自然语言处理面试基础
专栏亮点
内容新:本课程涵盖 RNN,LSTM,GRU,word2vec,CNN 这些基础,还包括多层,双向等拓展,有 Seq2seq 和 Attention,再到最近流行的 Transformer,ELMo,BERT,层层递进掌握经典模型。
实战多:包括 14 个项目的代码及详细的讲解,从命名实体识别,词性标注,到情感分析,聊天机器人,机器翻译,再到图片文字摘要,动手实现有趣的智能应用。
讲的细:每篇文章用黄金圈 why,how,what 的结构详细讲解模型原理,对面试中常考问题给出解答和理论依据,深刻理解经典模型解决问题的思想。
为什么要学习深度学习自然语言处理
让我们来想象这样一个画面:
当清晨被闹钟叫醒,睁开朦胧的双眼,摸起手机说“siri,帮我设一个五分钟的闹钟”,随之又进入了梦乡。五分钟后很快就到了,总算精神了一些,看看今天每小时的天气预报如何,起床准备开始一天的工作。早餐时间,一边吃着美味的早餐一边打开了邮箱,看到又多了几封垃圾邮件。一切准备就绪,出发去上班,在路上,兴致勃勃地看一篇今天特别感兴趣的外语文章,发现有个单词不认识,于是打开了翻译软件。忽然想到有个包裹怎么还没到,打开购物软件,和他们的聊天机器人客服聊了起来。
上面这些事情可能就发生在每日日常的一个小时内,但却用到了语音识别,时间序列预测,垃圾邮件识别,机器翻译,聊天机器人等技术。
你是否好奇是什么技术实现了这些便利的功能?是否也想自己也可以 DIY 一些人工智能应用来解决自己平日遇到的问题呢?
那么这门课程就可以为你的奇思妙想奠定基础,这门课不仅仅是实战,还有深入的模型理论讲解,尤其是面试中常遇问题的详细解答。
放眼宏观环境,人工智能已经被列入国家战略目标,2020要让人工智能和应用达到世界先进水平,2025年使其成为引导经济转型的主要动力,而自然语言处理是人工智能入口之争的主要技术之一,它将会是未来人机交互的主要方式,很多大公司或者新创公司都下大力度进行这方面的研究,无论是出于兴趣,还是早在职业规划目标之内,学习一下自然语言处理的经典模型原理和实践,未来可以找到更多机会参与到人工智能创新的浪潮中来。
之前有些朋友会向我咨询为什么自学了名校的课程认真做了笔记,却还是会在面试时回答不出来问题,因为其实很多优秀的课程和书籍侧重点会不同,理论上可能只是讲个思想,来龙去脉并不会讲的很深,实战中可能只是给出基础的代码,为什么要进行哪一步也没有讲的很细,关于面试的书也只是给出答案,到底为什么要这么回答也没有给出详细的解释,而在面试时面试官们通常会把最基础的东西问得很透彻,比如手推反向传播,手推 LSTM,改进 SkipGram 模型等等,所以单单学完一门课程看完一本书可能并不会真正地掌握知识。
在这门课程中会帮助大家解决这样的问题,我们会以能够回答出面试题为基准,并且是建立在透彻理解模型原理的基础上,而不是死记硬背答案,还会有数学公式推导作为理论支撑,做到真的理解模型,这样当面试官们变换问题时,或者要求提出改进方案或者拓展时,都能够根据自己的理解给出解答。
除了理论还有实战,本课程设计的实战项目有热门应用,如情感分析,聊天机器人等都是现在很多公司所需要的;也有 NER,POS 等基础应用,是自然语言处理项目中必备的。面试官们会对项目的每个环节都问的比较细,数据清洗,预处理,特征,建模,模型评估等等,所以我们的项目解释也很全,包括数据在模型里是如何变化的,每一步代码干了什么发生了什么都会心里有数。
当然在这一门课程中肯定无法涵盖自然语言处理的各个角落,我们会先主要覆盖 NLP 工程师面试所需的深度学习基础部分,将基础的经典的模型理论牢牢掌握,会针对真实的面试题给出详细的讲解,例如:
- RNN 为什么会发生梯度消失?如何改进?
- LSTM 的模型结构是什么?
- 为什么说 LSTM 具有长期记忆功能?
- LSTM 为什么能抑制梯度衰减?
- 什么是 Word2Vec?如何训练?
- Word2vec,CBOW 和 Skip-gram 的区别是什么?
- 什么是 seq2seq 模型?有哪些优点?
- 什么是注意力机制?
- 为什么要使用注意力机制,有什么优点?
- CNN 的原理是什么?有哪些优缺点?
- BERT 的模型结构是什么?如何应用?...
每个模型的公式是什么,怎么训练模型,怎么优化模型都会提到,在实战中遇到的特别技术概念也会给出详细的讲解。
专栏思路和内容大纲
第 1 部分:深度学习基础知识
因为本课程是关于深度学习在自然语言处理中的应用,所以课程开始部分我们会概括性地介绍什么是深度学习项目的一般流程和所需基本概念,深度学习在自然语言处理领域主要有哪些热门应用,还会介绍本课程项目所需的 Keras 和 TensorFlow 2.0 基础,有了这样一个全局观,在后面学习具体模型和项目的时候会更有掌控性。
第 2 部分:循环神经网络基础
这一部分会非常详细地介绍 RNN 和 LSTM 的原理,它们是深度自然语言处理的基础模型,掌握它们对学习并理解后面更复杂的模型结构有很好的帮助,而且课程中会有面试常考问题的详细解答和公式推导,从数学的层次做到真正理解经典模型的特性。
第 3 部分:词嵌入
在这里我们会介绍 Word2vec 的方法,包括 CBOW,Skip-gram,GloVe 的理论和应用。词嵌入是自然语言处理任务中很重要的一步,它可以让模型更好地学习到单词之间的关系和单词地含义,使模型表现地更好。
第 4 部分:循环神经网络的改进
这一部分我们将学习如何改进基础的 RNN 和 LSTM,通过前面对基础理论的深入了解,我们可以知道它们具有哪些不足,于是通过改善门控单元,搜索结果,增加方向等方法来使模型进一步得到改善。
第 5 部分:Seq2seq 和 Attention
这一部分模型的结构进一步升级,Seq2seq 是一个 Encoder–Decoder 结构的网络,它最重要的地方在于输入序列和输出序列的长度是可变的,不过因为不管输入的长度多长都会被它压缩成一个几百维的中间向量,就会造成任务质量的下降,而 Attention 又进一步解决了 Seq2seq 存在的问题,有了这些改进使得模型在情感分析,聊天机器人,机器翻译等任务中的性能提升。
