lucene读取索引文件到内存-源码解析
1.抛出问题:
lucene索引保存在倒排表文件中,那么lucene是如何将这些索引数据读取到内存中的呢?
2.环境说明:
首先需要说明下我的源码环境:我用的是lucene4,然后codec用的是SimpleTextCodec,这个codec的作用是格式化索引,把“黑箱”的索引格式转化成我们可以看得懂的格式,比如,用了SimpleTextCodec以后,我的倒排表文件的后缀是".pst",然后具体的索引内容如图: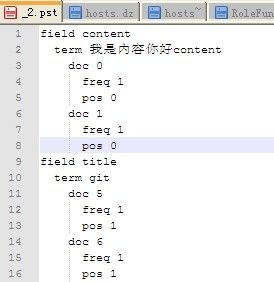 ;解释下,我索引了一个文档,有两个域:content和title,其他的相信你肯定能看懂是什么意思。
;解释下,我索引了一个文档,有两个域:content和title,其他的相信你肯定能看懂是什么意思。
3.lucene读取索引源码解析
启动搜索后,第一次搜索会比较慢!这个是lucene自己说的,而且事实也是如此,相信没人会怀疑,但是为什么会这样呢?就是因为第一次搜索的时候需要将索引从文件读入内存!
具体的过程如下:还是以上图表示的索引来说明,这份索引有两个域:content和title,如果现在我只搜索title域,用代码表示类似:

当我们第一次调用search方法的时候,内部会有个loadTerms()方法,就是这个方法用来读取索引文件的,具体源代码如图:
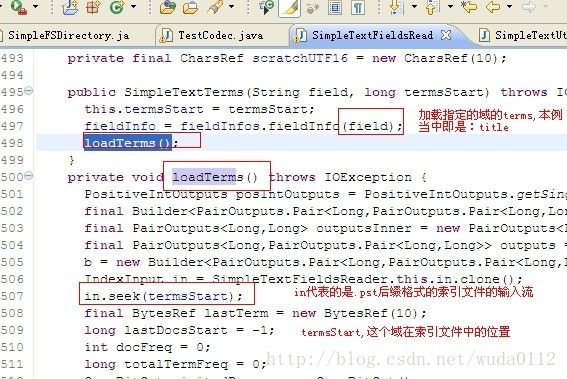
这里需要注意的是:不是加载所有的索引,而是加载搜索指定的域,因此我上面特别指定了只搜索title域。好了,想想lucene读取索引文件内容到内存需要的几个东西,
1.索引文件,即图中的“in”输入流,这个是已知的,因为在初始化的时候就需要指定索引目录;
2."field",即域名,这个也是已知的,因为搜索的时候必须指定,
3.termsStart,这个就是“未知”的了,我们怎么知道哪个域在索引文件的哪个位置呢?这个值肯定是有的,具体方法的源码如图:
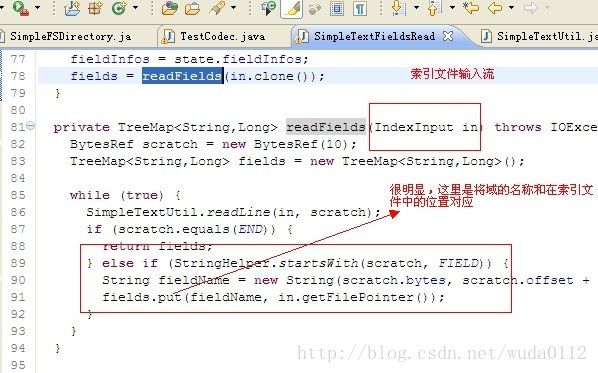
显然,在loadTerms()方法之前,就预先将域名和此域在文件中的位置处理了,在调用loadTerms()方法时,只需
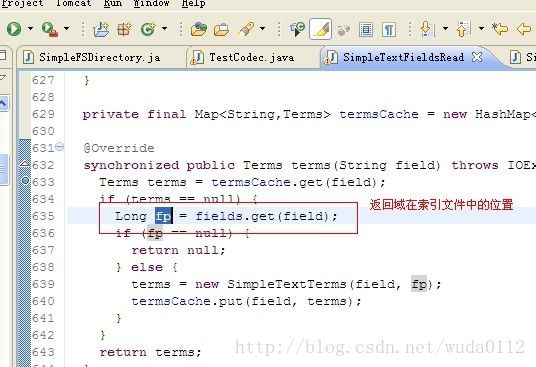
在缓存中获取这个位置,这里的fp从字母意思就可以知道是field position的缩写。
接下来估计你也知道了,完全就是文件I/O操作了,源码如图:
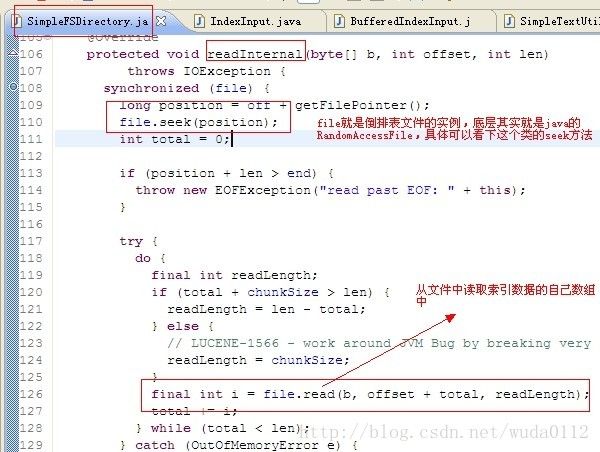
(上图的“自己”写错了,是字节)从索引文件中不断的读取字节数组,直到将这个域的所有terms读取完。
好了,以上就是lucene读取索引文件到内存的概要过程,注意这里我只是关注概要过程,有很多细节是没有关注的!而且源码的截图是不完整的,但是却能说明问题。