机器学习算法——kNN算法实现手写数字识别
上篇文章中我们通过kNN算法解决了海伦约会的经典问题。
为了更进一步的理解kNN算法,接下来就利用kNN算法实现手写数字识别来加强理解。
机器学习算法——kNN算法实现手写数字识别
实验环境 PyCharm,Python3,Numpy
手写数字训练数据集资源:
共有两组数据集,一组用于测试一组用来分析数据
数据集即为32*32像素点,且用二进制表示出来了数字的形状;
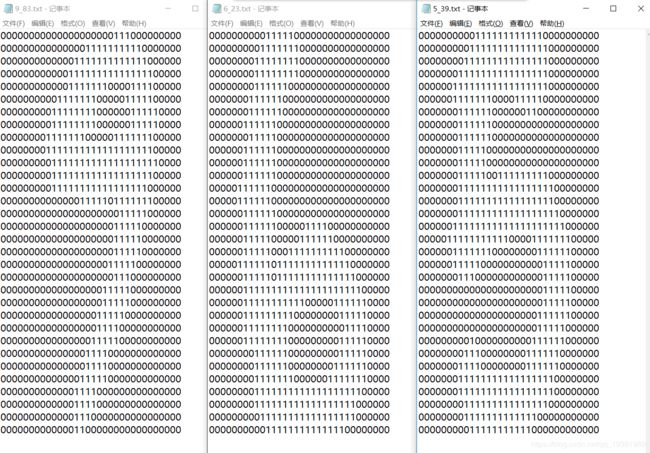
文件名以 真实数字_当前的数字的位置.txt 的形式存储
共有三大模块,算法模块,读取模块和测试模块
算法模块
k-近邻算法对位置类别属性的数据集的每个点依次执行以下操作:
1. 计算已知类别数据集中的点与当前点之间的距离;
2. 按照距离递增次序排序;
3. 选取与当前点距离最小的k个点;
4. 确定前k个点所在的类别的出现频率;
5. 返回前k个点出现频率最高的类别作为当前点的预测分类。
def classify0(inX, dataSet, labels, k):
'''
训练模块
kNN分类算法实现,近朱者赤近墨者黑
:param inX: 传入需要测试的列表
:param dataSet: 特征集合
:param labels: 类别集合
:param k: kNN
:return:
'''
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sgDiffMat = diffMat**2
sgDistances = sgDiffMat.sum(axis=1)
distances = sgDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]读取模块
实现目标:将该32*32的二进制图像矩阵转换为1*1024的向量(为了方便调用上节的算法模块,这样子就可以利用上节的算法模块处理数字图像信息了)
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect实现了将文件中的32*32矩阵转换成了1*1024的向量,并以returnVect返回
测试模块
测试时要收集错误信息,计算错误率,需要引用os库,调用listdir()方法(传入文件夹名,返回指定路径下的文件和文件夹列表)
def handwriting():
hwLabels = []
trainingFileList = os.listdir('./trainingDigits')
#trainFileList 存储trainingDigits下所以的文件名 以列表格式存储, 通过os库中的liststr来实现此功能
m = len(trainingFileList)
# m 存储trainingFileList下的文件数
trainingMat = zeros((m,1024))
#以trainingMat定义一个用来后面利于操作的零矩阵
for i in range(m):
fileNameStr = trainingFileList[i]
#一个一个的读文件名,fileNameStr用于暂时存储文件名
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
#获得文件名中真实数字信息,并将其添加到hwLabels列表中
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('./trainingDigits/%s' % fileNameStr)
#trainingMat来存储文件中的数据集, 当然这文件中的数据集需先通过img2vector处理
testFileList = os.listdir('./testDigits')
errorCount = 0.0
#错误率 = 错误数量与总数相除即为错误率
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
#得到真实答案
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
#打开文件,用vectorUnderTest存储列表
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 9)
#调用kNN训练算法模块训练数据集, 因为数据集中的数据单位为0或1,所以并不需要进行归一化处理
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
#错误数量与总数相除即为错误率
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest)))
整理模块
from numpy import *
import operator
import os
def classify0(inX, dataSet, labels, k):
'''
训练模块
kNN分类算法实现,近朱者赤近墨者黑
:param inX: 传入需要测试的列表
:param dataSet: 特征集合
:param labels: 类别集合
:param k: kNN
:return:
'''
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sgDiffMat = diffMat**2
sgDistances = sgDiffMat.sum(axis=1)
distances = sgDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwriting():
hwLabels = []
trainingFileList = os.listdir('./trainingDigits')
#trainFileList 存储trainingDigits下所以的文件名 以列表格式存储, 通过os库中的liststr来实现此功能
m = len(trainingFileList)
# m 存储trainingFileList下的文件数
trainingMat = zeros((m,1024))
#以trainingMat定义一个用来后面利于操作的零矩阵
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('./trainingDigits/%s' % fileNameStr)
#trainingMat来存储文件中的数据集, 当然这文件中的数据集需先通过img2vector处理
testFileList = os.listdir('./testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
#打开文件,用vectorUnderTest存储列表
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 9)
#调用kNN训练算法模块训练数据集, 因为数据集中的数据单位为0或1,所以并不需要进行归一化处理
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr):
errorCount += 1.0
#错误数量与总数相除即为错误率
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest)))
if __name__ == '__main__':
handwriting()
运行代码:
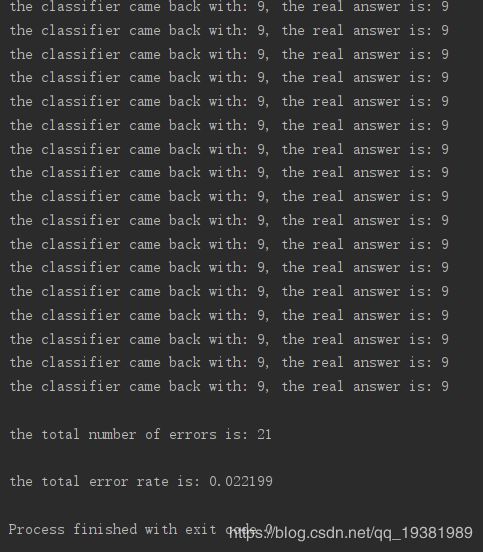
错误率为2.21%,手写数字识别成功完成。
欢迎大家提出建议和问题哦,如有错误理解欢迎指出呀