Merkle DAG 和 Merkle Tree的区别
Merkle DAG 和 Merkle Tree的区别
-
对于IPFS,Merkle DAG 和 Merkle Tree是两个很重要的概念。
-
Merkle DAG是IPFS的存储对象的数据结构, Merkle Tree则用于区块链交易的验证。
-
Merkle Tree通常也被称为哈希树(Hash Tree),就是存储哈希值的一颗树;而Merkle DAG是默克尔有向无环图的简称。二者有相似之处,也有一些区别。
-
从对象格式上, Merkle Tree的叶子是数据块(例如,文件、交易)的哈希值。非叶节点是其对应子节点串联字符串的哈希值。Merkle DAG的节点包括两个部分,Data和Link;Data为二进制数据,Link包含Name、Hash和Size这三个部分。从数据结构上看,Merkle DAG是Merkle Tree更普适的情况,换句话说,Merkle Tree是特殊的Merkle DAG。从功能上看,后者通常用于验证数据的完整性,而前者大多用于文件系统。
Merkle Tree
Merkle Tree可以看做Hash List的泛化(Hash List可以看作一种特殊的Merkle Tree,即树高为2的多叉Merkle Tree)。
在最底层,和哈希列表一样,我们把数据分成小的数据块,有相应地哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就结婚生子,得到了一个”子哈希“。如果最底层的哈希总数是单数,那到最后必然出现一个单身哈希,这种情况就直接对它进行哈希运算,所以也能得到它的子哈希。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,我们把它叫做 Merkle Root[3]。
在p2p网络下载网络之前,先从可信的源获得文件的Merkle Tree树根。一旦获得了树根,就可以从其他从不可信的源获取Merkle tree。通过可信的树根来检查接受到的Merkle Tree。如果Merkle Tree是损坏的或者虚假的,就从其他源获得另一个Merkle Tree,直到获得一个与可信树根匹配的Merkle Tree。
Merkle Tree和Hash List的主要区别是,可以直接下载并立即验证Merkle Tree的一个分支。因为可以将文件切分成小的数据块,这样如果有一块数据损坏,仅仅重新下载这个数据块就行了。如果文件非常大,那么Merkle tree和Hash list都很到,但是Merkle tree可以一次下载一个分支,然后立即验证这个分支,如果分支验证通过,就可以下载数据了。而Hash list只有下载整个hash list才能验证
- 应用案例
1.数字签名
最初Merkle Tree目的是高效的处理Lamport one-time signatures。 每一个Lamport key只能被用来签名一个消息,但是与Merkle tree结合可以来签名多条Merkle。这种方法成为了一种高效的数字签名框架,即Merkle Signature Scheme。
2. P2P网络
在P2P网络中,Merkle Tree用来确保从其他节点接受的数据块没有损坏且没有被替换,甚至检查其他节点不会欺骗或者发布虚假的块。大家所熟悉的BT下载就是采用了P2P技术来让客户端之间进行数据传输,一来可以加快数据下载速度,二来减轻下载服务器的负担。BT即BitTorrent,是一种中心索引式的P2P文件分分析通信协议[7]。
要进下载必须从中心索引服务器获取一个扩展名为torrent的索引文件(即大家所说的种子),torrent文件包含了要共享文件的信息,包括文件名,大小,文件的Hash信息和一个指向Tracker的URL[8]。Torrent文件中的Hash信息是每一块要下载的文件内容的加密摘要,这些摘要也可运行在下载的时候进行验证。大的torrent文件是Web服务器的瓶颈,而且也不能直接被包含在RSS或gossiped around(用流言传播协议进行传播)。一个相关的问题是大数据块的使用,因为为了保持torrent文件的非常小,那么数据块Hash的数量也得很小,这就意味着每个数据块相对较大。大数据块影响节点之间进行交易的效率,因为只有当大数据块全部下载下来并校验通过后,才能与其他节点进行交易。
就解决上面两个问题是用一个简单的Merkle Tree代替Hash List。设计一个层数足够多的满二叉树,叶节点是数据块的Hash,不足的叶节点用0来代替。上层的节点是其对应孩子节点串联的hash。Hash算法和普通torrent一样采用SHA1。其数据传输过程和第一节中描述的类似
