 3 [9]).
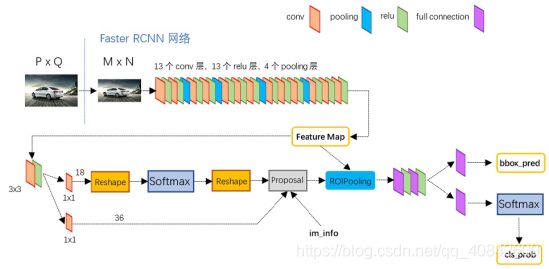
Figure 3 The basic structure of a Faster R-CNN
Now let’s come back to our lane line detection task and traffic sign detection task. Having an idea of the working principle of Faster R-CNN, it is clearly that the combination of cameras and Faster R-CNN is a potential solution to our lane line detection tasks and traffic sign detection tasks. In [10], authors proposed an improved Faster R-CNN model, in which multilayer feature maps and adaptive context information is used to increase the accuracy and sub-pixel sliding window is introduced to improve the ability to detect small objects. The propose CNN model was tested on two different lane marking datasets and result shows it achieves better accuracy than classic Faster R-CNN, especially on small lane line markings. In [11], a VGG 16 based Faster R-CNN algorithm is trained on a dataset provided by a traffic sign detection competition in 2016 by CCF and UISEE company and a mean precision value of 0.3449 was achieved. In another work [12], the authors build their Faster R-CNN model based on a combination of Inception v2, Resnet and Coco CNN and train it on the German Traffic Sign dataset [13]. The result show that their model is able to achieve a mean precision value of 0.7468, which is way better than the previous work [10]. This might imply that the overall performance of a Faster R-CNN model is heavily depends on the performance of its architecture used to generate the feature map. Moreover, many researches have shown that Faster R-CNN and its variations can be applied to many other object detection tasks in autonomous driving area, including [14][15].
Although using cameras and CNNs is a potential solution to the object detection tasks for autonomous driving vehicles, this combination has some natural limitations. One of the major limitations of this combination is that both cameras and CNNs are sensitive to many environmental factors like illumination. In addition, the spatial information (distance between objects) contained in the images collected by the camera is not as rich as lidar. Thus, many car producers (For example, Tesla) decide to build their environmental perception module based on lidar. Just like Radar, which is a device that actively emits radio waves to the outside world and collects reflected signals to determine the shape and position of objects. Lidar emits laser beam to the outside world and detect surrounding objects based on the reflected laser beams. The typical output data of a lidar is a set of point, which is usually called a point cloud. In object detection tasks, the first step is to divide the point cloud into different clusters, each corresponds to a specific object. Then, a classification algorithm is used to identify the class of each cluster. A typical detection result of such a lidar based object detection system is shown below (figure 4) [3]. There are many computer vision (Random Sample Consensus, Hough Transform) and traditional machine learning algorithms (support vector machine, random forest, etc.) can be used to deal with the point cloud data generated by lidars, but can we make it simpler and more accurate by combining lidar with CNN?

Figure 4 Point cloud generated by a lidar
The answer is yes. In [16], the authors proposed a region proposal algorithm based on Lidar data and combined it with a well -known CNN architecture (ResNet [17]) to detect pedestrians. They use Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm to cluster the preprocessed point cloud generated by a lidar and then project the clusters on to an RGB image generated by a camera and use them as regional proposals. These reginal proposals will then be classified by a fine-tuned ResNet. They test the proposed algorithm on KITTI data set and the results shows that the proposed algorithm achieve higher recall rate and fewer misses compared with the aforementioned Faster-RCNN algorithm.
In [18], CNN was used to detect surrounding vehicles from preprocessed point cloud data directly. The authors proposed to project point cloud data onto a 2-channel 2D point map and use a Fully Convolutional Network (FCN) to generate 3D bounding boxes for surrounding vehicles. Their proposed FCN architecture has two separate output layers both have the same 2D size as the input point map. One of them has two channels and is used to decide whether a point is on a surrounding vehicle. The other output layer has 24 channels and is used to predict the 3D bounding box of the vehicle corresponding to this point. They also test their algorithm on KITTI data set and claim a state-of-the art performance. Furthermore, in [19], the authors proposed a 3D CNN architecture called “VoxNet”(figure 5 [19]), which can be directly applied to classify segmented point cloud.
