java_大数据_Hadoop_yarn_hive_sqoop
文章目录
- 01_Hadoop集群搭建
- 1.什么是hadoop
- 1.1 hadoop中有3个核心模块:
- 2.HDFS整体运作机制
- 3.搭建HDFS分布式集群
- 3.1.需要准备多台Linux服务器
- 3.2安装,配置,启动HDFS
- 3.2.1 上传hadoop安装包到各服务器
- 3.2.2 修改配置文件
- 3.2.3 启动HDFS
- 3.2.4 hdfs命令行客户端的所有命令列表
- 4 yarn
- 4.1 配置yarn
- 4.2 启动yarn集群
- 02_在window环境开发hadoop_HDFS
- 1. 在window环境开发HDFS(文件)
- 1.1. 导入jar包
- 1.2. 开始写java代码
- 1.2.1. 上传文件,删文件
- 1.2.2. 下载文件,(需要在windows中配置hadoop环境)
- 1.2.3. 移动文件,改名
- 1.2.4. 创建文件夹
- 1.2.5. 读文件
- 原始代码
- demo读取文件中的内容,以及向文件中写内容
- 03_一个基于java,hadoop的数据采集程序demo
- 1.文件分布
- 2. 环境搭建
- 3 需要采集的目录
- 4 说明:
- 5. code
- 5.1 config.properties
- 5.2 PropertiesHolderLaze
- 5.3 CollectionData
- 5.4 ClearDate
- 5.5 Main
- 04_hadoop_读取hdfs在本地统计单词并将结果放回hdfs
- 1 文件目录
- 2 wordConfig.properties
- 3 WordCount
- 4 WordCountInterface
- 5 WordCountRealize
- 6 Context
- 05_hadoop_wordcounts_yarn的配置_mr的简单使用
- 1.导入jar包
- 2. Mapper
- 2 Reducer
- 3 配置yarn
- 4 运行
- 4.1 写windows提到交到Linux中yarn的程序
- 4.2 windows环境下模拟运行
- 4.3 将jar包导入到Linux服务器上运行
- 5 实列demo
- 5.1 bean类
- 5.2 mapper类
- 5.3 reduce类
- 5.4 提交类
- 5.6 数据源
- 5.7 输出结果
- 06_mapreduce小demo_自定义分组聚合规则
- 1.单词分类
- 1.1 思路
- 1.2 代码
- 2.需要求出每一个订单中成交金额最大的三笔
- 2.1 代码
- 2.2 解释
- 2.3 输出
- 2.4 优化_自定义分发规则
- 2.4.1 自定义 mapper分发的规则
- 2.4.2 自定义 reduce对比的规则(分组比较器)
- 2.4.3 bean 中的compareTo
- 2.4.4 代码
- 3.共同好友分析
- 3.1 代码
- 07_hive_搭建_启动_使用
- 1. 搭建hive
- 1.1 上传hive安装包
- 1.2 hive基本思想
- 1.3 为什么使用Hive
- 1.4 Hive特点
- 2 基本使用
- 2.1 优化使用
- 2.2 将hive 配置进系统变量
- 2.3 启动hive服务使用
- 2.4 脚本化运行
- 3 hive建库建表与数据导入
- 3.1 库
- 3.1.1 建库
- 3.2 表
- 3.2.1 基本建表语句
- 3.2.2 删除表
- 3.2.3 修改表定义
- 3.2.3.1 修改表名:
- 3.2.3.2 修改分区名:
- 3.2.3.1 添加分区:
- 3.2.3.1 删除分区:
- 3.2.3.1 修改表的文件格式定义:
- 3.2.3.1 修改列名定义:
- 3.2.3.1 增加/替换列:
- 3.3 内部表与外部表
- 3.4 分区表
- demo1:
- 1. 创建带分区的表
- 2. 向分区中导入数据
- 3. 针对分区数据进行查询
- demo2:
- 建表:
- 导数据:
- 3.5 CTAS建表语法
- 3.6 数据导入导出
- 3.6.1 将数据文件导入hive的表
- 3.6.1 将hive表中的数据导出到指定路径的文件
- 3.6.2 hive文件格式
- 3.7 数据类型
- 3.7.1 数字类型
- 3.7.2 日期时间类型
- 3.7.3 字符串类型
- 3.7.4 混杂类型
- 3.7.5 复合类型
- 3.7.5.1 array数组类型
- 3.7.5.2 map类型
- 3.7.5.3 struct类型
- 3.7 join关联查询示例
- 3.7.1 inner join(join)
- 3.7.2 left outer join(left join)
- 3.7.3 right outer join(right join)
- 3.7.5 full outer join(full join)
- 3.7.6 left semi join
- 3.8 group by分组聚合
- 4 hive函数使用
- 4.1 常用内置函数
- 4.1.1 类型转换函数
- 4.1.2 数学运算函数
- 4.1.3 字符串函数
- 4.1.4 时间函数
- 08_sqoop
- 1. 搭建sqoop
- 1.1 上传文件
- 1.2 修改配置文件
- 2 测试启动
- 3 导入导出数据
- 3.1 修改每台服务器的mapred-site.xml.template
- 3.2 导入表表数据到HDFS
- 3.3 导入表表数据到Hive
- 3.3.1 导入全部的数据
- 3.3.2 导入部分数据
- 3.3.2.1 自定义导入部分数据
- 3.3.2.2 增量导入
- 3.4 导出数据到mysql
- 其他
- 更新软件
- 安装jdk
- 查看java版本
- ssh 安装
- vim编辑器出问题
- mysql 安装:
- hive 启动:
01_Hadoop集群搭建
1.什么是hadoop
1.1 hadoop中有3个核心模块:
HDFS(分布式文件系统):将文件分布式存储在多台服务器上
MAPREDUCE(分布式运算编程框架):多台服务器并行运算
YARN(分布式资源调度平台):帮用户调度大量的MAPREDUCE程序,合理分配资源
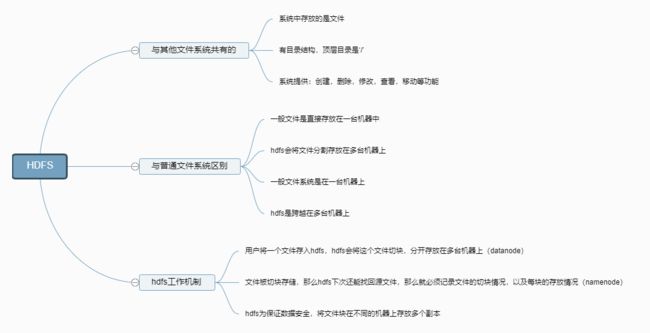
2.HDFS整体运作机制
HDFS(分布式文件系统):
一个HDFS系统,是由一个运行namenode的服务器和若干运行datanode的服务器组成
3.搭建HDFS分布式集群
3.1.需要准备多台Linux服务器
- 准备1+N台服务器:1个namenode节点和N个datanode节点
- 修改服务器ip修改为固定的 方法自行百度
- 修改etc下的hosts 将ip与服务器的名称对应上(相当于域名解析)(域名映射配置)

4.关闭防火墙
关闭防火墙:service iptables stop
关闭防火墙自启: chkconfig iptables off
6.安装jdk(自行百度)
(2-6)每台服务器都需要
3.2安装,配置,启动HDFS
3.2.1 上传hadoop安装包到各服务器
3.2.2 修改配置文件
- 解压至任意位置 演示为root目录下
hadoop的配置文件在:/root/hdoop**.**/etc/hadoop/ - 修改hadoop-env.sh(配置java环境:因为hadoop是java程序需要java环境)
export JAVA_HOME = 你的java jdk目录 (javahome) - 修改core-site.xml (说明你的 namenode在什么地方)
fs.defaultFS
hdfs://vm01:9000
说明:格式为固定写法,name为固定,value中vm01为你想要运行namenode服务的服务器的地址
- 修改hdfs-site.xml (说明你的文件分割记录放在哪个目录,分割的文件放在哪个目录)
dfs.namenode.name.dir
/root/dfs/name
dfs.datanode.data.dir
/root/dfs/data
dfs.namenode.secondary.http-address
vm02:50090
说明:
dfs.namenode.name.dir中的value是指定文件分割记录放在哪个目录
dfs.datanode.data.dir中的value是指定文件的分块放在哪个目录
dfs.namenode.secondary.http-address中的valuevm02是指服务器,50090是端口号(最好不要改)
- 将这些修改过的配置文件复制到其他服务器上(每台服务器都一样)
3.2.3 启动HDFS
要想直接运行Hadoop命令 先要配置环境变量
vi /etc/profile
文件尾部追加
export
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export
HADOOP_HOME=/root/hadoop/hadoop-2.8.5
export
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 初始化namenode的源数据目录
在vm01上执行初始化namenode命令
hadoop namenode -format
这个时候hdfs已经初步搭建完成
在vm01上可以启动namenode和datanode
在其他服务器上可以穹顶datanode
启动namenode命令
hadoop-daemon.sh start namenode
启动datanode命令
hadoop-daemon.sh start datanode
此时可以在window浏览器中访问hdfs提供的web端口:50070
http://192.168.1.101:50070 (运行namenode的服务器的ip)
但是要是有N台datanode那么是不是要在N台上面输入命令启动datanode呢?
当然不是,可以使用HDFS提供的批量启动脚本来执行启动
- 配置ssh免密登录
在主服务器(vm01)执行
ssh-keygen(一顿回车)
ssh-copy-id vm01(第一次需要输入密码)
ssh-copy-id vm0* (依次在主服务器执行以下命令vm02 03 04......)
······
······
-
如果遇到错误可能是无root登录权限 那么就修改
/etc/ssh/sshd_config文件中 添加一条PermitRootLogin yes
然后重启ssh服务sudo service ssh restart -
如果还是有错误可能是没有设置root用户密码
那么在root用户下sudo su
输入命令 sudo passwd 设置密码
这时候就可以免密登录了
- 修改主机hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入
vm-01
vm-02
vm-03
这时候就可以在主服务器上执行:
start-dfs.sh 来自动启动整个集群
如果要停止,则用脚本:stop-dfs.sh(如果提示没有找到命令 那就是环境变量没有配置好,可以在hadoop目录下面的sbin下用 ./ start-dfs.sh或./stop-dfs.sh来执行)
可以自行更改HDFS的分块以及副本数量配置
文件的切块大小和存储的副本数量,都是由客户端决定
所谓的由客户端决定,是通过配置参数来定的
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置(每台都需要改)
dfs.blocksize
64m
dfs.replication
2
3.2.4 hdfs命令行客户端的所有命令列表
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] ... ]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] [-h] [-v] [-t []] [-u] [-x] ...]
