Kettle与Hadoop(四)导入导出Hadoop集群数据
目录
一、向Hadoop集群导入数据(Hadoop copy files)
1. 向HDFS导入数据
2. 向Hive导入数据
二、从Hadoop集群抽取数据
1. 把数据从HDFS抽取到RDBMS
2. 把数据从Hive抽取到RDBMS
参考:
一、向Hadoop集群导入数据(Hadoop copy files)
1. 向HDFS导入数据
- 从下面的地址下载web日志示例文件,解压缩后的weblogs_rebuild.txt文件放到/root/big_data目录下。
http://wiki.pentaho.com/download/attachments/23530622/weblogs_rebuild.txt.zip?version=1&modificationDate=1327069200000
- 建立一个作业,把文件导入HDFS中。
(1)打开PDI,新建一个作业,如图1所示。
 图1
图1
(2)编辑'Hadoop Copy Files'作业项,如图2所示。
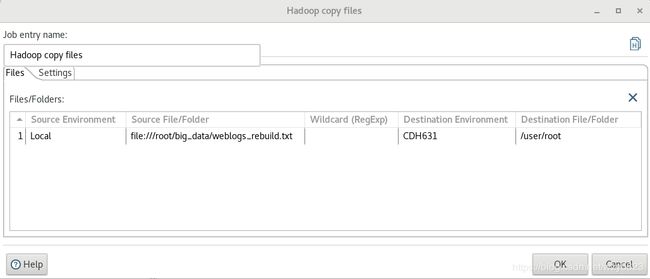 图2
图2
说明:CDH631是已经建立好的Hadoop Clusters对象,建立过程参见https://wxy0327.blog.csdn.net/article/details/106406702#%E4%BA%8C%E3%80%81%E8%BF%9E%E6%8E%A5Hadoop%E9%9B%86%E7%BE%A4。
(3)保存并执行作业,日志如图3所示。
 图3
图3
从图3可以看到,作业已经成功执行。
(4)检查HDFS,结果如图4所示。
 图4
图4
从图4可以看到,weblogs_rebuild.txt已经传到了HDFS的/root/big_data目录下。
2. 向Hive导入数据
- 从下面的地址下载web日志示例文件,解压缩后的weblogs_parse.txt文件放到Hadoop的/user/grid/目录下。
http://wiki.pentaho.com/download/attachments/23530622/weblogs_parse.txt.zip?version=1&modificationDate=1327068013000
- 建立一个作业,将文件导入到hive表中。
(1)执行下面的HSQL建立一个hive表,表结构与weblogs_parse.txt文件的结构相同。
create table test.weblogs (
client_ip string,
full_request_date string,
day string,
month string,
month_num int,
year string,
hour string,
minute string,
