实时法线贴图dxt压缩算法
JMP van Waveren |
|
2008年2月7日
©2008,id Software,Inc.
抽象
使用今天的图形硬件,普通地图可以存储在几种压缩格式中,这些格式在渲染过程中在硬件上即时解压缩。对使用现有纹理压缩格式的几个对象空间和正切空间法线贴图进行评估。虽然这些格式的解压缩在渲染过程中在硬件中实时发生,但是使用现有的压缩器可能需要大量时间的压缩。提出了两种高度优化的切线空间法线贴图压缩算法,可以在CPU和GPU上实现实时性能。
介绍
凹凸映射使用纹理来扰乱表面法线,以使对象更具有几何复杂的外观,而不增加几何图元的数量。如Blinn [ 1 ] 最初描述的,凹凸贴图在计算表面的照明之前,使用凹凸贴图高度场的梯度来扰动表面衍生(方向向量)方向上的内插表面法线。通过改变表面法线,表面被点亮,好像它具有更多的细节,结果也被认为比用于描述表面的几何图元具有更多的细节。
正态映射是凹凸映射的应用,由Peercy等引入 [ 2 ]。虽然凹凸贴图扰乱了对象的现有表面法线,但是正常映射完全取代了法线。普通地图是存储法线的纹理。这些法线通常存储为具有三个组件的单位长度向量:X,Y和Z.正常映射比凹凸贴图具有显着的性能优势,因为计算表面照明所需的操作更少。
通常的映射通常在两个品种中找到:对象空间和正切空间法线映射。它们在测量和存储法线的坐标系中不同。对象空间法则映射相对于整个对象的位置和方向存储法线。切线空间法线相对于三角形顶点的内插切线空间存储。虽然物体空间法线可以是单位球体上的任何地方,但正切空间法线仅在表面前方的单位半球上,因为法线总是指向表面。
 |
 |
| 对象空间法线贴图(左) 和切线空间中相同法线贴图(右)的示例。 |
|
正常并不一定必须存储为具有组件X,Y和Z的向量。然而,从其他表示形式的渲染通常以性能成本来存储。例如,通常可以存储为角度对(俯仰,偏航)。然而,该表示具有内插或滤波不能正常工作的问题,因为存在可能不存在用于表示局部旋转的角度的简单变化的方向。在内插,滤波或计算该物体的表面照明之前,角度对必须转换为不同的表示,如矢量,这需要昂贵的三角函数。
尽管法线贴图可以存储为浮点纹理,但是通常将法线贴图存储为有符号或无符号整数纹理,因为法向矢量的分量取值范围很广(通常为[-1,+1] ),并且在不浪费浮点指数的任何位的情况下,在整个范围内具有相同的精度是有益的。例如,要将法线贴图存储为每个分量8位的无符号整数纹理,X,Y和Z分量将从[-1,+1]范围内的实数值重新整数到[0, 255]。这样,实值向量[0,0,1]被转换成整数向量[128,128,255],当被解释为RGB空间中的一个点时,是紫色/蓝色主要在切线空间法线贴图 为了呈现存储为无符号整数纹理的法线贴图,矢量分量首先从一个整数值映射到硬件中的浮点范围[0,+1]。例如,在每个分量具有8位的纹理的情况下,通过与255分割将整数范围[0,255]映射到浮点范围[0,+1]。然后,组件通常从[0,+1]范围在片段程序渲染过程中通过在与2相乘后减1后范围为[-1,+1]范围。当使用有符号整数纹理时,从整数值到浮点数范围[-1,+1]直接在硬件中执行。矢量分量首先从整数值映射到硬件中的浮点范围[0,+1]。例如,在每个分量具有8位的纹理的情况下,通过与255分割将整数范围[0,255]映射到浮点范围[0,+1]。然后,组件通常从[0,+1]范围在片段程序渲染过程中通过在与2相乘后减1后范围为[-1,+1]范围。当使用有符号整数纹理时,从整数值到浮点数范围[-1,+1]直接在硬件中执行。矢量分量首先从整数值映射到硬件中的浮点范围[0,+1]。例如,在每个分量具有8位的纹理的情况下,通过与255分割将整数范围[0,255]映射到浮点范围[0,+1]。然后,组件通常从[0,+1]范围在片段程序渲染过程中通过在与2相乘后减1后范围为[-1,+1]范围。当使用有符号整数纹理时,从整数值到浮点数范围[-1,+1]直接在硬件中执行。
是否使用有符号或无符号整数纹理,一个根本的问题是不可能从二进制整数到浮点范围[-1,+1] 导出线性映射,使得值-1,和+1表示准确。在先前的NVIDIA实现中使用的带符号整数纹理的硬件映射并不完全代表+1。对于n位无符号整数分量,整数0映射到-1,整数2 n-1映射到0,最大整数值2 n -1映射到1 - 2 1-n。换句话说,值-1和0被精确地表示,但值+1不是。用于DirectX 10类硬件的映射是非线性的。对于n位有符号整数分量,整数-2 n-1映射到-1,整数-2 n-1 +1也映射到-1,整数0映射到0,整数2 n-1 -1映射到+1。换句话说,值-1,0和+1都被精确地表示,但值-1表示两次。
旧硬件不支持签名纹理。此外,从二进制整数到范围[-1,+1]的映射可能是硬件特定的。一些实现可能选择不完全代表+1,而传统的OpenGL映射指定-1和+1可以被精确地表示,但是0不能。其他实现可以选择非线性映射,或允许超出范围[-1,+1]的值,使得可以精确地表示所有三个值-1,0和+1。为了覆盖最广泛的硬件范围,没有任何硬件特定的依赖关系,这里使用的所有法线图被假设存储为无符号整数纹理。从[0,+1]到[-1,+1]范围内的映射在片段程序中通过在乘以2之后减1来执行。这可能导致附加的片段程序指令,当使用带符号的纹理时,可以将其简单地删除。这里使用的映射与传统的OpenGL映射相同,这导致值-1和+1的精确表示,但不是0。
整数法线贴图通常可以按照每个法向量16(5:6:5),24(8:8:8),48(16:16:16)或96(32:32:32)位存储。然而,今天的大部分普通地图都不存在每个法向量不超过24(8:8:8)位。重要的是要认识到实际上接近单位长度的相对较少的8:8:8位向量。例如,在RGB空间中为深蓝色的整数向量[0,0,64]不表示单位长度的法向量(长度为0.5而不是1.0)。下图显示了比单位长度小于特定百分比的可表示的8:8:8位向量的百分比。
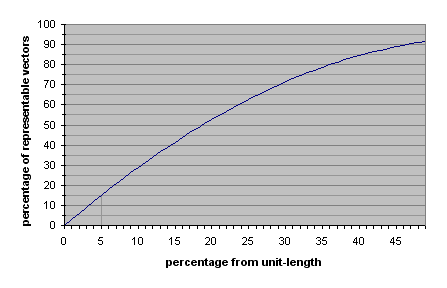
例如,如果法向量不被认为是单位长度大于5%的可接受的话,那么只有大约15%的可表示的8:8:8位向量可用于表示法向量。如5:6:5位那样精确度较低的位,接近单位长度的可表示向量的数量迅速减少。
为了显着增加可以使用的向量的数量,可以将每个法向量存储为不一定是单位长度的方向。然后,这个方向需要在片段程序中进行归一化。然而,仍然有一些浪费,因为只有83%的所有8:8:8位向量表示唯一的方向。例如,整数向量[0,0,32],[0,0,64]和[0,0,96]都指定完全相同的方向(它们是彼此的倍数)。此外,独特的标准化方向不是均匀分布在单位球体上。对于[-1,+1] x [-1,+1] x [-1,+1]向量空间的边界框的四个对角线的方向,有更多的表示方式,到坐标轴。例如,在向量[1,1,1]周围的15度半径内表示的方向比在向量[0,0,1]周围15度半径内的方向表示三倍。下图显示了投射到单位球体上的所有可表示的8:8:8位矢量的分布。载体密度较低的区域为绿色,密度较高的区域为红色。
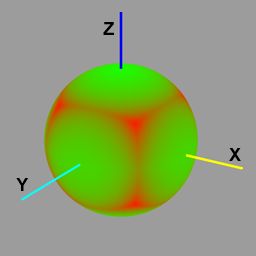 |
| 8:8:8位向量 投影在单位球体上的分布 |