第 6 部分:卷积神经网络的应用
卷积神经网络被大家熟知的是在图像领域的重要模型,这一部分就会介绍它其实也可以用于自然语言处理的任务中,通过学习这种“跨界”的模型,不仅可以更了解到任务和模型的本质,还有助于开拓解决问题的思路。
第 7 部分:Transformer,ELMo,BERT
BERT 是2018年10月11日由 Google AI Language 发布的模型,当时在问答,推理等 11 个 自然语言处理任务上的表现都刷新了记录,目前为止有很多优秀的模型都是在其基础上进行改进,所以这部分将介绍 Transformer,ELMo,BERT 这一系列的原理和应用。

作者介绍
杨熹,数学系硕士,目前从事数据科学方面的工作。曾任 Intel 成本分析师,日本 TRIAL 数据分析师,美国 Trilogy 数据科学培训师,参与销量预测,成本分析,推荐系统等多个项目,擅长机器学习,深度学习,自然语言处理。

你将收获什么
面试必备知识点
在自然语言处理相关职位的面试中,面试官会对模型的结构,原理,数学推导,优缺点,改进方法等进行细致地提问,很多外文原版书籍或者名校课程中都不会做特别详细地解答,最后看了很多书学了很多课程,可能到面试的时候还是答不出来问题,在本课程中就会对这些知识点进行深入地讲解,让大家能够真正理解每个模型,知其然知其所以然。
本课程将用通俗易懂的方式讲解模型的原理,用图解的方式画出模型中数据的走向,对关键步骤的计算,例如前向计算,反向传播,会有详细的手写推导。以及一些核心问题的探究,例如为什么循环神经网络具有记忆功能,LSTM 为什么可以缓解梯度消失,为什么用双向 LSTM,Encoder–Decoder 的结构是什么样的,为什么需要 Attention 机制等。
动手实践,编写有趣的项目
无论是出于兴趣还是想要找到高薪的工作,最后都要落实到有能力解决问题。所以本课程在每个模型的原理之后,都有相应的项目代码,而且有非常详细的代码讲解,理论与实践结合,真正把模型用起来,除了用序列模型处理其他模型能做到的分类和预测的任务,还可以构建一些好玩的,例如自动生成某个大师风格的文章,根据电影评论分析一下观众对它的评价,做个简易的聊天机器人,再或者平时经常用的翻译软件,自己也可以学习到机器翻译模型的构建方法。
熟练地使用 TensorFlow/Keras
本课程在每个模型后都配有应用代码,都是用 TensorFlow 或 Keras 来实现,这两个框架也是很多公司在招聘时优先考虑的技术,通过课程中一些小项目的练习,可以进行强化训练,并且由于都是序列模型,还可以进行横向比较,了解实现不同项目的共同点和区别,这样在以后应用这些深度学习框架来处理新的任务时可以得心应手。
适宜人群:
- 未来想从事自然语言处理方向的求职者。
- 对人工智能感兴趣的学生。
- 想亲手打造相关产品的开发者。
购买须知
- 本专栏为图文内容,共计 32 篇。
- 每周五更新,预计于 2020 年 2 月 15 日更新完毕。
- 付费用户可享受文章永久阅读权限。
- 本专栏为虚拟产品,一经付费概不退款,敬请谅解。
- 本专栏可在 GitChat 服务号、App 及网页端 gitbook.cn 上购买,一端购买,多端阅读。
订阅福利
- 本专栏限时特价 39 元,2020 年 1 月 2 日恢复至原价 69 元。
- 订购本专栏可获得专属海报(在 GitChat 服务号领取),分享专属海报每成功邀请一位好友购买,即可获得 25% 的返现奖励,多邀多得,上不封顶,立即提现。
- 提现流程:在 GitChat 服务号中点击「我-我的邀请-提现」。
- 购买本专栏后,服务号会自动弹出入群二维码和暗号。如果你没有收到那就先关注微信服务号「GitChat」,或者加我们的小助手「GitChatty6」咨询。(入群方式可查看第 5 篇文末说明)。
课程内容
导读:如何通关自然语言处理面试
让我们先看看一些常见自然语言处理面试题:
- RNN 为什么会发生梯度消失?如何改进?
- LSTM 的模型结构是什么?
- 为什么说 LSTM 具有长期记忆功能?
- LSTM 为什么能抑制梯度衰减?
- 什么是 Word2Vec?如何训练?
- Word2vec,CBOW 和 Skip-gram 的区别是什么?
- 什么是 seq2seq 模型?有哪些优点?
- 什么是注意力机制?
- 为什么要使用注意力机制,有什么优点?
- CNN 的原理是什么?有哪些优缺点?
- BERT 的模型结构是什么?如何应用?...
之前有些朋友会向我咨询为什么自学了名校的专栏认真做了笔记,却还是会在面试时回答不出来问题,因为其实很多优秀的专栏和书籍侧重点会不同,理论上可能只是讲个思想,来龙去脉并不会讲的很深。
实战中可能只是给出基础的代码,为什么要进行哪一步也没有讲的很细,关于面试的书也只是给出答案,到底为什么要这么回答也没有给出详细的解释,而在面试时面试官们通常会把最基础的东西问得很透彻,比如手推反向传播,手推 LSTM,改进 SkipGram 模型等等,所以单单学完一门专栏看完一本书可能并不会真正地掌握知识。
为什么要学习深度学习自然语言处理
让我们来想象这样一个画面:
当清晨被闹钟叫醒,睁开朦胧的双眼,摸起手机说“siri,帮我设一个五分钟的闹钟”,随之又进入了梦乡。五分钟后很快就到了,总算精神了一些,看看今天每小时的天气预报如何,起床准备开始一天的工作。早餐时间,一边吃着美味的早餐一边打开了邮箱,看到又多了几封垃圾邮件。一切准备就绪,出发去上班,在路上,兴致勃勃地看一篇今天特别感兴趣的外语文章,发现有个单词不认识,于是打开了翻译软件。忽然想到有个包裹怎么还没到,打开购物软件,和他们的聊天机器人客服聊了起来。
上面这些事情可能就发生在每日日常的一个小时内,但却用到了语音识别,时间序列预测,垃圾邮件识别,机器翻译,聊天机器人等技术。
你是否好奇是什么技术实现了这些便利的功能?是否也想自己也可以 DIY 一些人工智能应用来解决自己平日遇到的问题呢?