[-cp [-f] [-p | -p[topax]] [-d] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] [-x] ...]
[-expunge]
[-find ... ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getfattr [-R] {-n name | -d} [-e en] ]
[-getmerge [-nl] [-skip-empty-file] ]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] [-l] [-d] ... ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]
[-setfattr {-n name [-v value] | -x name} ]
[-setrep [-R] [-w] ...]
[-stat [format] ...]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-truncate [-w] ...]
[-usage [cmd ...]]
4 yarn
4.1 配置yarn
在每台机器上配置
node manager在物理上应该跟data node部署在一起
resource manager在物理上应该独立部署在一台专门的机器上
此处为demo 所有 namenode 与resourcemanager 放在同一台服务器
- 修改每台机器配置文件:
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>vm01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>2value>
property>
mapred-site.xml
mapreduce.framework.name
yarn
其中vm01为 resource manager
- mapreduce_shuffle为固定写法
- 1024 分配的内存 最小2048MB 因为yarn.app.mapreduce.am.resource.mb 需要有1536MB 如果设置小雨1536 - 运行yarn程序时会报错。当然不是运行就占用这么大的内存,而是最大可以用这么多。
2 为cpu个数 最小1个
4.2 启动yarn集群
- 启动yarn集群:start-yarn.sh (注:该命令应该在resource manager所在的机器上执行,否则resource manager会在执行这个命令的机器上启动)
- 用jps检查yarn的进程,用web浏览器查看yarn的web控制台
- http://vm01:8088
执行mapreduce没报错,可是任务运行到running job就卡住在 INFO mapreduce.Job: Running job: job14039055428930004
解决方法 mapred-site.xml
mapreduce.framework.name
yarn
改为
mapreduce.job.tracker
hdfs://192.168.1.120:8001
true
其中ip是主服务器地址。
02_在window环境开发hadoop_HDFS
1. 在window环境开发HDFS(文件)
1.1. 导入jar包
- 解压hadoop安装包
- 导入/share/hadoop/common/Hadoop-common-2.8.5.jar 以及依赖包 lib下全部jar
- 导入/share/haddop/hdfs/hadoop-hdfs-client-2.8.5-tests.jar 以及依赖包lib下全部jar
提取码: 3251
1.2. 开始写java代码
先构造Configuration对象
构造时,会先加载jar包中的默认配置xxx-default.xml
再加载用户写的xml 放在src下面 xxx-site.xml 会覆盖默认配置
在代码中可以在此conf.set(name,value);, 会再次覆盖配置
public class HdfsClient {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
//设置HDFS的配置
//会从项目的classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等配置文件
Configuration conf = new Configuration();
//设置副本数量为2
conf.set("dfs.replication","2");
//指定切块文件大小为64M
conf.set("dfs.blocksize","64M");
//构造一个访问指定HDFS系统的客户端对象,参数1.HDFS系统的URL,参数2,客户端指定的参数,参数3.客户端身份
FileSystem fileSystem = FileSystem.get(new URI("hdfs://vm01:9000/"),conf,"root");
}
}
1.2.1. 上传文件,删文件
//上传一个文件到hdfs中
fileSystem.copyFromLocalFile(new Path("C:\\Users\\81022\\Desktop\\1.txt"),new Path("/javaTest/1.txt"));
//fileSystem.delete(new Path("/video.zip"),true);
fileSystem.close();
1.2.2. 下载文件,(需要在windows中配置hadoop环境)
在Windows下配置环境变量 HADOOP_HOME
Window版本
fileSystem.copyToLocalFile(new Path("/javaTest/1.txt"),new Path("C:\\Users\\81022\\Desktop\\"));
1.2.3. 移动文件,改名
fileSystem.rename(new Path("/1.txt"),new Path("/javaTest/2.txt"));
1.2.4. 创建文件夹
fileSystem.mkdirs(new Path("/xx/yy/zz"));
1.2.5. 读文件
RemoteIterator iter = fileSystem.listFiles(new Path("/"), true);
while (iter.hasNext()){
LocatedFileStatus next = iter.next();
System.out.println("==============================");
System.out.println("文件位置+"+next.getPath());
System.out.println("块大小:"+next.getBlockSize());
System.out.println("文件副本数量:"+next.getReplication());
}
原始代码
public class HdfsClientTest {
FileSystem fileSystem = null;
/**
* 测试查询
* @Author chenpeng
* @Description //TODO
* @Date 19:28
* @Param []
* @return void
**/
@Test
public void fondTest() throws IOException {
RemoteIterator iter = fileSystem.listFiles(new Path("/"), true);
while (iter.hasNext()){
LocatedFileStatus next = iter.next();
System.out.println("==============================");
System.out.println("文件位置+"+next.getPath());
System.out.println("块大小:"+next.getBlockSize());
System.out.println("文件副本数量:"+next.getReplication());
}
fileSystem.close();
}
/**
* 测试目录及文件查询
* @Author chenpeng
* @Description //TODO
* @Date 19:28
* @Param []
* @return void
**/
@Test
public void fondAllTest() throws IOException {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus status:fileStatuses) {
System.out.println("==============================");
System.out.println("文件位置+"+status.getPath());
System.out.println(status.isDirectory()? "这是文件夹":"这是文件");
}
fileSystem.close();
}
/**
* 初始化
* @Author chenpeng
* @Description //TODO
* @Date 18:57
* @Param []
* @return void
**/
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
conf.set("dfs.replication","2");
conf.set("dfs.blocksize","64M");
fileSystem = FileSystem.get(new URI("hdfs://vm01:9000/"),conf,"root");
}
/**
* 下载文件
* @Author chenpeng
* @Description //TODO
* @Date 18:57
* @Param []
* @return void
**/
@Test
public void testGet() throws IOException {
fileSystem.copyToLocalFile(
new Path("/javaTest/1.txt"),new Path("C:\\Users\\81022\\Desktop\\"));
fileSystem.close();
}
/**
* 移动文件
* @Author chenpeng
* @Description //TODO
* @Date 19:03
* @Param []
* @return void
**/
@Test
public void renameTest() throws IOException {
fileSystem.rename(new Path("/1.txt"),new Path("/javaTest/1.txt"));
fileSystem.close();
}
/**
* 创建目录
* @Author chenpeng
* @Description //TODO
* @Date 19:24
* @Param []
* @return void
**/
@Test
public void mkdirTest() throws IOException {
fileSystem.mkdirs(new Path("/xx/yy/zz"));
fileSystem.close();
}
/**
* 测试删除文件
* @Author chenpeng
* @Description //TODO
* @Date 18:08
* @Param [fileSystem]
* @return void
**/
@Test
public void testDelete() throws IOException {
fileSystem.delete(new Path("/video.zip"),true);
fileSystem.close();
}
/**
* 上传文件测试
* @Author chenpeng
* @Description //TODO
* @Date 18:07
* @Param [fileSystem]
* @return void
**/
@Test
public void testPut() throws IOException {
fileSystem.copyFromLocalFile(
new Path("C:\\Users\\81022\\Desktop\\1.txt"),new Path("/xx/yy/zz/1.txt"));
fileSystem.close();
}
}
demo读取文件中的内容,以及向文件中写内容
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName HdfsReanAndWriteDemo.java
* @Description TODO
* @createTime 2019年01月28日 22:37:00
*/
public class HdfsReanAndWriteDemo {
FileSystem fileSystem;
private String url = "hdfs://vm01:9000/";
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
fileSystem = FileSystem.get(new URI(url),new Configuration(),"root");
}
/**
* 读取文件
* @Author chenpeng
* @Description //TODO
* @Date 22:54
* @Param []
* @return void
**/
@Test
public void readerHdfsDemo() throws IOException {
FilterInputStream in = fileSystem.open(new Path("/javaTest/2.txt"));
BufferedReader br = new BufferedReader(new InputStreamReader(in,"utf-8"));
String line = null;
while ((line = br.readLine())!=null){
System.out.println(line);
}
br.close();
in.close();
}
/**
* 读取文件 指定位置开始
* @Author chenpeng
* @Description //TODO
* @Date 22:54
* @Param []
* @return void
**/
@Test
public void readerRandomHdfsDemo() throws IOException {
FSDataInputStream in = fileSystem.open(new Path("/javaTest/1.txt"));
//指定从第三个开始读
in.seek(4);
byte[] bs = new byte[4];
int len = 0;
while ((len = in.read(bs))!=-1){
System.out.print(new String(bs,0,len,"gbk"));
}
in.close();
}
@Test
public void writeHDFSDemo() throws IOException {
fileSystem.delete(new Path("/javaTest/2.txt"),true);
FSDataOutputStream out = fileSystem.create(new Path("/javaTest/2.txt"),true);
out.write("测试第二行".getBytes());
out.close();
}
@After
public void last() throws IOException {
fileSystem.close();
}
}
03_一个基于java,hadoop的数据采集程序demo
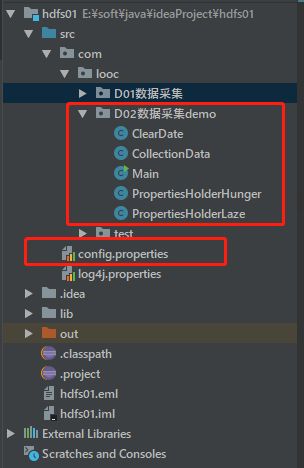
1.文件分布
2. 环境搭建
参考:02_在window环境开发hadoop_HDFS
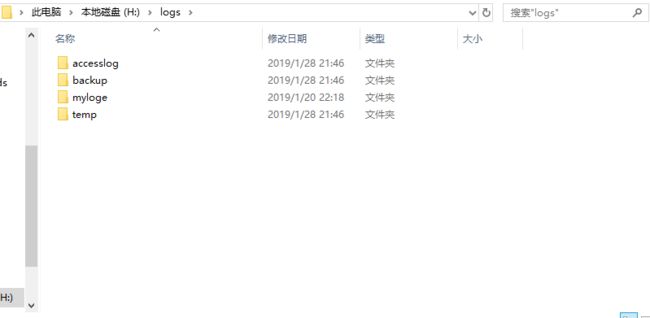
3 需要采集的目录
4 说明:
- 需要采集的文件在accesslog里面并且以.log结尾
- 采集的思路是
- 先从accesslog移动进temp文件夹
- 从temp向HDFS上传
- 将temp里面的文件移动进backup文件夹
- 此demo是采用读取配置文件来得到路径以及配置信息
- 读取配置文件采用单列模式的懒汉式并考虑了线程安全
5. code
5.1 config.properties
LOG_SOURCE_DIR=H:/logs/accesslog/
LOG_TEMP_DIR=H:/logs/temp/
LOG_BACKUP_DIR=H:/logs/backup/
LOG_TIMEOUT=24
LOG_NAME=.log
HDFS_URL=hdfs://vm01:9000/
HDFS_DIR=/logs/
HDFS_F_NAME=access_log_
HDFS_L_NAME=.log
5.2 PropertiesHolderLaze
package com.looc.D02数据采集demo;
import java.io.IOException;
import java.util.Properties;
/**
* 单列模式:懒汉式——并考虑线程安全
* @author chenPeng
* @version 1.0.0
* @ClassName PropertiesHolderLaze.java
* @Description TODO
* @createTime 2019年01月28日 19:47:00
*/
public class PropertiesHolderLaze {
private static Properties pros = null;
public static Properties getPros() throws IOException {
if (pros==null){
synchronized (PropertiesHolderLaze.class){
if (pros==null){
pros = new Properties();
pros.load(PropertiesHolderLaze.class.getClassLoader().getResourceAsStream(
"config.properties"));
}
}
}
return pros;
}
}
5.3 CollectionData
package com.looc.D02数据采集demo;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Properties;
import java.util.TimerTask;
import java.util.UUID;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName CollectionData.java
* @Description TODO
* @createTime 2019年01月28日 19:18:00
*/
public class CollectionData extends TimerTask {
private String LOG_SOURCE_DIR;
private String LOG_TEMP_DIR;
private String LOG_BACKUP_DIR;
private String LOG_TIMEOUT;
private String LOG_NAME;
private String HDFS_URL;
private String HDFS_DIR;
private String HDFS_F_NAME;
private String HDFS_L_NAME;
private String TIME_MATE = "yyyy-MM-dd";
/**
* The action to be performed by this timer task.
