spark11 sparkStreming
目录
- 架构
- DStream
- 依赖
- 无状态转化操作算子
- wordcount解析
- 有状态转化操作
- updateStateByKey
- 为什么使用updateStateByKey
- wordcount解析
- 窗口算子
- 为什么使用窗口函数
- window
- countByWindow
- countByValueAndWindow
- reduceByWindow
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
- transform
- 为什么用transform
- join操作
- DStream输出
- sparkStreaming在实时分析数据的过程常用api
sparkStreaming实时性不如storm,但是吞吐量要大得多
架构
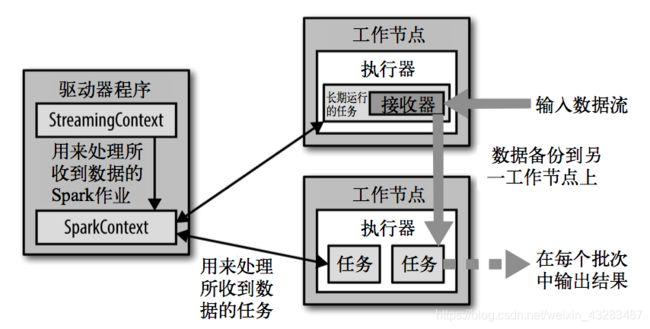
DStream
DStream还有DStream里面的元素,其实和rdd还有rdd里面的元素差不多
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
无状态转化操作算子
就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD
也就是说每隔一段时间都会有数据进来,但是不同时间段互不影响
每个DStream在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。例如,reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。 在下面的wordcount程序中,我们只会统计5秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个DStream间整合数据,不过也是在各个时间区间内。例如,键 值对DStream拥有和RDD一样的与连接相关的转化操作,也就是cogroup()、join()、leftOuterJoin() 、union等。我们可以在DStream上使用这些操作,这样就对每个批次分别执行了对应的RDD操作。
wordcount解析
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("Streaming-WordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
//要在虚拟机上敲命令nc -lk 9999
//会打开一个端口,你可以在linux控制台输入内容
val lineStream = ssc.socketTextStream("192.168.199.100",9999)
val wordAndCountRdd = lineStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wordAndCountRdd.print()
ssc.start()
ssc.awaitTermination()
}
}
先输入hello hht,再隔5秒输入hello nick,发现他们互不影响的
-------------------------------------------
Time: 1592224880000 ms
-------------------------------------------
(hht,1)
(hello,1)
-------------------------------------------
Time: 1592224885000 ms
-------------------------------------------
(hello,1)
(nick,1)
有以下几个算子

//foreachRDD 每个元素都是rdd
// foreachPartition 搭配foreachRDD使用,一般对分区的一个元素和items操作,一般用来数据库操作
key2CountDStream.foreachRDD(
rdd =>
rdd.foreachPartition {
items =>
val statArray = new ArrayBuffer[AdStat]()
for (item <- items) {
val keySplited: Array[String] = item._1.split("_")
val date = keySplited(0)
val province = keySplited(1)
val city = keySplited(2)
val adid = keySplited(3).toLong
val clickCount = item._2
statArray += AdStat(date, province, city, adid, clickCount)
}
AdStatDAO.insertOrUpdateBatch(statArray.toArray)
}
)
有状态转化操作
无状态其实就是每个时间段的数据互不影响
但是这个时间段的数据之前的怎么办,有状态算子会作用到从采集开始到当前时间的所有数据
也就是把多个采集周期集合起来当做一个窗口
updateStateByKey
你想要操作历史的数据的状态
那你就要保存历史数据的状态,那怎么保存呢,内存是可以的,但是文件更加安全
所以updateStateByKey一定要设置检查点
为什么使用updateStateByKey
主要是从程序开始的数据到当前的数据都需要,比如统计数据
需要统计所有的数据,不能之前的批次的数据就丢了吧,只统计这5秒的数据的话意义也不大
wordcount解析
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]) {
// 定义更新状态方法,参数values为当前批次单词频度,state为以往批次单词频度,第一批次的以往是null,所以用getOrElse
val updateFunc = (seq: Seq[Int], state: Option[Int]) => {
val currentCount = seq.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val sparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("Streaming-WordCount")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("hdfs://192.168.199.100:9000/streamCheck")
val lines = ssc.socketTextStream("192.168.199.100", 9999)
val pairs: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map(word => (word, 1))
val stateDstream: DStream[(String, Int)] = pairs.updateStateByKey {
case (seq, buffer) => {
val sum = buffer.getOrElse(0) + seq.sum
Option(sum)
}
}
//我们把上个操作优化一下,抽取出来一个函数
val stateDstream = pairs.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
[atguigu@hadoop102 kafka]$ nc -lk 9999
ni shi shui
等待5秒再输入
ni hao ma
-------------------------------------------
Time: 1504685181000 ms
-------------------------------------------
