我的架构梦:(二十八)Dubbo源码分析之集群容错源码剖析
Dubbo源码分析之集群容错源码剖析
- 一、前言
- 二、信息缓存接口Directory
- 三、路由规则实现原理
- 四、 Cluster组件
- 五、负载均衡实现原理
- 六、Invoker执行逻辑
一、前言
在对集群相关代码进行分析之前,这里有必要先来介绍一下集群容错的所有组件。包含 Cluster、 Cluster Invoker、Directory、Router 和 LoadBalance 等。
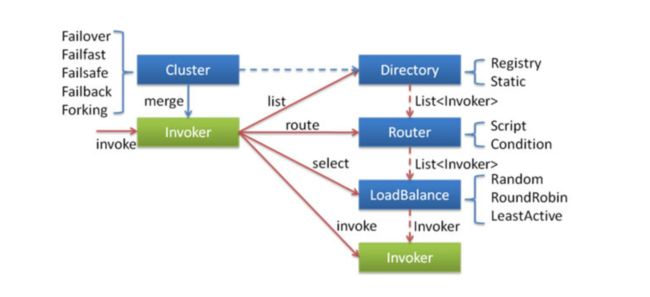
集群工作过程可分为两个阶段,第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消 费者创建 Cluster Invoker 实例,即上图中的 merge 操作。第二个阶段是在服务消费者进行远程调用时。以 FailoverClusterInvoker 为例,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。Directory 的用途是保存 Invoker列表,可简单 类比为 List。其实现类 RegistryDirectory 是一个动态服务目录,可感知注册中心配置的变化,它所持有的 Invoker 列表会随着注册中心内容的变化而变化。每次变化后,RegistryDirectory 会动态增删 Invoker,并调用 Router 的 route 方法进行路由,过滤掉不符合路由规则的 Invoker。当 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表后,它会通过 LoadBalance 从 Invoker 列 表中选择一个 Invoker。最后 FailoverClusterInvoker 会将参数传给 LoadBalance 选择出的 Invoker 实例的 invoke 方法,进行真正的远程调用。
Dubbo 主要提供了这样几种容错方式:
Failover Cluster- 失败自动切换 失败时会重试其它服务器Failfast Cluster- 快速失败 请求失败后快速返回异常结果 不重试Failsafe Cluster- 失败安全 出现异常 直接忽略 会对请求做负载均衡Failback Cluster- 失败自动恢复 请求失败后 会自动记录请求到失败队列中Forking Cluster- 并行调用多个服务提供者 其中有一个返回 则立即返回结果
二、信息缓存接口Directory
Directory是Dubbo中的一个接口,主要用于缓存当前可以被调用的提供者列表信息。我们在消费者进
行调用时都会通过这个接口来获取所有的提供者列表,再进行后续处理。
1、我们先来看看 Directory 接口,这里比较简单,我们可以通过 Directory 来找到指定服务中的提供者信息列表。
public interface Directory<T> extends Node {
// 获取服务的类型,也就是我们demo中所使用的HelloService
Class<T> getInterface();
// 根据本次调用的信息来获取所有可以被执行的提供者信息
List<Invoker<T>> list(Invocation var1) throws RpcException;
// 获取所有的提供者信息
List<Invoker<T>> getAllInvokers();
}
2、 Directory中有一个基础的实现类,主要是对一些通用的方法封装,主要还是依靠真正的实现。 其中可以看看 AbstractDirectory中的list 方法。通过这个方式我们能知道,真正实现还是依靠于真 正子类汇总的 doList 方法。
public List<Invoker<T>> list(Invocation invocation) throws RpcException {
if (this.destroyed) {
throw new RpcException("Directory already destroyed .url: " + this.getUrl());
} else {
return this.doList(invocation);
}
}
protected abstract List<Invoker<T>> doList(Invocation var1) throws RpcException;
3、我们可以继续往下看,他的实现子类是 RegistryDirectory#doList 方法。我们可以看到这里的实现也相对比较简单,主要依靠routerChain去决定真实返回的提供者列表。
public List<Invoker<T>> doList(Invocation invocation) {
// 当没有提供者的时候会直接抛出异常
if (this.forbidden) {
// 1. No service provider 2. Service providers are disabled
throw new RpcException(4, "No provider available from registry " + this.getUrl().getAddress() + " for service " + this.getConsumerUrl().getServiceKey() + " on consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() + ", please check status of providers(disabled, not registered or in blacklist).");
} else if (this.multiGroup) {
return this.invokers == null ? Collections.emptyList() : this.invokers;
} else {
List invokers = null;
try {
// 交给路由chain去处理并且获取所有的invokers
invokers = this.routerChain.route(this.getConsumerUrl(), invocation);
} catch (Throwable var4) {
logger.error("Failed to execute router: " + this.getUrl() + ", cause: " + var4.getMessage(), var4);
}
return invokers == null ? Collections.emptyList() : invokers;
}
}
4、路由是如何获取Invoker 列表的呢? 我们观察这个方法: RegistryProtocol.refer ,这里面也是 Invoker 生成的部分关键代码。