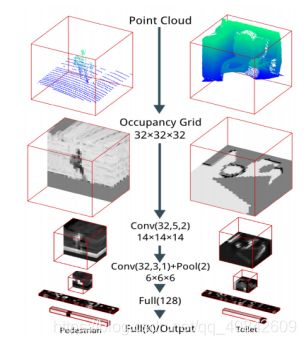
Figure 5 The basic structure of VoxNet
They transfer the unstructured point cloud to a 32 by 32 volumetric grid where each grid has an occupancy value. Then the 3D CNN is applied to detect and classify the object in the volumetric grid. The working principle of 3D CNN is similar to 2D CNN. The most significant difference is that in 2D CNN each convolutional layer may contain several 2D convolutional filters (each filter corresponding to a feature map), nevertheless, in 3D CNN each convolutional layer may contain several 3D convolutional filters. The proposed algorithm was tested on two different lidar data sets and shows better performance compared to existing classification algorithms. Moreover, there are still many research works aiming at applying CNN on handling point cloud generated by lidar [20] [21] [22] [23].
2.2 Application of reinforcement learning algorithms in behavioral decision
In this part I would like to talk about how can we apply deep learning algorithms to solve the behavior decision problem in autonomous driving. Recall that for the behavioral decision (policy making) subtask, the main problem is to generate a concrete behavioral decision (overtaking, lane changing, following, etc.) given the information provided by the environmental awareness module (location and speed of surrounding cars, road signs, etc.). This objective fits well with the problems that reinforcement learning algorithms focuses on solving.
Reinforcement learning is a branch of machine learning, which aims to solve sequential decision-making problems. Unlike CNNs (which are supervised learning algorithms), in the context of reinforcement learning, there is no available supervision signals (like labels attached to training samples) which can be used to update the parameters of the algorithm. Instead, an intelligent agent needs to explore the environment and learn an optimal policy by interacting with the environment. As shown in figure 6 [24], at each time step, the agent (Super Mario) will observe its state in the environment (for example, the position and speed of Super Mario on the screen) and make an action (for example, jump forward) according to its current state. After that, the agent will receive a reward signal provided by the environment (for example, the change in scores) and then enter the next state. This problem can be usually described as a Markov Decision Process (MDP), which usually consists of a state space S (used to describe the state information of the agent in its environment), an action space A (used to describe possible actions the agent will take at each time step), a transition matrix P (used to describe the transition probability between each state), a reward function R(s, a) and a time decay factor gamma.

Figure 6 Basic components of reinforcement learning
The ultimate objective of reinforcement learning algorithms is to work out an optimal policy by which the agent can maximize the accumulate discounted reward. Current reinforcement learning algorithms can be divided into three categories: value-based methods, policy-based methods and actor-critic methods.
For value-based method, a value function (q(s,a)) is used to compute the value (expected accumulated discounted reward) of each state-action pair in the MDP. The action that has the highest value given the current state will then be chosen as the next action that will be taken. (Usually, agents have a very small chance to randomly select an action in order to explore the environment.) Estimating the value function of the current policy and updating the policy according to its value function is an iterative process and this process will converge at the optimal point gradually. Famous value-based reinforcement learning algorithms including Q-learning, Sarsa (lambda), etc.
In the policy-based algorithms, the policy is described as a continuous probability distribution given some parameters theta. Different form value-based methods where a value function is used to evaluate the potential value of each state-action pair, when using policy-based algorithms a policy objective function J(theta) is used to evaluate the potential value of the policy directly. Once the policy objective function J(theta) is computed, the policy will be updated such that J(theta) is maximized. The most famous policy-based algorithm is policy gradient algorithm, in which the set of parameters theta will be optimized using gradient descent on J(theta) with respect to .
Actor-critic methods is the combination of value-based method and policy-based method. As suggested by its name, actor-critic method can be divided into two main parts. An actor, which is usually the core part of a policy-based algorithm, is used to determine which action should be taken for the next time step. In addition, a critic, which is usually the core part of a value-based algorithm, is used to help the actor to estimate for the current policy. There are many actor-critic algorithms [25]. Comparing with policy-based method like policy gradient, actor-critic methods are more efficient and stable (has lower variance).
All of the aforementioned reinforcement learning algorithms can be integrated with deep neural networks and therefore be able to solve more complex reinforcement learning problems (MDPs with high dimensional state space and action space) [3][26]. Now, let’s have a look at how can we combine the aforementioned reinforcement learning algorithms with deep neural networks to solve the behavioral decision (policy making) subtask in autonomous driving.