second string,
timezone string,
http_verb string,
uri string,
http_status_code string,
bytes_returned string,
referrer string,
user_agent string)
row format delimited fields terminated by '\t';(2)打开PDI,新建一个作业,如图1所示。
(3)编辑'Hadoop Copy Files'作业项,如图5所示。
 图5
图5
(4)保存并执行作业,日志如图6所示。
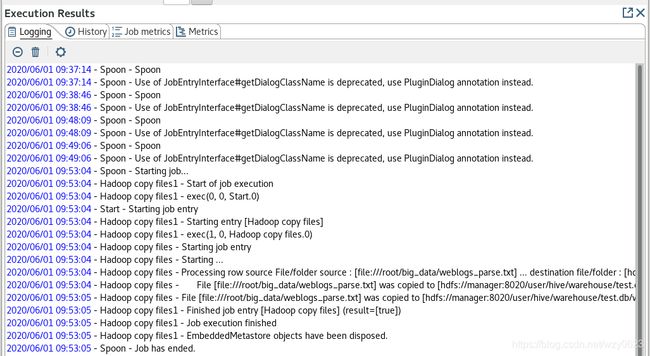 图6
图6
从图6可以看到,作业已经成功执行。
(5)查询test.weblogs表,结果如图7所示。
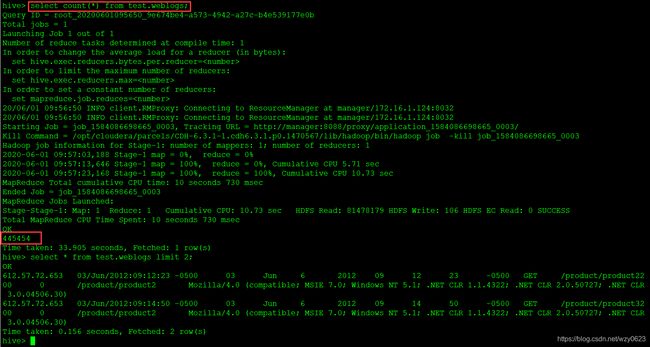 图7
图7
从图7可以看到,向test.weblogs表中导入了445454条数据。
二、从Hadoop集群抽取数据
1. 把数据从HDFS抽取到RDBMS
(1)从下面的地址下载示例文件。
http://wiki.pentaho.com/download/attachments/23530622/weblogs_aggregate.txt.zip?version=1&modificationDate=1327067858000
(2)用hdfs用户执行下面的命令,把解压缩后的weblogs_aggregate.txt文件放到HDFS的/user/root/目录下,并修改读写权限。
hdfs dfs -put -f /root/weblogs_aggregate.txt /user/root/
hdfs dfs -chmod -R 777 /(3)打开PDI,新建一个转换,如图8所示。
 图8
图8
(4)编辑'Hadoop File Input'步骤,如图9到图11所示。
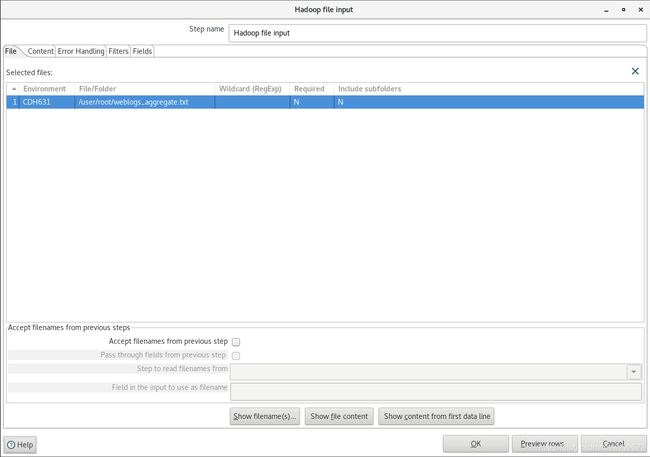 图9
图9
 图10
图10
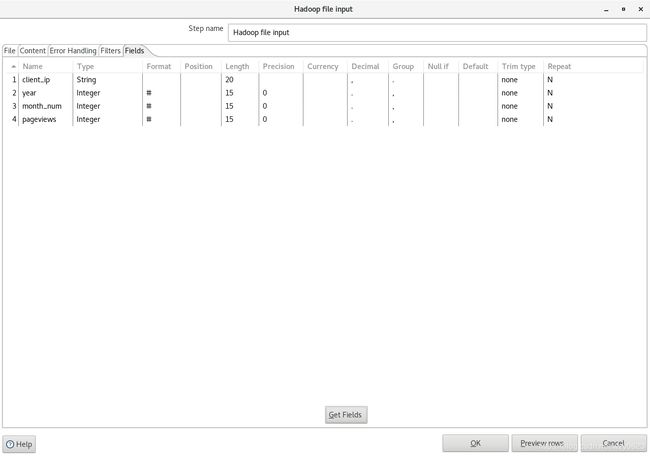 图11
图11
说明:在“File”标签指定Hadoop集群和要抽取的HDFS文件;在“Content”标签指定文件的属性,以TAB作为字段分隔符;在“Fields”指定字段属性。
(5)编辑'Table Output'步骤,如图12所示。
 图12
图12
说明:
- mysql_node3是已经建好的一个本地数据库连接,参见https://wxy0327.blog.csdn.net/article/details/106406702#%E4%BA%94%E3%80%81%E5%90%8E%E7%BB%AD%EF%BC%88%E5%BB%BA%E7%AB%8BMySQL%E6%95%B0%E6%8D%AE%E5%BA%93%E8%BF%9E%E6%8E%A5%EF%BC%89。