// url: registry://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService? application=dubbo-demo-annotation- consumer&dubbo=2.0.2&pid=7170&refer=application%3Ddubbo-demo-annotation- consumer%26dubbo%3D2.0.2%26init%3Dfalse%26interface%3Dcom.lagou.service.HelloSer vice%26methods%3DsayHello%2CsayHelloWithPrint%2CsayHelloWithTransmission%2CsayHe lloWithException%26pid%3D7170%26register.ip%3D192.168.1.102%26release%3D2.7.5%26 side%3Dconsumer%26sticky%3Dfalse%26timestamp%3D1583995964957®istry=zookeeper& release=2.7.5×tamp=1583995964996
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
// 获取注册中心的地址URL(主要用于转换协议),比如我们是使用的zookeeper,那么他就会转换为zookeeper://
url = this.getRegistryUrl(url);
// 获取注册中心配置信息
Registry registry = this.registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return this.proxyFactory.getInvoker(registry, type, url);
} else {
// 适用于多个分组时使用
Map<String, String> qs = StringUtils.parseQueryString(url.getParameterAndDecoded("refer"));
String group = (String)qs.get("group");
// 真正进行构建invoker和我们上面的Directory
return group == null || group.length() <= 0 || CommonConstants.COMMA_SPLIT_PATTERN.split(group).length <= 1 && !"*".equals(group) ? this.doRefer(this.cluster, registry, type, url) : this.doRefer(this.getMergeableCluster(), registry, type, url);
}
}
5、下面我们再来仔细跟踪 doRefer 方法, 这里面就是最主要产生Directory并且注册和监听的主要代码逻辑。我们所需要的 routerChain 也是在这里产生的。
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
// 实例化Directory
RegistryDirectory<T> directory = new RegistryDirectory(type, url);
// 设置注册中心和所使用的协议
directory.setRegistry(registry);
directory.setProtocol(this.protocol);
// 生成监听路径URL
Map<String, String> parameters = new HashMap(directory.getUrl().getParameters());
URL subscribeUrl = new URL("consumer", (String)parameters.remove("register.ip"), 0, type.getName(), parameters);
if (!"*".equals(url.getServiceInterface()) && url.getParameter("register", true)) {
// 在Directory中设置监听的consumerurl地址
directory.setRegisteredConsumerUrl(this.getRegisteredConsumerUrl(subscribeUrl, url));
// 在注册中心中注册消费者URL
// 也就是我们之前的Zookeeper的node中看到的consumer://
registry.register(directory.getRegisteredConsumerUrl());
}
// 构建路由链
directory.buildRouterChain(subscribeUrl);
// 进行监听所有的的provider
directory.subscribe(subscribeUrl.addParameter("category", "providers,configurators,routers"));
// 加入到集群中
Invoker invoker = cluster.join(directory);
return invoker;
}
6、回到 RouterChain#route 方法。这里所做的就是依次遍历所有的路由,然后分别执行并返回。这也就是整体的路由规则的实现。
public List<Invoker<T>> route(URL url, Invocation invocation) {
// 所有的invoker列表
List<Invoker<T>> finalInvokers = this.invokers;
Router router;
// 依次交给所有的路由规则进行选取路由列表
for(Iterator var4 = this.routers.iterator(); var4.hasNext(); finalInvokers = router.route(finalInvokers, url, invocation)) {
router = (Router)var4.next();
}
return finalInvokers;
}
三、路由规则实现原理
这里我们具体来讲解一下 RouterChain 中的 Router 是如何实现的。这里我们主要ConditionRouter 的实现来做说明。
1、可以看到这个类中有两个属性比较关键,这两个属性也是判断的关键。
// 是否满足判断条件
protected Map<String, ConditionRouter.MatchPair> whenCondition;
// 当满足判断条件时如何选择invokers
protected Map<String, ConditionRouter.MatchPair> thenCondition;
2、我们可以看到每一个 MatchPair 都有这两个属性,分别表示满足的条件和不满足的具体条件。
final Set<String> matches = new HashSet();
final Set<String> mismatches = new HashSet();
3、下面我们先跳过生成规则的代码,先从如何选择Invoker入手。可以看到整体的流程也比较简单, 主要在于判断( matchWhen )和选择( matchThen )的逻辑。