One potential idea is to combine Q learning with deep neural networks. In [27], the authors use a CNN (consists of three convolutional layers and two fully connected layers) to optimize the approximate the value function (). They named their work as Deep Q Network (DQN) and show that DQN is able to perform as well as a professional human player for most of the games in Atari 2600 games. From then on, DQN and its variations are applied to solve the behavioral decision problem in autonomous driving in many researches. In [28], the authors implement double DQN [29] to a simulated car racing game called JavaScript Racer. Their action space is a nine-dimensional vector consisting of four binary actions (acceleration, deceleration, left-turn and right-turn) and their possible combinations. They use the latest frame of the game screen as the input of the double DQN. They also tried two different reward functions, both of which give negative reward signal when the vehicle speed is zero, colliding with other vehicles or driving off the road. The experimental results show that the agent is able to learns to turn and navigate larger sections of the simulated raceway without crashing. However, an obvious shortcoming of this work is that the action space of the MDP is discrete, which is obviously not the case in real world. In [30], the authors proposed a modified DQN to train the agent to make lane change automatically in a simulated environment. Their modified DQN consists of three separate neural network and be able to be accommodated to a continuous action space (yaw acceleration). They use an eight-dimensional vector (including the vehicle speed, longitudinal, position, etc.) as the state space and their reward function also takes several factors (yaw acceleration, yaw rate and time consumed by lane changing) in to account. Their experiment results show that the agent learns to maximize the expected cumulated discounted reward to achieve a better lane change policy during the training. There are many other researchers aim at solving the decision-making task in autonomous field using DQN and its variations [31][32][33], due to the page limit I will not go through them in this post.
In addition to value-based methods, policy-based methods can also be combined with deep neural networks to solve the behavioral decision task in autonomous driving. Concretely speaking, the policy used by the agent can be approximated by a neural network with parameters and gradient descent can be used to optimize parameters with respect to the task-specific objective function. In [34], the authors train a hierarchical reinforcement learning algorithm with policy gradient to solve a traffic light passing scenario in a simulated environment. The action space of the primitive layer of the hierarchical neural network is the acceleration of the vehicle ([-5, 3] ). The state space of the system is a four-dimensional vector consisting of the velocity of the vehicle, the distance from the vehicle to the crossing line and the time before the traffic light turning to red. Their hierarchical neural network consists of three layers: the root layer (used to decide the current color of the traffic light), the middle layer (used to decide which lower module to be used to generate the concrete action) and the primitive layer (used to generate the concrete action). They applied their hierarchical reinforcement learning algorithm to a simulated traffic light passing scenario with their self-designed reward function. Their experimental results show that the proposed hierarchical reinforcement learning algorithm is able to break the traffic light passing task into 3 simpler tasks and learn to maximize their average return and avoid violating the traffic rule at the same time.
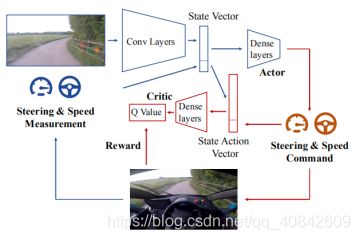
Figure 7 The structure of the actor-critic algorithm used
Another idea is to combine actor-critic method with deep neural networks. Concretely speaking, one can use two separate neural networks to build the actor-critic algorithm: one for the actor (the policy) and another for the critic (the value function). In [35], the authors applied Deep Deterministic Policy Gradients [[36]] (DDPG, which is an actor-critic reinforcement learning algorithm) to a real-world autonomous driving task - lane following (figure 7 [35]). They train an agent to drive a two-seater electric vehicle on a 250-meter section of road. They use the forward speed as the reward signal. An episode will be terminated once the terminal is reached or the vehicle breaks traffic rules. As a result, the value function is the expected driving distance before termination. They also define the action space to be a two-dimensional vector, where the first element is the steering angel (range [-1,1]) and the second element is the speed setpoint (km/h). For the state space, they use the 16-dimensional feature vector extracted by a CNN, where the input image of the CNN is captured by a single monocular forward-facing video camera. The experiment results show that after 37 minutes of training, the agent is able to drive along the lane of the 250-meter section of road 143.2 meters before disengagement in average (the same data for driving straight with constant speed is 22.7 meters). Moreover, in [37], another actor-critic algorithm (proximal policy optimization [38]) is applied to a parking lot exploration task where the vehicle is supposed to reach a specific position of the parking lot in the present of several obstacles. The authors use two neural networks with same architecture but different parameters to build the actor (the policy) and the critic (the value function). The state space of the agent consists of two parts. The first part is a seven-dimensional vector describing the position and dynamics of the agent, and the second part is a coarse grid map describing the surrounding environment of the agent. The action space consists of the angular velocity and the longitudinal acceleration of the agent. The reward function also consists of two part. The first part is used to encourage the agent to reach the target position quickly and the second part is used to encourage the agent to decelerate and stop at the target position. The proposed algorithm is trained in a simulated environment and tested in both the simulated environment and real-world scenarios. The experiment results show that the agent is able to reach the target position with time limit with a success rate of over 80% in the simulated environment and handle sharp turnings and unexpected obstacles in the real-world scenario. Furthermore, there are many other research works aiming at applying actor-critic algorithms on autonomous driving problem [39][40].
