python 数据分析(六)astype('category')按类别分组 + 分组聚合操作 + 透视表 + 交叉表 + excel表的数据处理
文章目录
- 一、按照类别单独分类astype()
- 1. astype()用法
- 二、时间操作
- 1. 第一种:直接利用to_datetime()
- 2. 第二种:Series.dt
- 三、分组聚合操作
- 1. 分组
- (1)groupby()方法
- 2. 聚合
- (1)agg()方法
- ① 使用方法1
- ② 使用方法2
- ③ 使用方法3
- ④ 使用方法4
- (2)在分组的基础上进行聚合操作
- (3)apply()方法
- (4)transform()方法
- ① 对于离差标准化
- 四、透视表
- 五、crosstab 函数创建交叉表
- 六、excel表的数据处理
- 1. 工号与名字一致重复(去重)
- 2. 员工平均工作年限
- 3. 任职最久的3位
- 4. 员工总体流失率
- 5. 各部门有多少员工
一、按照类别单独分类astype()
按照普通的mean来求菜品的均价无法计算(中间可能会有重复的菜品);
但按照类别对菜品进行分类获取的菜品是唯一的,这就用到了astype()方法并配合category(类别)来完成
普通求法:
import pandas
detail = pandas.read_excel('detail.xlsx')
print(detail.loc[:,['counts','amounts']].describe())

获得的count会有重复,这就会用到astype
1. astype()用法
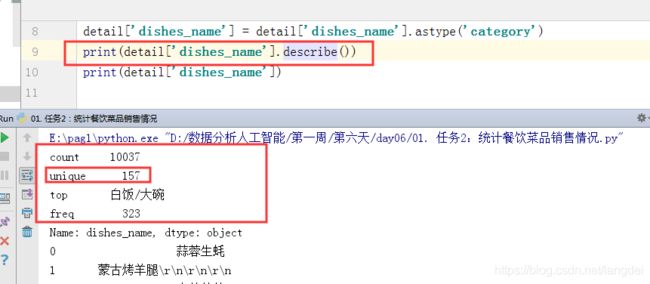
detail['dishes_name'] = detail['dishes_name'].astype('category')
print(detail['dishes_name'].describe())
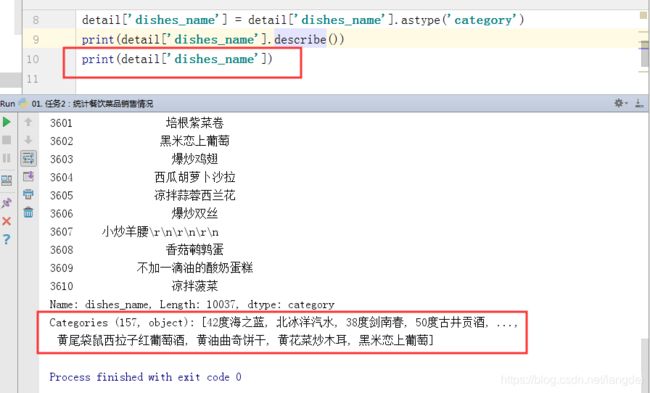
print(detail['dishes_name'])
二、时间操作
将本身的数据类型转换成符合条件的时间日期型,方便数据操作
1. 第一种:直接利用to_datetime()
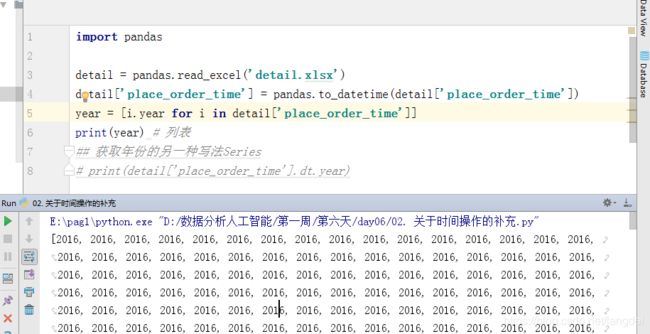
import pandas
detail = pandas.read_excel('detail.xlsx')
detail['place_order_time'] = pandas.to_datetime(detail['place_order_time'])
year = [i.year for i in detail['place_order_time']]
2. 第二种:Series.dt
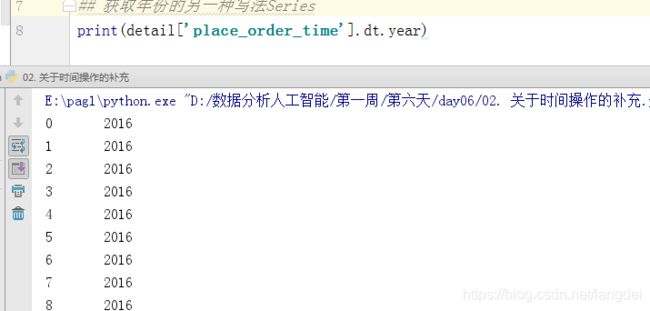
序列的.dt方法其实就是datatime方法的转换
print(detail['place_order_time'].dt.year)
三、分组聚合操作
1. 分组
(1)groupby()方法
groupby参数:
def groupby(self, by=None, axis=0, level=None, as_index=True, sort=True,group_keys=True, squeeze=False, **kwargs)

