什么?导致我leetcode超时的不是算法是并发?
什么?导致我leetcode超时的不是算法是并发?
(我写这篇文章真的只是为了打发时间,内容严重逻辑不清,既 不易懂 也 不深入,我不认为这篇文章具有阅读价值,所以看到这里就可以把它关掉了!)
本文由 CDFMLR 原创,收录于个人主页 https://clownote.github.io,并同时发布到 CSDN。本人不保证 CSDN 排版正确,敬请访问 clownote 以获得良好的阅读体验。
问题的提出
Emmmm,我很久很久(快半年了吧)没有刷过题了,昨天晚上无聊就打开了 leetcode 随便写了一道题:
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad" 输出: "bab" 注意: "aba" 也是一个有效答案。示例 2:
输入: "cbbd" 输出: "bb"来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-palindromic-substring
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
emmmm,首先的想法是动规,我一般都不爱用动规,空间消耗大。做了那么久开发再回来看算法,就觉得,时间稍微慢点可以等,内存一满就彻底炸了。
然后,我想到了最长公共子串,把这个字符串和它的反串求一个最长公共子串就是最长回文子串了。。。最长公共子串又是动规。
不想用动规,又不齿于暴力,那就硬写吧。
我的思路是遍历一次字符串,尝试以每个字符为回文中心,尽量去往两边“拓展”,得到以每个字符为中心的最长回文串,取这些拓展得的回文串中最长的输出。
我这个思路时间应该也许大概是 O ( n 2 ) O(n^2) O(n2) 吧(颓废到连这个都不会算了);空间可能比较好,都是调整指针的值, O ( 1 ) O(1) O(1) 吧。
然后,我准备开始写代码,突然意识到回文有两!种!情!况!
- 第一种,形如
aba,中心是一个字符b; - 第二种,形如
abba,中心在两个字符b之间,或者也可以看作中心是两个字符bb
所以,遍历字符串时,每个迭代要拓展两次,一次是以当前字符为中心(aba 型),一次是以当前字符+后一个字符为中心(abba 型)。
Golang 实现如下:
func longestPalindrome(s string) string {
if s == "" {
return s
}
b := []byte(s)
l, r := 0, 0
for i := 0; i < len(b); i++ {
laba := ext(b, i, i)
labba := ext(b, i, i+1)
var m int
if laba > labba {
m = laba
} else {
m = labba
}
if m > r-l+1 {
l = i - (m-1)/2
r = i + m/2
}
}
return string(b[l : r+1])
}
func ext(b []byte, l, r int) int {
for l >= 0 && r < len(b) && b[l] == b[r] {
l--
r++
}
return r - l - 1 // r - l + 1 - 2
}
提交跑一下,4ms(击败91.02%),2.3MB(击败49.75%)。
emmm,我不理解为什么空间占用这么高,传参到时候 Golang 里的 []byte 应该是传了引用呀(可以理解成也就是传指针),其他的基本都是 int 了,我暂时想不到好办法继续在空间上做优化。
所以我考虑了一下能不能在时间上更进一步。考虑这一段代码:
laba := ext(b, i, i)
labba := ext(b, i, i+1)
就是分别计算 aba 型和 abba 型的回文拓展。先算完一个,再算另一个,我想这里会比较耗时。如果让他们同时算会发生什么?
试试看,主要的改动就是开两个 goroutine 去执行这两个函数:
func ext(b []byte, l, r int, cl chan int) {
for l >= 0 && r < len(b) && b[l] == b[r] {
l--;
r++;
}
cl <- r - l -1
}
func longestPalindrome(s string) string {
if s == "" {
return s
}
b := []byte(s )
l, r := 0, 0
for i := 0; i < len(b); i++ {
cl1 := make(chan int)
cl2 := make(chan int)
go ext(b, i, i, cl1)
go ext(b, i, i+1, cl2)
laba := <- cl1
labba := <- cl2
var m int
if laba > labba {
m = laba
} else {
m = labba
}
if m > r - l + 1 {
l = i - (m - 1) / 2
r = i + m / 2
}
}
return string(b[l: r + 1])
}
提交,,40ms,6.2MB,发生了什么?