Section 3: Potential social and ethical issues associated with deep learning and autonomous driving
In the last part of this blog, I would like to talk about some potential social and ethical issues caused by the use of artificial intelligence in the field of autonomous driving. In addition to technical difficulties, these social and ethical issues also must be address before we can widely apply autonomous vehicles in our daily lives.
The first issue is the unemployment caused by autonomous driving technology. The adaption of automatic techniques always come with the unemployment of workers in corresponding industries, which might cause social instability and increase the crime rate. With the application of autonomous driving technology, the drivers of large trucks and public transportation bear the brunt (Because the driving routes of these vehicles are relatively fixed, which means the difficulty of achieving autonomous driving is relatively low). Currently in China, large long-distance freight cars are often equipped with two drivers to prevent fatigue driving. However, with the assistance of autonomous driving technology, even if it is only L3 level of assisted driving, most freight companies are still likely to abolish a driver and only keep one driver in each vehicle. In addition, many taxi drivers, driving school coaches and exercise partners, chauffeurs are very likely to lose their jobs as well. How can we compensate these people who lost their jobs due to autonomous driving technology, and hopefully provided them with new jobs?
In my opinion, a potential solution is to create more jobs from the autonomous driving technology itself. For example, large passenger vehicles may need to be equipped with at least one safety driver for a long period of time until the autonomous driving technology is extremely mature to ensure the safety of the passengers in the vehicle. In addition, with the popularity of autonomous driving technology, there may be many roads and other infrastructure that need to be modified accordingly to improve the safety of autonomous vehicles, which will also create a large number of jobs. At last, the application of autonomous driving technology is not done overnight, instead, it should be a long term and periodic process. In this process, the government should intentionally encourage people in the driving industry to gradually move to other similar or less affected industries.
The second issue is the degree of human control over the autonomous driving agent: should we give car owners absolute control over autonomous vehicles? If the answer is no, what degree of control should we give the car owner? One extremely solution is to give the car owner or its passengers the absolute control over the autonomous driving agent. This will undoubtedly make the car owner and passengers more convenient. However, this can be dangerous sometime, especially when the human driver is irrational or unconscious (drunken). In the most extreme case, a smart driving car that completely obey its owner may even become a real killing machine. One the other hand, if we only allow car owners or passengers set their destination, preferred route and expected travel time, how should we deal with the unexpected emergencies? For example, what if one of the passengers is a pregnant woman, and she is about to give birth? Should we given the car owner or passengers the ability to ask autonomous driving cars violate some not that serious traffic regulation?
One potential solution is to give the car owner the abilities to drive the car by himself when he wants. By doing this, we can distinguish the responsibility allocation in automatic driving mode from the that in manual driving mode. If a human driver has violated regulations in manual driving mode, we can punish him accordingly. Nevertheless, this solution may not be suitable for everyone. Because in a society that uses a lot of self-driving technology, most people in self-driving cars may not drive at all. Even if they have ever learned to drive, their ability to handle emergencies is likely to gradually decline as their driving experience decreases. In my opinion, I tend to give car owners and passengers the power to violate traffic laws to some extend in an emergency. Of course, such power should never be premised on causing serious harm to others or violating criminal law.