在今天的图形硬件上,普通地图也可以以多种压缩格式存储,在渲染过程中实时解压缩。由于减少的带宽要求,压缩的法线贴图不仅要求显卡内存少得多,而且通常还会比未压缩的法线贴图快。各种不同的方式来利用现有的纹理压缩格式的正常地图压缩,已被建议在文献[ 7,8,9 ]。这些正常的地图压缩技术中的几个以及它们的扩展在第2节和第3节进行了评估。
虽然这些格式的解压缩是在硬件中实时完成的,但对这些格式的压缩可能需要相当长的时间。现有压缩机设计为高质量离线压缩,而不是实时压缩[ 20,21,22 ]。然而,实时压缩对于从不同格式的代码转换法线图,动态生成的法线贴图的压缩以及压缩的法线贴图渲染目标来说是非常有用的。在第4节和第5节中,提出了两种高度优化的切线空间法线贴图压缩算法,可用于实现CPU和GPU的实时性能。
对象空间正常图
对象空间法则映射相对于整个对象的位置和方向存储法线。物体空间中的常规可以在整个单位球体上的任何地方,并且通常存储为具有三个组件的向量:X,Y和Z.可以使用常规颜色纹理压缩技术存储对象空间法线贴图,但是这些技术可能不会有效,因为法线贴图不具有与颜色纹理相同的属性。
2.1对象空间DXT1
DXT1 [ 3,4 ],也被称为在DirectX 10 BC1 [ 5 ],是用于颜色纹理一种有损压缩格式,以8:1的固定压缩比为2:1。DXT1格式设计用于在渲染过程中对显卡硬件进行实时解压缩。DXT1压缩是块截断编码(BTC)[ 6 ]的一种形式,其中图像被划分为非重叠块,并且每个块中的像素被量化为有限数量的值。4×4像素块中的像素的颜色值通过RGB颜色空间在一行上的等距点近似。该行由两个端点定义,对于4x4块中的每个像素,2位索引存储在该行上的一个等距点上。通过颜色空间的线的端点被量化为16位5:6:5 RGB格式,并且通过插值生成一个或两个中间点。DXT1格式允许通过根据终点的顺序切换到不同的模式,其中仅生成一个中间点并指定一个附加颜色,这是黑色和完全透明的。
虽然DXT1格式是为颜色纹理设计的,但此格式也可用于存储法线贴图。为了将法线贴图压缩成DXT1格式,法线向量的X,Y和Z分量映射到颜色纹理的RGB通道。特别是对于DXT1压缩,每个法向量分量从[-1,+1]范围映射到整数范围[0,255]。在光栅化期间,DXT1格式在硬件中解压缩,并且整数范围[0,255]映射到硬件中的浮点范围[0,1]。在片段程序中,范围[0,1]将必须映射回范围[-1,+1]以执行法向量的照明计算。以下片段程序显示了如何使用单个指令实现此转换。
#input.x = normal.x[0,1] #input.y = normal.y
将法线贴图压缩成DXT1格式通常会导致质量相当差。有明显的阻塞和条带伪影。每4×4块只能编码四个不同的法向量,这通常不足以准确地表示块中的所有原始法向量。因为每个块中的法线在一行上用等距点近似,所以也不可能对每个4×4块的四个不同的法向量编码都是单位长度。每4x4块只有两个法向量可以一次接近单位长度,通常一个压缩器通过向量空间来选择一个最小化一些误差度量的一条线,使得这些向量实际上不接近单位长度。
 |
 |
| 右侧的DXT1压缩法线贴图 与左侧的原始法线贴图相比,显示出明显的块状伪影。 |
|
为了提高质量,可以将每个法向量编码为不一定是单位长度的方向。然后,该方向必须在片段程序中重新归一化。以下片段程序显示了法向量如何重新归一化。
#input.x = normal.x
编码方向使压缩机更自由,因为压缩机不必担心向量的大小,并且可以通过正常空间将所有可表示向量的大部分百分比用于线路的终点。然而,这种增加的自由使压缩成为一个更难的问题。
|
 |
| DXT1压缩的法线贴图与 右侧的原始法线贴图相比右侧重新归一化。 |
|
以上图片显示,尽管质量好一点,质量一般还是比较差。无论是否在片段程序中重新规范化,DXT1压缩对象空间法线贴图的质量一般不被认为是可以接受的。
2.2对象空间DXT5
所述DXT5格式[ 3,4 ],也被称为在DirectX 10 BC3 [ 5 ],存储三个颜色通道中的相同的方式DXT1确实,但没有1位alpha通道。代替1位alpha通道,DXT5格式存储与DXT1色彩通道相似的单独的Alpha通道。4x4块中的alpha值通过α空间在一行上的等距点近似。通过α空间的线的端点存储为8位值,并且基于端点的顺序,通过插值生成4或6个中间点。对于4个中间点的情况,生成两个附加点,一个完全不透明,另一个用于完全透明。对于4x4块中的每个像素,3位索引通过alpha空间或两个附加点中的一个存储到该行上的等距点之一,用于完全不透明或完全透明。使用相同数量的位来将alpha通道编码为三个DXT1颜色通道。因此,与三维颜色空间相反,α通道以比每个颜色通道更高的精度被存储,因为α空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。使用相同数量的位来将alpha通道编码为三个DXT1颜色通道。因此,与三维颜色空间相反,α通道以比每个颜色通道更高的精度被存储,因为α空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。使用相同数量的位来将alpha通道编码为三个DXT1颜色通道。因此,与三维颜色空间相反,α通道以比每个颜色通道更高的精度被存储,因为α空间是一维的。此外,总共有8个样本表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。总共有8个样本来表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。总共有8个样本来表示4×4块中的α值,而不是4个样本来表示颜色值。由于额外的Alpha通道,DXT5格式消耗DXT1格式的内存量的两倍。
DXT5格式设计用于具有平滑alpha通道的颜色纹理。但是,此格式也可用于存储对象空间法线贴图。特别地,可以通过使用DXT5格式并将其中一个组件移动到Alpha通道来实现更好质量的法线贴图压缩。通过将其中一个组件移动到Alpha通道,该组件以更高的精度存储。此外,通过仅对DXT5格式的DXT1块中的两个组件进行编码,这些组件的存储准确度通常也会得到改善。对于对象空间法线图,由于法向量可以指向任何方向,因此所有元素都可以以相似的频率发生,所以没有明确的优点将任何特定的组件移动到alpha通道。当对象空间法线贴图在特定方向上确实具有最多的向量时,将与该方向最正交的轴线映射到阿尔法通道显然是一个好处。然而,由于每个编码需要不同的片段程序,所以通常在每个法线贴图上改变编码是不切实际的。以下片段程序假设Z组件移动到alpha通道。片段程序显示了组件如何从范围[0,1]映射到范围[-1,+1],而Z组件也从alpha通道移回原位。因为每个编码都需要一个不同的片段程序。以下片段程序假设Z组件移动到alpha通道。片段程序显示了组件如何从范围[0,1]映射到范围[-1,+1],而Z组件也从alpha通道移回原位。因为每个编码都需要一个不同的片段程序。以下片段程序假设Z组件移动到alpha通道。片段程序显示了组件如何从范围[0,1]映射到范围[-1,+1],而Z组件也从alpha通道移回原位。
#input.x = normal.x
就像DXT1一样,没有重新规范化,这种格式导致片段程序中的最小开销。质量明显优于对象空间法向贴图的DXT1压缩。然而,仍然存在明显的阻塞和条纹伪像。
|
 |
| 右侧的DXT5压缩法线贴图 与左侧原始法线贴图相比较。 |
|