3. BitCoin和Ethereum
Merkle Proof最早的应用是Bitcoin,它是由中本聪在2009年描述并创建的。Bitcoin的Blockchain利用Merkle proofs来存储每个区块的交易。
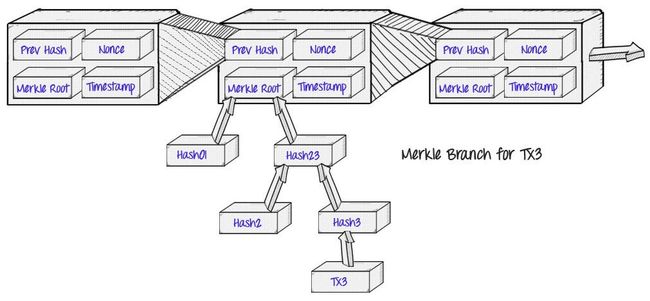
而这样做的好处,也就是中本聪描述到的“简化支付验证”(Simplified Payment Verification,SPV)的概念:一个“轻客户端”(light client)可以仅下载链的区块头即每个区块中的80byte的数据块,仅包含五个元素,而不是下载每一笔交易以及每一个区块:
- 上一区块头的哈希值
- 时间戳
- 挖矿难度值
- 工作量证明随机数(nonce)
- 包含该区块交易的Merkle Tree的根哈希
如果客户端想要确认一个交易的状态,它只需简单的发起一个Merkle proof请求,这个请求显示出这个特定的交易在Merkle trees的一个之中,而且这个Merkle Tree的树根在主链的一个区块头中。
但是Bitcoin的轻客户端有它的局限。一个局限是,尽管它可以证明包含的交易,但是它不能进行涉及当前状态的证明(如数字资产的持有,名称注册,金融合约的状态等)。
Bitcoin如何查询你当前有多少币?一个比特币轻客户端,可以使用一种协议,它涉及查询多个节点,并相信其中至少会有一个节点会通知你,关于你的地址中任何特定的交易支出,而这可以让你实现更多的应用。但对于其他更为复杂的应用而言,这些远远是不够的。一笔交易影响的确切性质(precise nature),可以取决于此前的几笔交易,而这些交易本身则依赖于更为前面的交易,所以最终你可以验证整个链上的每一笔交易。为了解决这个问题,Ethereum的Merkle Tree的概念,会更进一步。
Ethereum的Merkle Proof
每个以太坊区块头不是包括一个Merkle树,而是为三种对象设计的三棵树:
- 交易Transaction
- 收据Receipts(本质上是显示每个交易影响的多块数据)
- 状态State
Merkle DAG
-
Merkle DAG 的全称是Merkle directed acyclic graph(默克尔有向无环图)。它是在Merkle Tree的基础上构建的,与其非常相似,但不完全一样,比如Merkle DAG 不需要进行树的平衡操作、非叶子节点包含数据等。Merkle DAG是IPFS的核心概念,也是Git、Bitcoin和dat等技术的核心。散列树由内容块组成,每个内容块由其加密散列标识。IPFS add命令将从你指定的文件的数据创建Merkle DAG 。执行操作时,它遵循unixfs数据格式。这意味着你的文件被分解成块,然后使用“链接节点”以树状结构排列,以将它们连接在一起。给定文件的“散列”实际上是DAG种根节点(最上层)的散列。
-
Merkle DAG的功能
•内容寻址:使用多重哈希来唯一识别一个数据块的内容
•防篡改:可以方便的检查哈希值来确认数据是否被篡改
•去重:由于内容相同的数据块哈希是相同的,可以很容去掉重复的数据,节省存储空间
第三条是IPFS系统中,最为重要的一个特性,在IPFS系统中,每个Block的大小限制在256KB(可以通过参数进行选定),那些相同的数据就能通过Merkle DAG过滤掉,只需要增加一个文件引用,而不需要占据存储空间
- 数据对象格式
在IPFS中定义了Merkle DAG的对象格式。IPFS Object是存储结构,我们前面提到IPFS会限制每个数据大小在256KB以内。在IPFS Object对象里,我们保存两个部分,一个是Link,用于保存其他的分块数据的引用;另有一个是data,为本对象内容。Link主要包括3个部分,分别是Link的名字、Hash和Size,如以下代码所示。在这里Link只是对一个IPFS Object的引用,它不再重复存储一个IPFS对象了。
type IPFSObject struct {
links []IPFSLink //link数组
data []byte //数据内容
}
type IPFSLink struct {
Name string //link的名字
Hash Multihash //数据的加密哈希值
Size int //数据大小
}
使用Git和Merkle DAG的集合会极大减少存储空间消耗,因为对源文件的修改如果使用Merkle DAG来存储,那么修改的内容可能是很少的一部分。我们不再需要将整个修改后的文件再做一次备份了。这也就是IPFS节省存储空间的原因。