LightGBM算法框架一文详解!

简介
微软DMTK团队在 github上开源了性能超越其他 boosting decision tree工具 ! LIGHTGBM,三天之内star了1000+次,fork了200+次。知乎上有近干人关注如何看待微软开源的 Lightgbm? 问题,被评价为速度惊人”,“非常有启发”,“支持分布式",“代码清晰易慬",“占用内存小"等。
lightgbm主要涉及分类、回归、排序等。属于监督学习算法。
通过调整模型参数w使得损失函数最小化,但一昧的最小化模型输出和数据标度的差异,可能会使得模型过拟合,所以通畅加一些正则项来控制模型,比如下图中的L1正则,从而将有监督的学习目标变成了损失函数和正则项的加和。

Boosting简介
LightGBM属于Boosting的一种。Boosting就是指用一系列的模型线性组合来完成模型任务。在Boosting学习中,逐步的确定每一个模型之间,每一个子模型叠加到复合模型当中来,在这个过程中保证损失函数随着子模型的增加而逐渐减少。
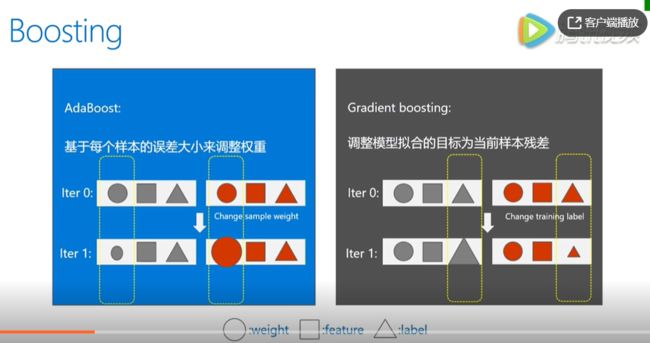
Boosting有两种,AdaBoost和Gradient Boost。
总的来说,Boosting方法都是在训练好子模型后,统计现有的复合模型的拟合情况,从而调整接下来学习任务的一些setting,使得接下来,找到的子模型加入复合模型之后,符合降低整体loss的目标。

AdaBoost和Gradient Boosting特点
AdaBoost
根据当前的loss来改变样本权重,比如这个样本在学习中误差比较大,则获得一个大的权重,反之获得更小的权重,从而控制后续子模型的产生。
Gradient Boosting
直接修改样本label,新的样本的label将变成原来的label和已知形成的模型预测值之间的残差。
从两者来看,gradient boosting 更倾向于降低训练误差的角度去完成算法乘积。
Gradient Boosting
完整的模型是由很多“base learner”的子模型组成,学习中是一个个增加子模型,并希望loss能够不断减小。如果把复合函数f(x)看成自变量,我们希望改变这个复合函数使得loss下降,那么沿着loss相对于f的梯度方向是一个合理的选择。简单来说,如果我们新加入的子模型使得f沿着loss相对于f的梯度方向变了,那么我们就得到了我们希望要的子模型。
在实际问题中,比如我们定义的loss是平方误差,也就是L2 loss,那么梯度方向就是估计值与样本值之间的残差,如下图。我们新加入的子模型,就应该朝着这个残差来学习,也就是下图显示的:
f m ( x ) f_m(x) fm(x)

GBDT
了解了gradient boosting,接下来GBDT就好理解了。
也就是当gradient boosting中,每一个base learner(基础学习器?)都是一个decision tree(决策树)时,我们就把它叫做GBDT。
GBDT可以完成分类、回归,排序(ranking)任务等。