那么这门专栏就可以为你的奇思妙想奠定基础,这门专栏不仅仅是实战,还有深入的模型理论讲解,尤其是面试中常遇问题的详细解答。
放眼宏观环境,人工智能已经被列入国家战略目标,2020要让人工智能和应用达到世界先进水平,2025年使其成为引导经济转型的主要动力,而自然语言处理是人工智能入口之争的主要技术之一,它将会是未来人机交互的主要方式,很多大公司或者新创公司都下大力度进行这方面的研究,无论是出于兴趣,还是早在职业规划目标之内,学习一下自然语言处理的经典模型原理和实践,未来可以找到更多机会参与到人工智能创新的浪潮中来。
同样在本门专栏中会帮助大家解决这样的问题,我们会以能够回答出面试题为基准,并且是建立在透彻理解模型原理的基础上,而不是死记硬背答案,还会有数学公式推导作为理论支撑,做到真的理解模型,这样当面试官们变换问题时,或者要求提出改进方案或者拓展时,都能够根据自己的理解给出解答。
除了理论还有实战,本专栏设计的实战项目有热门应用,如情感分析,聊天机器人等都是现在很多公司所需要的;也有 NER,POS 等基础应用,是自然语言处理项目中必备的。面试官们会对项目的每个环节都问的比较细,数据清洗,预处理,特征,建模,模型评估等等,所以我们的项目解释也很全,包括数据在模型里是如何变化的,每一步代码干了什么发生了什么都会心里有数。
当然在这一门专栏中肯定无法涵盖自然语言处理的各个角落,我们会先主要覆盖 NLP 工程师面试所需的深度学习基础部分,将基础的经典的模型理论牢牢掌握,会针对真实的面试题给出详细的讲解。
每个模型的公式是什么,怎么训练模型,怎么优化模型都会提到,在实战中遇到的特别技术概念也会给出详细的讲解。
专栏亮点
内容新:本专栏涵盖 RNN,LSTM,GRU,word2vec,CNN 这些基础,还包括多层,双向等拓展,有 Seq2seq 和 Attention,再到最近流行的 Transformer,ELMo,BERT,层层递进掌握经典模型。
实战多:包括 14 个项目的代码及详细的讲解,从命名实体识别,词性标注,到情感分析,聊天机器人,机器翻译,再到图片文字摘要,动手实现有趣的智能应用。
讲的细:每篇文章用黄金圈 why,how,what 的结构详细讲解模型原理,对面试中常考问题给出解答和理论依据,深刻理解经典模型解决问题的思想。
专栏思路和内容大纲
第 1 部分:深度学习基础知识
因为本专栏是关于深度学习在自然语言处理中的应用,所以专栏开始部分我们会概括性地介绍什么是深度学习项目的一般流程和所需基本概念,深度学习在自然语言处理领域主要有哪些热门应用,还会介绍本专栏项目所需的 Keras 和 TensorFlow 2.0 基础,有了这样一个全局观,在后面学习具体模型和项目的时候会更有掌控性。
第 2 部分:循环神经网络基础
这一部分会非常详细地介绍 RNN 和 LSTM 的原理,它们是深度自然语言处理的基础模型,掌握它们对学习并理解后面更复杂的模型结构有很好的帮助,而且专栏中会有面试常考问题的详细解答和公式推导,从数学的层次做到真正理解经典模型的特性。
第 3 部分:词嵌入
在这里我们会介绍 Word2vec 的方法,包括 CBOW,Skip-gram,GloVe 的理论和应用。词嵌入是自然语言处理任务中很重要的一步,它可以让模型更好地学习到单词之间的关系和单词地含义,使模型表现地更好。
第 4 部分:循环神经网络的改进
这一部分我们将学习如何改进基础的 RNN 和 LSTM,通过前面对基础理论的深入了解,我们可以知道它们具有哪些不足,于是通过改善门控单元,搜索结果,增加方向等方法来使模型进一步得到改善。
第 5 部分:Seq2seq 和 Attention
这一部分模型的结构进一步升级,Seq2seq 是一个 Encoder–Decoder 结构的网络,它最重要的地方在于输入序列和输出序列的长度是可变的,不过因为不管输入的长度多长都会被它压缩成一个几百维的中间向量,就会造成任务质量的下降,而 Attention 又进一步解决了 Seq2seq 存在的问题,有了这些改进使得模型在情感分析,聊天机器人,机器翻译等任务中的性能提升。
第 6 部分:卷积神经网络的应用
卷积神经网络被大家熟知的是在图像领域的重要模型,这一部分就会介绍它其实也可以用于自然语言处理的任务中,通过学习这种“跨界”的模型,不仅可以更了解到任务和模型的本质,还有助于开拓解决问题的思路。
第 7 部分:Transformer,ELMo,BERT
BERT 是2018年10月11日由 Google AI Language 发布的模型,当时在问答,推理等 11 个 自然语言处理任务上的表现都刷新了记录,目前为止有很多优秀的模型都是在其基础上进行改进,所以这部分将介绍 Transformer,ELMo,BERT 这一系列的原理和应用。
你将收获什么
面试必备知识点
在自然语言处理相关职位的面试中,面试官会对模型的结构,原理,数学推导,优缺点,改进方法等进行细致地提问,很多外文原版书籍或者名校专栏中都不会做特别详细地解答,最后看了很多书学了很多专栏,可能到面试的时候还是答不出来问题,在本专栏中就会对这些知识点进行深入地讲解,让大家能够真正理解每个模型,知其然知其所以然。
本专栏将用通俗易懂的方式讲解模型的原理,用图解的方式画出模型中数据的走向,对关键步骤的计算,例如前向计算,反向传播,会有详细的手写推导。以及一些核心问题的探究,例如为什么循环神经网络具有记忆功能,LSTM 为什么可以缓解梯度消失,为什么用双向 LSTM,Encoder–Decoder 的结构是什么样的,为什么需要 Attention 机制等。
动手实践,编写有趣的项目
无论是出于兴趣还是想要找到高薪的工作,最后都要落实到有能力解决问题。所以本专栏在每个模型的原理之后,都有相应的项目代码,而且有非常详细的代码讲解,理论与实践结合,真正把模型用起来,除了用序列模型处理其他模型能做到的分类和预测的任务,还可以构建一些好玩的,例如自动生成某个大师风格的文章,根据电影评论分析一下观众对它的评价,做个简易的聊天机器人,再或者平时经常用的翻译软件,自己也可以学习到机器翻译模型的构建方法。
熟练地使用 TensorFlow/Keras
本专栏在每个模型后都配有应用代码,都是用 TensorFlow 或 Keras 来实现,这两个框架也是很多公司在招聘时优先考虑的技术,通过专栏中一些小项目的练习,可以进行强化训练,并且由于都是序列模型,还可以进行横向比较,了解实现不同项目的共同点和区别,这样在以后应用这些深度学习框架来处理新的任务时可以得心应手。
作者介绍
杨熹,数学系硕士,目前从事数据科学方面的工作。曾任 Intel 成本分析师,日本 TRIAL 数据分析师,美国 Trilogy 数据科学培训师,参与销量预测,成本分析,推荐系统等多个项目,擅长机器学习,深度学习,自然语言处理。
适宜人群:
- 未来想从事自然语言处理方向的求职者。
- 对人工智能感兴趣的学生。
- 想亲手打造相关产品的开发者。
深度学习在自然语言处理中的应用全景图-上
Natural language processing (NLP) 即自然语言处理,它关注的是如何开发实际应用来促进计算机与人类之间的交互语言。 典型应用包括语音识别,口语理解,对话系统,词汇分析,解析,机器翻译,知识图谱,信息检索,问答系统,情感分析,社交计算,自然语言生成和自然语言总结。
在过去的五十年里,NLP 经历了三次浪潮,理性主义,经验主义,还有现在的深度学习。