我以为问题出在这里:
laba := <- cl1
labba := <- cl2
这里是先阻塞在 laba 这里等 cl1 传出来,然后再等 cl2 出来。万一 cl2 先算完出来了,还是要阻塞到 cl1 出来,可能这里耗时了。所以再改一下 longestPalindrome的策略,用一个 for-select:
select 不能 fallthrough,所以为了及时 break,减少一次阻塞把每个 case 里都写了退出判断,恶心了一点。
func longestPalindrome(s string) string {
if s == "" {
return s
}
b := []byte(s )
l, r := 0, 0
for i := 0; i < len(b); i++ {
// laba := ext(b, i, i)
// labba := ext(b, i, i+1)
cl1 := make(chan int)
cl2 := make(chan int)
go ext(b, i, i, cl1)
go ext(b, i, i+1, cl2)
var laba int
var labba int
cnt := 0
LOOP: for {
select {
case laba = <- cl1:
cnt++
if (cnt >= 2) {
break LOOP
}
case labba = <- cl2:
cnt++
if (cnt >= 2) {
break LOOP
}
default:
if (cnt >= 2) {
break LOOP
}
}
}
var m int
if laba > labba {
m = laba
} else {
m = labba
}
if m > r - l + 1 {
l = i - (m - 1) / 2
r = i + m / 2
}
}
return string(b[l: r + 1])
}
再提交,应该会快一点吧,结果是——超。出。时。间。限。制。而且超的还很多,只过了22个测试用例。
我哭了,并发了不是应该更快吗?是 leetcode 的锅吧。
还是在本地测试一下吧:
func main() {
s := []string{"babad", "cbbd", "", "a", "aa", "aaa", "aaaa"}
for i := 0; i < 10000; i++ {
longestPalindrome(s[i%7])
}
}
随便搞几个例子循环着跑10000次,$ time go run 看一下。
第一个版本(不并发):
real 0m0.246s
user 0m0.216s
sys 0m0.137s
最后一个版本(for-select):
real 0m1.005s
user 0m1.036s
sys 0m0.518s
\拍桌 还真的是并发导致了慢啊!
但是,为什么?
问题的分析
为了研究这个问题,我们把刚才三个版本的代码都简化一下:
v1,不并发:
// v1.go
package main
import (
"math/rand"
"time"
)
func somethingCost() bool {
// time.Sleep(time.Duration(rand.Intn(10)) * time.Millisecond)
time.Sleep(1 * time.Millisecond)
return true
}
func main() {
rand.Seed(time.Now().UnixNano())
for i := 0; i < 100; i++ {