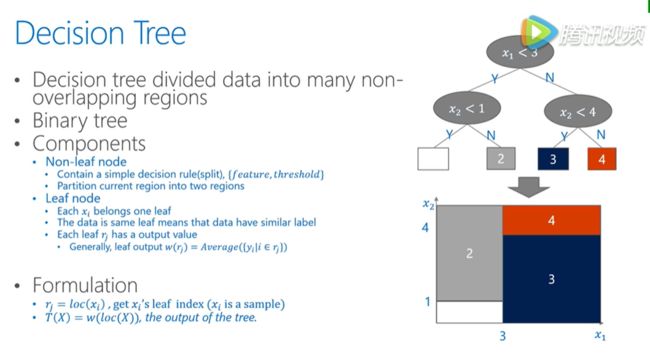
Decision Tree
就是把数据的feature value划分成很多不重叠的区域,一般来说我们都是指的二叉树,树种的叶子节点需要做分割。所以会包含分割点信息,有哪个为feature,然后这个为feature,我们用什么将数据分为左边和右边两个部分,从而不断把树长的更深。
而在叶子节点,包含了最重要的分类信息,也是纯度最大的地方,归类到同一个叶子节点的数据会被归类到一起,生成叶子节点的数值。会用在这个节点上所有样本的均值来作为这个节点的输出。
决策树是如何学习的
decision tree学习过程可以分为两种。一种,叫做leaf-wise learning,也就是说学习过程中,我们需要不断的寻找分类后收益最大的叶子节点,然后对其进行进一步的分裂,从而生长成树,这种方法能够更加快速有效的寻找模型,但是整个生长的过程都是顺序的不方便加速。
也因此提出了另一种方法,Level-wise learning
也就是说树的生长是按层去长的,不需要每次去挑选生长的节点,只需要按顺序去长,这样在每一个level中各个节点的分类可以并行的完成,有天然的并行性,但是这样会产生很多没必要的分类,也许会造成更大的计算代价。

decision tree伪代码
在每一个需要分类的点,我们去寻找最佳的分类位置,也就是根据当前节点的数据,找到当前节点最佳的分裂需要用的最佳的特征值进行分裂。寻找这个最佳特征值的过程在下图中右框里。
遍历所有特征值和可能的取值,假设在某一点把数据分成两部分后带来的损失变化,通过逐一比较找到能让我们获得最大收益的点,确定哪一个leaf要进行分裂。也就是图中的
p m : 最 大 收 益 点 p_m:最大收益点 pm:最大收益点
f m : 是 哪 一 维 度 特 征 f_m:是哪一维度特征 fm:是哪一维度特征
v m : 是 指 的 这 个 维 度 特 征 g a i n 最 高 的 v a l u e , 大 于 这 个 值 的 放 在 左 边 , 小 于 这 个 值 的 放 在 右 边 。 v_m:是指的这个维度特征gain最高的value,大于这个值的放在左边,小于这个值的放在右边。 vm:是指的这个维度特征gain最高的value,大于这个值的放在左边,小于这个值的放在右边。

FindBestsplit是计算代价最大的地方,GBDT就是不断增加新的decision tree来拟合之前的残差,每个树的学习都包含了整个decision tree的流程。
现有GBDT工具介绍
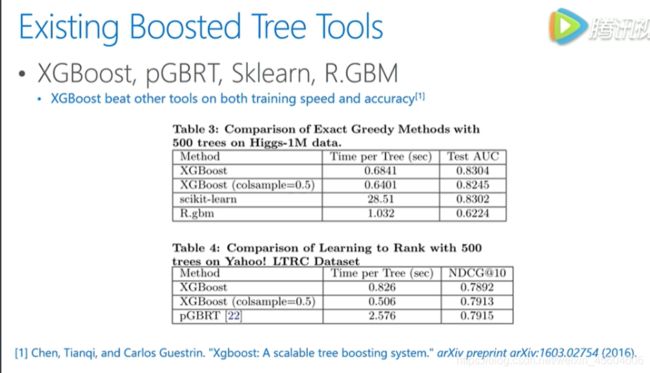
其中XGBoost性能相比其他更具要更好点,特别是速度上的优势,其次提供了很好的接口,方便使用。
从上图可以看到xgboost的训练时间和最后的结果都比较优秀。
XGBoost特点介绍

