2. 【第二部分】 代码练习
这一部分主要参考了知乎的一些文章
https://zhuanlan.zhihu.com/p/70703846
https://zhuanlan.zhihu.com/p/31551004
以及B站的视频
https://www.bilibili.com/video/BV1yE411p7L7
https://www.bilibili.com/video/BV1qE411T7qZ
2.1 MobileNetV1 网络
下面是这一部分的代码
- 准备下数据
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 在一个随机的位置裁剪给定的图像。
transforms.RandomHorizontalFlip(), # 以给定概论(默认值为0.5)水平翻转图片
transforms.ToTensor(), #Convert a PIL Image or numpy.ndarray to tensor.
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]) #Normalize a tensor image with mean and standard deviation. torchvision.transforms.Normalize(mean, std, inplace=False)
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
- RandomCrop()
https://pytorch.org/docs/stable/torchvision/transforms.html?highlight=randomcrop#torchvision.transforms.RandomCrop
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
Crop the given image at a random location. The image can be a PIL Image or a Tensor, in which case it is expected to have […, H, W] shape, where … means an arbitrary number of leading dimensions
- RandomHorizontalFlip()
torchvision.transforms.RandomHorizontalFlip(p=0.5)
https://pytorch.org/docs/stable/torchvision/transforms.html?highlight=randomhorizontalflip#torchvision.transforms.RandomHorizontalFlip
Horizontally flip the given image randomly with a given probability. The image can be a PIL Image or a torch Tensor, in which case it is expected to have […, H, W] shape, where … means an arbitrary number of leading dimensions
- 定义网络

#可分离卷积
class Block(nn.Module):
def __init__(self,in_planes,out_planes,stride = 1):
super(Block,self).__init__()
#depthwise部分
self.conv1 = nn.Conv2d(in_planes,in_planes,kernel_size=3,stride=stride,padding=1,
groups=in_planes, #groups=1--->普通卷积;groups=in_planes---》dw卷积
bias=False) #下面BN层中本身就有Scale and Shift这一个环节,这里不需要加偏置了
self.bn1 = nn.BatchNorm2d(in_planes)
#pointwise
self.conv2 = nn.Conv2d(in_planes,out_planes,kernel_size=1,
stride=1,padding=0,bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
return x
class MobileNet(nn.Module):
#(out_planes ,stride)
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self,num_classes=10):
super(MobileNet,self).__init__()
self.conv1 = nn.Conv2d(3,32,kernel_size=3,stride=1,padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024,num_classes)
def _make_layers(self,in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes,out_planes,stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
- 训练模型
记得选GPU加速,要不巨慢
# 网络放到GPU上
net = MobileNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')

4. 测试一下
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))

2.2 MobileNetV2: Inverted Residuals and Linear Bottlenecks
相比于V1版本,主要改进了
(1)设计了Inverted residual block 倒残差结构,两边宽中间窄

(2)去掉输出部分的ReLU6,改用线性激活函数

看下代码~
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out

class MobileNetV2(nn.Module):
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
训练过程和上面差不多,直接看下准确率~~
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
![]()
比V1版本高了不少
2.3 HybridSN
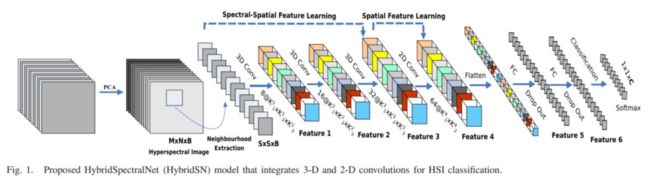
三维卷积部分:
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1,8,(7,3,3))
self.conv2 = nn.Conv3d(8,16,(5,3,3))
self.conv3 = nn.Conv3d(16,32,(3,3,3))
self.conv2d = nn.Conv2d(576,64,(3,3))
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128, class_num)
self.dropout = nn.Dropout(p=0.4)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(-1,x.shape[1]*x.shape[2],x.shape[3],x.shape[4])
x = F.relu(self.conv2d(x))
x = x.view(x.size(0),-1)
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.out(x)
return x
3.论文阅读
3.1 Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
参考了这篇博客以及周四同学讲的内容
- 提出了前馈去噪卷积神经网络(DnCNN)用于图像去噪
- 使用残差学习、批量归一化提高性能
- DnCNN易扩展,可处理一般的图像去噪任务
1.网络模型
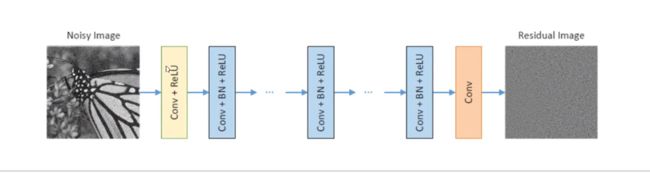
(1)Conv(3 * 3 * c * 64)+ReLu
(2)Conv(3 * 3 * 64 * 64)+BN +ReLu
(3)Conv(3 * 3 * 64)
2.批量归一化
把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,即把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域
为CNN减轻了内部协变量偏移问题

3.2 Squeeze-and-Excitation Networks
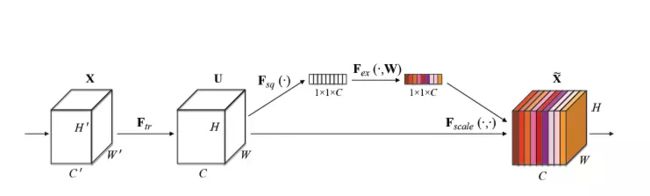
- CNN是基于卷积操作的,卷积就是通过融合局部感受野的空间和通道信息提取信息特征
- 为了增强CNN提取信息特征的表征力,本文提出关注通道间关系,并提出压缩并激活块(Squeeze and Excitation),通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率
- Squeeze
先是Squeeze部分。GAP有很多算法,作者用了最简单的求平均的方法(公式1),将空间上所有点的信息都平均成了一个值。这么做是因为最终的scale是对整个通道作用的,这就得基于通道的整体信息来计算scale。另外作者要利用的是通道间的相关性,而不是空间分布中的相关性,用GAP屏蔽掉空间上的分布信息能让scale的计算更加准确。 - Excitation
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
3.3 Deep Supervised Cross-modal Retrieval
提出了一种新的跨模态检索方法——深度监督跨模态检索(DSCMR)。它的目的是找到一个共同的表示空间,在这个空间中可以直接比较来自不同模式的样本。
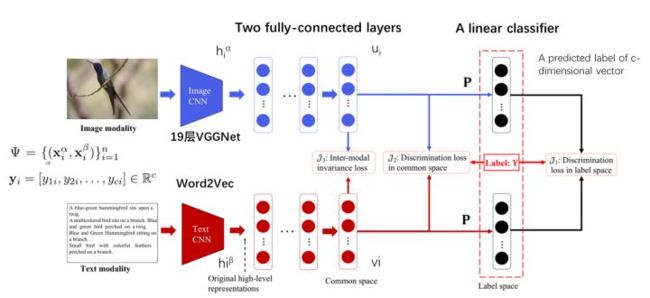
该方法包含两个子网络,一个用于图像模态,另一个用于文本模态,并且它们是以端到端的方式进行训练的。将图像和文本分别输入到两个子网络中,得到原始的高级语义表示。然后,在它们的顶部分别添加一些全连接层,将来自不同模式的样本映射到一个公共表示空间。最后,利用参数为P的线性分类器预测每个样本的类别。