全文搜索技术
全文搜索
传统的搜索(对数据库的检索),通过主键的查询,效率高,对于实际情况,也会对其他字段进行检索,通常模糊匹配:例如‘%小米%’ ,首尾端模糊匹配 ,在大量数据的检索中不准确,效率低
倒排索引
倒排索引又称为反向索引,
全文检索:数据索引的创建,数据索引的搜索
首先创建索引,对要搜索的文档进行拆分成单词或者词,来创建索引,与对应的文档编号的id,通过文档id查找文档
lucene
Lucene的简介及使用
Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
官网:http://lucene.apache.org/
什么是全文检索?
全文检索,实现的是全部都搜索,是将每一个词都建立一个索引,指名该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
什么是全文检索? ==> 全部都搜索 ==> 如何实现全部都搜索? ==> 分词 单词永不重复 单词就是索引 单词是最小的搜索单位
注意这是一个检索的思想:对文档(数据)中每一个词都做索引。
搭建检索test的环境。
目录结构:一个普通的不能再普通的maven项目结构

导入依赖

pom文件 依赖
<dependencies>
<!-- Junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.2</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.10.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
测试项目搭建完成,进行测试
测试代码
package cn.lucene.test;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import java.io.File;
import java.io.IOException;
public class LuceneTest {
@Test
public void indexCreate() throws IOException {
//创建文档对象
Document document = new Document();
//添加字段:参数Field是一个接口,要呢哇实现类对象(StringField,TextField)
//StringFile的实列化需要3个参数: 字段名 , 字段值 ,是否保存文档 Store.YES/Store.NO
document.add(new StringField("id","1", Field.Store.YES));
//TextField;创建索引并提供分词,----StringField创建索引但不分词
document.add(new TextField("title", "tg_锅锅是个程序员", Field.Store.YES));
//-----------------------------------------------------------------------------------
//创建,目录对象,指定索引库存放的位置:FSDirectory文件系统:RAMDirectory
FSDirectory directory = FSDirectory.open(new File("C:\\tmp\\indexDir"));
//创建分词对象
StandardAnalyzer analyzer = new StandardAnalyzer();
//创建索引写入配置对象,第一个参数版本VerSion.LATEST,第一个参数分词器
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST,analyzer);
//-------创建索引写入器 ,参数(目录对象,索引写入器配置对象)
//-------根据索引写入器的配置,写入索引到指定的目录中
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 向索引库写入文档对象
indexWriter.addDocument(document);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
}
}
补充:IndexWriter是索引写入器 ,是核心对象 需要传入两个参数 1.目录对象,2.索引写入器配置对象
根据这两个参数去写其他的代码一步一步往上推
测试结果:
 用Lucene索引查看工具,直观看分词:
用Lucene索引查看工具,直观看分词:

介绍一下Lucene的Document(文档类)
Document:文档对象,是一条原始数据
文档编号 文档内容
1 tg_锅锅是个程序员
2 tg_锅锅是程序员中的一个奇葩
3 tg_锅锅的程序员之路
一条记录就是一个Document,在测试代码中 document.add(new TextField(“title”, “tg_锅锅是个程序员”, Field.Store.YES));就是一条记录
文档编号 ,文档内容 是Document的两个字段,每一个字段就是是一个Field
字段类:
一个Document中可以有很多个不同的字段,每一个字段都是一个Field类的对象。
一个Document中的字段其类型是不确定的,因此Field类就提供了各种不同的子类,来对应这些不同类型的字段。

1)创建索引
DoubleField、FloatField、IntField、LongField、StringField、TextField这些子类一定会被创建索引。但是不一定会被存储到文档列表。要通过构造函数中的参数Store来指定:如果Store.YES代表存储,Store.NO代表不存储
2)创建索引,又会分词
TextField即创建索引,又会被分词。StringField等会创建索引,但是不会被分词。
如果不分词,会造成整个字段作为一个词条,除非用户完全匹配,否则搜索不到
3)是否存储
StoreField一定会被存储,但是一定不创建索引,StoredField可以创建各种数据类型的字段:
4)文件系统
FSDirectory:文件系统目录,会把索引库保存到本地磁盘。
特点:速度略慢,但是比较安全
RAMDirectory:内存目录,会把索引库保存在内存。
特点:速度快,但是不安全
noSQL:not only sql
Mongodb
Redis
IK分词器
官网:https://code.google.com/p/ik-analyzer/