(shi,1)
(shui,1)
(ni,1)
-------------------------------------------
Time: 1504685187000 ms
-------------------------------------------
(shi,1)
(ma,1)
(hao,1)
(shui,1)
(ni,2)
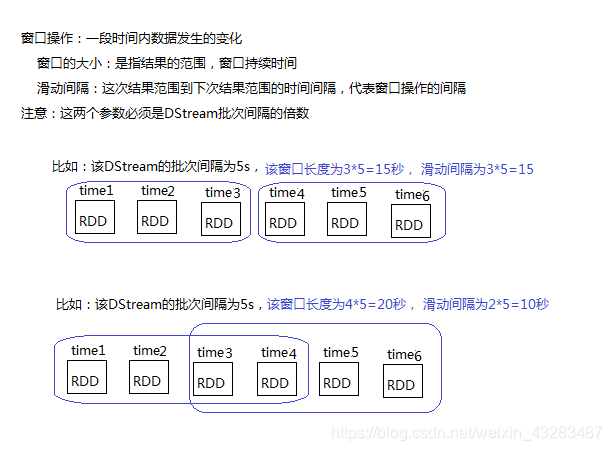
窗口算子
3个概念
- 批次间隔
创建StreamingContext设置,获取数据的时间间隔 - 窗口时长
DStream批次间隔的倍数
如果窗口长度小于滑动步长间隔,会导致丢失数据 - 滑动步长
也是DStream批次间隔的倍数
如果滑动时间间隔过小,会导致数据重复度会高
C:\Users\ITO-user>nc -l -p 9999
a
a b
等5s再发
a b a
为什么使用窗口函数
就是想要一个窗口的数据
比如统计最近一小时的广告点击量,其实就是统计这个窗口大小为1个小时的数据
window
基于对源DStream窗化的批次进行计算返回一个新的Dstream,这个Dstream是包含这个整个窗口的
val window: DStream[String] = lines.window(Seconds(10),Seconds(5))
window.print()
Time: 1592369140000 ms
-------------------------------------------
a
a b
-------------------------------------------
Time: 1592369145000 ms
-------------------------------------------
a
a b
a b a
-------------------------------------------
Time: 1592369150000 ms
-------------------------------------------
a b a
-------------------------------------------
Time: 1592369155000 ms
-------------------------------------------
countByWindow
和rdd的count效果基本一样,但是他是作用在每个窗口上
返回一个滑动窗口中包含元素的个数
这个窗口内有个DStream
flatMap切分的是DStream,其实和rdd有点类似的
必须设置检查点
val word = lines.flatMap(_.split(" "))
val countByWindow: DStream[Long] = word .countByWindow(Seconds(10),Seconds(5))
countByWindow.print()
-------------------------------------------
Time: 1592369725000 ms
-------------------------------------------
3
-------------------------------------------
Time: 1592369730000 ms
-------------------------------------------
6
-------------------------------------------
Time: 1592369735000 ms
-------------------------------------------
3
-------------------------------------------
Time: 1592369740000 ms
-------------------------------------------
0
countByValueAndWindow
和countByValue差不多,只不过也是作用在每个窗口上
k-v结构不可以调用这个函数
k结构调用返回k-v(v是对每个k统计的个数)结构
可配置reduce任务数量。
必须设置检查点
val word = lines.flatMap(_.split(" "))
val countByValueAndWindow: DStream[(String, Long)] = word.countByValueAndWindow(Seconds(10), Seconds(5))
countByValueAndWindow.print()
-------------------------------------------
Time: 1592369910000 ms
-------------------------------------------
(b,1)
(a,2)
-------------------------------------------
Time: 1592369915000 ms
-------------------------------------------
(b,2)
(a,3)
(c,1)
-------------------------------------------
Time: 1592369920000 ms
-------------------------------------------
(b,1)
(a,1)
(c,1)
-------------------------------------------
Time: 1592369925000 ms
-------------------------------------------
reduceByWindow
和reduce效果差不多的
通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流
val word = lines.flatMap(_.split(" "))
val reduceByWindow = word .reduceByWindow(_ + "*" + _, Seconds(10), Seconds(5))
reduceByWindow.print()
-------------------------------------------
Time: 1592369605000 ms
-------------------------------------------
a*a*b
-------------------------------------------
Time: 1592369610000 ms
-------------------------------------------
a*a*b*a*b*c
-------------------------------------------
Time: 1592369615000 ms
-------------------------------------------
a*b*c
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
和reduceByKey效果差不多的
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。Note:默认情况下,这个操作使用Spark的默认数量并行任务(本地是2),在集群模式中依据配置属性(spark.default.parallelism)来做grouping。你可以通过设置可选参数numTasks来设置不同数量的tasks
val word = lines.flatMap(_.split(" ")).map((_,1))
val reduceByKeyAndWindow: DStream[(String, Int)] = word.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(10), Seconds(5))