在传统的机器学习中,需要我们做大量的特征工程,很多时候需要大量的专业知识,这就形成了一个瓶颈,而且浅层模型也缺乏表示能力,缺乏抽象能力,在对观察到的数据进行建模时,无法识别复杂的因素。而深度学习却可以通过使用深度多层的模型结构和端到端的学习算法来克服上述困难。
深度学习的革命有五个基本支柱:
- 通过嵌入实现语言实体的分布式表示;
- 得益于嵌入的语义泛化;
- 自然语言的长跨深度序列建模;
- 从低到高有效表示语言水平的分层网络;
- 可以共同解决许多NLP任务的端到端的深度学习方法。
本文将主要介绍一下深度学习在这几个典型场景的应用:会话语言理解,对话系统,知识图谱,机器翻译,问答系统,情感分析还有视觉字幕。各领域会概括介绍一些先进的研究和模型,可以对 DL 在 NLP 的应用现状有个全局观,大家如果对某个领域特别感兴趣还可以着重去以此文为线索去读这个领域的相关论文。
1. 会话语言理解
会话语言理解 (Conversational Language Understanding) 是要从口语或文本形式的自然对话中提取出含义,这样可以方便用户只需要使用自然的语言给机器下达指令就能执行某些任务。它是语音助理系统的一个重要组成部分,例如 Google Assistant, Amazon Alexa, Microsoft Cortana, Apple Siri,这些助理系统可以帮助我们做很多事情,创建日历,安排日程,预订餐厅等等。
以目标为导向的会话语言理解主要包括 3 个任务;
- 领域分类(domain classification):要识别用户在谈什么方面的话题,例如旅行,
- 意图分类(intent determination):要判断用户想要干什么,例如想要订宾馆,
- 语义槽填充(slot filling):要知道这个目标的参数是什么,例如预订宾馆的日期,房型,地理位置等。
1. 领域分类和意图确定
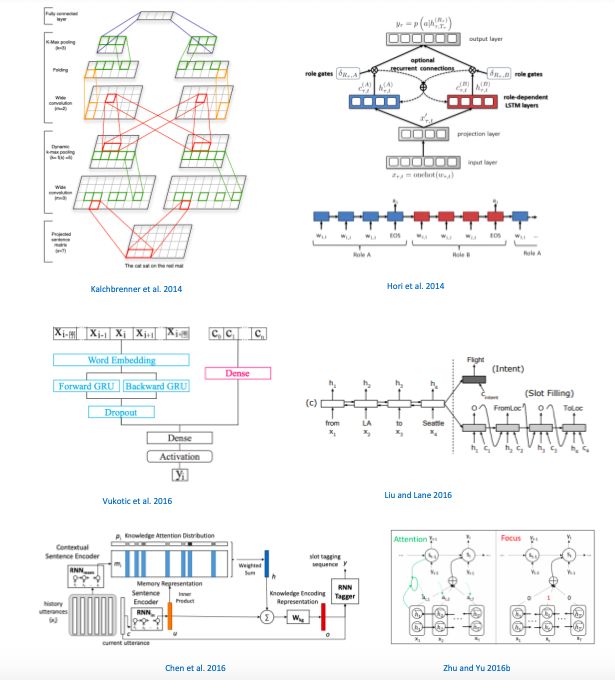
Hinton 等在2006年提出的 deep belief networks 率先将深度学习用于话语分类,并在信息处理应用的各个领域中普及。后来流行的技术是使用卷积神经网络 CNN 及其变体,例如 (Kalchbrenner et al. 2014)。随后 (Lee 和 Dernoncourt 2016) 尝试使用 循环神经网络 RNN 来处理这类任务,并与 CNN 结合,同时利用 RNN 和 CNN 的优点。
2. 语义槽填充
对于这个任务,比较先进的算法是基于 RNN 及其变种的。
(Dupont et al. 2017) 提出了一种新的 RNN 变体结构,其中输出标签也被连接到下一个输入中。
也有很多是基于双向 LSTM / GRU 模型的,(Vukotic et al. 2016)。
(Liu and Lane 2016) 将 encoder–decoder 模型用于此任务,(Chen et al. 2016) 使用了记忆网络 memory。(Zhu and Yu 2016b) 应用了焦点注意力机制。
3. 理解上下文
自然语言理解还有一个重要的任务是理解上下文。(Hori et al. 2014) 提出了使用 role-based LSTM 层,可以有效地理解口语中上下文。(Chen et al. 2016) 提出了一个基于端到端神经网络的对话理解模型,用记忆网络来提取先验信息,作为编码器的上下文知识,进而理解对话的含义。
2. 口语对话系统
口语对话系统(SDS:Spoken Dialog Systems)被认为是虚拟个人助理(VPA:virtual personal assistants)的大脑,也就是我们熟知的聊天机器人,现在应用非常广泛,从客服到娱乐随处可见。Microsoft 的 Cortana,Apple 的 Siri,Amazon 的 Alexa,Google 的 Home,和 Facebook 的 M 都集成了 SDS 模块,这样用户可以通过很自然的语言与虚拟助理交互,就能高效的完成任务。
经典的口语对话系统包含多个模块,自动语音识别,语言理解,对话管理器,自然语言生成器。目前深度学习技术已被用于模拟其中几乎所有组件。
1. 语言理解
这一模块在上一章已经介绍了一些先进研究成果。
2. 对话状态跟踪器(Dialog State Tracker)
它是通过对话过程来跟踪系统对用户目标的信任状态。最先进的对话管理器就是通过状态跟踪模型来监控对话进度的。
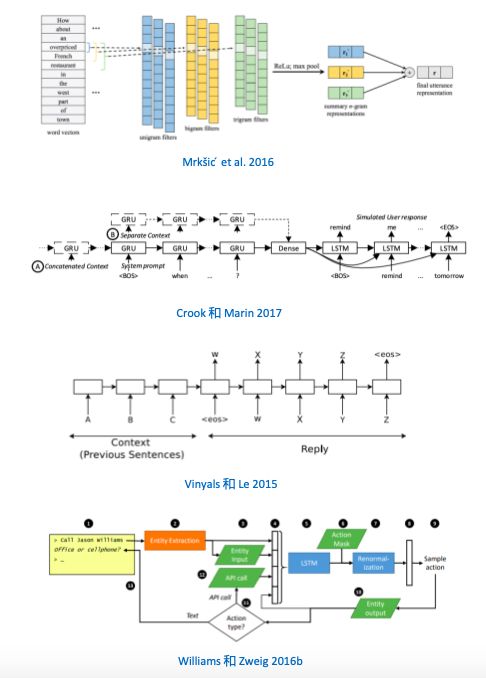
(Mrkšic ́ et al. 2016) 的神经对话管理器还提供了话语,时隙值对和知识图谱之间的联合表示,可以在较大的对话域中部署对话系统。
3. 深度对话管理器(Deep Dialog Manager)
可以让用户用很自然的方式进行交互。它负责对话的状态和流程,并且决定着应该使用什么策略。
对于复杂的对话系统,通常不可能先验地指定出来好的策略,并且环境还会随时变化, 所以 (Singh et al. 2016); (Fatemi et al. 2016b) 通过强化学习学出在线交互策略。
4. 基于模型的用户模拟器(Model-Based User Simulators)
用于生成人工交互对话。
(Crook 和 Marin 2017) 研究了基于上下文的 sequence-to-sequence 方法,可以产生像人类间说话一样水平的对话,超过了其他基线模型的表现。
5. 自然语言生成(NLG: Natural Language Generation)
是给一个含义来生成文本。
(Vinyals 和 Le 2015) 关于神经对话模型的研究开辟了新篇章,使用基于 encoder–decoder 的模型进行文本生成,他们的模型有两个 LSTM,一个用于将输入句子编码为“思想向量”,另一个用于将该向量解码为答复语句,不过这个模型只能提供简短的问题答案。后来 (Williams 和 Zweig 2016b) 等学者开始重点研究如何使用强化学习来探索文本生成。
3. 知识图谱
知识图谱也称为知识库,是一种重要的数据集,以结构化的形式组织了实体,实体属性和不同实体之间语义关系的丰富知识,是自然语言理解的基础资源,在人工智能的许多应用中发挥重要作用,如搜索,问答,语音识别等。
目前几个应用比较广泛的知识图谱是,Freebase,DBpedia,Wikidata,YAGO,HowNet。
基于深度学习的知识图谱技术有三大类:
- 知识表示技术,用来将图谱中的实体和关系嵌入到密集低维的语义空间中。
- 关系提取技术,从文本中提取关系,用于构建图谱。
- 实体链接技术,将图谱与文本数据联系起来,可以用于许多任务中。
1. 知识表示技术
(Bordes et al. 2013) 的 TransE 是一种典型的基于翻译的知识表示学习方法,用它来学习实体和关系的低维向量简单有效。
但大多数现有知识表示学习方法仅关注知识图谱中的结构信息,而没有处理其他丰富的多源信息,如文本信息,类型信息和视觉信息。(Xie et al. 2016b) 提出根据 CBOW 或 CNN 编码器的描述学习实体表示。(Xie et al. 2016c) 通过构造投影矩阵,利用分层类型结构增强了 TransR。Xie et al. 2016a) 提出了体现图像的知识表示,通过用相应的图来学习实体表示,进而考虑视觉信息。
2. 关系提取技术
关系提取是要从文本中自动地提取出关系。神经网络在关系提取上主要有两个任务,句子级和文档级。
其中句子级关系提取是要预测一个句子中实体对之间的语义关系。主要由三个部分组成:1. 输入编码器,用于表示输入的词。2. 句子编码器,将原始句子表示为单个向量或向量序列。3. 关系分类器,计算所有关系的条件概率分布。
