python爬取芒果TV《乘风破浪的姐姐》弹幕数据(已完成)
爬取平台:芒果TV
爬取内容:《乘风破浪的姐姐》弹幕数据(以前6期为例)
爬取工具:Anaconda3 Spyder
爬取日期:2020年7月1日
打开节目网页,通过开发者工具Network中的XHR我们可以发现,随着节目的播放,每隔一分钟XHR中会新增一个json文件。
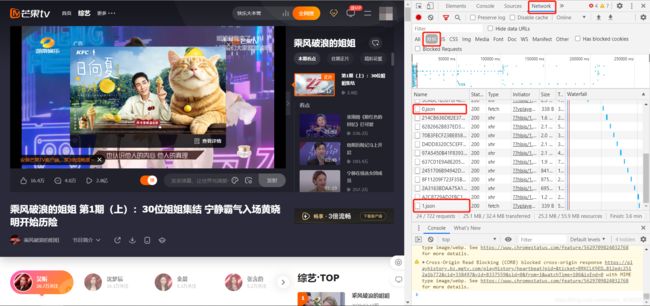
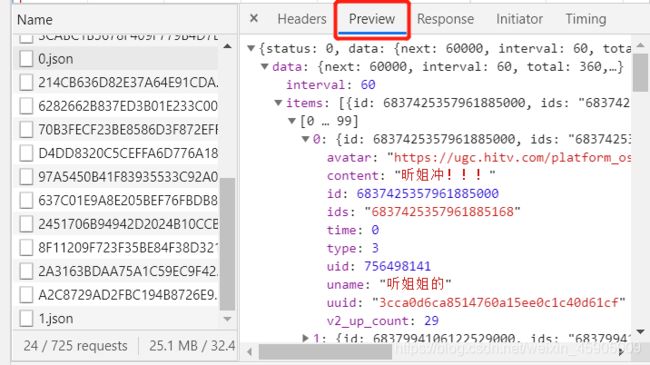
查看json文件,可以发现每个json文件都存储着前一分钟内所有的弹幕数据,主要包括用户名、弹幕内容、点赞数等,因此,节目时长(min)=json文件数。
在本次实验中,主要爬取用户id、用户名uname、弹幕内容content、发布时间time、弹幕点赞数v2_up_count。
在Headers中可以获取每个json文件的url(图是7.14补的,所以和代码里的url有差异,问题不大),发现同一期节目json文件的url日期后两个数字是一样的,可以通过这两个数字定位到节目的某一集。

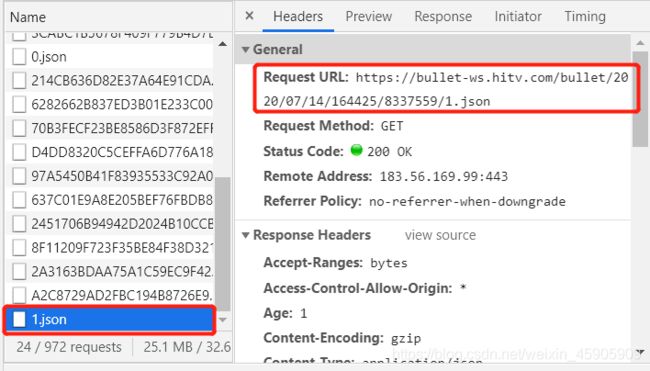
找到url的规律后开始写代码。
首先导入requests库、json库、pandas库。
import requests
import json
import pandas as pd
构建get_danmu(num1,num2,page)函数,其中num1、num2为url日期后的两个数字,page是json文件后缀前的数字(即节目分钟数)。
代码中用到的函数:
format():格式化输出,即将format()后面的内容,填入大括号中(可以按位置,可以按变量)
requests.get():向指定的资源发出请求
res.text:获取文本信息(否则只返回HTTP状态码)
json.loads():将json格式数据(字符串)转换为字典
#提取某一期的弹幕
def get_danmu(num1,num2,page):
try:
url='https://bullet-ws.hitv.com/bullet/2020/07/1/{}/{}/{}.json'
danmuurl = url.format(num1,num2,page)
res=requests.get(danmuurl)
res.encoding = 'utf-8'
jd=json.loads(res.text)
except:
print("无法连接")
details=[]
for i in range(len(jd['data']['items'])): #弹幕数据在json文件'data'的'items'中
result={}
result['stype']=num2 #通过stype可识别期数
result['id']=jd['data']['items'][i]['id'] #获取id
try: #尝试获取uname
result['uname']=jd['data']['items'][i]['uname']
except:
result['uname']=''
result['content']=jd['data']['items'][i]['content'] #获取弹幕内容
result['time']=jd['data']['items'][i]['time'] #获取弹幕发布时间
try: #尝试获取弹幕点赞数
result['v2_up_count']=jd['data']['items'][i]['v2_up_count']
except:
result['v2_up_count']=''
details.append(result)
return details
设置输入关键信息的代码(也可以自己新建一个list写循环)
#输入关键信息
def count_danmu():
danmu_total=[]
num1=input('第一个数字')
num2=input('第二个数字')
page=int(input('输入总时长'))
for i in range(page):
danmu_total.extend(get_danmu(num1,num2,i))
return danmu_total
设置需要循环爬取的次数
def main():
danmu_end=[]
#爬前六集,设置循环6次
for j in range(6):
danmu_end.extend(count_danmu())
df=pd.DataFrame(danmu_end)
df.to_excel('test\data\danmu.xlsx')
if __name__ == '__main__':
main()
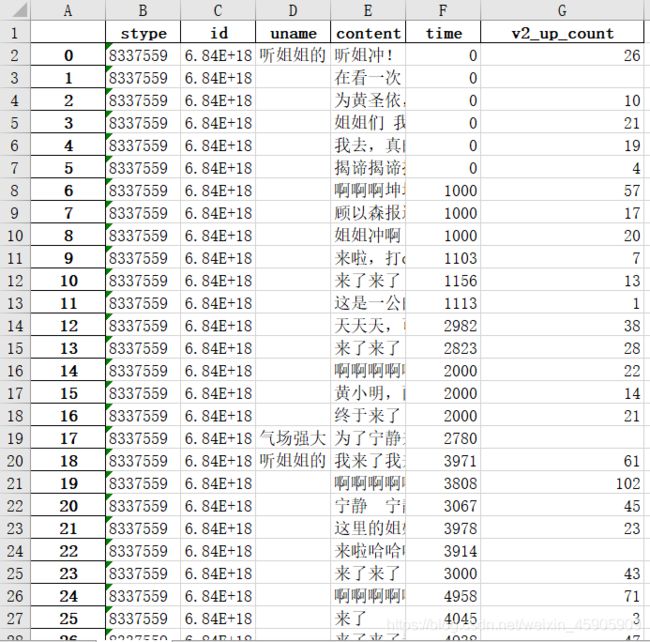
运行后即可获得danmu.xlsx文件。
截止至7月1日17:00,共爬取弹幕201,633条,其中:
第一期(上)36,043条,第一期(下)48,022条;
第二期35,822条,第二期(加更版)12,299条;
第三期57,479条,第三期(加更版)11,968条。
本次实验参考https://blog.csdn.net/bo_gu/article/details/106947576,并在此基础上进行了更详细的解说,感谢这位博主。