python爬取今日头条街拍美图(2020.2月新版)
最近再学习python爬虫,有幸看到崔庆才大大的教程,这篇博客是记录自己学习过程,也是把遇到的问题记录下来,督促自己学习。
同时借鉴了这篇文章,也写的很好!
https://www.jianshu.com/p/8481e34c86c2
首先分析目标网站,搜索‘街拍美图’

通过查找,我们发现详情页信息是再XHR里,同时页面下滑,左侧会增加URL。
且只是url中的offset值改变,得出通过改变offset的值即可以遍历多个链接。
打开上图中data—0,我们发现详情页的名称即为‘title’的值,我们要得到title,只需解析,然后直接get_text(),就可以得到名称内容。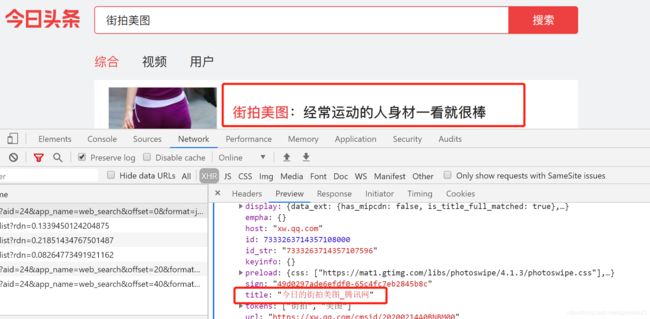
同时看到‘article_url’,点击进入这个详情页查看URL,通过查看多个,得出详情页的链接即为‘article_url’的值,解析后直接get即可!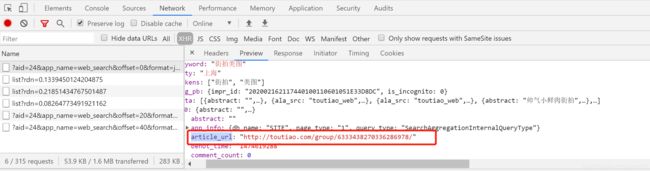
开始正式写程序;首先获取主页面,需要注意的是,要加入headers和cookie,否则会报错,params为请求的一些参数,再浏览器的headers可以找到。(当出现返回异常时,可以多看看headers和cookie,我再写的时候有出现过返回异常,改headers后就好了)传进去的参数offset是控制爬取的页面多少,keyword是控制爬取的内容(本次是‘街拍美图’)
def get_url(offset, keyword):#获取主页面
headers = {
'user - agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; s_v_web_id=k6n06g6v_lbexStV5_3Ntg_4wFE_B0ts_axcGWZuVpJm4; ttcid=007008aee03e463eb9caa0e440e9afba93; __tasessionId=qxl5qt72h1581735000822; tt_scid=a-NdD3V6Hzc21bo3bybzGZtDTFp2jVZ-NcUgYmlEYuwxvVqjZZCmAT0cyZUlplB696ea',
}
params = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'en_qc': 1,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': 158173512669,
}
url = "https://www.toutiao.com/api/search/content/?" + urlencode(params)
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
res = json.loads(r.text)#json.loads将json格式数据转换为字典
return res
except RequestException:
print('访问错误')
return None
提取详情页URL,使用yield返回生成器。因为’article_url’是在’data’中,而’data’是我们res的一个键,同时因为在获取主页面时我们返回的是字典类型(用json.loads转化过),所以我们直接get即可。
def parse_page_index(res):#提取详情页url
if res:#判断返回对象是否为空
if 'data' in res.keys():
for item in res.get('data'):
if 'article_url' in item:
yield item.get('article_url')
获取详情页,同样需要加入headers和cookie。这一步我们即可获得所有的详情页URL,到这里全部任务已经完成35%了!
def get_page_index(url):#获取详情页
headers = {
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; __tasessionId=fme29ihts1580901093483; s_v_web_id=k69b121k_igiqNCx4_57vq_40DG_BVQV_JdrkGEwFqmKB',
'user-agent': 'Mozilla/5.0'}
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.text
except RequestException:
print('访问错误')
return None
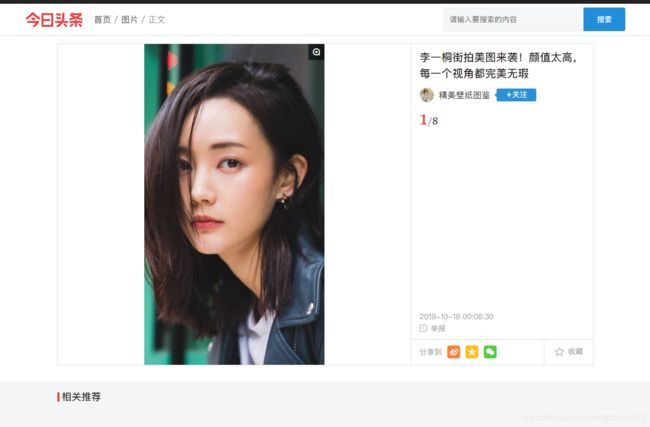
下面分析详情页,现在今日头像的图片部分有两种结构,一种是所有的图片都在一个框内展示(如下图),还有一直就是普通的下拉图文格式,我们分析第一种结构(我会告诉你因为崔大神只教了这个结构么!)
查看详情页,我们发现图片的url在‘JSON.parse’中(应该是网址改变,这里和崔大神的教程不一样)解析后,使用正则表达式提取出来即可!
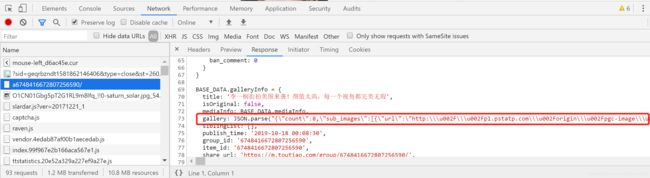
因爬出的链接中,含有大量的多余的‘\’以及‘u002F’,使用replace将其替换成正常URL(通过打开详情页,对比地址栏的链接与爬出的链接)
def parse_detail(html, url):#解析详情页
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()#获取详情页名称
#print(title)
if 'JSON.parse' in html:
img = re.compile(r'gallery: JSON.parse\("(.*)"\),', re.S)#获取图片url
photo = re.search(img, html)
#print(photo.group(1))
#group(1)只提取第一组
if photo.group(1):
data = json.loads(photo.group(1).replace('\\', ''))
#print(data)
if data:
if "sub_images" in data.keys():
sub = data.get("sub_images")
#replace('u002F', '/')
images = [item.get('url').replace('u002F', '/') for item in sub]
for image in images:
get_images(image)
return {
'title': title,
'url': url,
'images': images
}
到这里可以得到所有图片的url,既可以下载这些图片,因是图片我们使用content返回二进制数据。
def get_images(url):
headers = {
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; __tasessionId=fme29ihts1580901093483; s_v_web_id=k69b121k_igiqNCx4_57vq_40DG_BVQV_JdrkGEwFqmKB',
'user-agent': 'Mozilla/5.0'}
print('正在下载', url)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
save_image(res.content)#content以二进制的格式返回数据
return None
except RequestException:
print('下载图片出错')
return None
保存图片,使用md5防止图片重复,并命名图片
def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')#文件存储地址
#os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径。
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