The third issue I would like to discuss is an ethical dilemma: When faced with the necessary choices, should autonomous driving cars prioritize the interests of the passengers of the vehicle or the interests of pedestrians and passengers in other vehicles? This ethical dilemma can appear in many different scenarios. For example, when you ride your self-driving car on the road and will be late, a car wants to jump in front of you. Should your car let another car jump in, or should it keep close to the front car to prevent another car from jumping in? If you choose the former answer then you might be late, and if you choose the latter one you increase the likelihood of a traffic accident. Currently, most autonomous driving technology companies have paid more attention to the safety of autonomous driving technology, so their autonomous vehicles tend to be more conservative when driving, but is this necessarily reasonable? If you let other vehicles jump in front of you at every intersection, what about the vehicles that are behind you? What if you are in front of an ambulance? Furthermore, there is a new version of “trolley problem” [41]: If a passenger is sitting in a high-speed autonomous car, the car will hit five pedestrians. At this time, in order to avoid hitting pedestrians, the agent driving the car can choose to turn left and hit a wall, but this may sacrifice the passenger’s life. What should the agent choose at this time? This is obviously an ethical dilemma. If it is done from a moralistic perspective, then the agent should choose to sacrifice five pedestrians to save the passenger’s life. Because everyone is born equal, the agent should not deliberately harm the passenger in the car in order to save the lives of pedestrians. But this choice is likely to cause greater damage to the entire human community, because the five people who were hit are likely to assume more obligations and responsibilities in our society. Their death may also mean more broken hearts and broken families. If considered from a utilitarian point of view, the agent should sacrifice the passenger in the car in order to preserve the lives of five pedestrians. Because the expected value of five pedestrians for human society exceed the expected value of a passenger. But this kind of behavior that clearly priced everyone’s life clearly violates the moral concept that all human beings are equal and will eventually lead to the unrestricted oppression of the strong against the weak in the human society. Imagine that you, as a young man with a rare blood type, are waiting for a medical examination in the largest and most advanced hospital in the country. There are exactly five critically ill patients with the same blood type in your hospital: the first patient is an academician who urgently needs corneal transplantation; the second patient is a general who urgently needs lung transplantation; the third patient is the richest man in the world, he urgently needs liver transplantation; the fourth patient is a young scientific genius, he urgently needs kidney transplantation; the fifth patient is the president, he urgently needs spleen transplantation. At this time, you were discovered by five medical robots with utilitarian moral standards, what should you do?
In the real world, when a human driver faces such a dilemma, he will make his own choice based on his social background, life experience and values, and bear the corresponding consequences. Thus, one potential solution is to give agents the same moral concepts as most people. Actually, there are already some researchers trying to extract a summarized moral principle from human society. For example, in MIT, some researchers created a website called “moral machine” [42], where each one can test their own moral principle when facing different variations of aforementioned “trolley problem”(figure 5 [41]). However, this solution also creates some new problems. For example, does everyone want their opinions to be represented by most people’s opinions, especially at a time when life and death matter? How often should the code of ethics used by agents be updated? Hence, another possible solution is to build the moral principle of each autonomous vehicle based on their owners. This can be achieved by setting a series of “trolley problems” for the owner when they initialize their cars. However, this solution is more technically difficult and makes the accountability of autonomous vehicles after traffic accidents extremely complicated.
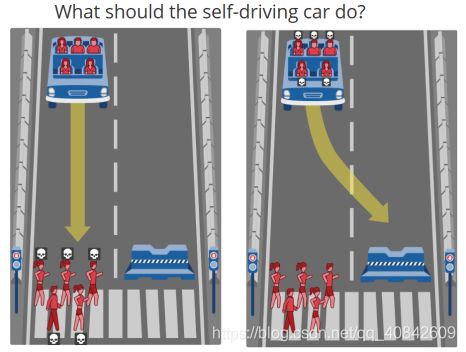
Figure 8 An autonomous driving-version "trolley problem"
At last, there is no doubt that there are many other society and ethical issues caused by the application of autonomous driving technology. Such as to what extend should we keep our privacy data, how should we prevent network intrusions against autonomous vehicles and corresponding V2X components [43], and so on. However, I believe that most of these problems will be gradually solved with the improvement of technology and the improvement of legislation. Even for questions that do not have an accurate answer, like the “trolley problem”, we will gradually figure out a solution to coexist autonomous driving technology with it.