使用第三个通道来存储比如从[ 24 ] 的YCoCg-DXT5压缩完成的比例因子并不能提高质量。单个组件的动态范围通常太大,或者不同的组件跨越不同的范围,而组合的动态范围只有一个比例因子。
就像对象空间法线图的DXT1压缩一样,通过将法向量编码为不一定是单位长度的方向,可以提高质量。以下片段程序显示如何执行swizzle和重新归一化。
#input.x = normal.x
编码方向给予压缩机更多的自由度,因为压缩器可以忽略向量的大小,并且可以通过正常空间将所有可表示向量的更大百分比用于线的端点。使用DXT5格式的DXT1块和alpha通道对法线矢量进行编码,其中Alpha通道的端点不存储量化。因此,线的端点的潜在搜索空间可能非常大,并且高质量压缩可能需要相当长的时间。
|
 |
| DXT5压缩的法线贴图与 右侧的原始法线贴图相比右侧重新归一化。 |
|
在当前硬件上,片段程序中重新归一化的DXT5格式导致对象空间法线贴图的最佳质量压缩。
切线 - 空间正常图
切线空间法向量相对于三角形顶点的内插切线空间存储。因为动态范围较低,切线空间法线贴图的压缩通常比对象空间法线贴图的效果更好。向量只在表面前面的单位半球(法向量从不指向对象)。此外,大多数正常向量接近单位半球的尖端,Z接近1。
与使用对象空间法线图相比,使用切线空间法线贴图本身可以被认为是一种压缩形式。使用局部变换来改变矢量分量的频域,从而降低其存储要求。该变换确实需要将切向量存储在三角形顶点处,并且因此成本。然而,与正常地图的存储要求相比,切线向量的存储要求相对较小。
通过仅存储单位长度法向量的X和Y分量以及导出Z分量,可以改善切线空间法线贴图的压缩。法向量总是向上指向表面,Z总是为正。此外,法向量是单位长度,因此,可以如下导出Z。
Z = sqrt(1-X * X-Y * Y)
从X和Y重建Z的问题是它是一个非线性运算,并在双线性滤波下分解。当在XY平面中的两个法线之间进行插值时,这个问题最为显着。理想地,使用法向量的球面插值来放大法线贴图,其中内插样本以恒定速度跟随单位球体上的最短大弧。三分法法线图的双线性滤波,在片段程序中进行重新归一化,不会以恒定速度产生球面插值,但至少内插样本遵循最短的大弧。然而,使用双分量法线贴图,其中Z从X和Y导出,内插样本不再必须跟随单位球上的最短大弧。例如,预计下图中两个向量之间的插值将跟随虚线。然而,相反,内插样本在单位球上上升的弧上。
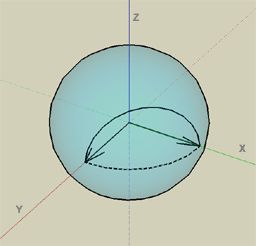
幸运的是,现实世界的正常地图通常与邻近XY平面的邻近矢量不具有很多尖锐的正常边界,大多数法线指向直线。因此,在导出Z分量之前,双线性或三线性过滤双分量法线图时通常不会有明显的伪影。
仅存储X和Y分量本质上是沿Z轴的法向量向XY平面的正投影。为了重构原始法向量,通过从X和Y中导出Z分量,可以使用返回到单位半球的投影。代替该正投影,也可以使用立体投影。对于立体投影,X和Y分量如下划分一个加Z,其中(pX,pY)是法向量的投影。
pX = X /(1 + Z) pY = Y /(1 + Z)
通过将立体投影向量投影到单位半球上来重建原始法向量,如下。
denom = 2 /(1 + pX * pX + pY * pY) X = pX * denom Y = pY * denom Z = denom - 1
使用立体投影的优点是内插法线矢量在双线性或三线性滤波下表现更好。内插的法向量仍然不在最短的大弧上,但是它们更接近,并且在单位半球上具有更少的上升趋势。
立体投影还导致pX和pY分量的更均匀分布与单位半球上的角度。虽然这似乎是可取的,但实际上并不是这样,因为大多数正切空间的法向量靠近单位半球的尖端。因此,使用正交投影实际上有一个优点,其导致Z接近1的向量的更多表示。下面讨论的压缩技术使用正投影,因为对于大多数正常映射,其导致更好的质量压缩。
3.1切线空间DXT1
使用正切空间法线图,只有X和Y分量必须以DXT1格式存储,Z分量可以在片段程序中导出。以下片段程序显示如何从X和Y派生Z。
#input.x = normal.x
以下图像显示右侧的XY_ DXT1压缩法线贴图,位于左侧原始法线贴图旁边。DXT1压缩的法线贴图显示明显的阻塞和条纹伪影。
 |
 |
| XY_ DXT1压缩的法线贴图 与左侧原始法线贴图相比较。 |
|
尽管起初似乎这种压缩应该产生优质的质量,但通常可以通过存储所有三个组件并在片段程序中重新归一化来实现更好的质量压缩,就像对象空间法线图一样。当只有X和Y分量以DXT1格式存储时,通过导出Z分量来自动归一化重构法线矢量。当X和Y分量由于DXT1压缩而失真,其中所有点通过XY空间放置在直线上时,导出的Z中的误差可能相当大。
下面显示的用于重新归一化DXT1压缩法线的片段程序与用于具有重新归一化的DXT1压缩对象空间法线贴图相同。
#input.x = normal.x
以下图像显示了右侧重新归一化的DXT1压缩法线贴图,在左侧的原始法线贴图旁边。
|
|
| DXT1压缩的法线贴图与 右边的正规化法相比,左边是原来的法线贴图。 |
|
无论哪种方式,无论是在DXT1中存储两个组件并导出Z,还是将DXT1格式中的所有三个组件存储在片段程序中的重新归一化,质量相当差。
3.2切线空间DXT5
就像对象空间法线图一样,所有三个组件都可以以DXT5格式存储。通常在存储_YZX数据时可以获得最佳结果。换句话说,X分量被移动到alpha通道。这种技术也被称为RxGB压缩,并被用于电脑游戏DOOM III。通过将X分量移动到alpha通道,X和Y分量被分别编码。这提高了质量,因为X和Y组件在最大动态范围内最独立。Z始终为正,通常接近1,因此,将Z分量与Y分量存储在DXT5格式的DXT1部分中会导致Y分量几乎不失真。存储所有三个组件会导致片段程序中的最小开销,如下所示。
#input.x = 0 #input.y = normal.y
以下图像显示,虽然质量优于DXT1压缩,但仍然有明显的条带伪像。
|
 |
| 右侧的DXT5压缩法线贴图 与左侧原始法线贴图相比较。 |
|
就像对象空间法线图一样,可以通过存储不一定是单位长度的方向来改善质量。通过将X组件移动到DXT5 alpha通道也可以实现最佳质量。以下片段程序显示了如何在将X组件从alpha通道移回到原位后如何重新归一化方向。
#input.x = normal.x
以下图像显示,在片段程序中具有重新归一化的编码方向减少了带状伪像,但是它们仍然非常显着。
|
 |
| DXT5压缩的法线贴图与 右侧的原始法线贴图相比右侧重新归一化。 |
|
对于大多数正切空间的法线贴图,仅通过将X和Y组件存储在DXT5格式中并获得Z即可实现更好的质量压缩。这也称为DXT5nm压缩,并且在当今的电脑游戏中是最受欢迎的。以下片段程序显示了Z是如何从X和Y组件导出的。
#input.x = 0 #input.y = normal.y
以下图像显示仅存储X和Y并导出Z,进一步减少了带状伪像。
|
 |
| DXT5压缩的法线贴图只在 右边的X和Y 与左边原来的法线贴图相比较。 |
|
