基本k-mean聚类的文本聚类算法原理和例子
基于质心的划分方法是研究最多的算法,包括k-mean聚类算法及其各种变体,这些变体依据初始簇的选择,对象的划分、相识度的计算方法、簇中心的计算方法不同而不同。基于质心的划分方法将簇中所有对象的平均值看做簇的质心,根据一个数据对象与簇质心的距离,将该对象赋予最近的簇。在这类方法中,需要给定划分的簇个数k,首先得到k个初始划分的集合,然后采用地带重定位技术,通过将对象从一个簇移到另外一个簇来改进划分的质量。
算法:k-mean
输入:数据集D,划分簇的个数k
输出:k个簇的集合
从数据集合D中任意选择k个对象作为初始簇中心;、
Repeat
For 数据集D中每个对象P do
计算对象P到k个簇中心的距离
将对象P指派到与其最近(距离最短)的簇
End for
计算每个簇中心对象的均值,作为新的簇的中心
Until k个簇的簇中心不再发生变化
(1)本例子的样本集合是选择搜狗语料库中的三类文章,每类10篇,如图
(2)对于文本聚类,使用中科院的分词库ICTCLAS,接口封装在split.h和split.cpp中,在分词时,本例子只选用了动词和名词
(3)特征词选取使用tf-idf方法来提取每篇文章的前100个根据tf-idf大小排序的特征词
词频tf(Term Frequency)是指一个词条在一个文本出现的频数。频数越大,则该词语对文本的贡献度越大。其重要可表示为
tf=n/N (n是指单词w在文本Di中出现的次数,Ni是指文本Di中所有词语出现的总数)
逆文本频度idf(Inverse Document Frequency)表示词语在整个文本集中的分布情况,包含该词语的文本数目越少,则idf越大,数目该词语具有较强的类别区别能力。
idf=log2(N/m) (N是文本集合的总个数,m是包含该词语的文本个数)
最后将两者相乘。
算法实现思路是扫描所有的文章,对于每一篇文章都用一个map
/*
统计单词频数和文档频数
*/
void TFIDFMeasure::Statistics(void){
for(vector::iterator it_document=documents.begin();it_document!=documents.end();it_document++){
//读取文档
string content=ReadFile(it_document->name);
vector words;
map tf;
//分词
words=Split::splitToWord(const_cast(content.c_str()));
vector::iterator it_word=words.begin();
vector::iterator it_end_word=words.end();
//记录频数
for(;it_word!=it_end_word;it_word++){
pair< map::iterator,bool> ret =tf.insert(make_pair((*it_word).word,1));
if(!ret.second){
(ret.first->second)++;
}
}
map::iterator it_tf=tf.begin();
map::iterator it_end_tf=tf.end();
int wordsize=0;
for(;it_tf!=it_end_tf;it_tf++){
KeyWord keyword;
keyword.word=it_tf->first;
keyword.fre=it_tf->second;
it_document->words.insert(make_pair(it_tf->first,keyword));
wordsize+=it_tf->second;
//文档数目加1
pair< map::iterator,bool> ret=DocFre.insert(make_pair(it_tf->first,1));
if(!ret.second){
(ret.first->second++);
}
}
//记录文章的总单词数目
it_document->wordSize=wordsize;
}
} /*
将it-idf的前100个作为文档的特征向量如:(坦克:0.32;团长:0.02;...)
*/
void TFIDFMeasure::CalculTFIDF(void){
cout<::iterator it_document=documents.begin();it_document!=documents.end();it_document++){
vector vector_sort;
for(map::iterator it_keyWord=it_document->words.begin();it_keyWord!=it_document->words.end();it_keyWord++){
KeyWord keyword;
keyword.word=it_keyWord->first;
keyword.fre=it_keyWord->second.fre;
map::iterator docfre=DocFre.find(keyword.word);
//计算ifXidf
keyword.TF_IDF=((double)keyword.fre/it_document->wordSize)*log((double)documents.size()/docfre->second)*10;
vector_sort.push_back(keyword);
}
//排序
sort(vector_sort.begin(),vector_sort.end(),sort_keyword);
int size=limited>vector_sort.size()?vector_sort.size():limited;
//提取前100个
double absolute=0.0;
for(int i=0;ifeatrue.insert(make_pair(vector_sort[i].word,vector_sort[i].TF_IDF));
}
it_document->absolute=absolute;
}
cout<<"------"< (4)两篇文章之间的距离,本文使用余弦相似度来计算,将两个向量相乘

//计算其余弦相似度
double KMEAN::CalculCosim(Document &document1,Document &document2){
double sum=0.0,absolute1=0.0,absolute2=0.0;
for(map::iterator it_document1=document1.featrue.begin();it_document1!=document1.featrue.end();it_document1++){
//计算向量绝对值
absolute1+=(it_document1->second*it_document1->second);
}
for(map::iterator it_document2=document2.featrue.begin();it_document2!=document2.featrue.end();it_document2++){
map::iterator it_match=document1.featrue.find(it_document2->first);
if(it_match!=document1.featrue.end()){
sum+=(it_match->second*it_document2->second*10);
}
//计算向量绝对值
absolute2+=(it_document2->second*it_document2->second);
}
//cout<
/*
重新计算该簇的质心向量
*/
void KMEAN::CalculMean(vector &classes){
for(int i=0;i allfeatrue;
for(int j=0;j::iterator it=classes[i].Document[j].featrue.begin();it!=classes[i].Document[j].featrue.end();it++){
pair::iterator,bool> ret=allfeatrue.insert(make_pair(it->first,it->second));
if(!ret.second){
ret.first->second+=it->second;
}
}
}
vector > vector_sort;
for(map::iterator it=allfeatrue.begin();it!=allfeatrue.end();it++){
vector_sort.push_back(make_pair(it->first,it->second));
}
//取前面100个
sort(vector_sort.begin(),vector_sort.end(),cmp_featrue);
int size=limited>vector_sort.size()?vector_sort.size():limited;
int same=0;
for(int k=0;k::iterator it_find=classes[i].featrue.find(vector_sort[k].first);
if(it_find!=classes[i].featrue.end()){
same++;
}
}
cout<<"--------"<
void KMEAN::CalculKmean(int times){
if(times==1){
return ;
}
bool flag=true;
double maxCosValue=0.0;
int maxIndex=0;
for(int i=0;imaxCosValue){
maxCosValue=cosValue;
maxIndex=j;
}
}
//将文章放到对于的簇
myclasses[maxIndex].Document.push_back(documents[i]);
cout< 结果分析
选取
 分别作为3个簇的开始,其中军事使用A表示,汽车使用B表示,财经使用C表示
分别作为3个簇的开始,其中军事使用A表示,汽车使用B表示,财经使用C表示
第一遍递归后的准确率和质心相似率

第二遍递归后
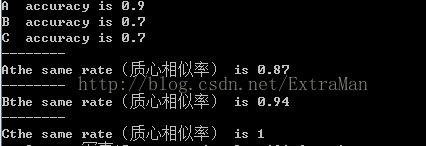
可以看出第二遍后质心相似率达到了90%,准确率也有80%左右,对于该算法还有很多研究的地方,比如初始K的选择,质心的计算方法等,有兴趣的同学可以交流一下。