(Zeng et al. 2014) 用一个 CNN 对输入句子作嵌入,其中卷积层可以提取局部特征,再用 max-pooling 将所有局部特征组合起来,最后获得固定大小的输入句子的向量。
(Zhang and Wang 2015) 用 RNN 嵌入句子,这样可以学习出时间特征。
3. 实体链接技术
实体链接任务有一个问题是名称歧义, 所以关键的挑战是如何有效使用上下文来计算名称与实体之间兼容度。在实体链接中,神经网络主要用来表示异构的上下文证据,例如名称提及表示,上下文提及表示和实体描述。
(Francis-Landau et al. 2016) 用 CNN 将名称提及表示,局部上下文,源文档,实体标题和实体描述投影到同一个连续特征空间,而且不同证据之间的语义相互作用被建模为它们之间的相似性,不仅可以考虑到单词的重要性和位置影响,还可用于实体链接中的文档表示

深度学习在自然语言处理中的应用全景图-下
机器翻译
机器翻译研究的是如何使用计算机自动翻译人类语言。
深度学习用于机器翻译主要有两类方法:
- 将深度学习用于改进统计机器翻译的各个组件,如词对齐,翻译规则概率估计,短语重新排序模型,语言模型和模型特征组合。
- 基于编码器-解码器框架的端到端翻译系统,可以直接用神经网络将源语言映射到目标语言。
端到端神经机器翻译与传统统计机器翻译的主要区别是它可以直接从数据中学习,无需手动设计特征来捕获翻译规则。
Sutskever et al. 2014) 提出用一个 RNN 作为编码器,将源上下文编码为向量表示,用另一个 RNN 作为解码器,逐字生成翻译。
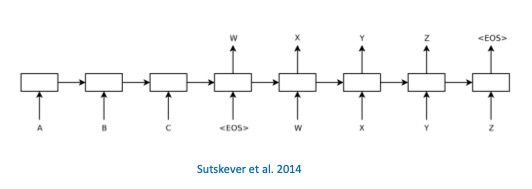
在 Sutskever 的编码-解码框架中,不管句子的长度是多少,编码器需要将整个源句子表示为一个固定长度的向量。 Bahdanau et al. 2015) 表明这样会使神经网络难以处理长期依赖,并引入了注意机制,动态地选择相关源上下文来生成目标词。

神经机器翻译有一个很大的挑战是如何解决目标语言词汇引起的效率问题,因此 Sutskever 和 Bahdanau 使用的都是完整词汇表的子集,但这样会显著影响子集或词典外的词的翻译质量。Luong et al. 2015) 提出的模型可以识别源语句和目标句子中的词典外单词之间的对应关系,并在后期处理步骤中翻译词典外单词。
神经机器翻译还有一个重要课题是如何将先验知识整合到神经网络中。Zhang et al. 2017b) 在 (Ganchev et al. 2010) 提出的后验正规化的基础上,提出了一个框架可以整合任意知识来源。
问答系统
问答系统 (QA: Question answering QA) 是自然语言处理中一个非常有挑战性的任务,
深度学习在 QA 中两个比较典型任务上有了很不错的应用:
- 深层学习问答知识库,即用深度学习来理解问题的含义,并将它们翻译成结构化查询。2. 深度学习机器理解,用来直接计算问题和答案之间的深层语义匹配。
很多神经网络或它们的变种都已经被用于这个任务,例如 CNN,RNN(LSTM,BLSTM),注意机制和记忆网络。这些研究主要分为两类:信息提取方式(information extraction)或语义解析方式(semantic parsing)。信息提取即使用一些关系提取技术从知识库中获得一组候选答案,然后将其与问题进行比较。 语义解析是设法借助新颖的网络结构从句子中提取出符号表示或结构化查询。
信息提取方式的工作通常是在一个神经网络结构中对答案进行 retrieval–embedding–comparing。
Bordes et al. 2014a) 最早提出了一个联合嵌入框架,可以学习出一个结构化知识库中对单词,实体,关系等语义项的向量表示,并设法将一个自然语言问题映射到知识库的某个子图。
Dong et al. 2015) 用 CNN 来编码问题和候选答案之间的不同类型的特征。他们提出了一种多列卷积神经网络(MCCNN)来捕捉问题的不同方面,并通过三个渠道,答案路径,答案语境,答案类型进一步对一组问答进行评分。
Hao et al. 2017) 提出的一种基于交叉注意力机制的神经网络比基于知识库的问答系统要好。
记忆网络是一种新颖的学习框架,根据一个记忆机制设计,可以在特定任务期间被读取,修改和添加。 Miller et al. 2016) 研究了记忆知识的各种 Key- Value 形式,他们的模型还可以从存储器中进行多次寻址和读取,可以收集上下文,动态地更新问题并获得最终答案。
基于 KBQA 的另一种主流是语义分析的模型,这种模型尝试正规地表示问题的含义,然后使用知识库进行实例化,并在知识库上面建立结构化查询,进而可以显式地捕获复杂查询。Xu et al. 2016) 提出了一个多通道卷积神经网络(MCC-NNs),可以从词汇和句法角度学习紧凑稳健的关系表示。这个方法很适合开放域知识库问答系统。因为在开放域知识库中通常存在数千个关系,传统的基于特征的模型会遇到数据稀疏问题,而且在看不见的单词上的泛化能力也差。
在语义理解领域,Seo et al. 2016) 提出了双向注意流网络(BiDAF),采用多阶段分层过程,可以不需要提前总结就能在不同粒度下表示上下文。

情感分析
情感分析要做的是从社交网络,博客或产品的评论中识别和提取用户的情绪,在数据挖掘,网络挖掘和社交媒体分析方面有广泛应用。主要任务有情绪分类,意见提取,细粒度情绪分析。接下来我们主要看深度学习在 句子级,文档级的应用。
句子级别的情感分析就是对句子的情感极性进行分类。很多神经网络结构都可以用来处理这个问题,卷积神经网络,循环神经网络,递归神经网络和辅助增强句子表示。
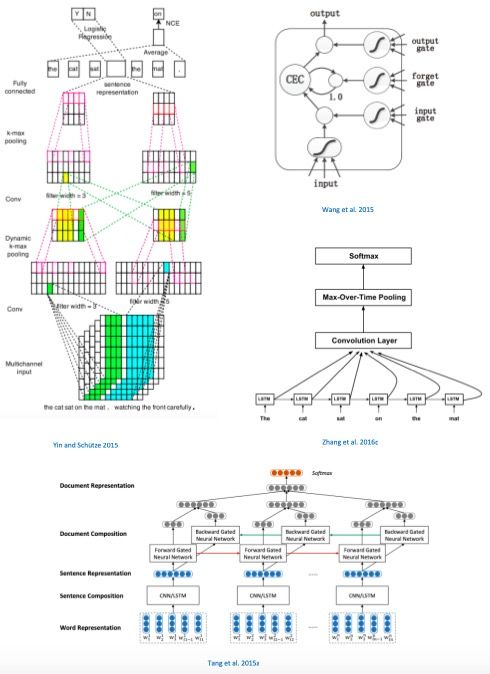
CNN 可以更好地捕获基于窗口的局部组合,基本的 CNN 有一个卷积层和池化层,Kalchbrenner et al. 2014) 将其扩展为多层结构,并用动态k-max 池化来更好地表示句子。Yin and Schütze 2015) 构建了多通道的多层 CNN,可以使用若干个不同的词嵌入。
RNN 可以有效学习隐式长期依赖性,Wang et al. 2015) 提出了用长期短期记忆(LSTM)神经网络进行推文情绪分析。
Zhang et al. 2016c) 结合了 LSTM 和 CNN,提出了一个依赖敏感的 CNN 模型,使 CNN 网络结构也能够捕获长距离依赖性,很好地利用了二者的优点。
文档级的情感分类是要识别一个文档的情感类型。
Tang et al. 2015a) 用 CNN 来计算句子向量,然后用双向 GRU 来计算整个文档的嵌入表示。
视觉字幕
由图像生成自然语言,或者称为视觉字幕,是一种新兴的深度学习应用,属于自然语言生成(NLG),是计算机视觉和自然语言处理的交叉。是很多重要应用的基础技术,如语义视觉搜索,聊天机器人的视觉智能,帮助视障人士感知视觉内容等等。
过去2年深度学习技术发展迅速才使这一领域得到突破性进展,在这之前这个任务几乎是不可能完成的。
Sutskever et al. 2014); Bahdanau et al. 2015) 将 sequence-to-sequence 用于机器翻译取得了比较成功的效果后,(Vinyals et al. 2015); (Karpathy and Fei-Fei 2015); (Fang et al. 2015); (Devlin et al. 2015); (Chen and Zitnick 2015) 也研究了用于图像字幕的端到端的 end-to-end encoder–decoder 框架。