当使用XY_ DXT1,_YZX DXT5或_Y_X DXT5压缩用于切线空间法线贴图时,至少有一个可用于存储比例因子的备用通道,可用于对抗与YCoCg-DXT5类似的量化误差压缩机从[ 24 ]。然而,尝试升级组件以对抗量化误差不会提高质量(通常PSNR改善小于0.1 dB)。组件只有在动态范围较小时才能进行放大。虽然大多数法线指向直线,并且大多数XY向量的幅度相对较小,但XY分量的动态范围实际上仍然相当大。即使所有的法线都不会从直线偏离45度以上,那么每个X或Y分量仍然可以映射到范围[-cos(45°)+ + cos(45°)],其中cos(45°)≅0.707。换句话说,即使是从直线向下偏离小于45度的角度范围的50%,每个部件仍然可以覆盖超过最大动态范围的70%。一方面,这是一件好事,因为对于正切空间法向量的分量,这意味着动态范围的最大部分涵盖最常发生的值。另一方面,这意味着由于动态范围相对较大而难以升级组件。因为对于正切空间法向矢量的分量,这意味着动态范围的最大部分涵盖最常发生的值。另一方面,这意味着由于动态范围相对较大而难以升级组件。因为对于正切空间法向矢量的分量,这意味着动态范围的最大部分涵盖最常发生的值。另一方面,这意味着由于动态范围相对较大而难以升级组件。
在_Y_X DXT5压缩切线空间法线图的情况下,有两个未使用的通道,其中一个通道也可用于存储偏置以使动态范围居中。这显着增加了4x4块的数量,可以对这些块进行放大(通常,所有4x4块中的75%以上的块通常使用至少为2的比例因子)。然而,即使使用偏差来增加缩放的4×4块的数量对提高质量没有太大的帮助。真正的问题是DXT1块的四个采样点根本不足以准确地表示4x4块中法线的所有Y分量。引入更多的采样点将显着提高质量,但这在DXT5格式中显然是不可能的。
代替存储偏差和比例,备用信道之一,也可用于存储正常矢量的旋转在绕Z轴的4×4块,如[建议的11,12 ]。可以使用这样的旋转来找到XY向量的更紧密的边界框。特别是使用_Y_X DXT5压缩这样的旋转可以用来确保具有最大动态范围的轴映射到阿尔法通道,这样被更精确地压缩。为了能够将具有最大动态范围的轴映射到Alpha通道,可能需要高达180度的旋转。该旋转可以作为5位通道之一中的整个4x4块的常数值存储。代替存储旋转角度,可以存储角度的余弦,使得余弦不必在片段程序中计算,其中矢量需要旋转回其原始位置。在[0,180]度范围内进行旋转的正弦值总是为正值,因此可以如下从片段程序中的余弦中导出。
正弦= sqrt(1 - 余弦*余弦)
在4×4块中旋转法线的PSNR改善是显着的,通常在2至3dB的范围内。不幸的是,相邻的4×4块可能需要非常不同的旋转,并且在双线性或三线性滤波下,对于具有不同旋转的两个4×4块之间的边界处的滤波纹迹样本,可能出现可见的伪像。在旋转施加到X和Y分量之前,分别对X,Y和旋转进行过滤。这样,滤波的旋转被施加到经过滤的X和Y分量,其与首先旋转回其原始位置的滤波X和Y分量不同。换句话说,除非法线贴图只是点采样,使用旋转也不是提高DXT1或DXT5法线贴图质量的选择。
当然,如[ 8 ] 所述,非归一化值仍然可以存储在一个备用通道中。非正规化值用于缩小较低mip级别的法向量,使得镜面亮度随着距离而消失以减轻混叠伪影。
3.3切线空间3Dc
3Dc格式[ 10 ]专门设计用于切线空间法线贴图压缩,并产生比DXT1或DXT5法线贴图压缩更好的质量。3Dc格式仅存储两个通道,因此不能用于对象空间法线贴图。格式基本上由每个4x4法线块的两个DXT5 alpha块组成。换句话说,对于每个4×4块,存在8个X分量的样本,并且对于Y分量也有8个独立样本。Z分量必须在片段程序中导出。
DirectX 10中的3Dc格式也被称为BC5 [ 5 ]。在OpenGL中可以将相同的格式作为LATC或RGTC加载。使用LATC格式,在所有三个RGB通道中复制亮度。这可以特别方便,因为这种方式可以将LATC和_Y_X DXT5(DXT5nm)压缩的法线贴图用于相同的旋转(和片段程序代码)。换句话说,相同的片段程序可以用在不支持3Dc的硬件上。以下片段程序显示当法线贴图以RGTC格式存储时Z如何从X和Y分量派生。
#normal.x = x
以下图像显示了与_Y_X DXT5(DXT5nm)相比,正常地图的3Dc压缩如何导致显着更少的条带。
|
 |
| 右侧的3Dc压缩法线贴图 与左侧的原始法线贴图相比。 |
|
到的3Dc几个扩展,提出在[ 11 ]和专门用于改进正常地图压缩设计了一种新格式在[呈现12 ]。但是,这些格式在当前的图形硬件中不可用。在所有DirectX 10兼容的硬件上,3Dc(或BC5)格式可以产生最佳质量切线空间法线贴图压缩。在不实现3Dc的旧硬件上,通常使用_Y_X DXT5(DXT5nm)实现最佳质量。
4.实时压缩CPU
虽然从前面部分描述的格式解压缩是在硬件中实时完成的,但对这些格式的压缩可能需要相当长的时间。现有压缩机设计为高质量离线压缩,而不是实时压缩[ 20,21,22 ]。然而,实时压缩对于以不同(更高效的)格式压缩存储在磁盘上的法线贴图,并且压缩动态生成的法线贴图是非常有用的。
在今天的渲染引擎中,切线空间法线贴图比对象空间法线贴图更受欢迎。在当前的硬件上,没有压缩格式可用于非常适用的对象空间法线贴图。第2节中描述的物体 - 空间法线贴图压缩技术全部导致明显的伪像,或压缩非常昂贵。
对象空间法线贴图也不能在动画对象上使用。当物体表面动画化时,物体空间法向矢量保持指向相同的物体空间方向。另一方面,切线空间法线贴图相对于三角形顶点的切线空间存储法线。当物体的表面动画并且切面矢量(存储在三角形顶点处)与表面一起变换时,相对于这些切向矢量存储的切线 - 空间法向量也将与表面一起动画。因此,这里的重点是实时压缩切线空间法线贴图。
在3Dc(BC5或LATC)格式不可用的硬件上,_Y_X DXT5(DXT5nm)格式通常会产生最佳质量切线空间法线贴图压缩。实时_Y_X DXT5压缩器与[ 23 ] 的实时DXT5压缩器非常相似。
首先计算XY正常空间的边界框。用于近似X和Y值的两条线从最小值到该边界框的最大值。为了改善均方误差(MSE),边界框在任一端插入线上采样点之间的距离的四分之一。Y组件存储在“绿色”通道中,在“彩色”空间上有4个采样点。因此,最小和最大Y值插入范围的1/16。X组件存储在“alpha”通道中,并且在“alpha”空间上有8个采样点。因此,最小和最大X值是在范围的1/32之间插入的。
仅使用“彩色”通道的单个通道来存储法线矢量的Y分量。使用这种知识,[ 23 ] 的实时DXT5压缩器可以进一步针对_Y_X DXT5压缩进行优化。通过Y空间在线上的最佳匹配点可以以类似的方式找到,在[ 23 ] 的DXT5压缩器中,通过“alpha”空间的线上的最佳匹配点可以找到。首先计算一组交叉点,其中Y值从最接近一个采样点到另一个采样点。
字节mid =(max-min)/(2 * 3); 字节gb1 = max - mid; 字节gb2 =(2 * max + 1 * min)/ 3 - mid; 字节gb3 =(1 * max + 2 * min)/ 3 - mid;
然后可以测试AY值是否大于等于每个交叉点,并且这些比较的结果(0为false,1为真)可以加在一起以计算索引。这导致索引0到3从最小到最大值的顺序如下。
|
但是,“颜色”采样点按照DXT5格式进行不同的排序,如下所示。
|
从四个减去比较的结果,并将结果与按位逻辑AND和3结合,导致以下顺序。
|
订单接近正确,但最小和最大值仍然交换。以下代码显示了如何将Y值与交叉点进行比较,以及如何从比较结果计算指标,其中索引0和1在XOR-ing结束时通过比较结果进行交换(2>指数)。