致敬齐保元锅锅
基本使用
入IK分词器的依赖:
<!-- 引入IK分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
修改代码
//将上述lunece测试代码中的分词器改为IK分词器
IKAnalyzer ikAnalyzer = new IKAnalyzer();
测试结果:
 IK分词器比开始用的分词器更适合给中文分词,对比一下:
IK分词器比开始用的分词器更适合给中文分词,对比一下:
StandardAnalyzer analyzer = new StandardAnalyzer();将中文每一个字都分成一个词条。
IKAnalyzer ikAnalyzer = new IKAnalyzer();将中文的词组或者成语分成一个词条,且效率更高。
有些词IK也不能分出来 例如:锅锅
可以更改仓库中的IKAnalyzer.cfg.xml文件
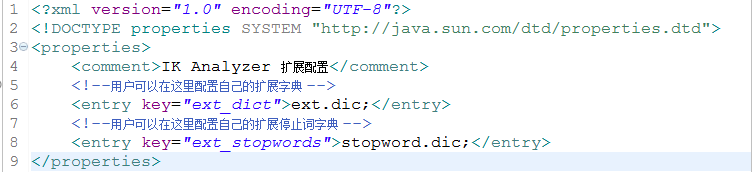
加载扩展词典:
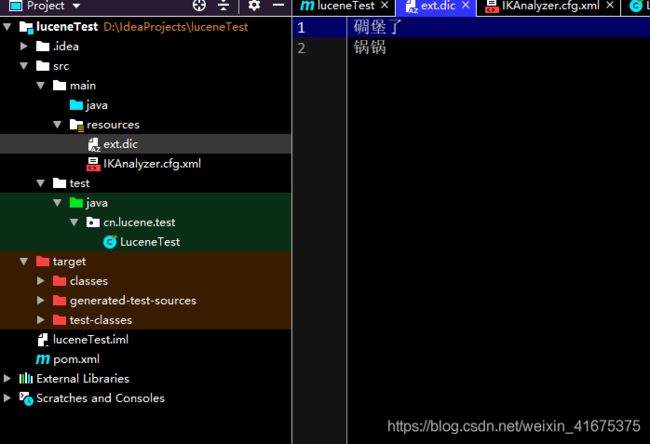
创建配置文件: IKAnalyzer.cfg.xml 依赖仓库中有,ext.dic是扩展词典
执行结果:

查询索引数据
@Test
public void testSearcher() throws IOException, ParseException{
// 初始化索引库对象
Directory directory = FSDirectory.open(new File("C:\\tmp\\index"));
// 索引读取工具
IndexReader indexReader = DirectoryReader.open(directory);
// 索引搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 创建查询解析器对象
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("锅锅");
// 执行搜索操作,返回值topDocs包含命中数,得分文档
TopDocs topDocs = indexSearcher.search(query, Integer.MAX_VALUE);
// 打印命中数
System.out.println("一共命中:"+topDocs.totalHits+"条数据");
// 获得得分文档数组对象,得分文档对象包含得分和文档编号
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("得分:"+scoreDoc.score);
// 文档的编号
int doc = scoreDoc.doc;
System.out.println("编号:"+doc);
// 获取文档对象,通过索引读取工具
Document document = indexReader.document(doc);
System.out.println("id:"+document.get("id"));
System.out.println("title:"+document.get("title"));
}
}
注意: IndexSearcher对象是 核心对象,围绕这个对象写代码
3.3.3、特殊查询
抽取公用的搜索方法:
//抽取公用的搜索方法:
public void search(Query query) throws Exception {
// 创建目录对象
Directory directory = FSDirectory.open(new File("C:\\tmp\\indexDir"));
// 索引的读取对象
IndexReader indexReader = DirectoryReader.open(directory);
// 索引的搜索工具
IndexSearcher searcher = new IndexSearcher(indexReader);
// 尝试查询,1-查询对象,2-查询的条数
// 返回的是前n条文档的对象,topDocs:包含文档的总条数,文档的得分数组
TopDocs topDocs = searcher.search(query, 10);
System.out.println("搜索的命中总条数:" + topDocs.totalHits);
// 获取得分文档的数组,得分文档包含文档编号以及得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("文档编号" + scoreDoc.doc);
System.out.println("文档得分" + scoreDoc.score);
// 根据编号查询文档
Document document = indexReader.document(scoreDoc.doc);
System.out.println(document.get("id"));
System.out.println(document.get("title"));
}
}
// TermQuery(词条查询)
/**
* 词条查询
* 查询条件必须是最小粒度不可再分割的内容
* 场景:不可分割的字段可以采用,比如id
* 缺点:只能查询一个词,例如可以查询"谷歌",不能查询"谷歌地图"
* @throws IOException
* @throws ParseException
*/
@Test
public void testTermSearcher() throws IOException, ParseException{
// 创建查询对象
Query query = new TermQuery(new Term("title", "谷歌"));
// 执行搜索操作
searcher(query);
}
//WildcardQuery(通配符查询)
@Test
public void testWildCardQuery() throws Exception {
// 查询条件对象(通配符
// ?:通配一个字符
// *:通配多个字符
Query query = new WildcardQuery(new Term("title", "*歌*"));
search(query);
}
//FuzzyQuery(模糊查询)
@Test
public void testFuzzyQuery() throws Exception {
// 查询条件对象(模糊查询