*/
@Override
public void run() {
//移动数据到temp
//temp上传到hdfs
//temp移动到backup
try {
init();
//移动之前判断是否有文件
if (!isNullDir()){
moveToTemp();
setUpToHdfs();
tempToBackup();
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
/**
* 初始化得到配置文件
* @Author chenpeng
* @Description //TODO
* @Date 20:19
* @Param []
* @return void
**/
public void init() throws IOException {
Properties pros = PropertiesHolderLaze.getPros();
LOG_SOURCE_DIR = pros.getProperty("LOG_SOURCE_DIR");
LOG_TEMP_DIR = pros.getProperty("LOG_TEMP_DIR");
LOG_BACKUP_DIR = pros.getProperty("LOG_BACKUP_DIR");
LOG_TIMEOUT = pros.getProperty("LOG_TIMEOUT");
LOG_NAME = pros.getProperty("LOG_NAME");
HDFS_URL = pros.getProperty("HDFS_URL");
HDFS_DIR = pros.getProperty("HDFS_DIR");
HDFS_F_NAME = pros.getProperty("HDFS_F_NAME");
HDFS_L_NAME = pros.getProperty("HDFS_L_NAME");
}
/**
* 判断文件夹是否为空
* @Author chenpeng
* @Description //TODO
* @Date 21:19
* @Param []
* @return boolean
**/
public boolean isNullDir(){
if (new File(LOG_SOURCE_DIR).list().length==0){
return true;
}
return false;
}
/**
* 移动数据到temp
* @Author chenpeng
* @Description //TODO
* @Date 20:17
* @Param []
* @return void
**/
public void moveToTemp() throws IOException {
//拿到文件
File[] logSourceArray = new File(LOG_SOURCE_DIR).listFiles();
//移动文件
for (File file : logSourceArray) {
FileUtils.moveFileToDirectory(file,new File(LOG_TEMP_DIR),true);
}
}
/**
* temp上传到hdfs
* @Author chenpeng
* @Description //TODO
* @Date 20:18
* @Param []
* @return void
**/
public void setUpToHdfs() throws URISyntaxException, IOException, InterruptedException {
//拿到全部的文件
File[] logTempArray = new File(LOG_TEMP_DIR).listFiles();
//获取hdfs链接
FileSystem fileSystem =
FileSystem.get(new URI(HDFS_URL),new Configuration(),"root");
//获取一个时间
SimpleDateFormat sdf = new SimpleDateFormat(TIME_MATE);
Calendar calendar = Calendar.getInstance();
String time = sdf.format(calendar.getTime());
//上传文件
for (File file : logTempArray) {
fileSystem.copyFromLocalFile(
new Path(file.getAbsolutePath()),
new Path(HDFS_DIR+"/"+time+"/"+
HDFS_F_NAME+time+UUID.randomUUID()+HDFS_L_NAME));
}
//关闭流
fileSystem.close();
}
/**
* temp移动到backup
* @Author chenpeng
* @Description //TODO
* @Date 20:18
* @Param []
* @return void
**/
public void tempToBackup() throws IOException {
//拿到全部的文件
File[] logTempArray = new File(LOG_TEMP_DIR).listFiles();
//拿到时间
SimpleDateFormat sdf = new SimpleDateFormat(TIME_MATE);
Calendar calendar = Calendar.getInstance();
String time = sdf.format(calendar.getTime());
for (File file : logTempArray) {
FileUtils.moveFileToDirectory(
file,new File(LOG_BACKUP_DIR+"/"+time),true);
}
}
}
5.4 ClearDate
package com.looc.D02数据采集demo;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Properties;
import java.util.TimerTask;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName ClearDate.java
* @Description TODO
* @createTime 2019年01月28日 19:19:00
*/
public class ClearDate extends TimerTask {
private String TIME_MATE = "yyyy-MM-dd";
private String LOG_BACKUP_DIR;
/**
* The action to be performed by this timer task.
*/
@Override
public void run() {
try {
init();
fondTimeOutFile();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
/**
* 初始化路径
* @Author chenpeng
* @Description //TODO
* @Date 21:25
* @Param []
* @return void
**/
public void init() throws IOException {
Properties properties = PropertiesHolderLaze.getPros();
LOG_BACKUP_DIR = properties.getProperty("LOG_BACKUP_DIR");
}
/**
* 扫描文件夹是否存在超时文件
* @Author chenpeng
* @Description //TODO
* @Date 21:26
* @Param []
* @return void
**/
public void fondTimeOutFile() throws IOException, ParseException {
//拿到路径
File[] fileArray = new File(LOG_BACKUP_DIR).listFiles();
//拿到时间
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DAY_OF_MONTH,-1);
SimpleDateFormat sdf = new SimpleDateFormat(TIME_MATE);
for (File file : fileArray) {
if (calendar.getTime().getTime() > sdf.parse(file.getName()).getTime()){
//删除
FileUtils.deleteDirectory(file);
}
}
}
}
5.5 Main
/**
* 程序入口
* @author chenPeng
* @version 1.0.0
* @ClassName Main.java
* @Description TODO
* @createTime 2019年01月28日 20:08:00
*/
public class Main {
private static Integer LOG_TIMEOUT;
public static void init() throws IOException {
Properties properties = PropertiesHolderLaze.getPros();
LOG_TIMEOUT = Integer.parseInt(properties.getProperty("LOG_TIMEOUT"));
}
public static void main(String[] args){
Timer timer = new Timer();
timer.schedule(new CollectionData(),0,LOG_TIMEOUT*60*60*1000L);
timer.schedule(new ClearDate(),0,LOG_TIMEOUT*60*60*1000L);
}
}
04_hadoop_读取hdfs在本地统计单词并将结果放回hdfs
1 文件目录

2 wordConfig.properties
配置文件
CLASS_BUSINESS=com.looc.D04HDFS单词计数.WordCountRealize
HDFS_URL=hdfs://vm01:9000/
HDFS_USER=root
OUT_PUT_SRC=/wordCount/result/
RESOURCE_SRC=/wordCount/resource/
3 WordCount
package com.looc.D04HDFS单词计数;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName WordCount.java
* @Description TODO
* @createTime
*/
public class WordCount {
private String CLASS_BUSINESS;
private String HDFS_URL;
private String HDFS_USER;
private String OUT_PUT_SRC;
private String RESOURCE_SRC;
private String PROS_CONFIG="wordConfig.properties";
private FileSystem fileSystem;
private WordCountInterface wordCountInt;
public static void main(String[] args) throws IllegalAccessException, InterruptedException,
IOException, InstantiationException, URISyntaxException, ClassNotFoundException {
WordCount wordCount = new WordCount();
wordCount.doMain();
}
public void doMain() throws IllegalAccessException, InterruptedException, IOException,
InstantiationException, URISyntaxException, ClassNotFoundException {
init();
doIt();
readerResult();
finallys();
}
/**
* 初始化
* 拿到配置文件
* @Author chenpeng
* @Description //TODO
* @Date 19:07
* @Param []
* @return void
**/
public void init() throws ClassNotFoundException, IOException, URISyntaxException,
InterruptedException, IllegalAccessException, InstantiationException {
//读取配置文件
Properties pros = new Properties();
pros.load(new InputStreamReader(
WordCount.class.getClassLoader().getResourceAsStream(PROS_CONFIG),"GBK"));
CLASS_BUSINESS = pros.getProperty("CLASS_BUSINESS");
HDFS_URL = pros.getProperty("HDFS_URL");
HDFS_USER = pros.getProperty("HDFS_USER");
OUT_PUT_SRC = pros.getProperty("OUT_PUT_SRC");
RESOURCE_SRC = pros.getProperty("RESOURCE_SRC");
//加载业务逻辑类
Class<?> tClass = Class.forName(CLASS_BUSINESS);
wordCountInt = (WordCountRealize) tClass.newInstance();
//拿到HDFS链接
fileSystem = FileSystem.get(new URI(HDFS_URL), new Configuration(), HDFS_USER);
}
/**
* 执行
* @Author chenpeng
* @Description //TODO
* @Date 19:08
* @Param []
* @return void
**/
public void doIt() throws IOException {
//拿到全部的文件
FileStatus[] fileStatuses = fileSystem.listStatus(new Path(RESOURCE_SRC));
//记录信息
Context context = new Context();
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream fsDataInputStream = fileSystem.open(fileStatus.getPath());
BufferedReader bfr = new BufferedReader(new InputStreamReader(fsDataInputStream));
String temp = null;
while ((temp=bfr.readLine())!=null){
//执行业务逻辑
wordCountInt.wordCountBusiness(temp, context);
}
bfr.close();
fsDataInputStream.close();
}
//输出结果
HashMap<Object, Object> map = context.getMap();
Set<Map.Entry<Object, Object>> entries = map.entrySet();
StringBuffer stringBuffer = new StringBuffer();
for (Map.Entry<Object, Object> entry : entries) {
stringBuffer.append(entry.getKey()+"====="+entry.getValue()+"\n");
}
//写入文件
FSDataOutputStream fsDataOutputStream = fileSystem.create(
new Path(OUT_PUT_SRC+"wordCount.txt"), true);
fsDataOutputStream.write(stringBuffer.toString().getBytes());
fsDataOutputStream.close();
}
/**
* 读取结果
* @Author chenpeng
* @Description //TODO
* @Date 19:59
* @Param []
* @return void
**/
public void readerResult() throws IOException {
FSDataInputStream open = fileSystem.open(new Path(OUT_PUT_SRC+"wordCount.txt"));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open));
String temp = null;
while ((temp = bufferedReader.readLine())!=null){
System.out.println(temp);
}
}
/**
*
* @Author chenpeng
* @Description //TODO
* @Date 19:08
* @Param []
* @return void
**/
public void finallys() throws IOException {
fileSystem.close();
System.out.println("HDFS流正常关闭");
}
}
4 WordCountInterface
package com.looc.D04HDFS单词计数;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName WordCountInterface.java
* @Description TODO
* @createTime
*/
public interface WordCountInterface {
/**
* 业务接口
* @Author chenpeng
* @Description //TODO
* @Date 19:27
* @Param [str, context]
* @Param str
* @Param context
* @return void
**/
void wordCountBusiness(String str,Context context);
}
5 WordCountRealize
package com.looc.D04HDFS单词计数;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName WordCountRealize.java