unsigned int result = 0; for(int i = 15; i> = 0; i--){ 结果<< = 2; 字节g =块[i * 4]; int b1 =(g> = gb1); int b2 =(g> = gb2); int b3 =(g> = gb3); int index =(4-b1-b2-b3)&3; index ^ =(2> index); result | = index; }
使用SIMD指令,每个字节比较会产生一个字节,全部为零(当表达式为假时)或全部1位(当表达式为真时)。当被解释为有符号(两个补码)整数时,字节比较的结果等于数字0(对于假)或数字-1(对于真)。而不是明确地减去一个导致为真的比较的1,比较的实际结果可以简单地作为带符号整数加到值4中。
“alpha”通道的指标计算与[ 23 ]中实时DXT5压缩机的计算非常相似。然而,通过减法而不是相加选择最佳匹配采样点,可进一步优化计算。首先,计算X值从最接近一个采样点到另一采样点的一组交叉点。
字节mid =(max - min)/(2 * 7); 字节ab1 = max - mid; 字节ab2 =(6 * max + 1 * min)/ 7 - mid; 字节ab3 =(5 * max + 2 * min)/ 7 - mid; 字节ab4 =(4 * max + 3 * min)/ 7 - mid; 字节ab5 =(3 * max + 4 * min)/ 7 - mid; 字节ab6 =(2 * max + 5 * min)/ 7 - mid; 字节ab7 =(1 * max + 6 * min)/ 7 - mid;
然后可以测试X值大于等于每个交叉点,并且可以从8中减去这些比较的结果(0为假,1为真),并使用按位逻辑“和”7进行包装计算索引。前两个索引也通过比较(2>索引)的结果进行交换,如下面的代码所示。
字节索引[16]; for(int i = 0; i <16; i ++){ 字节a =块[i * 4]; int b1 =(a> = ab1); int b2 =(a> = ab2); int b3 =(a> = ab3); int b4 =(a> = ab4); int b5 =(a> = ab5); int b6 =(a> = ab6); int b7 =(a> = ab7); int index =(8-b1 - b2 - b3 - b4 - b5 - b6 - b7)&7; indices [i] = index ^(2> index); }
实时_Y_X DXT5压缩机的全面实现可以在附录A中找到。该实时压缩机的MMX和SSE2实现分别在附录B和C中找到。
在可用的地方,3Dc(BC5或LATC)格式导致最佳的质量正切空间法线贴图压缩。实时3Dc压缩器首先像_Y_X DXT5压缩器一样计算XY正常空间的边界框。用于近似X和Y值的两条线从最小值到该边界框的最大值。为了改善均方误差(MSE),边界框在任一端插入线上采样点之间的距离的四分之一。3Dc格式基本上存储两个具有相同编码和8个采样点的DXT5 Alpha通道。因此,在两个轴上,边界框的两端插入范围的1/32。与_Y_X DXT5压缩相同的代码也用于计算“alpha”通道索引,除了使用两次。
5. GPU上的实时压缩
也可以在GPU上执行切线空间法线贴图的实时压缩。这是可能的,因为DX10类图形硬件上可用的新功能,可以渲染整数纹理和使用按位和算术整数运算。
为了压缩法线贴图,通过在整个目标表面上渲染四边形,为4x4纹素的每个块使用片段程序。该片段程序的结果是一个压缩的DXT块,写入整数纹理的纹素。DXT5和3DC块都是128位,它等于一个RGBA纹素,每个元件有32位。因此,当将法线贴图压缩为任一格式时,将使用无符号整数RGBA纹理作为渲染目标。然后通过使用像素缓冲对象将该渲染目标的内容复制到相应的DXT纹理。该过程非常类似于在[ 24 ] 中更详细描述的用于YCoCg-DXT5压缩的过程。
3DC压缩纹理通过两个不同的扩展在OpenGL中公开:GL_EXT_texture_compression_latc [ 25 ]和GL_EXT_texture_compression_rgtc [ 26 ]。前者将X和Y分量映射到亮度和α通道,而后者将X和Y分量分别映射到红色和绿色,其余的通道设置为0。
在这里描述的实现中,使用LATC格式。这是稍微更方便,因为它允许共享用于正常重建的相同着色器代码:
N.xy = 2 * tex2D(image,texcoord).wy - 1; Nz = sqrt(饱和(1-Nx * Nx-Ny * Ny));
当使用LATC时,亮度在RGB通道中被复制,所以WY旋转将亮度和alpha分量映射到X和Y.类似地,当使用_Y_X DXT5时,WY旋转将绿色和α分量映射到X和Y.
如[使用的相同的代码24 ]以编码用于YCoCg中-DXT5压缩alpha通道,也可用于编码X和用于压缩的3Dc Y分量,和用于_Y_X DXT5压缩的X分量。如第4节所示,_Y_X DXT5压缩器也可以进行优化,以仅通过仅适配Y分量来计算DXT1块。然而,如[ 23 ]所述,α空间是一维空间,并且通过α空间的线上的点是等距的,这允许通过划分来计算每个原始α值的最接近的点。在CPU上,这需要一个相当慢的标量整数除法,因为没有可用于整数除法的MMX或SSE2指令。该分割可以被实现为具有shift的整数乘法。然而,除数不是常数,这意味着需要查找表才能获得乘数。乘法也增加了动态范围,限制了通过SIMD指令集可以利用的并行度。在CPU上,通过在最小的可能元素(字节)上使用简单的操作,而不增加动态范围,可以很好地利用最大并行度。然而,在GPU上,使用标量浮点数学,分割和/或乘法相对便宜。因此,通过仅应用比例和偏差,可以将X和Y分量映射到各个指标。用于_Y_X DXT5格式的Y分量的索引计算的CG代码如下:乘法也增加了动态范围,限制了通过SIMD指令集可以利用的并行度。在CPU上,通过在最小的可能元素(字节)上使用简单的操作,而不增加动态范围,可以很好地利用最大并行度。然而,在GPU上,使用标量浮点数学,分割和/或乘法相对便宜。因此,通过仅应用比例和偏差,可以将X和Y分量映射到各个指标。用于_Y_X DXT5格式的Y分量的索引计算的CG代码如下:乘法也增加了动态范围,限制了通过SIMD指令集可以利用的并行度。在CPU上,通过在最小的可能元素(字节)上使用简单的操作,而不增加动态范围,可以很好地利用最大并行度。然而,在GPU上,使用标量浮点数学,分割和/或乘法相对便宜。因此,通过仅应用比例和偏差,可以将X和Y分量映射到各个指标。用于_Y_X DXT5格式的Y分量的索引计算的CG代码如下:在CPU上,通过在最小的可能元素(字节)上使用简单的操作,而不增加动态范围,可以很好地利用最大并行度。然而,在GPU上,使用标量浮点数学,分割和/或乘法相对便宜。因此,通过仅应用比例和偏差,可以将X和Y分量映射到各个指标。用于_Y_X DXT5格式的Y分量的索引计算的CG代码如下:在CPU上,通过在最小的可能元素(字节)上使用简单的操作,而不增加动态范围,可以很好地利用最大并行度。然而,在GPU上,使用标量浮点数学,分割和/或乘法相对便宜。因此,通过仅应用比例和偏差,可以将X和Y分量映射到各个指标。用于_Y_X DXT5格式的Y分量的索引计算的CG代码如下:
const int GREEN_RANGE = 3; float bias = maxGreen +(maxGreen - minGreen)/(2.0 * GREEN_RANGE); 浮标= 1.0f /(maxGreen - minGreen); //计算索引 uint索引= 0; for(int i = 0; i <16; i ++) { uint index = saturate((bias-block [i] .y)* scale)* GREEN_RANGE; index | = index <<(i * 2); } uint i0 =(indices&0x55555555); uint i1 =(indices&0xAAAAAAAA)>> 1; indices =((i0 ^ i1)<< 1)| I1;
对于_Y_X DXT5格式的X分量以及3Dc格式的X和Y分量都可以这样做:
const int ALPHA_RANGE = 7; float bias = maxAlpha +(maxAlpha - minAlpha)/(2.0 * ALPHA_RANGE); 浮标= 1.0f /(maxAlpha - minAlpha); uint2 indices = 0; for(int i = 0; i <6; i ++) { uint index = saturate((bias-block [i] .x)* scale)* ALPHA_RANGE; indices.x | = index <<(3 * i); } for(int i = 6; i <16; i ++) { uint index = saturate((bias-block [i] .x)* scale)* ALPHA_RANGE; indices.y | = index <<(3 * i - 18); } uint2 i0 =(indices >> 0)&0x09249249; uint2 i1 =(indices >> 1)&0x09249249; uint2 i2 =(indices >> 2)&0x09249249; i2 ^ = i0&i1; i1 ^ = i0; i0 ^ =(i1 | i2); indices.x =(i2.x << 2)| (i1.x << 1)| i0.x; indices.y =(((i2.y << 2)|(i1.y << 1)| i0.y)<< 2)| (indices.x >> 16); indices.x << = 16;
附录D中可以找到实时_Y_X DXT5(DXT5nm)法线贴图压缩器和实时3Dc(BC5或LATC)法线贴图压缩器的完整Cg 2.0实现。
对CPU与GPU的压缩
如前面章节所示,可以在CPU和GPU上实现高性能法线贴图压缩。压缩是否最好在CPU或GPU上实现依赖于应用程序。
CPU上的实时压缩对于在CPU上动态创建的法线图很有用。对CPU进行压缩对于以不能用于渲染的格式从磁盘流式传输的法线图进行转码也特别有用。例如,法线图或高度图可以以JPEG格式存储在磁盘上,因此不能直接用于呈现。JPEG解压缩算法的一些部分目前可以在GPU上高效地实现。存储器可以保存在图形卡上,通过解压缩原始数据并将其重新压缩为DXT格式,可以提高渲染性能。在CPU上重新压缩纹理数据的优点是上传到图形卡的数据量很小。此外,当在CPU上执行压缩时,完整的GPU可以用于渲染工作,因为它不需要执行任何压缩。对于当今CPU上越来越多的内核的确定趋势,通常可以轻松地使用可用于纹理压缩的免费内核。
因为对于代码转换,实时压缩可能不太有用,因为用于上传未压缩纹理数据的带宽需求增加,并且因为GPU可能已经被昂贵的渲染工作所约束了。然而,GPU上的实时压缩对压缩的渲染目标非常有用。GPU上的压缩可以用于在渲染到纹理时节省内存。此外,如果来自渲染目标的数据用于进一步渲染,则这样的压缩渲染目标可以提高性能。渲染目标被压缩一次,而渲染过程中可能会多次访问生成的数据。压缩数据导致光栅化期间带宽要求降低,因此可以显着提高性能。
7.结果
7.1对象空间
对象空间法线贴图压缩技术已经用下面所示的对象空间法线图进行了测试。
| 对象空间法向图 | |||
 |
 |
 |
|
| 商场 | 触手 | 胸部 | 面对 |
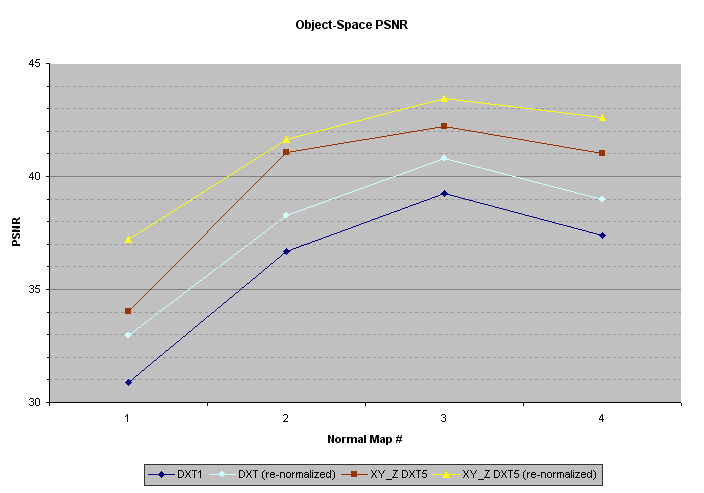
在未加权的X,Y和Z值上计算了峰值信噪比(PSNR),存储为8位无符号整数。
| PSNR | ||||||||
| 图片 | XYZ DXT1 |
重新归一化 XYZ DXT1 |
XY_Z DXT5 |
重新归一化 XY_Z DXT5 |
||||
|---|---|---|---|---|---|---|---|---|
| 01_arcade | 30.90 | 32.95 | 34.02 | 37.23 | ||||
| 02_tentacle | 36.68 | 38.29 | 41.04 | 41.62 | ||||
| 03_chest | 39.24 | 40.79 | 42.22 | 43.47 | ||||
| 04_face | 37.38 | 38.99 | 41.03 | 42.60 | ||||
7.2切线空间
已经用下面所示的切线空间法线图测试了切线空间法线贴图压缩技术。
| 切线空间正常图 | |||
 |
 |
 |
 |
| dot1 | dot2 | dot3 | dot4 |
 |
 |
 |
 |
| 块状 | voronoi | 乌龟 | 8. normalmap |
 |
 |
 |
 |
| 金属 | 皮肤 | 十九岁 | 桶 |
 |
 |
 |
|
| 街机 | 触手 | 胸部 | 面对 |
在未加权的X,Y和Z值上计算了峰值信噪比(PSNR),存储为8位无符号整数。
| PSNR | ||||||||||||
| 图片 | XY_ DXT1 |
重新归一化 XYZ DXT1 |
_YZX DXT5 |
重新归一化 _YZX DXT5 |
_Y_X DXT5 |
的3Dc |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01_dot1 | 27.61 | 29.51 | 32.00 | 35.16 | 35.07 | 40.15 | ||||||
| 02_dot2 | 25.39 | 26.45 | 29.55 | 32.92 | 32.68 | 36.70 | ||||||
| 03_dot3 | 21.88 | 23.05 | 27.34 | 30.77 | 30.02 | 34.13 | ||||||
| 04_dot4 | 23.18 | 24.46 | 29.16 | 32.81 | 31.38 | 35.80 | ||||||
| 05_lumpy | 30.54 | 31.13 | 34.70 | 37.15 | 37.73 | 41.92 | ||||||
| 06_voronoi | 37.53 | 38.16 | 41.72 | 42.16 | 43.93 | 48.23 | ||||||
| 07_turtle | 36.12 | 37.06 | 38.74 | 39.93 | 41.22 | 45.76 | ||||||