// 参数:1-词条,查询字段及关键词,关键词允许写错;2-允许写错的最大编辑距离,并且不能大于2(0~2)
// 最大编辑距离:facebool-->facebook需要编辑的次数,包括大小写
Query query = new FuzzyQuery(new Term("title", "facebook"), 1);
search(query);
}
//NumericRangeQuery(数值范围查询)
@Test
public void testNumericRangeQuery() throws Exception {
// 查询条件对象(数值范围查询
// 查询非String类型的数据或者说是一些继承Numeric类的对象的查询
// 1-字段;2-最小值;3-最大值;4-是否包含最小值;5-是否包含最大值
Query query = NumericRangeQuery.newLongRange("id", 2l, 4l, true, true);
search(query);
}
//BooleanQuery(组合查询)
@Test
public void testBooleanQuery() throws Exception {
Query query1 = NumericRangeQuery.newLongRange("id", 2l, 4l, true, true);
Query query2 = NumericRangeQuery.newLongRange("id", 0l, 3l, true, true);
// boolean查询本身没有查询条件,它可以组合其他查询
BooleanQuery query = new BooleanQuery();
// 交集: Occur.MUST + Occur.MUST
// 并集:Occur.SHOULD + Occur.SHOULD
// 非:Occur.MUST_NOT
query.add(query1, Occur.SHOULD);
query.add(query2, Occur.SHOULD);
search(query);
}
排序,分页 ,修改索引,高亮的操作代码 如下:
/**
* 修改索引 修改的原理:先删除根据条件查询的所有的结果,然后在添加一个新的文档对象Document
* @throws IOException
*/
@Test
public void updateIndex() throws IOException{
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File(INDEX_PATH)), conf);
Term term = new Term("content", "tg_锅锅");
Document doc = new Document();
LongField id = new LongField("id", 30L, Store.YES);
doc.add(id);
TextField title = new TextField("title", "tg_锅锅跳槽FaceBook", Store.YES);
doc.add(title);
TextField content = new TextField("content", "tg_锅锅是未来的社会栋梁", Store.YES);
doc.add(content);
// 根据指定的词条进行搜索,所有与词条匹配的内容会被指定的doc覆盖
indexWriter.updateDocument(term, doc);
indexWriter.commit();
indexWriter.close();
}
/**
* 删除索引
* @throws IOException
*/
@Test
public void deleteIndex() throws IOException{
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File(INDEX_PATH)), conf);
//根据指定的词条进行删除
// indexWriter.deleteDocuments(new Term("content","linux"));
indexWriter.deleteAll();
//删除所有
indexWriter.commit();
indexWriter.close();
}
/**
* 高亮查询 : 高亮就是搜索的参数(关键词高亮显示)
* @throws InvalidTokenOffsetsException
*/
@Test
public void searchhighlighter() throws IOException, ParseException, InvalidTokenOffsetsException{
//查询解析器对象 构造参数:1.搜索的目标字段名称 2.使用何种分词器对搜索的参数进行分析
// QueryParser queryParser = new QueryParser("content", new IKAnalyzer());
//同时查询多字段的查询解析器
MultiFieldQueryParser parser = new MultiFieldQueryParser(new String[]{"id","content"}, new IKAnalyzer());
// 对搜索的参数进行解析 解析后得到Query对象
Query query = parser.parse("tg_锅锅在哪里?");
DirectoryReader reader = DirectoryReader.open(FSDirectory.open(new File(INDEX_PATH)));
//创建索引查询对象
IndexSearcher indexSearcher = new IndexSearcher(reader);
Formatter formatter = new SimpleHTMLFormatter("", "");
Scorer fragmentScorer = new QueryScorer(query);
//创建高亮显示处理对象
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
//topDocs:排名前 n 的结果集
TopDocs topDocs = indexSearcher.search(query, Integer.MAX_VALUE);
//得分文档集合
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc sd : scoreDocs){