将信息保存到MongoDB。这里需要在建一个文件,写入MongoDB数据库的一些内容
def save_to_mongo(result):
if result:
if db[MONGO_TABLE].insert_one(result):
print('存储到MongoDB成功!', result)
return True
return False
下面给出全部代码:
MongoDB:(起的文件名称是“ config.py ”)
MONGO_URL = 'localhost'#链接地址
MONGO_DB = 'toutiao'#数据库名称
MONGO_TABLE = 'toutiao'#表名
GROUP_START = 1
GROUP_END = 20
KEYWORD = '街拍美图'
主代码:
import json
import os
import re
from hashlib import md5
from urllib.parse import urlencode
import pymongo
import requests
from requests import RequestException
from bs4 import BeautifulSoup
from config import *
from multiprocessing import Pool
client = pymongo.MongoClient(MONGO_URL,)# 连接本地的数据库
db = client[MONGO_DB]#创建数据库:给数据库命名
def get_url(offset, keyword):#获取主页面
headers = {
'user - agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; s_v_web_id=k6n06g6v_lbexStV5_3Ntg_4wFE_B0ts_axcGWZuVpJm4; ttcid=007008aee03e463eb9caa0e440e9afba93; __tasessionId=qxl5qt72h1581735000822; tt_scid=a-NdD3V6Hzc21bo3bybzGZtDTFp2jVZ-NcUgYmlEYuwxvVqjZZCmAT0cyZUlplB696ea',
}
params = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'en_qc': 1,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': 158173512669,
}
url = "https://www.toutiao.com/api/search/content/?" + urlencode(params)
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
res = json.loads(r.text)
return res
except RequestException:
print('访问错误')
return None
def parse_page_index(res):#提取详情页url
if res:
if 'data' in res.keys():
for item in res.get('data'):
if 'article_url' in item:
yield item.get('article_url')
def get_page_index(url):#获取详情页
headers = {
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; __tasessionId=fme29ihts1580901093483; s_v_web_id=k69b121k_igiqNCx4_57vq_40DG_BVQV_JdrkGEwFqmKB',
'user-agent': 'Mozilla/5.0'}
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.text
except RequestException:
print('访问错误')
return None
def parse_detail(html, url):#解析详情页
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()#获取详情页名称
#print(title)
if 'JSON.parse' in html:
img = re.compile(r'gallery: JSON.parse\("(.*)"\),', re.S)#获取图片url
photo = re.search(img, html)
#print(photo.group(1))
if photo.group(1):
data = json.loads(photo.group(1).replace('\\', ''))
#print(data)
if data:
if "sub_images" in data.keys():
sub = data.get("sub_images")
# for item in sub:
# yield item.get("url").replace('u002F', '/')
images = [item.get('url').replace('u002F', '/') for item in sub]
for image in images:
get_images(image)
return {
'title': title,
'url': url,
'images': images
}
def get_images(url):
headers = {
'cookie': 'tt_webid=6756552095103878663; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6756552095103878663; csrftoken=e3986e027ddb4e2f9307dbd024811241; __tasessionId=fme29ihts1580901093483; s_v_web_id=k69b121k_igiqNCx4_57vq_40DG_BVQV_JdrkGEwFqmKB',
'user-agent': 'Mozilla/5.0'}
print('正在下载', url)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
save_image(res.content)
return None
# r = res.content
# file_path = "{0}/{1}.{2}".format(os.getcwd(),md5(r).hexdigest(),'jpg')
# f = open(file_path, 'wb')
# f.write(r)
except RequestException:
print('下载图片出错')
return None
def save_to_mongo(result):
if result:
if db[MONGO_TABLE].insert_one(result):
print('存储到MongoDB成功!', result)
return True
return False
def save_image(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_url(offset, KEYWORD)
items = parse_page_index(html)
for item in items:
#print(item)
html1 = get_page_index(item)
# parse_detail(html1)
result = parse_detail(html1, item)
#print(html2)
save_to_mongo(result)
if __name__ == "__main__":
groups = [x*20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
pool.close()
main()
运行结果:

MongoDB结果:
爬取到的图片:

自从开始学爬虫,身体一天不如一天!