| 08_normalmap | 35.57 | 36.36 | 37.78 | 38.95 | 40.00 | 44.49 | ||||||
| 09_metal | 41.65 | 41.99 | 46.37 | 46.55 | 49.03 | 54.10 | ||||||
| 10_skin | 28.95 | 29.48 | 34.68 | 36.20 | 36.83 | 41.37 | ||||||
| 11_onetile | 29.08 | 29.82 | 34.17 | 35.98 | 36.76 | 41.14 | ||||||
| 12_barrel | 29.93 | 31.67 | 33.15 | 36.79 | 37.03 | 40.20 | ||||||
| 13_arcade | 32.31 | 33.63 | 36.86 | 39.24 | 39.81 | 44.61 | ||||||
| 14_tentacle | 39.03 | 40.47 | 40.30 | 41.39 | 43.23 | 47.82 | ||||||
| 15_chest | 38.92 | 41.03 | 41.64 | 42.29 | 42.87 | 46.52 | ||||||
| 16_face | 38.27 | 39.58 | 41.59 | 42.55 | 43.71 | 48.61 | ||||||
下图使用3Dc格式显示正交和立体投影之间的质量差异。立体投影导致更一致的结果,但对于大多数正常地图,质量明显较低。
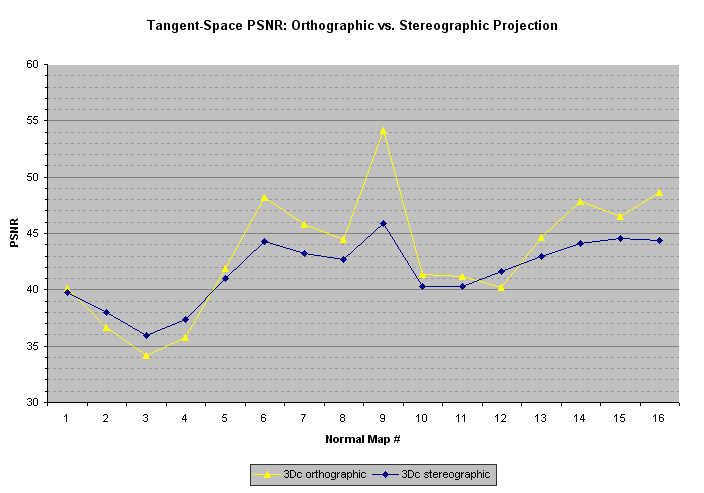
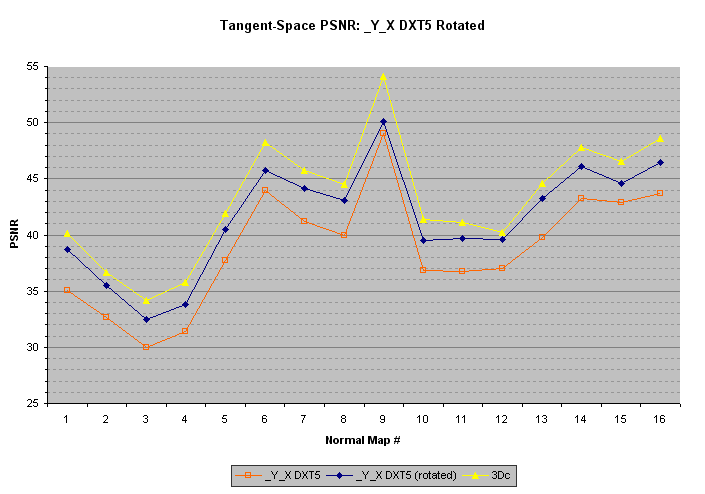
以下图表仅仅是理论上的兴趣,因为它显示了在4x4块中旋转法线的质量改进,并将旋转存储在_Y_X DXT5格式的一个未使用的通道中。该图表显示仅用于点采样的法线贴图的质量改进,因为过滤会导致4x4块与不同旋转之间纹素样本的显着伪像。
7.3实时切线空间
已经使用上面所示的相同的切线空间法线图测试了实时切线空间法线贴图压缩机。在未加权的X,Y和Z值上计算了峰值信噪比(PSNR),存储为8位无符号整数。
| PSNR | ||||||||
| 图片 | 离线 _Y_X DXT5 |
实时 _Y_X DXT5 |
离线 3Dc |
实时 3Dc |
||||
|---|---|---|---|---|---|---|---|---|
| 01_dot1 | 35.07 | 33.36 | 40.15 | 37.99 | ||||
| 02_dot2 | 32.68 | 31.67 | 36.70 | 35.67 | ||||
| 03_dot3 | 30.02 | 29.03 | 34.13 | 33.22 | ||||
| 04_dot4 | 31.38 | 30.49 | 35.80 | 34.89 | ||||
| 05_lumpy | 37.73 | 36.63 | 41.92 | 40.63 | ||||
| 06_voronoi | 43.93 | 42.99 | 48.23 | 46.99 | ||||
| 07_turtle | 41.22 | 40.30 | 45.76 | 44.50 | ||||
| 08_normalmap | 40.00 | 38.99 | 44.49 | 43.26 | ||||
| 09_metal | 49.03 | 47.60 | 54.10 | 52.45 | ||||
| 10_skin | 36.83 | 35.69 | 41.37 | 40.20 | ||||
| 11_onetile | 36.76 | 35.67 | 41.14 | 39.92 | ||||
| 12_barrel | 37.03 | 35.51 | 40.20 | 39.11 | ||||
| 13_arcade | 39.81 | 38.05 | 44.61 | 42.18 | ||||
| 14_tentacle | 43.23 | 41.90 | 47.82 | 46.31 | ||||
| 15_chest | 42.87 | 41.95 | 46.52 | 45.38 | ||||
| 16_face | 43.71 | 42.85 | 48.61 | 47.53 | ||||
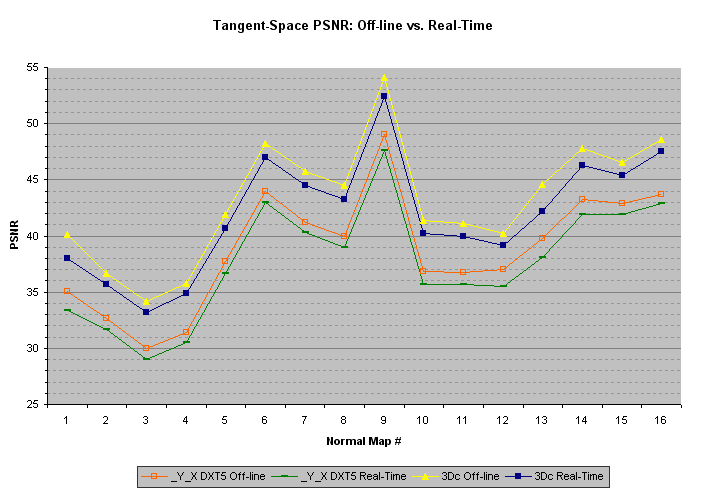
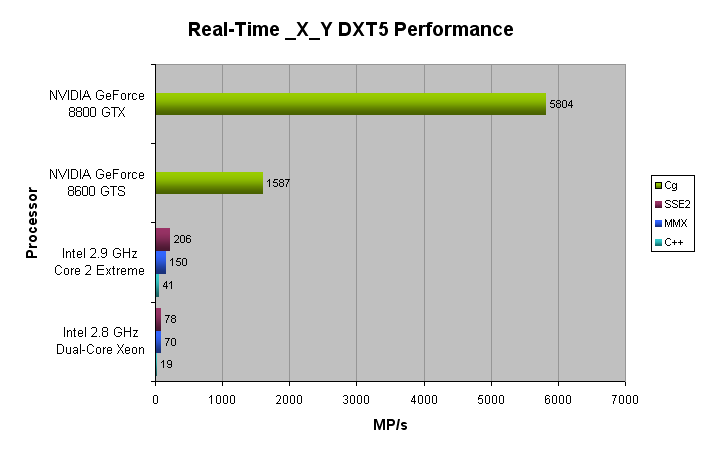
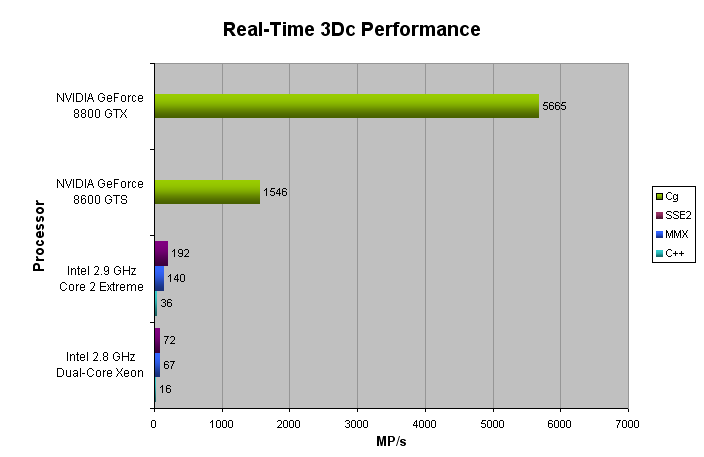
采用英特尔®2.8 GHz双核至强®(“Paxville”90nm NetBurst微架构)和英特尔®2.9 GHz Core™2 Extreme(“Conroe”65nm Core 2微架构)测试了SIMD优化实时压缩器的性能)。这些处理器中只有一个核心用于压缩。由于纹理压缩是基于块的,所以压缩算法可以容易地使用多个线程来利用这些处理器的所有核心。当使用多个内核时,可预期的线速度随着可用内核的数量而增加。在NVIDIA GeForce 8600 GTS和NVIDIA GeForce 8800 GTX上,还对Cg 2.0实现的性能进行了测试。
下图显示了每秒可以压缩到_Y_X DXT5格式的多个像素数(更高的MP / s =更好)。
下图显示了每秒可以压缩到3Dc格式的更大像素数(更高的MP / s =更好)。
8.结论
现有的颜色纹理压缩格式也可以用于存储法线贴图,但结果各不相同。最新的图形硬件还实现了专门为普通地图压缩设计的格式。虽然这些格式的解压缩在渲染过程中在硬件中实时发生,但对这些格式的压缩可能需要相当长的时间。现有压缩机设计用于高质量离线压缩,而不是实时压缩。然而,以一些质量为代价,普通地图也可以在CPU和GPU上实时压缩,这对于从不同格式转码法线贴图和动态生成的法线贴图进行压缩是非常有用的。
参考文献
| 1。 | 皱纹曲面的模拟。 James F. Blinn In Proceedings of SIGGRAPH,vol。12,#3, pp。286-292,1978在线可用:http://portal.acm.org/citation.cfm?id=507101 |
| 2。 | 高效的凸点映射硬件。 Mark Peercy,John Airey,Brian Cabral Computer Graphics,vol。31, pp。303-306,1997 Available online:http://citeseer.ist.psu.edu/peercy97efficient.html |
| 3。 | S3纹理压缩 Pat Brown NVIDIA Corporation,2001年11月 在线提供:http://oss.sgi.com/projects/ogl-sample/registry/EXT/texture_compression_s3tc.txt |
| 4。 | 压缩纹理资源(Direct3D 9) Microsoft开发人员网络 MSDN,2007年11月 在线可用:http://msdn2.microsoft.com/en-us/library/bb204843.aspx |