- “Database fields”标签不需要设置。
(6)执行下面的脚本建立mysql的表。
use test;
create table aggregate_hdfs (
client_ip varchar(15),
year smallint,
month_num tinyint,
pageviews bigint
);(7)保存并执行转换,日志如图13所示。
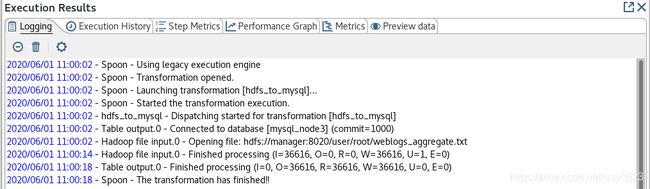 图13
图13
从图13可以看到,转换已经成功执行。
(8)查询mysql表,结果如图14所示。
 图14
图14
从图14可以看到,数据已经从HDFS抽取到了mysql表中。
2. 把数据从Hive抽取到RDBMS
(1)执行下面的脚本建立mysql的表
use test;
create table aggregate_hive (
client_ip varchar(15),
year varchar(4),
month varchar(10),
month_num tinyint,
pageviews bigint
);(2)打开PDI,新建一个转换,如图15所示。
 图15
图15
(3)编辑'Table input'步骤,如图16所示。
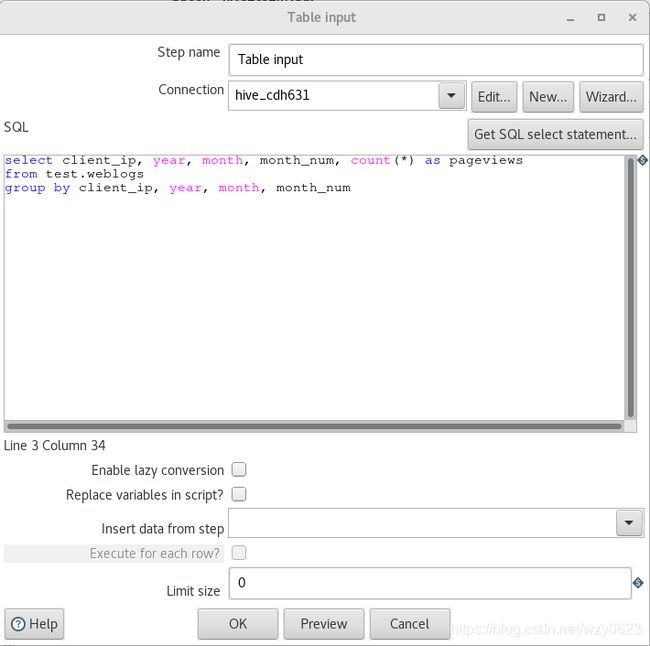 图16
图16
说明:hive_cdh631是已经建好的一个hive数据库连接,参见https://wxy0327.blog.csdn.net/article/details/106406702#%E4%B8%89%E3%80%81%E8%BF%9E%E6%8E%A5Hive。
(4)编辑'Table output'步骤,如图17所示。
 图17
图17
说明:mysql_node3是已经建好的一个本地数据库连接;“Database fields”标签不需要设置。
(5)保存并执行转换,日志如图18所示。
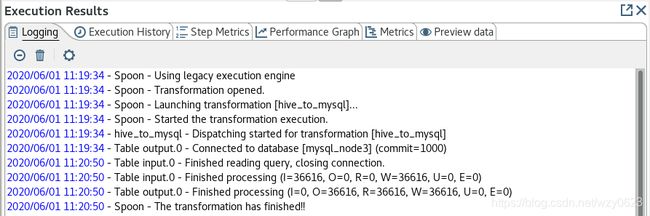 图18
图18
从图18可以看到,转换已经成功执行。
(6)查询mysql表,结果如图19所示。
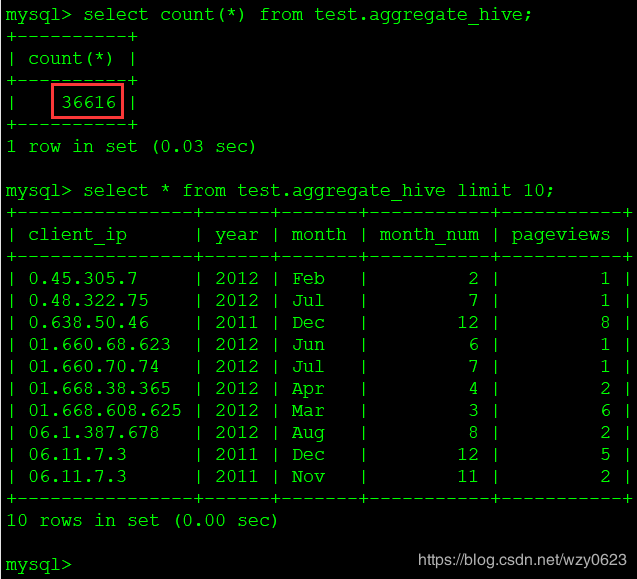 图19
图19
参考:
- http://wiki.pentaho.com/display/BAD/Extracting+Data+from+HDFS+to+Load+an+RDBMS
- http://wiki.pentaho.com/display/BAD/Extracting+Data+from+Hive+to+Load+an+RDBMS