在这个框架中,原始图像通过深度 CNN 被编码为一个全局视觉特征向量,承载着图像的整体语义信息,
提取出全局视觉特征向量后,被投入到基于 RNN 的解码器中来生成字幕,
上述 encoder–decoder 结构不仅可以用于图像字幕,还被 (Ballas et al. 2016) 用于视频字幕,主要区别是用了不同的 CNN 的结构和基于 RNN 的语言模型。
(Xu et al. 2015) 也将注意力机制用于这个方向,来学习字幕生成时应该聚焦在图像的什么位置。
(Anderson et al. 2017) 提出的 bottom-up 注意力模型,可以将整个模型的所有部分,包括 CNN,RNN 和 attention,从头到尾共同训练,实现端对端并且达到了非常好的效果。
此外,(Rennie et al. 2017) 提出了一种自我批判序列训练算法,是强化学习在视觉字幕领域的应用。强化学习在视觉字幕领域也越来越流行,
生成对抗网络(GAN)也被用于文本生成,SeqGAN(Yu et al.2017)将生成器建模为一种强化学习的随机策略,用于输出文本,RankGAN (Lin et al.2017)提出了一种基于排序的鉴别器的损失,可以更好地评估生成文本的质量。


以上就是简要介绍了深度学习在 NLP 的其中几个领域的重要研究,会话语言理解,对话系统,知识图谱,机器翻译,问答系统,情感分析还有视觉字幕,由此我们也可以看出 RNN,LSTM,GRU,双向RNN,Seq2seq,Attention机制在深度学习自然语言处理领域的重要作用,本门课程也会对其中几个应用进行详细讲述和给出代码实战。在提到的文献中都给出了论文链接,如果大家有兴趣可以点击学习,也可以进一步找相关论文学习,了解更新的研究进展,另外推荐大家看一下这本书《Deep Learning in Natural Language Processing》。
一文了解深度学习
其实一篇几千字的文章很难将深度学习都讲清楚,不过标题是“了解”,这篇文章的目的就是希望可以给大家带来一个深度学习的整体印象,它是什么,能干什么,处理问题的一般流程是什么,会涉及到的主要概念有哪些,有了这样的基本框架后,这样在后面的实战中,大家可以再回头来比较,看哪些是属于通用流程的,哪些是具体问题所特有的技术技巧。
在这篇文章中我们主要有以下内容:
- 什么是深度学习
- 深度学习的简要发展史
- 和机器学习的关系和区别
- 深度学习有什么应用
- 应用深度学习的一般流程和基本概念
1. 什么是深度学习
深度学习是机器学习的一个分支,是一类让计算机直接通过大量的实例,自主地从数据中学习特征的技术。

在人类大脑中大约有 1000 亿个神经元和 100~1000 万亿个突触,可以进行很复杂的思维活动,处理很高级有难度的任务,受神经系统的启发,深度学习主要应用神经网络模型,来让机器更智能地完成一些任务。
神经网络就是按照一定规则将多个神经元连接起来的网络,不同的神经网络具有不同的连接规则。例如全连接神经网络,它有三种层:输入层,输出层,隐藏层,第 N 层的每个神经元和第 N-1 层的所有神经元相连,同一层的神经元之间没有连接。

深度学习的“深”,指的就是神经网络中隐藏层的个数。普通的神经网络只包含2-3个隐藏层,而深层网络可以包含多达几百个。
不同的层负责学习不同的特征,例如在图片识别任务中,第一层可能学习到了颜色,第二层学习到了角度,第三层学习到了纹理等。隐藏层通常以无监督模式学习到输入数据的一些特征,输出层以监督式模式来完成分类或回归的任务。
2. 深度学习的简要发展史

(图片来自:Andrew L. Beamhttps://beamandrew.github.io/deeplearning/2017/02/23/deeplearning101_part1.html)
神经网络的数学模型最早出现在 1943 年的论文 《A Logical Calculus of Ideas Immanent in Nervous Activity》 中,这个模型的神经元也叫做 McCulloch Pitts 神经元,用一种很简单的方式来模拟人类大脑的神经元,
在二十世纪 60 年代提出了反向传播的概念,后来在 1986 年 Hinton 和其他几位作者展示了如何在神经网络中应用反向传播,1989 年 Yann LeCun 第一次将反向传播应用于实践,用 CNN 识别手写数字。
在 2000 年发现了梯度消失问题,一般的多层神经网络的表现并不是很好,在 1997 由 Sepp Hochreiter 和 Juergen Schmidhuber 提出的 LSTM:Long Short-Term Memory 模型恰好可以改善这个问题。
2006 年 Hinton 提出的 DBN:Deep Belief Networks 引起了神经网络的第二次发展。
2012 年,在 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 比赛中,SuperVision 团队建立的深度卷积神经网络有 7 个隐藏层,5 个卷积层,包括 6000 万个参数,650,000 个神经元,6300 万个连接,通过 1000 万个图片的训练,最后在 150,000 个图片测试集上的成绩是错误率为 15.3%。
3. 和机器学习的关系和区别
传统的机器学习算法,需要应用者对某个相关领域有一些专业知识,一般流程是需要人为地根据数据构造出很多个特征,然后选择合适的模型进行分类或回归等任务。
深度学习和其他机器学习算法的区别是它能够自动地学习出数据的特征表示,不需要依赖人为做很复杂的特征工程,可以直接将原始数据投入到深层神经网络,就能够自动学习到数据中的关系和模式,而且随着数据量的增加,效果还会不断地提升,

4. 深度学习有什么应用
随着数据量的增大,计算能力的增强,云计算等技术的发展,还有很多新的神经网络结构不断被研发出来,有 TensorFlow,Theano 等能够让开发者快速迭代验证想法的开源平台,再加上可以更有效地改善梯度消失梯度爆炸过拟合等问题的激活函数,正则化方法,优化算法等技术的应用,深度学习在很多任务上的表现越来越好。
现在深度学习被广泛应用于计算机视觉,语音识别,无人驾驶,社交网络,机器翻译,生物信息学,药物设计,医学图像分析,工业自动化,和游戏等等很多领域,而且在某些任务上面的表现甚至超过了人类。
5. 应用深度学习的一般流程和基本概念汇总
当我们用深度学习模型解决问题时,一般有下面几步:
- 加载数据
- 数据预处理
- 2.1 分为训练集和测试集
- 2.2 数据标准化归一化
- 定义模型
- 3.1 权重初始化
- 3.2 激活函数
- 3.3 Batch Normalization
- 3.4 Dropout
- 配置模型
- 4.1 定义损失函数
- 4.2 L1, L2 正则化
- 4.3 选择优化算法
- 4.4 学习率
- 训练模型
- 评估模型
- 6.1 定义评估指标函数
- 做出预测
- 保存模型
接下来让我们简要看看其中关键的概念:
2.1 训练集,验证集,测试集
When:拿到数据集后,需要将数据分为训练集、验证集、测试集。
Why:训练集:算法用其进行训练,学习出模型的参数,进而得到模型验证集:用于交叉验证,为了选择出最好的模型测试集:训练好的模型用其进行预测,评估模型的表现
How:一般可以采用这样的比例:
数据量在几万或以下级别时,无验证集的情况:70% : 30%有验证集的情况:60% : 20% : 20%
数据量在百万级别时,验证集和测试集的比重变小,只要能达到验证模型评估模型效果即可,百万数据量:98% : 1% : 1%超过百万数据量:99.5% : 0.25% : 0.25%
2.2 数据标准化归一化
When:当样本数据的各个特征具有不同的量纲时,需要对其进行标准化。
Why:作用就是在应用梯度下降等算法求成本函数的最优解时,可以加快收敛速度。直观上,以一个最简单的成本函数为例,可以将成本函数的图像由椭圆调整为圆,这样梯度下降法求最优解时就不用走很多弯路,进而减少迭代次数,加快收敛到最优解。并且无论从哪个位置开始迭代,都可以用比较少的迭代次数找到全局最优解。
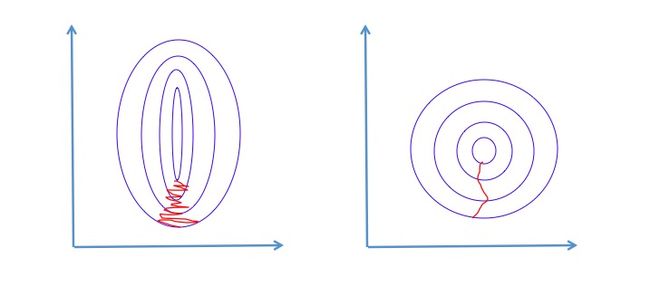
How:常用的方法有:
0 均值标准化(标准化):$x^* = \frac{x−μ}{σ}$,其中 μ 为数据的均值,σ 为标准差,转换后的数据符合标准正态分布
min-max 极差标准化(归一化):$x^* = \frac{x−min}{max−min}$,其中 min 为数据中最小值,max 为最大值,转换后的数据在 0~1 之间
3.1 权重初始化
When:我们在训练神经网络时,需要将权重进行初始化
Why:合适的初始化方法可以在一定程度上减缓梯度消失和爆炸的速度
How:常用方法有:
1. 随机初始化,使其服从标准正态分布
w = np.random.randn(layer_size[l], layer_size[l-1])
但这个方法在训练深度神经网络时可能会造成两个问题,梯度消失和梯度爆炸。
所以在初始化权重时,不再服从标准正态分布,而是 服从方差为 k/n 的正态分布,k 因激活函数而不同。
2. 对于 RELU(z),用这个式子 $\sqrt{\frac{2}{size^[l-1]}}$ 乘以随机生成的 w,也叫做 He Initialization:
w = np.random.randn(layer_size[l], layer_size[l-1]) * np.sqrt(2 / layer_size[l-1])
3. 对于 tanh(z),用 Xavier 初始化方法,即用这个式子 $\sqrt{\frac{1}{size^[l-1]}}$ 乘以随机生成的 w,和上一个的区别就是 k 等于 1 而不是 2。
w = np.random.randn(layer_size[l], layer_size[l-1]) * np.sqrt(1 / layer_size[l-1])
通过这些方式,w 既不会比 1 大很多,也不会比 1 小很多,所以梯度不会很快地消失或爆炸,可以避免收敛太慢,也不会一直在最小值附近震荡。
3.2 激活函数
What:在神经元中,输入的 inputs 通过加权求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function。
Why:激活函数能够使神经网络具有非线性,这种非线性使深度网络能够学习复杂的关系,激活函数决定着一个感知器是否应该被触发。
How:常用的激活函数有:
Sigmoid:可以将一个实数映射到 (0,1) 的区间,即可用于转换为概率,因此可用来做二分类,但存在梯度消失问题。
Tanh:是 sigmoid 的缩放版本,将输入映射到[-1,1]范围内,是 0 均值的,应用中 tanh 会比 sigmoid 更好。
**ReLU: **用于隐藏层神经元的输出,x 大于 0 时,函数值为 x,导数恒为 1,这样在深层网络中使用 relu 激活函数就不会导致梯度消失和爆炸的问题,而且 SGD 的收敛速度会比 sigmoid, tanh 快很多。但是因为 x 小于 0 时函数值恒为 0,会导致一些神经元无法激活。
Leaky Relu:为了解决 Relu 函数为 0 部分的问题,当 x 小于 0 时,函数值为 kx,有很小的坡度 k,一般为 0.01,0.02,或者可以作为参数学习而得。它具有 ReLU 的所有优点:计算高效、快速收敛。而且因为导数总是不为零,减少静默神经元的出现,允许基于梯度的学习,一定程度上缓解了 dead ReLU 问题。

在选择激活函数的时候,如果在不知道该选什么的时候就选择 ReLU。
3.3 Batch Normalization
When:在前面有提到输入数据要进行标准化,在神经网络中,不仅在输入层要做这样的预处理,在隐藏层也需要做一下标准化,
Why:因为前一层的输出值,对后面一层来说,就是它的输入,而且如果某个特征数量级过大,在经过激活函数时,就会提前进入它的饱和区间,即不管如何增大这个数值,它的激活函数值都在 1 附近,不会有太大变化,这样激活函数就对这个特征不敏感。
How:简单理解就是在计算出前一层的 z 后,先计算出这批数据的平均值和标准差,对每个数据做完标准化之后,再经过激活函数,进入到下一层。

3.4 Dropout
What:Dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。即在训练时,每个神经单元都可能以概率 p 被去除,在测试阶段不需要用 Dropout。

Why:神经网络的规模如果很大就会有这样两个缺点:费时,而且容易过拟合,所以用 Dropout 来起到收缩的作用。
How:
每层 Dropout 网络和传统网络计算的不同之处:
相应的公式:

4.1 定义损失函数
What:损失函数是用来衡量模型的预测值和数据的实际值之间的差距的。
Why:模型训练的目的就是通过不断的迭代来使损失函数达到最小值。
How:在回归问题中,常用的损失函数是 MSE:Mean squared error$$L(y, \hat{y}) = \sum{i} (yi - \hat{y}_i)^{2}$$
在分类问题中,最常用的就是交叉熵损失函数:Cross entropy $$L(y, \hat{y}) = \sumi yi \log \frac{1}{\hat{y}i} = -\sumi yi \log \hat{y}i$$
4.2 L1, L2 正则化
What:L1, L2 正则化就是要在损失函数上面加入一个惩罚项,
Why:L1 正则化可以产生稀疏权值矩阵,可以用于特征选择,一定程度上也可以防止过拟合。L2 正则化用于防止模型过拟合。因为神经网络的训练目标是使成本函数最小化,在成本函数上加入一个正则化项后,如果正则化因子 λ 设置的足够大,那么权重 W 就需要足够小,甚至趋于 0,相当于减小了很多神经元的影响,一个复杂的网络变得简单些。
How:L1 正则化:
$$L = L0 + \alpha \sumw{|w|} \tag{1}$$
L2 正则化:
$$L = L0 + \alpha \sumw{w^2} \tag{2}$$
4.3 定义优化算法
What:优化算法是用来找到目标函数的最优解的算法。
What:常用的优化算法有:
梯度下降法:形象地理解是如果我们在一座山上,想要到达最低点,那么沿着当前位置的梯度的负方向前进一步,到达一个新位置后同样以当前位置的梯度的负方向,这样的方法是可以最快到达最低点的。
Batch 梯度下降:每次对整个训练集进行梯度下降,不过这样处理耗时会较长。
$$\theta = \theta - \eta \cdot \nabla_\theta J( \theta)$$
Stochastic 梯度下降:每次只对一个样本进行梯度下降,会有很多噪音,不能通过向量化来进行加速,只会在最小值附近不断的波动。