* @Description TODO
* @createTime
*/
public class WordCountRealize implements WordCountInterface{
/**
* 业务接口
* @param str
* @param context
* @return void
* @Author chenpeng
* @Description //TODO
* @Date 18:29
* @Param [str, context]
*/
@Override
public void wordCountBusiness(String str, Context context) {
String[] wordArray = str.toLowerCase().split(" ");
for (String word : wordArray) {
Object number = context.getValue(word);
if (number!=null){
int nub = (int)number + 1;
context.add(word, nub);
continue;
}
context.add(word, 1);
}
}
}
6 Context
package com.looc.D04HDFS单词计数;
import org.junit.Test;
import java.util.HashMap;
/**
* 一个上下文对象
* @author chenPeng
* @version 1.0.0
* @ClassName Context.java
* @Description TODO
* @createTime
*/
public class Context {
private HashMap<Object,Object> hashMap = new HashMap<>();
/**
* 写入值
* @Author chenpeng
* @Description //TODO
* @Date 19:25
* @Param [obj, obj]
* @return void
**/
public void add(Object objK,Object objV){
hashMap.put(objK, objV);
}
/**
* 取值
* @Author chenpeng
* @Description //TODO
* @Date 19:25
* @Param [obj]
* @return java.lang.Object
**/
public Object getValue(Object obj){
return hashMap.get(obj);
}
/**
* 获取map对象
* @Author chenpeng
* @Description //TODO
* @Date 19:26
* @Param []
* @return java.util.HashMap
**/
public HashMap<Object,Object> getMap(){
return hashMap;
}
}
05_hadoop_wordcounts_yarn的配置_mr的简单使用
1.导入jar包
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.2.0version>
dependency>
dependencies>
2. Mapper
继承 org.apache.hadoop.mapreduce.Mapper 下的 Mapper
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
- KEYIN
是map task 读取到的数据的key的类型,是一行的启始偏移量Long - VALUEIN
是map task读取到的数据的value的类型,是一行的内容Stirng - KEYOUT
是用户的自定义map方法要返回的数据kv数据的key的类型 - VALUEOUT
用户的自定map方法要返回的结果kv数据的value的数据类型
在mapreduce中,map参数的数据传输给reduce,需要进行序列化和反序列化,而JDK中的原生序列化机制产生的数据比较冗余,就会导致MAPREDUCE运行过程中传输效率低
所以 hadoop专门设计了自己的序列化机制
hadoop为常用数据类型封装了自己的实现了hadoop序列化
| java基本类型 | Long | String | Integer | Float |
|---|---|---|---|---|
| hadoop基本类型 | LongWritable | Text | IntWritable | FloatWritable |
core:
public class WorkcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
2 Reducer
另外的一个class 继承
Reducer
core:
public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sun = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable va = iterator.next();
sun+=va.get();
}
context.write(key, new IntWritable(sun));
}
}
3 配置yarn
在每台机器上配置
node manager在物理上应该跟data node部署在一起
resource manager在物理上应该独立部署在一台专门的机器上
此处为demo 所有 namenode 与resourcemanager 放在同一台服务器
- 修改每台机器配置文件:
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>vm01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>2value>
property>
其中vm01为 resource manager
mapreduce_shuffle为固定写法
1024 分配的内存 最小2048MB 因为yarn.app.mapreduce.am.resource.mb 需要有1536MB 如果设置小雨1536 运行yarn程序时会报错。当然不是运行就占用这么大的内存,而是最大可以用这么多。
2 为cpu个数 最小1个
- 启动yarn集群:start-yarn.sh (注:该命令应该在resource manager所在的机器上执行,否则resource manager会在执行这个命令的机器上启动)
- 用jps检查yarn的进程,用web浏览器查看yarn的web控制台
http://vm01:8088
4 运行
4.1 写windows提到交到Linux中yarn的程序
package com.looc.main;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName JobSubmitter.java
* @Description TODO
* @createTime 2019年02月01日 16:55:00
*/
public class JobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
//在代码中设置 获取HDFS以及yarn的用户身份
System.setProperty("HADOOP_USER_NAME", "root");
//设置job运行时的参数
Configuration conf = new Configuration();
//1. 设置job运行时需要访问的默认文件系统
conf.set("fs.defaultFS", "hdfs://vm01:9000");
//2. 设置job提交到哪里去
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "vm01");
//3. 如果是在windows上运行就设置为跨平台,如果是在Linux系统上就不需要。因为windows上路径问题,和jar包执行命令不同
conf.set("mapreduce.app-submission.cross-platform","true");
//设置job
Job job = Job.getInstance(conf);
//1. 封装参数:jar包所在位置,写死适用于在window的ide上执行,也需要事先打好jar包,自动获取使用与在Linux系统上运行
job.setJar("H:\\BaiduNetdiskDownload\\bigDateTempJar\\wr.jar");
//job.setJarByClass(JobSubmitter.class);
//2. 封装参数:此次job所需调用的Mapper实现类,Reducer实现类
job.setMapperClass(WorkcountMapper.class);
job.setReducerClass(WordcountReduce.class);
//3. 封装参数:此次job的Mapper实现类和,Reducer实现类产生的结果数据的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//此处是demo如果存在就删除
Path outPutPath = new Path("/wordCount/outPut");
FileSystem fileSystem = FileSystem.get(new URI("hdfs://vm01:9000"),conf,"root");
if (fileSystem.exists(outPutPath)){
fileSystem.delete(outPutPath, true);
}
//4. 封装参数:此次job需要处理的输入数据所在的路径,以及输出路径
FileInputFormat.setInputPaths(job, new Path("/wordCount/resource"));
FileOutputFormat.setOutputPath(job, outPutPath);
//5. 封装参数:想要启动reduce task的数量
job.setNumReduceTasks(2);
//6. 提交job给yarn 此处为等待yarn执行完,并将执行过程输出到控制台,可以用job.submit();来提交
boolean res = job.waitForCompletion(true);
System.exit(res? 0:1);
}
}
4.2 windows环境下模拟运行
public class JobSubWin {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(JobSubWin.class);
job.setMapperClass();
job.setReducerClass();
job.setMapOutputValueClass();
job.setMapOutputKeyClass();
job.setOutputValueClass();
job.setOutputKeyClass();
FileInputFormat.setInputPaths(job, new Path("H:\BaiduNetdiskDownload\bigDateTempJar\\input"));
FileOutputFormat.setOutputPath(job, new Path("H:\BaiduNetdiskDownload\bigDateTempJar\\output"));
job.setNumReduceTasks(3);
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
4.3 将jar包导入到Linux服务器上运行
- 将jar包放置任何一台装了hadoop的Linux机器上
- 使用命令
hadoop jar xxx.jar xxx.xxx.xxx.JobSubLinux
core:
public class JobSubLinux {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(JobSubWin.class);
job.setMapperClass();
job.setReducerClass();
job.setMapOutputValueClass();
job.setMapOutputKeyClass();
job.setOutputValueClass();
job.setOutputKeyClass();
FileInputFormat.setInputPaths(job, new Path("/wordCount/input"));
FileOutputFormat.setOutputPath(job, new Path("/wordCount/output"));
job.setNumReduceTasks(3);
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
5 实列demo
统计某个电话号码的全部上传流量,全部下载流量,以及全部上传和下载流量
如果需要使用自定义对象,那么该对象需要实现Writable接口,重写write和readFields方法 必须有无参构造因为需要反序列化
需要注意: write和readFields的顺序以及方法要一样
如下:
5.1 bean类
package com.looc.流量数据分析demo;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName FlowBean.java
* @Description TODO
* @createTime
*/
public class FlowBean implements Writable {
private Integer upFlow;
private Integer dFlow;
private Integer amountFlow;
private String phone;
public FlowBean() {}
public FlowBean(Integer upFlow, Integer dFlow, String phone) {
this.upFlow = upFlow;
this.dFlow = dFlow;
this.amountFlow = upFlow + dFlow;
this.phone = phone;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getdFlow() {
return dFlow;
}
public void setdFlow(Integer dFlow) {
this.dFlow = dFlow;
}
public Integer getAmountFlow() {
return amountFlow;
}
public void setAmountFlow(Integer amountFlow) {
this.amountFlow = amountFlow;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(upFlow);
dataOutput.writeInt(dFlow);
dataOutput.writeInt(amountFlow);
dataOutput.writeUTF(phone);
}
public void readFields(DataInput dataInput) throws IOException {
upFlow = dataInput.readInt();
dFlow = dataInput.readInt();
amountFlow = dataInput.readInt();
phone = dataInput.readUTF();
}
}
5.2 mapper类
package com.looc.流量数据分析demo;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName FlowCountMapper.java
* @Description TODO
* @createTime
*/
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phone = fields[1];
Integer upFlow = Integer.parseInt(fields[fields.length-3]);
Integer dFlow = Integer.parseInt(fields[fields.length-2]);
context.write(new Text(phone), new FlowBean(upFlow, dFlow, phone));
}
}
5.3 reduce类
package com.looc.流量数据分析demo;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName FlowCountReducer.java
* @Description TODO
* @createTime
*/
public class FlowCountReducer extends Reducer<Text ,FlowBean,Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
int upSum = 0;
int dSun = 0;
for (FlowBean value : values) {
upSum+=value.getUpFlow();
dSun+=value.getdFlow();
}
context.write(key,new FlowBean(upSum, dSun, key.toString()));
}
}
5.4 提交类
package com.looc.流量数据分析demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author chenPeng
* @version 1.0.0
* @ClassName FlowJobSub.java
* @Description TODO
* @createTime
*/
public class FlowJobSub {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(FlowJobSub.class);
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\数据流量分析demo\\input"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\数据流量分析demo\\output"));
job.waitForCompletion(true);
}
}
5.6 数据源