Conclusion
This blog is a comprehensive introduction about emerging topics in applying deep learning techniques in autonomous driving area. In the first part, I briefly introduce the problem setting and current state of autonomous driving technology. In the second part, I talked about how can we apply deep learning in autonomous driving vehicles from two aspects: environmental perception (based on CNN) and behavioral decision (based on reinforcement learning). In the last part, I discuss three society and ethical issues that are likely be caused by the application of deep learning in autonomous driving area.
There is no doubt that this article only describes the tip of the iceberg of deep learning based autonomous driving technology, both at the technical level and at the ethical level. There are uncountable problems waiting to be solved before we can truly free our brains, eyes, hands and legs from driving a car. However, just like the invention of steam engines and light bulbs, the benefits of autonomous driving technology to human society are far greater than the problems that accompany it. Moreover, just like the application process of cars and alternating current in human society, the application process of autonomous driving technology in human society is not done overnight. Even with some unavoidable pain, it should be a long term and spiraling development process, just like the development law of general things described by Marx in Das Kapital.
References
[1] “SAE Standards News: J3016 automated-driving graphic update.” [Online]. Available: https://www.sae.org/news/2019/01/sae-updates-j3016-automated-driving-graphic. [Accessed: 30-Apr-2020].
[2] “Cadillac Homepage.” [Online]. Available: https://www.cadillac.com.cn/ct6/summarize.html. [Accessed: 30-Apr-2020].
[3] S. D. Pendleton et al., “Perception, planning, control, and coordination for autonomous vehicles,” Machines, vol. 5, no. 1, pp. 1–54, 2017.
[4] D. Silver et al., “Mastering the game of Go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017.
[5] R. Simhambhatla, K. Okiah, and R. Slater, “Self-Driving Cars : Evaluation of Deep Learning Techniques for Object Detection in Different Driving Conditions,” SMU Data Sci. Rev., vol. 2, no. 1, pp. 1–27, 2019.
[6] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2017.
[7] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2016-Decem, pp. 779–788, 2016.
[8] L. Huang, Y. Yang, Y. Deng, and Y. Yu, “DenseBox: Unifying Landmark Localization with End to End Object Detection,” pp. 1–13, 2015.
[9] 白裳, “一文读懂Faster RCNN,” 2020. [Online]. Available: https://zhuanlan.zhihu.com/p/31426458.
[10] Y. Tian, J. Gelernter, X. Wang, W. Chen, J. Gao, and Y. Zhang, “Neurocomputing Lane marking detection via deep convolutional neural network,” Neurocomputing, vol. 280, pp. 46–55, 2018.
[11] “Traffic Signs Detection Based on Faster RCNN.pdf.” .
[12] P. Garg, D. R. Chowdhury, and V. N. More, “Traffic Sign Recognition and Classification Using YOLOv2 , Faster RCNN and SSD,” 2019 10th Int. Conf. Comput. Commun. Netw. Technol., pp. 1–5, 2019.
[13] “German Traffic Sign Benchmarks.” [Online]. Available: http://benchmark.ini.rub.de/?section=gtsdb&subsection=dataset. [Accessed: 09-May-2020].
[14] K. Qiao, H. Gu, J. Liu, and P. Liu, “Optimization of traffic sign detection and classification based on faster R-CNN,” Proc. - 2017 Int. Conf. Comput. Technol. Electron. Commun. ICCTEC 2017, pp. 608–611, 2017.
[15] P. Li, X. Chen, and S. Shen, “Stereo R-CNN based 3D object detection for autonomous driving,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2019-June, pp. 7636–7644, 2019.
[16] D. Matti, H. K. Ekenel, and J. P. Thiran, “Combining LiDAR space clustering and convolutional neural networks for pedestrian detection,” 2017 14th IEEE Int. Conf. Adv. Video Signal Based Surveillance, AVSS 2017, pp. 0–5, 2017.
[17] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2016-Decem, pp. 770–778, 2016.
[18] B. Li, T. Zhang, and T. Xia, “Vehicle detection from 3D lidar using fully convolutional network,” Robot. Sci. Syst., vol. 12, 2016.
[19] D. Maturana and S. Scherer, “VoxNet: A 3D Convolutional Neural Network for real-time object recognition,” IEEE Int. Conf. Intell. Robot. Syst., vol. 2015-Decem, pp. 922–928, 2015.