reduceByKeyAndWindow.print()
-------------------------------------------
Time: 1592371550000 ms
-------------------------------------------
(b,1)
(a,2)
-------------------------------------------
Time: 1592371555000 ms
-------------------------------------------
(b,2)
(a,3)
(c,1)
-------------------------------------------
Time: 1592371560000 ms
-------------------------------------------
(b,1)
(a,1)
(c,1)
-------------------------------------------
Time: 1592371565000 ms
-------------------------------------------
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
和上面相比,多传入一个函数invFunc。
这个函数是上述函数的更高效版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置
必须设置检查点
val word = lines.flatMap(_.split(" ")).map((_,1))
val reduceByKeyAndWindow: DStream[(String, Int)] = word.reduceByKeyAndWindow((a: Int, b: Int) => (a + b), (a: Int, b: Int) => (a - b),Seconds(10), Seconds(5))
reduceByKeyAndWindow.print()
-------------------------------------------
Time: 1592371690000 ms
-------------------------------------------
(b,1)
(a,2)
-------------------------------------------
Time: 1592371695000 ms
-------------------------------------------
(b,2)
(a,3)
(c,1)
-------------------------------------------
Time: 1592371700000 ms
-------------------------------------------
(b,1)
(a,1)
(c,1)
-------------------------------------------
Time: 1592371705000 ms
-------------------------------------------
(b,0)
(a,0)
(c,0)
transform
允许DStream上执行任意的RDD-to-RDD函数
但是其实无状态函数也是可以做到的,那么它和无状态函数区别是什么呢
为什么用transform
- 里面的操作都是rdd,很多算子比如reduceByKey,streaming是没有的,但是我们可以用transform里面去使用更多rdd的算子
- 看下面代码对比
transform函数每一批次调度一次,比如黑名单,那么我肯定要每个批次过来的数据我都要更新,也就是每个批次的数据他都要走一遍这个代码
val a = 1 //代码在driver端运行,只走一遍
lines.map{
case x =>{
val a = 1 //代码在Executor端运行,走n遍
x
}
}
val a = 1 //代码在driver端运行,只走一遍
lines.transform{
case rdd =>{
val a = 1 //代码在driver端运行,但是运行m(采集周期为5秒,那就5秒就走一遍)遍
rdd.map{
case x => {
val a = 1 //代码在Executor端运行,走n遍
x
}
}
}
}
join操作
感觉上和rdd类似的,但是它连接的是不同的DStream
Stream-Stream Joins
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
windows-stream - windows-stream Joins
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
Stream-dataset joins
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
DStream输出
DStream和RDD一样是懒惰的
但是DStream遇到输出算子才会启动,我把它理解rdd遇到action算子才会执行是一样的
| print() | 在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。在Python API中,同样的操作叫print() |
| saveAsTextFiles(prefix, [suffix]) | 以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | 以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用 |
| saveAsHadoopFiles(prefix, [suffix]) | 将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API Python中目前不可用 |
| foreachRDD(func) | 这是最通用的输出操作,即将函数 func 用于产生于 stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。注意:函数func在运行流应用的驱动中被执行,同时其中一般函数RDD操作从而强制其对于流RDD的运算 |
通用的输出操作foreachRDD(),它用来对DStream中的RDD运行任意计算。这和transform() 有些类似,都可以让我们访问任意RDD。在foreachRDD()中,可以重用我们在Spark中实现的所有行动操作
常见的用例之一是把数据写到诸如MySQL的外部数据库中。
注意:
(1)连接不能写在driver层面,定义到driver,数据库链接不饿能序列化,在Executor不能执行;
(2)如果写在foreach则每个RDD都创建,得不偿失;
(3)增加foreachPartition,在分区创建。
orderInfoDstream.foreachRDD{rdd=>
rdd.foreachPartition{orderItr=>
MyEsUtil.indexBulk(GmallConstant.ES_INDEX_ORDER,orderItr.toList)
}
}
sparkStreaming在实时分析数据的过程常用api
checkpoint 一般Streaming都会设置检查点
KafkaUtils.createDirectStream 从kafka获取数据并返回DFrame
transform
updateStateByKey 相对于不同批次进行进行聚合
foreachRDD
tuples.reduceByKeyAndWindow((x: Int, y: Int) => (x + y), Seconds(10), Seconds(10))
start 提交
awaitTermination 等待处理下批次任务