1363157985066 137****0503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 138****4101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 139****5656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 139****1106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 182****5961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 841****3 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 135****9658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 159****3257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 137****9419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 136****7991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 150****5858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 159****2119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 135****9658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 134****3104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 136****6565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 139****4466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 135****8823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 183****3382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 139****7413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 137****8710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985066 137****8888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157993055 135****6666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
5.7 输出结果
134****3104 180 180 360
135****8823 7335 110349 117684
135****6666 1116 954 2070
135****9658 2034 5892 7926
136****6565 1938 2910 4848
136****7991 6960 690 7650
137****9419 240 0 240
137****0503 2481 24681 27162
137****8888 2481 24681 27162
137****8710 120 120 240
138****4101 264 0 264
139****4466 3008 3720 6728
139****7413 11058 48243 59301
139****1106 240 0 240
139****5656 132 1512 1644
150****5858 3659 3538 7197
159****3257 3156 2936 6092
159****2119 1938 180 2118
182****5961 1527 2106 3633
183****3382 9531 2412 11943
841****3 4116 1432 5548
06_mapreduce小demo_自定义分组聚合规则
1.单词分类
a.txt
hello tom
hello jim
hello kitty
hello rose
b.txt
hello jerry
hello jim
hello kitty
hello jack
c.txt
hello jerry
hello java
hello c++
hello c++
需要得到以下结果:
hello a.txt-->4 b.txt-->4 c.txt-->4
java c.txt-->1
jerry b.txt-->1 c.txt-->1
…
1.1 思路
1 将单词个数以及文件位置 统计个数
2 将相同的单词 将数据合并为一条数据
1.2 代码
得到文件名
从输入切片信息中获取当前正在处理的一行数据所属的文件
InputSplit 的实现类 FileSplit inputSplit = (FileSplit)context.getInputSplit();
- 第一步
- IndexesMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class IndexesMapper extends Mapper<LongWritable, Text, Text , IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
String[] str = value.toString().split(" ");
for (String s : str) {
context.write(new Text(s+"-"+fileName), new IntWritable(1));
}
}
}
- IndexesReduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IndexesReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int temp = 0;
for (IntWritable value : values) {
temp+=1;
}
context.write(key,new IntWritable(temp));
}
}
- IndexesSub
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class IndexesSub {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(IndexesSub.class);
job.setMapperClass(IndexesMapper.class);
job.setReducerClass(IndexesReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\索引数据"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\output"));
job.waitForCompletion(true);
}
}
- 第二步
- IndexSecMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class IndexSecMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] str = value.toString().split("-");
context.write(new Text(str[0]), new Text(str[1]));
}
}
- IndexSecReduce
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IndexSecReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder stringBuilder = new StringBuilder();
for (Text value : values) {
stringBuilder.append(" >"+value.toString());
}
context.write(key, new Text(stringBuilder.toString()));
}
}
- IndexSecSub
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class IndexSecSub {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(IndexSecSub.class);
job.setMapperClass(IndexSecMapper.class);
job.setReducerClass(IndexSecReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\output"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\output2"));
job.waitForCompletion(true);
}
}
2.需要求出每一个订单中成交金额最大的三笔
order001,u001,小米6,1999.9,2
order001,u001,雀巢咖啡,99.0,2
order001,u001,安慕希,250.0,2
order001,u001,经典红双喜,200.0,4
order001,u001,防水电脑包,400.0,2
order002,u002,小米手环,199.0,3
order002,u002,榴莲,15.0,10
order002,u002,苹果,4.5,20
order002,u002,肥皂,10.0,40
order003,u001,小米6,1999.9,2
order003,u001,雀巢咖啡,99.0,2
order003,u001,安慕希,250.0,2
order003,u001,经典红双喜,200.0,4
order003,u001,防水电脑包,400.0,2
2.1 代码
- OrderMapper
public class OrderMapper extends Mapper<LongWritable, Text, Text, OrderBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
context.write(new Text(split[0]),
new OrderBean(split[0],split[1],split[2],Float.parseFloat(split[3]),Integer.parseInt(split[4])));
}
}
- OrderReduce
public class OrderReduce extends Reducer<Text, OrderBean, OrderBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException {
List<OrderBean> orderBeans = new ArrayList<OrderBean>();
for (OrderBean value : values) {
orderBeans.add(new OrderBean(value));
}
Collections.sort(orderBeans);
for (int i = 0; i < 3; i++) {
context.write(orderBeans.get(i), NullWritable.get());
}
}
}
- OrderSub
public class OrderSub {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(OrderSub.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderBean.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\交金额最大的三笔\\input"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\交金额最大的三笔\\output"));
job.waitForCompletion(true);
}
}
- OrderBean
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private String userId;
private String comName;
private Float price;
private Integer nub;
private Float subPrice;
@Override
public String toString() {
return orderId+"\t"+userId+"\t"+comName+"\t"+price+"\t"+nub+subPrice;
}
public int compareTo(OrderBean o) {
Float temp = o.getSubPrice() - this.getSubPrice();
if (temp == 0){
return this.getComName().compareTo(o.getComName());
}else if (temp>0){
return 1;
}else{
return 0;
}
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.orderId);
dataOutput.writeUTF(this.userId);
dataOutput.writeUTF(this.comName);
dataOutput.writeFloat(this.price);
dataOutput.writeInt(this.nub);
dataOutput.writeFloat(this.subPrice);
}
public void readFields(DataInput dataInput) throws IOException {
this.orderId = dataInput.readUTF();
this.userId = dataInput.readUTF();
this.comName = dataInput.readUTF();
this.price = dataInput.readFloat();
this. nub = dataInput.readInt();
this.subPrice = price*nub;
}
public OrderBean() {}
public OrderBean(OrderBean ob){
this.orderId = ob.getOrderId();
this.userId = ob.getUserId();
this.comName = ob.getComName();
this.price = ob.getPrice();
this.nub = ob.getNub();
this.subPrice = ob.getSubPrice();
}
public OrderBean(String orderId, String userId, String comName, Float price, Integer nub) {
this.orderId = orderId;
this.userId = userId;
this.comName = comName;
this.price = price;
this.nub = nub;
this.subPrice = price*nub;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getComName() {
return comName;
}
public void setComName(String comName) {
this.comName = comName;
}
public Float getPrice() {
return price;
}
public void setPrice(Float price) {
this.price = price;
}
public Integer getNub() {
return nub;
}
public void setNub(Integer nub) {
this.nub = nub;
}
public Float getSubPrice() {
return subPrice;
}
public void setSubPrice(Float subPrice) {
this.subPrice = subPrice;
}
}
2.2 解释
- 排序
- bean 中调用 WritableComparable 接口
public int compareTo(OrderBean o) { Float temp = o.getSubPrice() - this.getSubPrice(); if (temp == 0){ return this.getComName().compareTo(o.getComName()); }else if (temp>0){ return 1; }else{ return 0; } }- OrderReduce中使用
ListorderBeans = new ArrayList (); for (OrderBean value : values) { orderBeans.add(new OrderBean(value)); } Collections.sort(orderBeans);
2.3 输出
order001 u001 雀巢咖啡 99.0 2198.0
order001 u001 安慕希 250.0 2500.0
order001 u001 小米6 1999.9 23999.8
order002 u002 榴莲 15.0 10150.0
order002 u002 肥皂 10.0 40400.0
order002 u002 苹果 4.5 2090.0
order003 u001 小米6 1999.9 23999.8
order003 u001 雀巢咖啡 99.0 2198.0
order003 u001 安慕希 250.0 2500.0
2.4 优化_自定义分发规则
2.4.1 自定义 mapper分发的规则
public class OptimizeOrderPartitione extends Partitioner<OrderBean, NullWritable> {
@Override
public int getPartition(OrderBean orderBean, NullWritable nullWritable, int i) {
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE)%i;
}
}
2.4.2 自定义 reduce对比的规则(分组比较器)
public class OptimizeOrderGroupingComparator extends WritableComparator {
public OptimizeOrderGroupingComparator(){
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean o1 = (OrderBean) a;
OrderBean o2 = (OrderBean) b;