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {
// 不启用时,则直接返回提供者的列表
if (!this.enabled) {
return invokers;
} else if (CollectionUtils.isEmpty(invokers)) { // 如果不存在任何invoker则直接返回
return invokers;
} else {
try {
if (!this.matchWhen(url, invocation)) { // 判断是否满足判断条件,不满足直接返回列表
return invokers;
}
List<Invoker<T>> result = new ArrayList();
if (this.thenCondition == null) {
logger.warn("The current consumer in the service blacklist. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey());
return result;
}
Iterator var5 = invokers.iterator();
// 依次判断每一个invoker的url是否满足条件
while(var5.hasNext()) {
Invoker<T> invoker = (Invoker)var5.next();
if (this.matchThen(invoker.getUrl(), url)) {
result.add(invoker);
}
}
// 如果不为空则直接返回
if (!result.isEmpty()) {
return result;
}
// 如果为空,并且必须要走这个条件时,则直接返回空
if (this.force) {
logger.warn("The route result is empty and force execute. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey() + ", router: " + url.getParameterAndDecoded("rule"));
return result;
}
} catch (Throwable var7) {
logger.error("Failed to execute condition router rule: " + this.getUrl() + ", invokers: " + invokers + ", cause: " + var7.getMessage(), var7);
}
return invokers;
}
}
4、可以看到这里判断条件是尽量的简单,甚至可以为空,主要在于判定when 以及是否匹配then规 则。两者最终底层都是调用的 matchCondition 方法,我们在看他实现逻辑之前,先来确定一下
condition 中都存储了什么样的信息。
boolean matchWhen(URL url, Invocation invocation) {
// 1. 如果判断条件为空则直接认定为匹配
// 2. 如果条件匹配则认定为匹配
return CollectionUtils.isEmptyMap(this.whenCondition) || this.matchCondition(this.whenCondition, url, (URL)null, invocation);
}
private boolean matchThen(URL url, URL param) {
// 判断条件不能为空并且匹配条件规则时才返回
return CollectionUtils.isNotEmptyMap(this.thenCondition) && this.matchCondition(this.thenCondition, url, param, (Invocation)null);
}
5、最后我们再来看看他是如何生成整个路由规则的。我们跟进 ConditionRouter#init 方法,其中比较关键的方法为 parseRule , when 和 then 的规则都是相同的。
public void init(String rule) {
try {
// 必须包含规则配置
if (rule != null && rule.trim().length() != 0) {
rule = rule.replace("consumer.", "").replace("provider.", "");
// 根据"=>"来判断when或者then条件
int i = rule.indexOf("=>");
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
// 分别根据"=>"来生成前后的规则
Map<String, ConditionRouter.MatchPair> when = !StringUtils.isBlank(whenRule) && !"true".equals(whenRule) ? parseRule(whenRule) : new HashMap();
Map<String, ConditionRouter.MatchPair> then = !StringUtils.isBlank(thenRule) && !"false".equals(thenRule) ? parseRule(thenRule) : null;
this.whenCondition = (Map)when;
this.thenCondition = then;
} else {
throw new IllegalArgumentException("Illegal route rule!");
}
} catch (ParseException var7) {
throw new IllegalStateException(var7.getMessage(), var7);
}
}
6、parseRule 方法实现。
private static Map<String, ConditionRouter.MatchPair> parseRule(String rule) throws ParseException {
Map<String, ConditionRouter.MatchPair> condition = new HashMap();
if (StringUtils.isBlank(rule)) {
return condition;
}
// 当前所操作的数据
// 用于后面循环中使用,标识上一次循环中所操作的信息
ConditionRouter.MatchPair pair = null;
Set<String> values = null;
// 转化每一个条件
// 这里分别会对每一次的分割做匹配
// host = 1.1.1.* & host != 1.1.1.2 & method=sayHello
// 1. "" host
// 2. "=" 1.1.1.x
// 3. "&" host
// 4. "!=" 1.1.1.2
// ....