Integer docID = sd.doc;
Document document = indexSearcher.doc(docID);
System.out.println(sd.score);
System.out.println("搜索到的结果集id = " + document.get("id"));
System.out.println("搜索到的结果集title = " + document.get("title"));
String content = document.get("content");
//对结果集进行高亮处理
String highlighterContent = highlighter.getBestFragment(new IKAnalyzer(), "content", content);
System.out.println("搜索到的结果集content = " + highlighterContent);
}
indexSearcher.getIndexReader().close();
}
/**
* 对搜索的结果集进行排序
* @throws IOException
* @throws ParseException
*/
@Test
public void sortSearch() throws IOException, ParseException{
DirectoryReader reader = DirectoryReader.open(FSDirectory.open(new File(INDEX_PATH)));
//创建索引查询对象
IndexSearcher indexSearcher = new IndexSearcher(reader);
org.apache.lucene.queryparser.classic.QueryParser parser = new org.apache.lucene.queryparser.classic.QueryParser("content", new IKAnalyzer());
Query query = parser.parse("linux的优秀的操作系统");
// SortField 指定排序字段
//指定字段类型 指定使用的排序规则 false(升序) ,true(降序)
Sort sort = new Sort(new SortField("id", Type.LONG,true));
//topDocs:排名前 n 的结果集
TopDocs topDocs = indexSearcher.search(query, 30, sort);
//得分文档集合
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc sd : scoreDocs){
Integer docID = sd.doc;
Document document = indexSearcher.doc(docID);
System.out.println("文档的得分:"+sd.score);
System.out.println("搜索到的结果集id = " + document.get("id"));
System.out.println("搜索到的结果集title = " + document.get("title"));
System.out.println("搜索到的结果集content = " + document.get("content"));
}
indexSearcher.getIndexReader().close();
}
/**
* 分页查询 并根据id降序排列
* @throws IOException
* @throws ParseException
*/
@Test
public void pageSortSearch() throws IOException, ParseException{
int pageNum = 3;
int pageSize = 10;
//起始位置
int start = (pageNum -1)*pageSize;
//结束位置
int end = pageNum * pageSize;
DirectoryReader reader = DirectoryReader.open(FSDirectory.open(new File(INDEX_PATH)));
//创建索引查询对象
IndexSearcher indexSearcher = new IndexSearcher(reader);
org.apache.lucene.queryparser.classic.QueryParser parser = new org.apache.lucene.queryparser.classic.QueryParser("content", new IKAnalyzer());
Query query = parser.parse("linux的优秀的操作系统");
// SortField 指定排序字段 指定字段类型 指定使用的排序规则 false(升序) ,true(降序)
Sort sort = new Sort(new SortField("id", Type.LONG,true));
//topDocs:排名前 n 的结果集
TopDocs topDocs = indexSearcher.search(query, end, sort);
//得分文档集合
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(int i=start ; i<scoreDocs.length;i++){
ScoreDoc sd = scoreDocs[i];
Integer docID = sd.doc;
Document document = indexSearcher.doc(docID);
System.out.println("文档的得分:"+sd.score);
System.out.println("搜索到的结果集id = " + document.get("id"));
System.out.println("搜索到的结果集title = " + document.get("title"));
System.out.println("搜索到的结果集content = " + document.get("content"));
}
indexSearcher.getIndexReader().close();
}