XGBoost是一种基于预排序的方法,它会将每一个unique的feature value做计算,好处是能够找到特定的feature value来做为分割点,不好的地方就是这种方法的计算和存储代价都非常大。并且这样找到的特别精确的分割点可能存在过拟合,另外它生长每颗树的方法是按层生长,即level-wise learning。按层生长会带来不少的时间好处,每一层可以都对所有数据做操作,但是会有一些不必要的运算,比如一些节点不需要分裂计算。
LightGBM
与XGBoost类似,他也是一个gradient boosting的框架,设计初衷是并行与高效。
它具有训练速度快,内存使用少,处理了类别特征,大大加快了训练速度,也有更好的模型精度。
下面表格给出了lgb和xgb之间更加细致的性能对比,包括树的生长,方式,分裂。

lgb采用的是生长方法是leaf-wise learning,减少了计算量,当然这样的算下下也需要控制树的深度和每个叶节点的最小的数据量,从而减少over fit。分裂点,xgb采取的是预排序的方法,而lgb采取的是histogram算法,即将特征值分为很多小桶,直接在这些桶上寻找分类,这样带来了存储代价和计算代价等方面的缩小,从而得到更好的性能。
另外,数据结构的变化也使得细节处理方面效率有所不同,比如对缓存的利用,lgb更加高效。从而使得它右很好的加速性能,特别是类别特征处理,也使得lgb在特定的数据集上有非常大的提升。
下图是数据集上的实验对比。

左边对比了应用上的准确率、内存使用情况。其中Higgas、Expo都是分类数据,Yahoo LTR 和 MSLTR 都是排序数据。可以看到lgb在这些数据集上的表现都更好。
右边是计算速度的对比,可见lgb完成相同的数据集速度要几倍于xgb。
LightGBM的细节技术讲解
Histogram optimization(直方图优化)
在XGB中,采用了预排序的方法,计算过程中按照feature value排序,逐个数据样本来进行当前 feature value 样本的分裂收益,这样算法能够精确找到最佳分裂值,带式代价非常大,也不具有好的推广性。
在LGB中,将这些连续的或者精确的每一个 feature value 划分到一系列的离散值,也就是所说的桶里面,下图即拿浮点型的特征来举例。
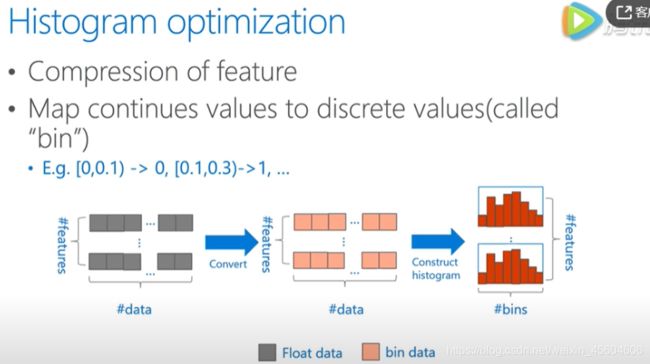
一个区间的值,会被作为一个桶,比如 [0,0.1) 为第零个桶…,有了分桶的信息,建立起来基于分桶的直方图的统计,之后的计算都会基于这些以分桶为精度单位的直方图来做。
这样一来,数据的表达更为简化,减少了数据的使用,而且直方图带来了一定的正则化的效果,使得我们的模型不容易 over fitting 有着更好的推广性。下面是做过直方图后寻找最佳分裂点的求解函数的伪代码。

可以看到,这是按照 bin(桶) 来索引 直方图的,所以不需要按照每个 feature 来排序,也不需要一一对比所有不同 feature 值,大大的减少了运算量。
存储优化
当我们用 feature bin 来描述数据时,memory 的变化如下图。
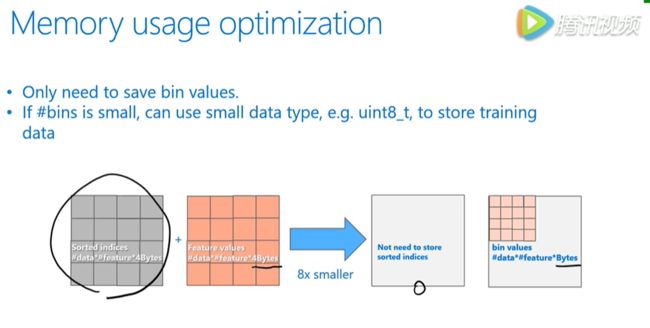
首先,我们不需要像XGB那样,存储预排序对应的data的序列,也就是灰色方格,因此这个代价就变成了0,另外用 bin 表示 feature 可以有效减少占用的存储空间(一般bin不会设置太多)。
带有深度限制的 Leaf-wise learning
lgb采用了带有深度限制的 leaf-wise 学习来提高模型精度。
leaf-wise 相对于 level-wise ,更加的高效,还可以降低更多的训练误差,得到更好的精度,但单纯使用它来进行生长,可能会长出比较深的树,在小数据集上可能造成过拟合,因此在 leaf-wise 上,多加了深度的限制。
直方图做差
lgb还使用了直方图做差的优化,可以观察到一个叶子节点上的直方图可以由它的 父节点直方图减去兄弟节点的直方图来得到,根据这点,我们可以构造出来计算数据量比较小的叶子节点直方图,然后用直方图做差得到中间较大的叶子节点的直方图,达到加速的效果。