//返回为零则代表相同
return o1.getOrderId().compareTo(o2.getOrderId());
}
}
2.4.3 bean 中的compareTo
public int compareTo(OrderBean o) {
return this.getOrderId().compareTo(o.getOrderId())==0 ? Float.compare(o.getSubPrice(),this.getSubPrice()):this.getOrderId().compareTo(o.getOrderId());
}
2.4.4 代码
public class OptimizeOrder {
public static class OpOrdMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
context.write(new OrderBean(
split[0],split[1],split[2],Float.parseFloat(split[3]),Integer.parseInt(split[4])),v);
}
}
public static class OpOrdReduce extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
int temp = 0;
for (NullWritable value : values) {
context.write(key, value);
if (++temp==3){
return;
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(OptimizeOrder.class);
job.setMapperClass(OpOrdMapper.class);
job.setReducerClass(OpOrdReduce.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
//设置分割器
job.setPartitionerClass(OptimizeOrderPartitione.class);
//设置分组比较器
job.setGroupingComparatorClass(OptimizeOrderGroupingComparator.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\交金额最大的三笔\\input"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\交金额最大的三笔\\output2"));
job.waitForCompletion(true);
}
}
3.共同好友分析
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
3.1 代码
- 第一步
public class MutualFriend {
public static class MutualFriendMapper extends Mapper<LongWritable, Text, Text, Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(":");
String[] split1 = split[1].split(",");
v.set(split[0]);
for (String s : split1) {
k.set(s);
context.write(k,v);
}
}
}
public static class MutualFriendReduce extends Reducer<Text,Text,Text,Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
List<String> list = new ArrayList<String>();
for (Text value : values) {
list.add(value.toString());
}
v.set(key);
for (int i =0 ;i<list.size()-1;i++){
for (int j = i+1; j<list.size();j++){
k.set(list.get(i)+"-"+list.get(j));
context.write(k,v);
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(MutualFriend.class);
job.setMapperClass(MutualFriendMapper.class);
job.setReducerClass(MutualFriendReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\共同好友\\input"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\共同好友\\output"));
job.waitForCompletion(true);
}
}
结果:
I-K A
I-C A
I-B A
I-G A
I-F A
I-H A
I-O A
I-D A
K-C A
K-B A
K-G A
K-F A
K-H A
K-O A
K-D A
C-B A
C-G A
C-F A
C-H A
C-O A
C-D A
B-G A
B-F A
B-H A
B-O A
B-D A
G-F A
G-H A
G-O A
G-D A
F-H A
F-O A
F-D A
H-O A
H-D A
O-D A
A-F B
A-J B
A-E B
F-J B
F-E B
J-E B
A-E C
A-B C
A-H C
A-F C
A-G C
A-K C
E-B C
E-H C
E-F C
E-G C
E-K C
B-H C
B-F C
B-G C
B-K C
H-F C
H-G C
H-K C
F-G C
F-K C
G-K C
G-C D
G-K D
G-A D
G-L D
G-F D
G-E D
G-H D
C-K D
C-A D
C-L D
C-F D
C-E D
C-H D
K-A D
K-L D
K-F D
K-E D
K-H D
A-L D
A-F D
A-E D
A-H D
L-F D
L-E D
L-H D
F-E D
F-H D
E-H D
G-M E
G-L E
G-H E
G-A E
G-F E
G-B E
G-D E
M-L E
M-H E
M-A E
M-F E
M-B E
M-D E
L-H E
L-A E
L-F E
L-B E
L-D E
H-A E
H-F E
H-B E
H-D E
A-F E
A-B E
A-D E
F-B E
F-D E
B-D E
L-M F
L-D F
L-C F
L-G F
L-A F
M-D F
M-C F
M-G F
M-A F
D-C F
D-G F
D-A F
C-G F
C-A F
G-A F
O-C I
D-E L
E-F M
A-H O
A-I O
A-J O
A-F O
H-I O
H-J O
H-F O
I-J O
I-F O
J-F O
- 第二步
public class MutualFriend2 {
public static class MutualFriend2Mapper extends Mapper<LongWritable, Text, Text, Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
k.set(split[0]);
v.set(split[1]);
context.write(k,v);
}
}
public static class MutualFriend2Reduce extends Reducer<Text,Text,Text,Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
k.set(key+">");
StringBuilder stringBuilder = new StringBuilder();
for (Text value : values) {
stringBuilder.append(value.toString()+"\t");
}
v.set(stringBuilder.toString());
context.write(k, v);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(MutualFriend2.class);
job.setMapperClass(MutualFriend2Mapper.class);
job.setReducerClass(MutualFriend2Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\共同好友\\output"));
FileOutputFormat.setOutputPath(job, new Path("E:\\soft\\java\\ideaProject\\hadoop\\file\\倒排索引demo\\共同好友\\output2"));
job.waitForCompletion(true);
}
}
结果:
A-B> E C
A-D> E
A-E> D C B
A-F> C D B O E
A-G> C
A-H> D O C
A-I> O
A-J> O B
A-K> C
A-L> D
B-D> E A
B-F> C A
B-G> C A
B-H> C A
B-K> C
B-O> A
C-A> D F
C-B> A
C-D> A
C-E> D
C-F> D A
C-G> F A
C-H> A D
C-K> D
C-L> D
C-O> A
D-A> F
D-C> F
D-E> L
D-G> F
E-B> C
E-F> M C
E-G> C
E-H> C D
E-K> C
F-B> E
F-D> E A
F-E> B D
F-G> C
F-H> D A
F-J> B
F-K> C
F-O> A
G-A> E D F
G-B> E
G-C> D
G-D> E A
G-E> D
G-F> D E A
G-H> E A D
G-K> D C
G-L> D E
G-M> E
G-O> A
H-A> E
H-B> E
H-D> A E
H-F> C E O
H-G> C
H-I> O
H-J> O
H-K> C
H-O> A
I-B> A
I-C> A
I-D> A
I-F> A O
I-G> A
I-H> A
I-J> O
I-K> A
I-O> A
J-E> B
J-F> O
K-A> D
K-B> A
K-C> A
K-D> A
K-E> D
K-F> D A
K-G> A
K-H> D A
K-L> D
K-O> A
L-A> F E
L-B> E
L-C> F
L-D> E F
L-E> D
L-F> E D
L-G> F
L-H> E D
L-M> F
M-A> F E
M-B> E
M-C> F
M-D> F E
M-F> E
M-G> F
M-H> E
M-L> E
O-C> I
O-D> A
07_hive_搭建_启动_使用
1. 搭建hive
1.1 上传hive安装包
- 上传apache-hive-1.2.1-bin.tar.gz 压缩包
- 解压
- 在conf下面新建一个 hive-site.xml 文件
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.169.1.221:3306/hive?createDatabaseIfNotExist=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>rootvalue>
<description>password to use against metastore databasedescription>
property>
configuration>
- 上传mysql驱动jar包 到lib下
- 在bin 中 hive即可启动
1.2 hive基本思想
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
1.3 为什么使用Hive
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大 - 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
功能扩展很方便。
1.4 Hive特点
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。 - 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 - 容错
良好的容错性,节点出现问题SQL仍可完成执行。
2 基本使用
2.1 优化使用
- 让提示符显示当前库:
hive> set hive.cli.print.current.db=true;
2、显示查询结果时显示字段名称:
hive>set hive.cli.print.header=true;
但是这样设置只对当前会话有效,重启hive会话后就失效
解决办法:
在linux的当前用户目录中,编辑一个.hiverc文件
将参数写入其中:
vi .hiverc
set hive.cli.print.header=true;
set hive.cli.print.current.db=true;
2.2 将hive 配置进系统变量
vi /etc/profile
export HIVE_HOME=/root/apps/hive/apache-hive-1.2.1-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
source /etc/profile
2.3 启动hive服务使用
启动hive的服务:
bin/hiveserver2 -hiveconf hive.root.logger=DEBUG,console
上述启动,会将这个服务启动在前台,如果要启动在后台,则命令如下:
nohup bin/hiveserver2 1>/dev/null 2>&1 &
启动成功后,可以在别的节点上用beeline去连接
- 方式(1)
bin/beeline
回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//hadoop01:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
- 方式(2)
启动时直接连接:
bin/beeline -u jdbc:hive2://vm03:10000 -n root
接下来就可以做正常sql查询了
2.4 脚本化运行
大量的hive查询任务,如果用交互式shell来进行输入的话,显然效率及其低下,因此,生产中更多的是使用脚本化运行机制:
该机制的核心点是:hive可以用一次性命令的方式来执行给定的hql语句
hive -e "insert into table t_dest select * from t_src;"
然后,进一步,可以将上述命令写入shell脚本中,以便于脚本化运行hive任务,并控制、调度众多hive任务,示例如下:
vi x.sh
#!/bin/bash
hive -e "select * from db_order.t_order"
hive -e "select * from default.t_user"
hql="create table default.t_bash as select * from db_order.t_order"
hive -e "$hql"
如果要执行的hql语句特别复杂,那么,可以把hql语句写入一个文件:
vi x.hql
select * from db_order.t_order;
select count(1) from db_order.t_user;
然后,用
hive -f /root/x.hql
来执行
3 hive建库建表与数据导入
3.1 库
3.1.1 建库
hive中有一个默认的库:
库名: default
库目录:hdfs://hdp20-01:9000/user/hive/warehouse
新建库:
create database db_order;
库建好后,在hdfs中会生成一个库目录:
user/hive/warehouse/db_order.db
3.2 表
3.2.1 基本建表语句
use db_order;//进入db_order库
create table t_order(id string,create_time string,amount float,uid string);
表建好后,会在所属的库目录中生成一个表目录
/user/hive/warehouse/db_order.db/t_order
只是,这样建表的话,hive会认为表数据文件中的字段分隔符为 ^A(vim 中输入^A 为Alt+a)
正确的建表语句为:
create table t_order(id string,create_time string,amount float,uid string)
row format delimited
fields terminated by ',';
这样就指定了表数据文件中的字段分隔符为 “,”
3.2.2 删除表
drop table t_order;
删除表的效果是:
- hive会从元数据库中清除关于这个表的信息;
- hive还会从hdfs中删除这个表的表目录;
3.2.3 修改表定义
仅修改Hive元数据,不会触动表中的数据,用户需要确定实际的数据布局符合元数据的定义。
3.2.3.1 修改表名:
alter table name rename to new_name
3.2.3.2 修改分区名:
alter table t_partition partition(department='xiangsheng',sex='male',howold=20) rename to partition(department='1',sex='1',howold=20);
3.2.3.1 添加分区:
alter table t_partition add partition (department='2',sex='0',howold=40);
3.2.3.1 删除分区:
alter table t_partition drop partition (department='2',sex='2',howold=24);
3.2.3.1 修改表的文件格式定义:
ALTER TABLE table_name [PARTITION partitionSpec] SET FILEFORMAT file_format
alter table t_partition partition(department='2',sex='0',howold=40 ) set fileformat sequencefile;
3.2.3.1 修改列名定义:
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENTcol_comment] [FIRST|(AFTER column_name)]
alter table t_user change price jiage float first;
3.2.3.1 增加/替换列:
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type[COMMENT col_comment], ...)