final Matcher matcher = ROUTE_PATTERN.matcher(rule);
while(matcher.find()) { // Try to match one by one
// 分隔符
String separator = matcher.group(1);
// 内容
String content = matcher.group(2);
// 如果不存在分隔符
// 则认为是首个判断
if (StringUtils.isEmpty(separator)) {
pair = new MatchPair();
// 则直接放入当前condition condition.put(content, pair);
condition.put(content, pair);
}
// 如果是"&"则代表并且
else if ("&".equals(separator)) {
// 如果当前的when或者then中不包含该判定条件则添加则放入 // 否则当前的condition就需要拿出来
if (condition.get(content) null) {
pair = new MatchPair();
condition.put(content, pair);
} else {
pair = condition.get(content);
}
}
// The Value in the KV part.
else if ("=".equals(separator)) {
if (pair == null) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \"" + content + "\".", matcher.start());
}
// 如果是等于的比较,则需要将值放入matches中
values = pair.matches;
values.add(content);
}
// The Value in the KV part.
else if ("!=".equals(separator)) {
if (pair == null) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \"" + content + "\".", matcher.start());
}
// 如果为不等于,则需要放入到不等于中
values = pair.mismatches;
values.add(content);
}
// 如果values是多个的话
else if (",".equals(separator)) { // Should be separated by ','
if (values == null || values.isEmpty()) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \"" + content + "\".", matcher.start());
}
// 则分别加入到values列表中
values.add(content);
} else {
throw new ParseException("Illegal route rule \"" + rule
+ "\", The error char '" + separator + "' at index " + matcher.start() + " before \"" + content + "\".", matcher.start());
}
}
return condition;
}
四、 Cluster组件
下面我们再来看看再Dubbo中也是很关键的组件: Cluster 。它主要用于代理真正的Invoker执行时做
处理,提供了多种容错方案。
1、我们首先来看一下他的接口定义。这里我们在之前也有见到过( doRefer ),那里也是真正调用它来生成的位置。
// 默认使用failover作为实现
@SPI("failover")
public interface Cluster {
// 生成一个新的invoker
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}
2、下面我们再来看一下他提供的几种实现,Cluster和 Registry 采用了相同的类方式,都提供了 Abstract 类来进行统一的封装。
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
// 使用子类doJoin来真正生成Invoker
// 并且使用拦截器的方式进行一层封装
return this.buildClusterInterceptors(this.doJoin(directory), directory.getUrl().getParameter("reference.interceptor"));
}
// 对invoker进行封装
private <T> Invoker<T> buildClusterInterceptors(AbstractClusterInvoker<T> clusterInvoker, String key) {
AbstractClusterInvoker<T> last = clusterInvoker;
// 获取所有的拦截器
List<ClusterInterceptor> interceptors = ExtensionLoader.getExtensionLoader(ClusterInterceptor.class).getActivateExtension(clusterInvoker.getUrl(), key);
if (!interceptors.isEmpty()) {
for(int i = interceptors.size() - 1; i >= 0; --i) {
// 对拦截器进行一层封装
ClusterInterceptor interceptor = (ClusterInterceptor)interceptors.get(i);
last = new AbstractCluster.InterceptorInvokerNode(clusterInvoker, interceptor, (AbstractClusterInvoker)last);
}
}
return (Invoker)last;
}
3、下面我们看看 failover 里面都做了些什么。这里面比较简单,只是进行new了一个新的 Invoker。
public class FailoverCluster extends AbstractCluster {
public static final String NAME = "failover";
public FailoverCluster() {
}
public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker(directory);
}
}
4、我们通过观察Invoker接口得知,其中最关键的方式是 invoke 方法。我们也可以看到,他也是通过 Abstract 进行了一层封装。其中我们来看看他的 invoke 方法实现。
