CVPR 2019 | 国防科大提出双目超分辨算法,效果优异代码已开源
点击我爱计算机视觉标星,更快获取CVML新技术
近年来,双摄像头成像系统在智能手机、自动驾驶等领域取得了广泛的应用。
近日,来自国防科技大学等单位的学者提出了新型双目超分辨算法,充分利用了左右图的信息提升图像超分辨效果;
另外,他们构建了一个大型双目图像超分辨数据集,用于双目图像超分辨算法的训练和评估。代码已开源,相关论文已被CVPR 2019录用。
以下是论文作者信息:

论文链接:
https://arxiv.org/pdf/1903.05784.pdf
代码链接:
https://github.com/LongguangWang/PASSRnet
数据集链接:
https://yingqianwang.github.io/Flickr1024/
引言
双摄系统提供了同一场景两个不同视角的观测信息。然而在实际应用中,由于相机基线、焦距、场景深度以及成像分辨率不同,双目图像的视差具有较大差异。因此如何高效、灵活地利用双摄系统来提升图像的分辨率存在较大的挑战。
本文提出了一种基于视差注意力机制(Parallax Attention Mechanism)的双目图像超分辨网络(Parallax Attention Stereo SR Network, PASSRnet),利用视差注意力机制实现了对双目图像左右图信息的高效融合。
同时本文构建并公开了一个大型双目图像超分辨数据集Flickr1024,用于双目图像超分辨算法的训练和评估。
本文将双目视觉中的对极几何(EPI)关系引入到注意力机制中,计算双目图像不同视差位置间的相似性,并基于这一相似性测度实现对左右图特征的融合。
视差注意力机制能够对双目图像中沿视差方向的全局信息进行融合,不受视差大小的限制,具有更强的灵活性与鲁棒性。
本文所提算法在Middlebury、KITTI2012以及KITTI2015数据集上与主流算法进行了对比,实验结果证明了PASSRnet的优越性。
方法
PASSRnet的网络结构如图1所示,其输入为低分辨率双目RGB图像,输出为高分辨率左视角RGB图像。
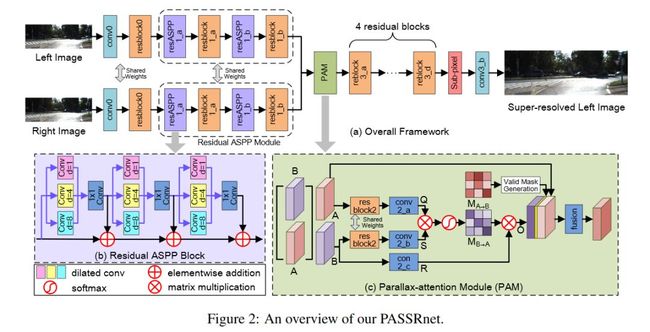
图1 PASSRnet网络结构图
● 残差空洞金字塔模块(Residual ASPP Module)
PASSRnet首先利用一个共享权值的Residual ASPP模块对输入的双目图像进行多尺度特征提取,扩大了网络的接受野。
如图1(a)所示,Residual ASPP模块由残差空洞金字塔块(Residual ASPP Block)与残差块交替连接组成。
如图1(b)所示,Residual ASPP Block由三组空洞卷积组(ASPP Group)组成,在每个ASPP Group中,首先利用三个膨胀系数分别为1、4、8的3*3卷积层进行特征提取,之后利用一个1*1卷积对三个膨胀卷积层提取的特征进行融合。
与ASPP Block相比,Residual ASPP Block利用残差连接进一步丰富了特征提取的尺度,实现了更密集的多尺度特征提取。
● 视差注意力模块(Parallax Attention Module)
在提取双目图像的多尺度特征之后,PASSRnet利用视差注意力模块(Parallax Attention Module)对左右图特征进行融合。受“自注意力机制”启发,本文将双目视觉中的对极几何关系引入注意力机制中,将注意力机制的搜索空间限制在极线上。

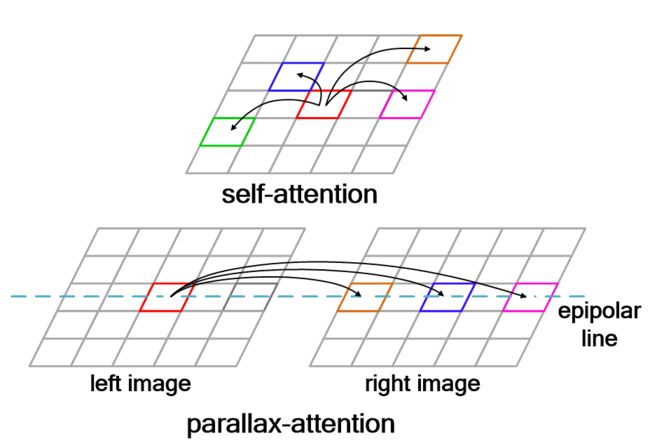
图2 视差注意力与自注意力示意图
如图2所示,与自注意力机制在图像全局范围内进行搜索不同,视差注意力机制只沿着极线方向进行搜索。对于左图中任意一点(i,j),视差注意力机制将其与右图极线上任意一点进行相似性计算,得到视差注意力图。
以Mright->left为例,Mright->left(i,j,k)表示右图中位置(i,k)对左图中位置(i,j)的权值,也就是说,视差注意力图上的权值分布形态能够描述左右图间的对应关系。利用视差注意力图的这一特性,Parallax Attention Module能够通过批次化矩阵乘实现左右图特征的有效融合(如图3所示)。