$$\theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i)}; y^{(i)})$$
Mini batch 梯度下降:每次处理样本的个数在上面二者之间。可以进行向量化,不用等待整个训练集训练完就可以进行后续的工作,所以更新参数更快,避免局部最优。
$$\theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i:i+n)}; y^{(i:i+n)})$$
Momentum 梯度下降:用梯度的指数加权平均数来更新权重,减少摆动,加快最小值方向上的收敛。$$\begin{align} \begin{split} vt &= \gamma v{t-1} + \eta \nabla\theta J( \theta) \ \theta &= \theta - vt \end{split} \end{align}$$
RMSprop:将微分项进行平方,用平方根进行梯度更新,可以减小某些维度上波动较大的情况,进而加快梯度下降。
$$\begin{align} \begin{split} E[g^2]t &= 0.9 E[g^2]{t-1} + 0.1 g^2t \ \theta{t+1} &= \theta{t} - \dfrac{\eta}{\sqrt{E[g^2]t + \epsilon}} g_{t} \end{split} \end{align}$$
Adam:是 Momentum 和 RMSprop 的结合,在 RMSprop 的基础上加了 bias-correction 和 momentum。
$$\theta{t+1} = \theta{t} - \dfrac{\eta}{\sqrt{\hat{v}t} + \epsilon} \hat{m}t$$
其中,
$$\begin{align} \begin{split} \hat{m}t &= \dfrac{mt}{1 - \beta^t1} \ \hat{v}t &= \dfrac{vt}{1 - \beta^t2} \end{split} \end{align}$$
$$\begin{align} \begin{split} mt &= \beta1 m{t-1} + (1 - \beta1) gt \ vt &= \beta2 v{t-1} + (1 - \beta2) gt^2 \end{split} \end{align}$$
整体来讲,Adam 的效果最好,所以最常用。
4.4 学习率
What:在梯度下降等算法中可以看到有一个系数 α ,它决定着梯度下降的步伐快慢。
Why:如果 α 太大:步伐太大,可能会造成模型训练发散而不收敛,跨过最优解,使损失函数变得更糟。如果 α 太小:步伐太小,虽然不会跨过最优解,但是损失函数的变化速度较慢,要用更长的时间才能收敛。如果 α 固定不变:当用 mini-batch 梯度下降法时,因为不同 batch 会存在一定的噪声,所以算法在到达最小值附近时会在一个较大范围内波动而不会精确收敛。所以采用 α 逐渐减小的策略:开始时向最小值点方向下降较快,α 逐渐减小,下降步伐逐渐变小,最终在最小值附近一个较小范围内波动。
How:常用的学习率下降方法有:
常用:$$\alpha = \dfrac{1}{1+decay_rate*epoch_num}\alpha_{0}$$
指数衰减:$$\alpha = 0.95^{epoch_num}\alpha_{0}$$
其他:$$\alpha = \dfrac{k}{epoch_num}\cdot\alpha_{0}$$
5. 训练模型
神经网络的训练大体可以分为下面几步:
- 首先用前面提到的初始化权重 weights 和 biases
- 然后进行前向传播:用 input X, weights W ,biases b, 计算每一层的线性组合 Z,经过激活函数得到 A,最后一层用 sigmoid, softmax 或 linear function 等作用 A 得到预测值 Y
- 接着计算损失,来衡量预测值与实际值之间的差距
- 然后进行反向传播,来计算损失函数对 W, b 的梯度 dW ,db
- 最后通过随机梯度下降等优化算法来进行梯度更新,重复第二到第四步直到损失函数收敛到最小
6.1 定义评估指标函数
训练完模型后,需要在测试集上对模型的表现进行评估。
评估函数和损失函数很像,它们的区别是评估函数的结果不会用在模型的训练过程中,任何损失函数都可用作评估函数。
在回归问题中可以用:
Mean Squared Error: 计算预测值与真值的均方差Mean Absolute Error: 计算预测值与真值的平均绝对误差Mean Absolute Percentage Error: 计算预测值与真值的平均绝对误差率Cosine Proximity: 计算预测值与真值的余弦相似性
在分类问题中可以用:
Binary Accuracy: 对二分类问题,计算在所有预测值上的平均正确率Categorical Accuracy: 对多分类问题,计算再所有预测值上的平均正确率Sparse Categorical Accuracy: 与 categorical_accuracy 相同,在对稀疏的目标值预测时有用Top k Categorical Accuracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
也可以自定义评估函数。
以上就是建立深度学习模型的一般流程,其中合适的权重初始化,激活函数,Batch Normalization 用于缓解梯度消失梯度爆炸的问题;选择合适的优化算法和学习率可以加速模型的训练;正则化和 Dropout 可以缓解过拟合问题。
一般情况下我们可以先选择下面这样的配置,然后再根据模型表现进行调优:
权重初始化:He initialization 激活函数:ELU 进行 Batch Normalization 应用 Dropout 选择优化算法:Adam
当然这只是一个基本的流程,还有很多技术会在后面的实战中进行详细解释。
实战中进行详细解释。
一文掌握 TensorFlow 基础
一文掌握 Keras
TensorFlow 2.0 Alpha 实用教程
具有记忆能力的 RNN
LSTM 三重门背后的故事
用多层 RNN 建立语言模型
word2vec:基于层级 softmax 和负采样的 CBOW
word2vec:基于层级 softmax 和负采样的 Skip-Gram
详解 GloVe 的原理和应用
用 word2vec 进行文档分类
详解 GloVe 的原理和应用
LSTM 的几种改进方案
Peephole LSTM, GRU,Beam Search 实战
双向 RNN 识别手写数字
双向 LSTM 实现词性标注
双向 LSTM-CRF 实现命名实体识别
用一个小例子理解 seq2seq 的本质
动手实现 Bahdanau 注意力模型
情感分析 Kaggle 实战
实践:动手搭建聊天机器人
透彻理解神经机器翻译的原理
实践:动手搭建神经机器翻译模型
多复杂的 CNN 都离不开的这几个基本结构
实战:用 CNN 实现句子分类
实战:为图片生成文本摘要
迁移学习基础
什么是 Transformer
详解 BERT
BERT 实战
专栏结语
阅读全文: http://gitbook.cn/gitchat/column/5e031b6a6b195b5f92fdee0d