foo := somethingCost()
bar := somethingCost()
if foo == bar {
continue
}
}
}
v2,并发,阻塞在第一个 channel:
// v2.go
package main
import (
"math/rand"
"time"
)
func somethingCost(ch chan bool) {
// time.Sleep(time.Duration(rand.Intn(10)) * time.Millisecond)
time.Sleep(1 * time.Millisecond)
ch <- true
}
func main() {
rand.Seed(time.Now().UnixNano())
ch1 := make(chan bool)
ch2 := make(chan bool)
for i := 0; i < 100; i++ {
go somethingCost(ch1)
go somethingCost(ch2)
foo := <-ch1
bar := <-ch2
if foo == bar {
continue
}
}
}
v3,运用 select:
// v3.go
package main
import (
"math/rand"
"time"
)
func somethingCost(ch chan bool) {
// time.Sleep(time.Duration(rand.Intn(10)) * time.Millisecond)
time.Sleep(1 * time.Millisecond)
ch <- true
}
func main() {
rand.Seed(time.Now().UnixNano())
ch1 := make(chan bool)
ch2 := make(chan bool)
for i := 0; i < 100; i++ {
cnt := 0
go somethingCost(ch1)
go somethingCost(ch2)
LOOP:
for {
select {
case <-ch1:
cnt++
case <-ch2:
cnt++
default:
if cnt >= 2 {
break LOOP
}
}
}
}
}
我们首先在 somethingCost 里睡眠了相同的时间,来模拟执行一个慢速任务,运行代码得到类似如下的结果:
$ time go run v1.go
real 0m0.553s
user 0m0.204s
sys 0m0.159s
$ time go run v2.go
real 0m0.379s
user 0m0.182s
sys 0m0.135s
$ time go run v3.go
real 0m0.362s
user 0m0.314s
sys 0m0.138s
【补充】real时间、user时间和sys时间。
- real时间是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
- user时间是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
- sys时间是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。
参考: Linux命令大全. time命令[OL].https://man.linuxde.net/time, 2020
用物理实验的方法,多次重复实验,得到如下结果:
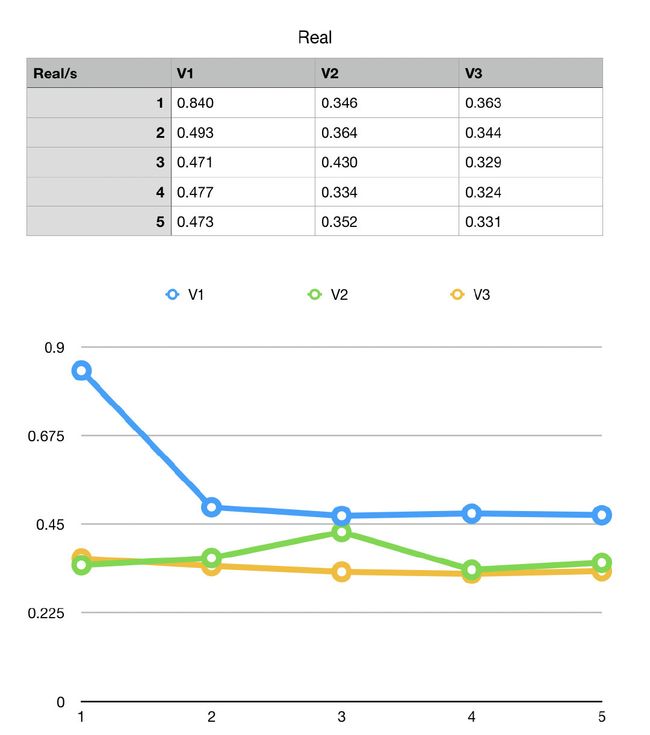
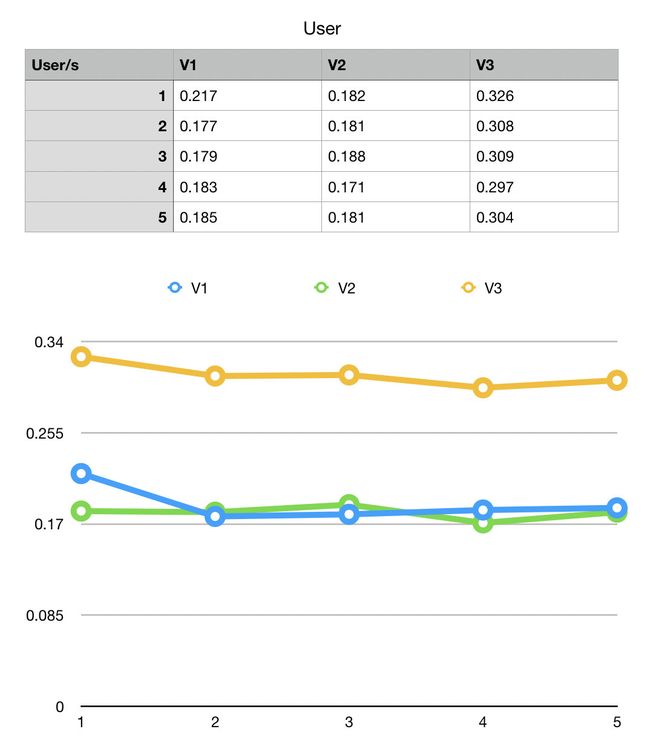
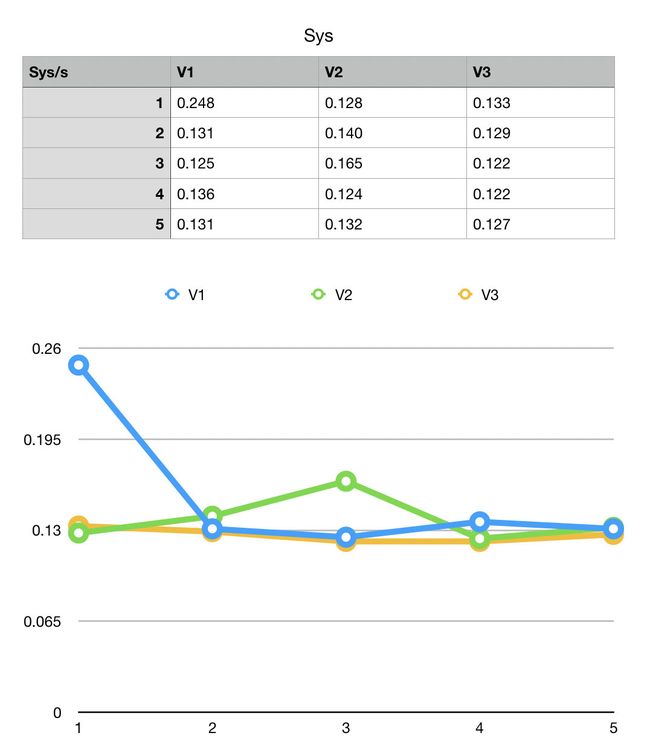
【注】实验环境:
Computer: MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)
CPU: 2.3 GHz Intel Core i5
RAM: 8 GB 2133 MHz LPDDR3
OS: macOS Mojave 10.14.6
Golang: go version go1.12 darwin/amd64
实验次数少,数据不太好,不管了,我懒得搞大规模的实验(其实我只是边研究边写这篇文章打发时间)。
从实验的结果来看,有两点比较肯定:
- Real 时间上,v3 略优于 v2 优于 v1
- User 时间上,v1 约等于 v2 优于 v3
由此,可以推知:
- 在现实环境(正常的多核计算机)使用中,如 v3 版本的程序,使用
goroutine-for-select的方案可以运行得比较快(real time,与不并发相比),但在等待返回的 channel 不多时与不使用for-select区别不大。 - 在 goroutine 和 channel 比较少的时候使用
for-select的策略,进程所花费的时间(user time)会明显加大。
注意,是在 goroutine 和 channel 比较少的时候 v2 的 user time 优于 v3。当我们增多 goroutine,比如开到 1000 个,结果就不一样了(我不想用 v1 依次执行1000次函数,结果可想而知,没有可比性了):
$ time go run v2.go
real 0m5.824s
user 0m8.036s
sys 0m3.967s
$ time go run v3.go
real 0m1.919s
user 0m3.006s
sys 0m0.244s
所以,在慢速任务比较多的时候,使用类似于 v3 的 for-select 会大幅度提高效率。
我们再来看一下如果任务速度比较快,例如我们直接把 Sleep 注释掉,然后开最外层的循环次加到100次:
$ time go run v1.go
real 0m0.302s
user 0m0.168s
sys 0m0.127s
$ time go run v2.go
real 0m0.373s
user 0m0.198s
sys 0m0.149s
$ time go run v3.go
real 0m0.353s
user 0m0.301s
sys 0m0.142s
这种情况下 v2、 v3 就显得没有优势了,这时多线程上下午切换等等的开支会造成比较大的额外开支,导致整体运行效率低下。这也就是我们提交到 leetcode 的代码超时的问题所在。
(啊,我不想写了,打中文好麻烦,开模mo糊fu拼音都不能满足我的需求。反正我已经知道我想要的答案了,而且还在研究过程中得到了更多的收获,还有好多东西我没写,但懒得写了,想知道的话自己去研究啊,方法我给你了,控制个变量总会了吧!我再写句烂总结就去睡觉了,再见!)
问题的总结
(不想写!)
这个故事告诉我们,不要在需要并发的任务少,通信不复杂的情况下(比如刷 leetcode 的算法题)尝试使用处理高并发的手段,异步的方法还是用来处理比较慢的任务比较好。
(扯不下去了,就这样吧,这篇文章明天发。)
某个头疼的夜 (澄清:头疼 ≠ \neq = 发烧;我没发烧,没得肺炎,只是很烦!)