( AbstractClusterInvoker.invoke )
public Result invoke(final Invocation invocation) throws RpcException {
// 检查是否已经关闭了
this.checkWhetherDestroyed();
// 拷贝当前RPCContext中的附加信息到当前的invocation中
Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation)invocation).addObjectAttachments(contextAttachments);
}
// 找寻出所有支持的invoker,已经路由过的
List<Invoker<T>> invokers = this.list(invocation);
// 初始化负载均衡器
LoadBalance loadbalance = this.initLoadBalance(invokers, invocation);
// 用于适配异步请求使用
RpcUtils.attachInvocationIdIfAsync(this.getUrl(), invocation);
// 交给子类进行真正处理请求
return this.doInvoke(invocation, invokers, loadbalance);
}
5、我们再来细关注一下 FailoverClusterInvoker 中的 doInvoke 方法是怎么做的。这里的方法也 是很简单,主要是通过for循环的形式来达到重试次数的目的,并且每次重试否会重新走一遍路由等规则。
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
// 如果没有任何的invoker则抛出异常
List<Invoker<T>> copyInvokers = invokers;
this.checkInvokers(invokers, invocation);
// 获取这个方法最大的重试次数
String methodName = RpcUtils.getMethodName(invocation);
int len = this.getUrl().getMethodParameter(methodName, "retries", 2) + 1;
if (len <= 0) {
len = 1;
}
RpcException le = null;
List<Invoker<T>> invoked = new ArrayList(invokers.size());
Set<String> providers = new HashSet(len);
// 通过for循环的形式表示可以重试的次数
for(int i = 0; i < len; ++i) {
if (i > 0) {
// 每次都执行一次是否关闭当前consumer的判断
this.checkWhetherDestroyed();
// 重新获取一遍invoker列表
copyInvokers = this.list(invocation);
// 再次进行一次存在invoker的检查
this.checkInvokers(copyInvokers, invocation);
}
// 选择具体的invoker(交给负载均衡)
Invoker<T> invoker = this.select(loadbalance, invocation, copyInvokers, invoked);
// 增加到已经执行过得invoker列表中
invoked.add(invoker);
RpcContext.getContext().setInvokers(invoked);
try {
// 让其真正的去进行执行操作
Result result = invoker.invoke(invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName + " in the service " + this.getInterface().getName() + " was successful by the provider " + invoker.getUrl().getAddress() + ", but there have been failed providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + this.directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le);
}
Result var13 = result;
return var13;
} catch (RpcException var18) {
// 如果是业务异常则直接抛出
if (var18.isBiz()) {
throw var18;
}
le = var18;
} catch (Throwable var19) {
le = new RpcException(var19.getMessage(), var19);
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
// 如果重试了指定次数后依旧失败,则直接认定为失败
throw new RpcException(le.getCode(), "Failed to invoke the method " + methodName + " in the service " + this.getInterface().getName() + ". Tried " + len + " times of the providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + this.directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), (Throwable)(le.getCause() != null ? le.getCause() : le));
}
五、负载均衡实现原理
通过上面一小节我们也有看到在 Cluster 中经过负载选择真正 Invoker 的代码,这里我们再来细追踪
是如何负载均衡的。
1、再次来看看 LoadBalance 接口定义。这里默认选择了随机算法。
// 默认使用随机算法
@SPI("random")
public interface LoadBalance {
// 进行选择真正的invoker
@Adaptive({"loadbalance"})
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
2、LoadBalance 依旧选择了 AbstractLoadBalance 作为基础的实现类。我们来关注一下 select 方法。这里的方法也比较简单,主要就是处理只有一个invoker的情况。