Increase cache hit chance(提高缓存命中率吧)
pre-sorted算法中有两个操作频繁的地方,会造成 cache missed 。对梯度的访问,在计算gain时需要用到梯度,不同的 feature 访问梯度的舒徐是不一样的并且是随机的。对于索引表的访问,pre-sorted有个行号和叶节点号的索引表,可以防止数据切分的时候对所有的 feature 进行切分。访问梯度也一样,所有的 feature 都需要通过访问索引表,所以都是随机访问,会带来非常大的系统性能的下降。
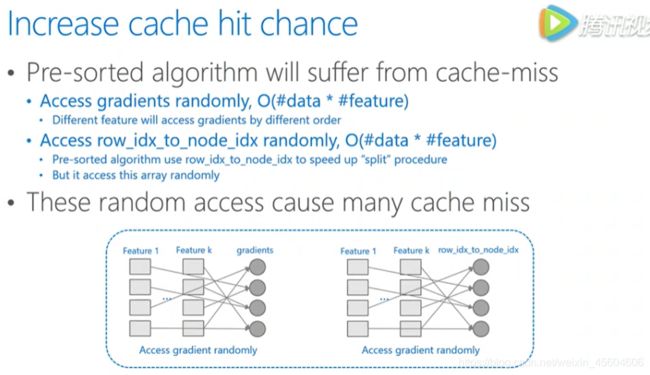
而 lightgbm 使用的直方图算法则是天然的 cache friendly。首先,对梯度的访问,因为不需要对 feature 进行排序,同时所有的 feature 都用同样的方式来访问,所以只需要对梯度访问的顺序进行一个排序,所有的 feature 都能连续的访问梯度。并且直方图算法不需要数据 ID 到叶节点号的索引表,所以没有占用 cache 的问题,cache * 对速度的影响是很大的,尤其是数据量很大的时候,相比于随机访问,顺序访问速度可以快四倍以上。

支持直接输入类别特征
传统对的机器学习算法不能直接输入类别特征,需要先离散化,这样的空间或者时间效率都不高。lgb通过更改决策树算法的决策规则,直接原生支持类别特征,不许额外离散化。速度快了8倍以上。

并行学习支持
lgb原生支持多种并行的算法,适用不同的数据场景,当 feature 并行时,通常适用于小数据但是 feature 比较多的场景。data 并行适用数据量比较大但是 feature 量比较少的情景。Voting 则适用数据量大且 feature 也很多的场景。

Feature/Attribute Parallelization
通过垂直切分数据在不同机器上都用所有的数据样本点,但是有不同的特征,不同机器上寻找不同特征上的最优分割点进行全局的同步,得到全局的最优分割点。
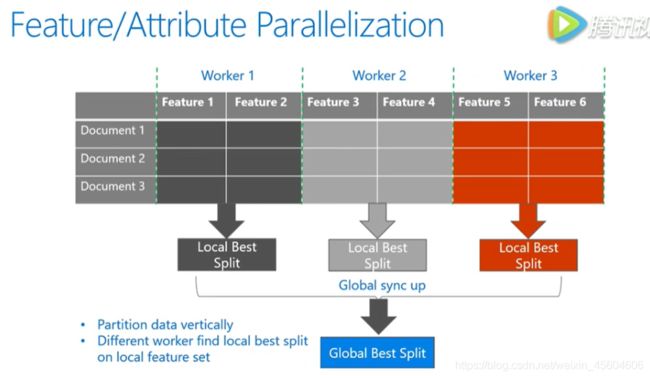
Data Parallelization
data并行通过水平切分数据,让不同机器拥有不同的数据,并行的时候让不同的机器首先用稳定的数据构造好直方图,然后进行一个全局的直方图合并,在合并好的全局直方图上寻找最佳分割点。