[20] B. Xiang, J. Tu, J. Yao, and L. Li, “A novel octree-based 3-D fully convolutional neural network for point cloud classification in road environment,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 10, pp. 7799–7818, 2019.
[21] D. Prokhorov, “A convolutional learning system for object classification in 3-D lidar data,” IEEE Trans. Neural Networks, vol. 21, no. 5, pp. 858–863, 2010.
[22] D. Maturana and S. Scherer, “3D Convolutional Neural Networks for landing zone detection from LiDAR,” Proc. - IEEE Int. Conf. Robot. Autom., vol. 2015-June, no. June, pp. 3471–3478, 2015.
[23] C. R. Qi, H. Su, M. Niebner, A. Dai, M. Yan, and L. J. Guibas, “Volumetric and multi-view CNNs for object classification on 3D data,” Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2016-Decem. pp. 5648–5656, 2016.
[24] “[Reinforcement Learning] 强化学习介绍 | 电子创新网 Imgtec 社区.” [Online]. Available: http://imgtec.eetrend.com/blog/2019/100017372.html. [Accessed: 10-May-2020].
[25] I. Grondman, L. Busoniu, G. A. D. Lopes, and R. Babuška, “A survey of actor-critic reinforcement learning: Standard and natural policy gradients,” IEEE Trans. Syst. Man Cybern. Part C Appl. Rev., vol. 42, no. 6, pp. 1291–1307, 2012.
[26] D. Silver et al., “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016.
[27] V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
[28] R. B. April Yu, Raphael Palefsky-Smith, “Deep Reinforcement Learning for Simulated Autonomous Vehicle Control.”
[29] H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double Q-Learning,” 30th AAAI Conf. Artif. Intell. AAAI 2016, pp. 2094–2100, 2016.
[30] P. Wang, C. Y. Chan, and A. De La Fortelle, “A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers,” IEEE Intell. Veh. Symp. Proc., vol. 2018-June, no. Iv, pp. 1379–1384, 2018.
[31] T. Okuyama, T. Gonsalves, and J. Upadhay, “Autonomous Driving System based on Deep Q Learnig,” 2018 Int. Conf. Intell. Auton. Syst. ICoIAS 2018, pp. 201–205, 2018.
[32] A. El Sallab, M. Abdou, E. Perot, and S. Yogamani, “Deep reinforcement learning framework for autonomous driving,” IS T Int. Symp. Electron. Imaging Sci. Technol., pp. 70–76, 2017.
[33] P. Wang and C. Y. Chan, “Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge,” IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, vol. 2018-March, pp. 1–6, 2018.
[34] N. Liu et al., “A Hierarchical Framework of Cloud Resource Allocation and Power Management Using Deep Reinforcement Learning,” Proc. - Int. Conf. Distrib. Comput. Syst., pp. 372–382, 2017.
[35] A. Kendall et al., “Learning to drive in a day,” Proc. - IEEE Int. Conf. Robot. Autom., vol. 2019-May, pp. 8248–8254, 2019.
[36] T. P. Lillicrap et al., “Continuous control with deep reinforcement learning,” 4th Int. Conf. Learn. Represent. ICLR 2016 - Conf. Track Proc., 2016.
[37] A. Folkers, M. Rick, and C. Buskens, “Controlling an autonomous vehicle with deep reinforcement learning,” IEEE Intell. Veh. Symp. Proc., vol. 2019-June, pp. 2025–2031, 2019.
[38] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” pp. 1–12, 2017.
[39] A. El Sallab, M. Abdou, E. Perot, and S. Yogamani, “End-to-End Deep Reinforcement Learning for Lane Keeping Assist,” no. Nips, pp. 1–9, 2016.
[40] J. Chen, B. Yuan, and M. Tomizuka, “Model-free Deep Reinforcement Learning for Urban Autonomous Driving,” 2019 IEEE Intell. Transp. Syst. Conf. ITSC 2019, pp. 2765–2771, 2019.
[41] “Trolley problem.” [Online]. Available: https://en.wikipedia.org/wiki/Trolley_problem. [Accessed: 11-May-2020].
[42] “MORAL MACHINE.” [Online]. Available: http://moralmachine.mit.edu/. [Accessed: 11-May-2020].
[43] “Vehicle-to-everything.” [Online]. Available: https://en.wikipedia.org/wiki/Vehicle-to-everything. [Accessed: 11-May-2020].