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 如果不存在任何的invoker则直接返回
if (CollectionUtils.isEmpty(invokers)) {
return null;
} else {
// 如果还有一个invoker则直接返回,不需要执行负载均衡
// 交给子类进行实现
return invokers.size() == 1 ? (Invoker)invokers.get(0) : this.doSelect(invokers, url, invocation);
}
}
3、我们来看看默认的随机算法是如何实现的。这里主要比较关键在于权重的概念。通过权重选取了不同的机器。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 总计的invoker列表数量
int length = invokers.size();
// 默认每个invoker的权重都是相同的
boolean sameWeight = true;
// 所有的权重列表
int[] weights = new int[length];
// 首个invoker的权重信息
int firstWeight = this.getWeight((Invoker)invokers.get(0), invocation);
weights[0] = firstWeight;
// 计算总共的权重,并且吧每一个invoker的权重进行设置到列表中
int totalWeight = firstWeight;
int offset;
int i;
for(offset = 1; offset < length; ++offset) {
i = this.getWeight((Invoker)invokers.get(offset), invocation);
// save for later use
weights[offset] = i;
// Sum
totalWeight += i;
if (sameWeight && i != firstWeight) {
sameWeight = false;
}
}
// 如果权重不相同
if (totalWeigh t > 0 && !sameWeight) {
// 通过总共的权重来随机分配
offset = ThreadLocalRandom.current().nextInt(totalWeight);
// 看看最终落到哪一个机器上去
for(i = 0; i < length; ++i) {
offset -= weights[i];
if (offset < 0) {
return (Invoker)invokers.get(i);
}
}
}
// 如果权重都是相同的话,则随机选取一个即可
return (Invoker)invokers.get(ThreadLocalRandom.current().nextInt(length));
}
六、Invoker执行逻辑
Invoker就是我们真实执行请求的组件。这里也会衍生出我们真正的 Dubbo 或者 Grpc 等其他协议的请求。
1、我们依旧先来看一下接口定义:、
public interface Invoker<T> extends Node {
// 当前执行器的服务接口是哪一个
Class<T> getInterface();
// 执行请求操作
Result invoke(Invocation invocation) throws RpcException;
}
2、Invoker 同样具有 AbstractInvoker ,其中我们重点关注一下 invoke 方法。这里同样主要做的是基础信息封装,并且将请求真正的子类。这里面的子类主要是 DubboInvoker
public Result invoke(Invocation inv) throws RpcException {
// 判断系统是否已经关闭
if (this.destroyed.get()) {
this.logger.warn("Invoker for service " + this + " on consumer " + NetUtils.getLocalHost() + " is destroyed, , dubbo version is " + Version.getVersion() + ", this invoker should not be used any longer");
}
RpcInvocation invocation = (RpcInvocation)inv;
invocation.setInvoker(this);
// 设置所有的RPCContext中的附加信息
if (CollectionUtils.isNotEmptyMap(this.attachment)) {
invocation.addObjectAttachmentsIfAbsent(this.attachment);
}
Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
if (CollectionUtils.isNotEmptyMap(contextAttachments)) {
invocation.addObjectAttachments(contextAttachments);
}
// 获取执行的模式
invocation.setInvokeMode(RpcUtils.getInvokeMode(this.url, invocation));
// 设置执行id,主要用于适配异步模式使用
RpcUtils.attachInvocationIdIfAsync(this.getUrl(), invocation);
AsyncRpcResult asyncResult;
try {
// 交给子类进行真正的执行
asyncResult = (AsyncRpcResult)this.doInvoke(invocation);
} catch (InvocationTargetException var7) {
// 业务异常
Throwable te = var7.getTargetException();
if (te == null) {
asyncResult = AsyncRpcResult.newDefaultAsyncResult((Object)null, var7, invocation);
} else {
if (te instanceof RpcException) {
((RpcException)te).setCode(3);
}
asyncResult = AsyncRpcResult.newDefaultAsyncResult((Object)null, te, invocation);
}
} catch (RpcException var8) {
// RPC阶段出现了异常
if (!var8.isBiz()) {
throw var8;
}