alter table t_user add columns (sex string,addr string);
alter table t_user replace columns (id string,age int,price float);
3.3 内部表与外部表
内部表(MANAGED_TABLE):
表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中
外部表(EXTERNAL_TABLE):
表目录由建表用户自己指定
create external table t_access(ip string,url string,access_time string)
row format delimited
fields terminated by ','
location '/access/log';
外部表和内部表的特性差别:
- 内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
- drop一个内部表时:hive会清除相关元数据,并删除表数据目录
- drop一个外部表时:hive只会清除相关元数据;
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;
然后,后续的etl操作,产生的各种表建议用managed_table
3.4 分区表
分区表的实质是:在表目录中为数据文件创建分区子目录,以便于在查询时,MR程序可以针对分区子目录中的数据进行处理,缩减读取数据的范围。
比如,网站每天产生的浏览记录,浏览记录应该建一个表来存放,但是,有时候,我们可能只需要对某一天的浏览记录进行分析
这时,就可以将这个表建为分区表,每天的数据导入其中的一个分区;
当然,每日的分区目录,应该有一个目录名(分区字段)
demo1:
1. 创建带分区的表
create table t_access(ip string,url string,access_time string)
partitioned by(dt string)
row format delimited
fields terminated by ',';
注意:分区字段不能是表定义中的已存在字段
2. 向分区中导入数据
load data local inpath '/root/access.log.2017-08-04.log' into table t_access partition(dt='20170804');
load data local inpath '/root/access.log.2017-08-05.log' into table t_access partition(dt='20170805');
3. 针对分区数据进行查询
a. 统计8月4号的总PV:
select count(*) from t_access where dt='20170804';
实质:就是将分区字段当成表字段来用,就可以使用where子句指定分区了
b、统计表中所有数据总的PV:
select count(*) from t_access;
实质:不指定分区条件即可
demo2:
多个分区字段示例
建表:
create table t_partition(id int,name string,age int)
partitioned by(department string,sex string,howold int)
row format delimited fields terminated by ',';
导数据:
load data local inpath '/root/p1.dat' into table t_partition partition(department='xiangsheng',sex='male',howold=20);
3.5 CTAS建表语法
1.可以通过已存在表来建表:
create table t_user_2 like t_user;
//新建的t_user_2表结构定义与源表t_user一致,但是没有数据
2.在建表的同时插入数据
create table t_access_user
as
select ip,url from t_access;
t_access_user会根据select查询的字段来建表,同时将查询的结果插入新表中
3.6 数据导入导出
3.6.1 将数据文件导入hive的表
-
方式1:导入数据的一种方式:
手动用hdfs命令,将文件放入表目录; -
方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录
hive>load data local inpath '/root/order.data.2' into table t_order;
- 方式3:用hive命令导入hdfs中的数据文件到表目录
hive>load data inpath '/access.log.2017-08-06.log' into table t_access partition(dt='20170806');
注意:导本地文件和导HDFS文件的区别:
本地文件导入表:复制
hdfs文件导入表:移动
3.6.1 将hive表中的数据导出到指定路径的文件
- 将hive表中的数据导入HDFS的文件
insert overwrite directory '/root/access-data'
row format delimited fields terminated by ','
select * from t_access;
- 将hive表中的数据导入本地磁盘文件
insert overwrite local directory '/root/access-data'
row format delimited fields terminated by ','
select * from t_access limit 100000;
3.6.2 hive文件格式
HIVE支持很多种文件格式:
SEQUENCE FILE | TEXT FILE | PARQUET FILE | RC FILE
create table t_pq(movie string,rate int) stored as textfile;
create table t_pq(movie string,rate int) stored as sequencefile;
create table t_pq(movie string,rate int) stored as parquetfile;
demo:
1.
先建一个存储文本文件的表
create table t_access_text(ip string,url string,access_time string)
row format delimited fields terminated by ','
stored as textfile;
导入文本数据到表中:
load data local inpath '/root/access-data/000000_0' into table t_access_text;
建一个存储sequence file文件的表:
create table t_access_seq(ip string,url string,access_time string)
stored as sequencefile;
从文本表中查询数据插入sequencefile表中,生成数据文件就是sequencefile格式的了:
insert into t_access_seq
select * from t_access_text;
建一个存储parquet file文件的表:
create table t_access_parq(ip string,url string,access_time string)
stored as parquetfile;
3.7 数据类型
3.7.1 数字类型
TINYINT (1-byte signed integer, from -128 to 127)
SMALLINT (2-byte signed integer, from -32,768 to 32,767)
INT/INTEGER (4-byte signed integer, from -2,147,483,648 to 2,147,483,647)
BIGINT (8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
FLOAT (4-byte single precision floating point number)
DOUBLE (8-byte double precision floating point number)
demo:
create table t_test(a string ,b int,c bigint,d float,e double,f tinyint,g smallint)
3.7.2 日期时间类型
TIMESTAMP (Note: Only available starting with Hive 0.8.0) 时间戳
DATE (Note: Only available starting with Hive 0.12.0)
demo:
假如有以下数据文件:
1,zhangsan,1985-06-30
2,lisi,1986-07-10
3,wangwu,1985-08-09
那么,就可以建一个表来对数据进行映射
create table t_customer(id int,name string,birthday date)
row format delimited
fields terminated by ',';
然后导入数据
load data local inpath '/root/customer.dat' into table t_customer;
然后,就可以正确查询
3.7.3 字符串类型
STRING
VARCHAR (Note: Only available starting with Hive 0.12.0)
CHAR (Note: Only available starting with Hive 0.13.0)
3.7.4 混杂类型
BOOLEAN
BINARY (Note: Only available starting with Hive 0.8.0)
3.7.5 复合类型
3.7.5.1 array数组类型
arrays: ARRAY (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
示例:array类型的应用
假如有如下数据需要用hive的表去映射:
流浪地球,屈楚萧:吴京:李光洁:吴孟达:赵今麦,2019-02-05
飞驰人生,沈腾:黄景瑜:尹正:张本煜:尹昉,2019-02-05
疯狂的外星人,黄渤:沈腾:汤姆·派福瑞:马修·莫里森:徐峥,2019-02-05
设想:如果主演信息用一个数组来映射比较方便
建表:
create table t_movie(moive_name string,actors array,first_show date)
row format delimited fields terminated by ','
collection items terminated by ':';
导入数据:
load data local inpath '/root/movie.dat' into table t_movie;
查询:
select * from t_movie;
select moive_name,actors[0] from t_movie;
select moive_name,actors from t_movie where array_contains(actors,'吴刚');//array_contains(actors,'吴刚');是否存在
select moive_name,size(actors) from t_movie;
3.7.5.2 map类型
maps: MAP (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
1) 假如有以下数据:
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
可以用一个map类型来对上述数据中的家庭成员进行描述
2) 建表语句:
create table t_person(id int,name string,family_members map,age int)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';
3) 查询
select * from t_person;
## 取map字段的指定key的值
select id,name,family_members['father'] as father from t_person;
## 取map字段的所有key
select id,name,map_keys(family_members) as relation from t_person;
## 取map字段的所有value
select id,name,map_values(family_members) from t_person;
select id,name,map_values(family_members)[0] from t_person;
## 综合:查询有brother的用户信息
select
id,name,father
from (
select
id,name,family_members['brother'] as father
from
t_person) tmp
where
father
is not null;
或
select
id,name,age
from
t_family
where
array_contains(map_keys(family_members),'brother');
3.7.5.3 struct类型
structs: STRUCT
1) 假如有如下数据:
1,zhangsan,18:male:beijing
2,lisi,28:female:shanghai
其中的用户信息包含:年龄:整数,性别:字符串,地址:字符串
设想用一个字段来描述整个用户信息,可以采用struct
2) 建表:
create table t_person_struct(id int,name string,info struct)
row format delimited fields terminated by ','
collection items terminated by ':';
3) 查询
select * from t_person_struct;
select id,name,info.age from t_person_struct;
3.7 join关联查询示例
数据:
+------------+------------+--+
| t_a.name1 | t_a.name2 |
+------------+------------+--+
| a | 1 |
| b | 2 |
| c | 3 |
| d | 4 |
+------------+------------+--+
+------------+------------+--+
| t_b.name1 | t_b.name2 |
+------------+------------+--+
| a | xx |
| b | yy |
| d | zz |
| e | pp |
+------------+------------+--+
3.7.1 inner join(join)
sql:
select
a.name1 aname1,
a.name2 aname2,
b.name1 aname1,
b.name2 aname2
from
t_a a inner join
t_b b on
a.name1 = b.name1;
结果:
+---------+---------+---------+---------+--+
| aname1 | aname2 | aname1 | aname2 |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| d | 4 | d | zz |
+---------+---------+---------+---------+--+
3.7.2 left outer join(left join)
sql:
select
a.name1 aname1,
a.name2 aname2,
b.name1 aname1,
b.name2 aname2
from
t_a a left outer join
t_b b on
a.name1 = b.name1;
结果:
+---------+---------+---------+---------+--+
| aname1 | aname2 | aname1 | aname2 |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| c | 3 | NULL | NULL |
| d | 4 | d | zz |
+---------+---------+---------+---------+--+
3.7.3 right outer join(right join)
sql:
select
a.name1 aname1,
a.name2 aname2,
b.name1 aname1,
b.name2 aname2
from
t_a a right outer join
t_b b on
a.name1 = b.name1;
结果:
+---------+---------+---------+---------+--+
| aname1 | aname2 | aname1 | aname2 |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| d | 4 | d | zz |
| NULL | NULL | e | pp |