| 5。 | 块压缩(Direct3D 10) Microsoft开发人员网络 MSDN,2007年11月 在线可用:http://msdn2.microsoft.com/en-us/library/bb694531.aspx |
| 6。 | 使用块截断编码的图像编码 E.J. Delp,OR Mitchell IEEE Transactions on Communications,vol。27(9),pp。1335-1342,1979年 9月在线可用:http://scholarsmine.umr.edu/post_prints/01094560_09007dcc8030cc78.html |
| 7。 | Bump地图压缩 Simon Green NVIDIA技术报告,2001年10月 在线提供:http://developer.nvidia.com/object/bump_map_compression.html |
| 8。 | 正常地图压缩 ATI Technologies Inc ATI,2003年8月 在线提供:http://www.ati.com/developer/NormalMapCompression.pdf |
| 9。 | 正常地图压缩 Jakub Klarowicz 着色器X2:使用DirectX 9的着色器编程提示和技巧 |
| 10。 | 3DC 白皮书 ATI Technologies Inc ATI,2004年4月 在线提供:http://ati.de/products/radeonx800/3DcWhitePaper.pdf |
| 11。 | 高品质正常地图压缩 Jacob Munkberg,Tomas Akenine-Möller,JacobStrömGraphics Hardware 2006 在线可用:http://graphics.cs.lth.se/research/papers/normals2006/ |
| 12。 | 紧帧正常地图压缩 Jacob Munkberg,Ola Olsson,JacobStröm,Tomas Akenine-MöllerGraphics Hardware 2007 在线可用:http://graphics.cs.lth.se/research/papers/2007/tightframe/ |
| 13。 | 基于矢量量化的快速有效的正态图压缩 T. Yamasaki, K.Aizawa In Proceedings of ICASSP(2006),vol。2, pp。2-12在线可用:http://www.ee.columbia.edu/~dpwe/LabROSA/proceeds/icassp/2006/pdfs/0200009.pdf |
| 14。 | 混合自适应法线贴图压缩算法 B. Yang, Z.Pan In International Conference on Artificial Reality and Telexistence(2006),IEEE Computer Society, pp。349-354 Available online:http://doi.ieeecomputersociety.org/10.1109 /ICAT.2006.11 |
| 15。 | 基于统一条件的正常地图压缩的数学误差分析 Toshihiko Yamasaki,Kazuya Hayase,Kiyoharu Aizawa IEEE International Conference on Image Processing,vol。2,pp。253-6,2005年9月 在线提供:http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=1530039 |
| 16。 | 压缩正常图和渲染3D图像之间的数学PSNR预测模型 Toshihiko Yamasaki,Kazuya Hayase,Kiyoharu Aizawa Pacific Rim多媒体会议(PCM2005)LNCS 3768,第584-594页,韩国济州岛,2005年11月13-16日 可用在线:http://www.springerlink.com/content/f3707080w8553g3l/ |
| 17。 | 实时渲染具有不连续性的正常地图 Evgueni Parilov,Ilya Rosenberg,Denis Zorin CIMS技术报告,TR2005-872,2005年8月 可在线获取:http://csdocs.cs.nyu.edu/Dienst/UI/2.0/Describe/ ncstrl.nyu_cs%2FTR2005-872t |
| 18。 | Mipmapping法线贴图 M. Toksvig 图形工具杂志10,3,65-71 。2005 在线可用:http://developer.nvidia.com/object/mipmapping_normal_maps.html |
| 19。 | 频域正态图过滤 Charles Han,Bo Sun,Ravi Ramamoorthi,Eitan Grinspun SIGGRAPH 2007 在线提供:http://www.cs.columbia.edu/cg/normalmap/normalmap.pdf |
| 20。 | ATI Compressonator Library Seth Sowerby,Daniel Killebrew ATI Technologies Inc,The Compressonator版本1.27.1066,2006年3月 在线提供:http://www.ati.com/developer/compressonator.html |
| 21。 | NVIDIA DDS工具 NVIDIA NVIDIA DDS工具,2006年4月 在线提供:http://developer.nvidia.com/object/nv_texture_tools.html |
| 22。 | NVIDIA纹理工具 NVIDIA NVIDIA纹理工具,2007年9月 在线提供:http://developer.nvidia.com/object/texture_tools.html |
| 23。 | 实时DXT压缩 J.MP van Waveren 英特尔软件网络,2006年10月 在线提供:http://www.intel.com/cd/ids/developer/asmo-na/eng/324337.htm |
| 24。 | 实时YCoCg-DXT压缩 J.MP van Waveren,IgnacioCastañoNVIDIA, 2007年10月 在线提供:http://news.developer.nvidia.com/2007/10/real-time-ycocg.html |
| 25。 | GL_EXT_texture_compression_latc 可在线获得:http://www.opengl.org/registry/specs/EXT/texture_compression_latc.txt |
| 26。 | GL_EXT_texture_compression_rgtc 可在线获得:http://www.opengl.org/registry/specs/EXT/texture_compression_rgtc.txt |