asyncResult = AsyncRpcResult.newDefaultAsyncResult((Object)null, var8, invocation);
} catch (Throwable var9) {
asyncResult = AsyncRpcResult.newDefaultAsyncResult((Object)null, var9, invocation);
}
// 设置执行的结果信息
RpcContext.getContext().setFuture(new FutureAdapter(asyncResult.getResponseFuture()));
// 返回结果
return asyncResult;
}
3、我们再来看看 DubboInvoker 中的 doInvoke 方法。这里看到,他其实底层更多的是依赖底层真正的客户端实现。
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation)invocation;
String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment("path", this.getUrl().getPath());
inv.setAttachment("version", this.version);
// 传输的客户端
ExchangeClient currentClient;
if (this.clients.length == 1) {
currentClient = this.clients[0];
} else {
currentClient = this.clients[this.index.getAndIncrement() % this.clients.length];
}
try {
// 是否返回值,也就是相当于发送了一个指令,不在乎服务端的返回
// 通常适用于异步请求
boolean isOneway = RpcUtils.isOneway(this.getUrl(), invocation);
// 获取超时的配置
int timeout = this.getUrl().getMethodPositiveParameter(methodName, "timeout", 1000);
if (isOneway) {
// 如果不需要返回值信息(异步)
boolean isSent = this.getUrl().getMethodParameter(methodName, "sent", false);
// 发送命令
currentClient.send(inv, isSent);
// 告知为异步的结果
return AsyncRpcResult.newDefaultAsyncResult(invocation);
} else {
// 获取真正执行的线程池(ThreadPool中的SPI)
ExecutorService executor = this.getCallbackExecutor(this.getUrl(), inv);
// 发送请求并且等待结果
CompletableFuture<AppResponse> appResponseFuture = currentClient.request(inv, timeout, executor).thenApply((obj) -> {
return (AppResponse)obj;
});
// 在2.6.x中使用,设置完成的额结果信息
FutureContext.getContext().setCompatibleFuture(appResponseFuture);
// 创建新的结果信息并且返回
AsyncRpcResult result = new AsyncRpcResult(appResponseFuture, inv);
result.setExecutor(executor);
return result;
}
} catch (TimeoutException var10) {
throw new RpcException(2, "Invoke remote method timeout. method: " + invocation.getMethodName() + ", provider: " + this.getUrl() + ", cause: " + var10.getMessage(), var10);
} catch (RemotingException var11) {
throw new RpcException(1, "Failed to invoke remote method: " + invocation.getMethodName() + ", provider: " + this.getUrl() + ", cause: " + var11.getMessage(), var11);
}
}
4、我们再来详细追踪一下 ExchangeClient 接口,发现他有一个最关键的方法。位于 ExchangeChannel 接口中。
// 真实的发送请求信息
// request: RPCInvocation
// timeout: 超时
// executor: 业务线程池
CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor) throws RemotingException;
5、他底层真实的实现方式是 HeaderExchangeClient 来进行处理的。可以看到他只是交给了真实的渠道 channel 进行数据处理。
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor) throws RemotingException {
if (this.closed) {
throw new RemotingException(this.getLocalAddress(), (InetSocketAddress)null, "Failed to send request " + request + ", cause: The channel " + this + " is closed!");
} else {
// 创建一个新的request对象
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
// 创建一个执行结果的回调信息处理
DefaultFuture future = DefaultFuture.newFuture(this.channel, req, timeout, executor);
try {
// 交给真正的业务渠道进行处理
// 这里的渠道是交给Transporter这个SPI进行创建的,其中我们的NettyChannel就是在这 里产生的
this.channel.send(req);
return future;
} catch (RemotingException var7) {
// 请求出现异常则取消当前的请求封装
future.cancel();
throw var7;
}
}
}