Python 包、模块、类
目录
一、组织结构
二、import导入模块
三、from import 导入变量
四、__init__.py 的用法
五、包与模块的几个常见错误_
六、模块内置变量
七、入口文件和普通模块内置变量的区别
八、 __name__的经典应用
九、 相对导入和绝对导入
一、组织结构
1、Python组织结构的意义:
在相对复杂的项目下,便于管理,便于维护,便于复用。
2、组织结构:
包(可以理解为文件夹)--模块(.py文件)--类(class:包括函数、变量。函数变量算作类里的具体组成部分,类的特性)
函数变量可以直接写在模块里面,但是不建议,最好用类把函数变量组织起来

二、import导入模块
1、import 模块名注意:
- 使用模块前请先导入后使用;
- 使用导入模块中的变量或函数的格式:模块名.变量或函数。
2、如果结构不同层级,要用命名空间解决。
# t为文件夹,也就是包,c7为模块 ,a为变量
import t.c7
print(t.c7.a)3、import 模块名 as 名称
此语法可以解决命名空间过长问题。
## t为文件夹,也就是包,c7为模块 ,a为变量,此处相当于将m变为t.c7
import t.c7 as m
print(m.a)三、from import 导入变量
1、导入变量:
- from module import a ,def
- 调用 a 的时候不需要命名空间(module.a)
2、 * 表示导入文件的所有变量,函数
- 可以控制能被引用的函数和变量,利用 __all__(模块的内置变量、内置属性)
- 在模块里定义__all__:
- 这样在from 模块 import * 时,别的模块就只能导入a、c变量(可以强行from 模块 import b 强行导入)
- from import 用法比较灵活 可以从包引入模块
四、__init__.py 的用法
1、代码换行最好用() 也可以在末尾加上反斜杠\
import c7 from(a,b,
c,d)
2、__init__.py 的作用:
- 当包或该包下的模块,变量..被导入时,该文件自动执行。可以用来做包和模块的初始化。
- 可以在__init___.py文件中定义''__all__''变量来定义该包下哪些模块可以被其它模块引用(from 包 import *)。
- 可以利用__init__.py文件做批量导入:在子包的 __init__.py文件里导入需要的模块, 然后在上一级 import 子包名 进行模块的批量导入
注意 ::引用的时候注意命名空间 子包名.def
3、__init__.py文件名 就是包名
五、包与模块的几个常见错误_
1. 包和模块不会被重复导入;
2. 避免循环导入,不管是直接循环还是间接循环。
例如:
1)直接循环:p1.py中导入p2.py的变量,同时p2.py中又导入p1.py的变量。
2)间接循环:p1.py中导入p2.py的变量,p2.py中导入p3.py的变量,p3.py中导入p4.py的变量,p4.py中导入p1.py的变量,形成一个闭环。
解决方法:打开循环,取消最后一个文件的import语句或变为注释
六、模块内置变量
1、dir()函数:返回当前模块的所有变量:
a = 2
b = 3
d = 4
infos = dir()
print(infos)
'''
output:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'd']
'''
2、__name__ : 模块名称,即命名空间
3、__package__ :包名/4、__doc__ :模块注释
4、__file__ :系统层级当前文件的路径
5、traceback是堆栈跟踪,涉及错误的调用路径全部显示出来。
七、入口文件和普通模块内置变量的区别
1、name: __main__
2、package: 作为顶级文件,没有包注意:并不是因为c15所在的文件夹)
3、file:和执行命令所在目录有关,是不确定的值(当终端命令为python t1\c9.py时,file为t1\c9.py;当终端命令为python c9.py时,file为c9.py)
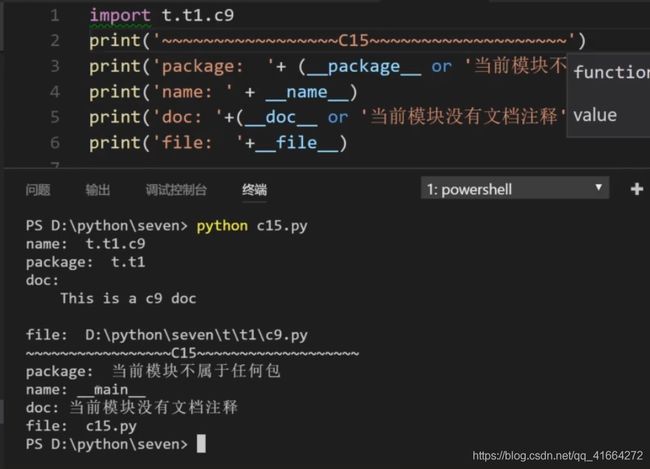
八、 __name__的经典应用
1、dir()函数括号内如果什么都不写,则输出的是当前模块里所有的变量。当需要查看某个函数或类里的变量时,可以使用dir()函数
2、python中的普通模块必须有一个包,当想要把一个可执行文件当作一个普通模块运行时,,可以使用-m参数,如:python -m 命名空间(包).模块名
3、3.if __name__ == '__main__' : pass意思是make a script both importable and executable(让这个脚本既可以作为一个普通的模块被导入到其他模块中,也可以作为可执行模块)
4、作用:判断当前模块是否为入口文件
九、 相对导入和绝对导入
1、顶级包与入口文件main.py(可执行文件)的位置有关,与入口文件main.py同级的包就是该包下所有模块的顶级包。而对于入口文件来说不存在包的概念。
2、绝对导入/绝对路径:从顶级包到被导入模块名称的完整路径。
3、相对导入:一个'.'表示当前包,两个'..'表示上一级包.'...'上上级包,以此类推
注意:
- import不支持相对导入,只能使用from import格式实现相对导入。
- 入口文件中不能使用相对导入,因为它没有包的概念。
- 使用相对导入不要超出顶级包///(入口文件同级都不能使用相对导入,放到包下面去)
- 入口文件可以使用绝对路径导入。但是不可以使用相对路径导入,相对路径能够找到对应模块是根据内置模块变量__name__来定位,入口文件被执行后__name__就不是所谓的模块名而是将被python改成__main__ , __main__ 模块是不存在的,所以不可以使用相对路径导入。如果想用相对导入也是可以的,用模块的形式,返回模块的上一级 python -m demo.main