图3 批次化矩阵乘示意图
● 损失函数(Loss Function)
本文所提PASSRnet在训练中所采用的损失函数为:

其中 设为0.005,各个Loss项的含义如下:
设为0.005,各个Loss项的含义如下:
➢ 超分辨损失:

超分辨损失反映了输出图像与Groundtruth间的均方误差(MSE)。
➢ 照度损失:

照度损失反映了双目图像间照度的左右一致性。本文利用视差注意力图计算照度损失。视差注意力图能够较好地反映左右图之间的对应关系,
比如视差注意力图与右图的批次化矩阵乘可以得到左图,反之亦然。
➢ 循环一致性损失:

在照度损失的基础上,受cycle GAN中循环损失启发,本文设计了循环一致性损失,以自封闭的形式进一步对双目图像间的潜在几何关系进行正则。循环一致性损失可以理解为,左图(或右图)经过两次注意力图的映射后,应当能够得到左图(或右图)本身。
➢ 平滑损失:
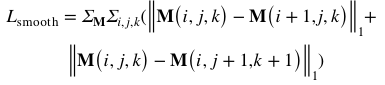
本文设计了定义在视差注意力图上的平滑损失。根据视差注意力图的物理意义可以看出,这一损失在反映了视差在局部区域内的平滑性。
数据集

图4 Flickr1024数据集
在双目视觉领域,现有的数据集(例如KITTI数据集、Middlebury数据集以及ETH3D数据集)更多地针对深度估计与光流估计等任务,在场景数量、场景多样性以及图像质量等方面无法满足双目超分辨算法的需求。因此,本文收集了1024幅双目图像,构建并公开了一个大型双目图像超分辨数据集Flickr1024,用于对双目超分辨算法进行训练和评估。
实验结果
实验部分首先通过消融学习对网络中不同模块以及不同Loss函数的有效性进行了验证:
● 网络结构
表1 不同网络结构的结果对比

● 损失函数
表2 不同损失函数的结果对比

● 算法对比(Comparison to the State-of-the-arts):
本文在Middlebury, KITTI2012以及KITTI2015三个公开数据集上将PASSRnet与双目超分辨算法StereoSR(CVPR18),单图超分辨算法SRCNN(ECCV14)、VDSR(CVPR16)、DRCN(CVPR16)、LapSRN(CVPR17)以及DRRN(CVPR17)进行了对比,结果如下表所示:
表3 不同方法的结果对比

图5与图6进一步展示了本文提出的PASSRnet与其他对比算法超分辨结果的可视化效果:

图5 不同超分辨算法结果对比

图6 不同超分辨算法结果对比
● 灵活性
本文进一步测试了PASSRnet算法和StereoSR算法在处理不同视差图像时的灵活性。实验通过对测试集图像的缩放得到不同分辨率、不同视差大小的测试图像,数值结果如下表所示:
表4 不同方法的灵活性对比
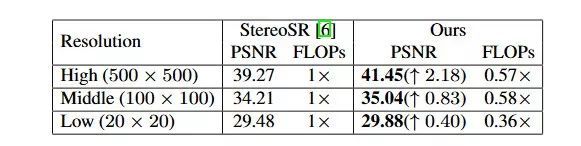
由上表可见,随着输入图像分辨率的增加,双目图像间的视差不断增大,PASSRnet相比于StereoSR的优势不断增强,这主要是因为StereoSR算法无法对视差超过64像素的图像信息进行融合,而PASSRnet采用了视差注意力机制,可以对双目图像全局信息进行有效融合;
当图像水平分辨率低于64像元时,StereoSR需要对图像进行Zero Padding至64像元,造成了不必要的计算开销。相比之下,PASSRnet具有更高的计算效率。
超分辨率结果视觉比较示例(请点击查看大图):

论文链接:
https://arxiv.org/pdf/1903.05784.pdf
代码链接:
https://github.com/LongguangWang/PASSRnet
数据集链接:
https://yingqianwang.github.io/Flickr1024/
超分辨率交流群
关注最新的图像视频超分辨率技术,欢迎加入52CV-超分辨率专业交流群,扫码添加CV君拉你入群,
(请务必注明:SR):

喜欢在QQ交流的童鞋可以加52CV官方QQ群:702781905。
(不会时时在线,如果没能及时通过还请见谅)

长按关注我爱计算机视觉