+---------+---------+---------+---------+--+
3.7.5 full outer join(full join)
sql:
select
a.name1 aname1,
a.name2 aname2,
b.name1 aname1,
b.name2 aname2
from
t_a a full outer join
t_b b on
a.name1 = b.name1;
结果:
+---------+---------+---------+---------+--+
| aname1 | aname2 | aname1 | aname2 |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| c | 3 | NULL | NULL |
| d | 4 | d | zz |
| NULL | NULL | e | pp |
+---------+---------+---------+---------+--+
3.7.6 left semi join
sql:
select
a.name1 aname1,
a.name2 aname2
from
t_a a left semi join
t_b b on
a.name1 = b.name1;
结果:
+---------+---------+--+
| aname1 | aname2 |
+---------+---------+--+
| a | 1 |
| b | 2 |
| d | 4 |
+---------+---------+--+
注意: left semi join的 select子句中,不能有右表的字段
3.8 group by分组聚合
注意:
- 一旦有group by子句,那么,在select子句中就不能有 (分组字段,聚合函数) 以外的字段
- 么where必须写在group by的前面,group by后面的条件只能用having
- where过滤不满足条件的数据
- 用聚合函数和group by进行数据运算聚合,得到聚合结果
- 用having条件过滤掉聚合结果中不满足条件的数据
- upper():
将字段变为大写
select ip, upper(url),time from t_pv_log;
+------------+-----------------------+----------------------+--+
| ip | _c1 | time |
+------------+-----------------------+----------------------+--+
| 10.8.9.41 | HTTP://WWW.BAIDU.COM | 2019-02-24 22:58:22 |
| 10.8.9.42 | HTTP://WWW.BAIDU.COM | 2019-02-24 22:48:22 |
| 10.8.9.43 | HTTP://WWW.BAIDU.COM | 2019-02-24 22:52:22 |
| 10.8.9.44 | HTTP://WWW.BAIDU.COM | 2019-02-24 22:53:22 |
+------------+-----------------------+----------------------+--+
- 分组
select url,count(id) nub from t_pv_log group by url;
+-------------------------+------+--+
| url | nub |
+-------------------------+------+--+
| http://www.baidu.com | 15 |
| http://www.baidu.com/a | 6 |
| http://www.baidu.com/b | 2 |
| http://www.baidu.com/c | 6 |
| http://www.baidu.com/d | 1 |
+-------------------------+------+--+
- 分组聚合
select url,max(time) nub from t_pv_log group by url;
+-------------------------+----------------------+--+
| url | nub |
+-------------------------+----------------------+--+
| http://www.baidu.com | 2019-02-24 22:59:26 |
| http://www.baidu.com/a | 2019-02-24 22:58:27 |
| http://www.baidu.com/b | 2019-02-24 22:58:25 |
| http://www.baidu.com/c | 2019-02-24 22:59:26 |
| http://www.baidu.com/d | 2019-02-24 22:53:22 |
+-------------------------+----------------------+--+
4 hive函数使用
都是对某一个字段的转换
hive函数手册
select substring ("abcdefghigk",1,3);//是从1开始 所有0或1 都是第一个
+------+--+
| _c0 |
+------+--+
| abc |
+------+--+
4.1 常用内置函数
4.1.1 类型转换函数
select cast("5" as int);
select cast("2019-02-25" as date) ;
select cast(current_timestamp as date);
//current_timestamp 为当前时间
//unix_timestamp() 毫秒时间
4.1.2 数学运算函数
- round() 随机数
select round(5.4) ;
select round(5.1345,3) ;
- 向上取整
select ceil(5.4) ;
- 向下取整
select floor(5.4);
- 取绝对值
select abs(-5.4);
- 取最大值
select greatest(3,5,6) ;
- 取最小值
select least(3,5,6);
4.1.3 字符串函数
- 截取子串
substr(string, int start)
substring(string, int start)
示例:select substr("abcdefg",2);//bcdefg
substr(string, int start, int len)
substring(string, int start, int len)
示例:select substr("abcdefg",2,3); //bcd
- 拼接字符串
concat(string A, string B...)
concat_ws(string SEP, string A, string B...)
示例:select concat("ab","xy"); //abxy
select concat_ws(".","192","168","33","44");//192.168.33.44
- 求长度
length(string A)
示例:select length("192.168.33.44");//13
- 分割
split(string str, string pat)
示例: select split("192.168.33.44","\\.");
- 转大写
upper(string str)
4.1.4 时间函数
- 取当前时间的毫秒数时间戳
select unix_timestamp();
- unix时间戳转字符串
from_unixtime(bigint unixtime[, string format])
示例:select from_unixtime(unix_timestamp());
select from_unixtime(unix_timestamp(),"yyyy/MM/dd HH:mm:ss");
- 字符串转unix时间戳
unix_timestamp(string date, string pattern)
示例: select unix_timestamp("2017-08-10 17:50:30");
select unix_timestamp("2017/08/10 17:50:30","yyyy/MM/dd HH:mm:ss");
- 将字符串转成日期date
select to_date("2017-09-17 16:58:32");
08_sqoop
1. 搭建sqoop
1.1 上传文件
1.2 修改配置文件
- 修改名称
/conf/sqoop-env-template.sh名字为/conf/sqoop-env.sh - 修改文件内容
export HADOOP_COMMON_HOME=
export HADOOP_MAPRED_HOME=
export HIVE_HOME=
在vim下 直接获取地址 :r!whice hadoop
-
上传jdbc jar包
上传到 /lib下 -
配进环境
vi /etc/profile
export SQOOP_HOME=/root/apps/sqoop/sqoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$SQOOP_HOME/bin
source /etc/profile
2 测试启动
./sqoop-list-databases --connect jdbc:mysql://mycp:3306/ --username root --password root
./sqoop-list-tables --connect jdbc:mysql://mycp:3306/bigdata --username root --password root
3 导入导出数据
3.1 修改每台服务器的mapred-site.xml.template
mv mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
3.2 导入表表数据到HDFS
./sqoop import \
--connect jdbc:mysql://mycp:3306/bigdata \
--username root \
--password root \
--target-dir \
/sqooptest \
--fields-terminated-by ',' \
--table emp \
--split-by id \
--m 2
如果出现错误
执行mapreduce没报错,可是任务运行到running job就卡住在
INFO mapreduce.Job: Running job: job14039055428930004
解决方法 mapred-site.xml下将
mapreduce.framework.name
yarn
改成
mapreduce.job.tracker
hdfs://192.168.1.120:8001
true
其中ip是master地址。
3.3 导入表表数据到Hive
3.3.1 导入全部的数据
./sqoop import \
--hive-import \
--connect jdbc:mysql://mycp:3306/bigdata \
--username root \
--password root \
--table emp \
--split-by id \
--m 2
hive导入参数
--hive-home 重写$HIVE_HOME
--hive-import 插入数据到hive当中,使用hive的默认分隔符
--hive-overwrite 重写插入
--create-hive-table 建表,如果表已经存在,该操作会报错!
--hive-table [table] 设置到hive当中的表名
--hive-drop-import-delims 导入到hive时删除 \n, \r, and \01
--hive-delims-replacement 导入到hive时用自定义的字符替换掉 \n, \r, and \01
--hive-partition-key hive分区的key
--hive-partition-value hive分区的值
--map-column-hive 类型匹配,sql类型对应到hive类型
如果出现错误
18/12/12 11:25:35 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
复制hive lib 包下面的hive-common-1.1.0-cdh5.7.0.jar 至sqoop lib 包下
3.3.2 导入部分数据
3.3.2.1 自定义导入部分数据
- 方法1(导入dfs):
sqoop import \
--connect jdbc:mysql://mycp:3306/bigdata \
--username root \
--password root \
--where "city ='sec-bad'" \
--target-dir /wherequery \
--table emp_add \
--m 1
- 方法2(导入dfs):
sqoop import \
--connect jdbc:mysql://mycp:3306/bigdata \
--username root \
--password root \
--target-dir /wherequery2 \
--query 'select id,name,deg from emp WHERE id>1207 and $CONDITIONS' \
--split-by id \
--fields-terminated-by '\t' \
--m 2
and $CONDITIONS为固定写法
3.3.2.2 增量导入
sqoop支持两种增量MySql导入到hive的模式一种是append,
-
即通过指定一个递增的列
--incremental append --check-column num_id --last-value 0 -
是可以根据时间戳,比如:
--incremental lastmodified --check-column created --last-value '2012-02-01 11:0:00'
就是只导入created 比’2012-02-01 11:0:00’更大的数据。
导入dfs——demo:
sqoop import \
--connect jdbc:mysql://mycp:3306/bigdata \
--target-dir \
/sqooptest \
--username root \
--password root \
--table emp --m 1 \
--incremental append \
--check-column id \
--last-value 1205
--incremental append \追加
注意:增量导入不适合直接导入hive 只能通过导入hdfs导入hive
分隔符最后 自定义 否则追加到hive 很容易出问题 (默认分隔符为\001)
3.4 导出数据到mysql
sqoop export \
--connect jdbc:mysql://mycp:3306/bigdata \
--username root \
--password root \
--fields-terminated-by '\001' \
--table emp_add \
--export-dir /user/hive/warehouse/emp_add
其他
更新软件
sudo apt-get update
安装jdk
sudo apt-get install openjdk-8-jdk
查看java版本
java -version
ssh 安装
sudo apt-get install openssh-server
如果遇到错误可能是无root登录权限 那么就修改/etc/ssh/sshd_config文件中 添加一条 PermitRootLogin yes然后重启ssh服务 sudo service ssh restart
vim编辑器出问题
步骤一,输入下述命令以卸载vim-tiny:
sudo apt-get remove vim-common
步骤二,输入下述命令以安装vim-full:
sudo apt-get install vim
mysql 安装:
- 首先执行下面三条命令:
sudo apt-get install mysql-server
sudo apt install mysql-client
sudo apt install libmysqlclient-dev
- 安装成功后可以通过下面的命令测试是否安装成功:
sudo netstat -tap | grep mysql
出现如下信息证明安装成功:
tcp 0 0 localhost:mysql *:* LISTEN 8154/mysqld
- 可以通过如下命令进入mysql服务:
mysql -uroot -p你的密码
- 现在设置mysql允许远程访问,首先编辑文件
/etc/mysql/mysql.conf.d/mysqld.cnf
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
注释掉bind-address = 127.0.0.1:
保存退出,然后进入mysql服务,执行授权命令:
grant all on *.* to root@'%' identified by '你的密码' with grant option;
flush privileges;
然后执行quit命令退出mysql服务,执行如下命令重启mysql:
service mysql restart
hive 启动:
nohup bin/hiveserver2 1>/dev/null 2>&1 &
bin/beeline -u jdbc:hive2://vm03:10000 -n root