基于投票的并行
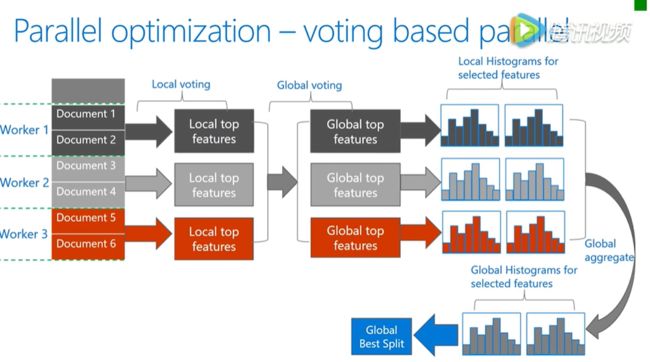
是对于数据并行的优化,数据并行的瓶颈主要在于合并直方图的时候,空间代价比较大,根据这一点,基于投票的方式,只和并部分特征值的直方图,达到了降低通信量的目的。
首先通过本地的数据找到本地的 top features ,然后利用投票筛选出可能是全局最优点的特征,合并直方图时只和并这些被选出来的特征,由此减低了通信量。
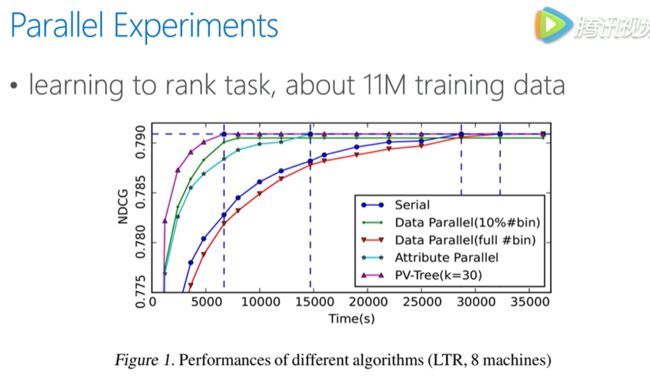
以下是几种并行算法的实验对比
可以看到 voting 并行可以比其他几种算法更快的达到收敛点,并且精度几乎与原来一致。
其他方面的特点
使用经验


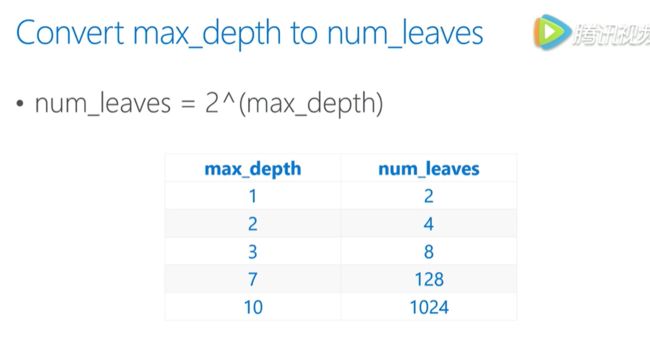
因为lgb采用的是 leaf-wise learning 来生成树,所以树的深度与叶子数有关。以下是参考。
随机减少特征来加速,实践中不会损失太多的精度。
直接输入类别特征,不需要哑变量,更快。
如果一个文件训练多次,可以保存成二进制的文件,这样训练起来会更快。

比较小的学习率,更加多的迭代次数,一般会提高正确率。过拟合情况下,增加叶子节点数也能提高精度。或者用交叉验证的方式,对比一些参数,找到更好的参数。训练数据越多,训练精度也有提升。

防止过拟合方法,第三、五点用的最多。

以下为相应参考资料。

参考文章及视频
1.https://v.qq.com/x/page/k0362z6lqix.html
2.https://blog.csdn.net/weixin_38569817/article/details/78808535
大家可以关注我的公众,后续会有更多干货和大家分享!

码字不易,希望大家如果觉得“文”有所值,帮忙我转发一下吧,谢谢大家!
往期文章
数据分析怎么做?看这篇就够了!
Webscraper让你不用编程也能爬虫!
科学吃瓜,你造吗?
个人公众号简介