分组获取指定列对象
result = detail[['order_id','counts','amounts']].groupby(by='order_id')
print(result) # 
获取的是DataFrameGroupBy 对象
print(result['order_id'])#SeriesGroupBy
但对于DataFrameGroupBy取出的就是SeriesGroupBy对象
我们可以对分组后的对象进行一些操作:如均值
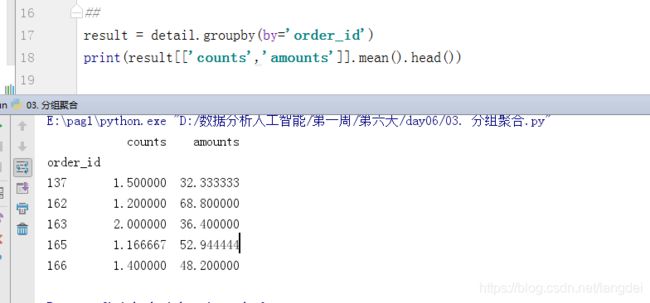
result = detail.groupby(by='order_id')
print(result[['counts','amounts']].mean().head())
亦可以对分组后的对象进行一些聚合操作
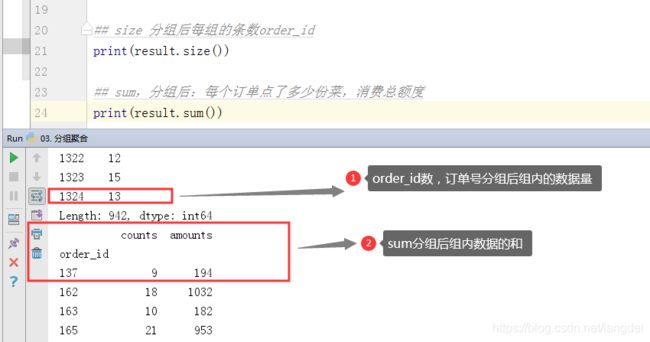
## size 分组后每组的条数order_id
print(result.size())
## sum,分组后:每个订单点了多少份菜,消费总额度
print(result.sum())
说明:可以进行分组,分组后的所有列只能使用一种聚合函数操作
注意:如果想让不同的列进行不同的聚合操作,需要写两次代码
2. 聚合
(1)agg()方法
DataFrame.agg(func, axis=0, *args, **kwargs)
# func是一个函数,如果接多个函数,需要使用列表将多个函数名封装起来,可以使用我们自己定义的也可以使用聚合函数
- agg,aggregate 方法都支持对每个分组应用某函数,包括 Python 内置函数或自定义函数。 同时这两个方法能够也能够直接对 DataFrame 进行函数应用操作。
- 在正常使用过程中,agg 函数和 aggregate 函数对 DataFrame 对象操作时功能几乎完全相 同,因此只需要掌握其中一个函数即可。
- 它们的参数说明如下表

以我们之前的所学无法求不同列的均值,和等聚合操作;但利用agg方法我们可以来做个尝试
- 求不同列的和
result1 = detail[['counts','amounts']].agg(numpy.sum) print(result1)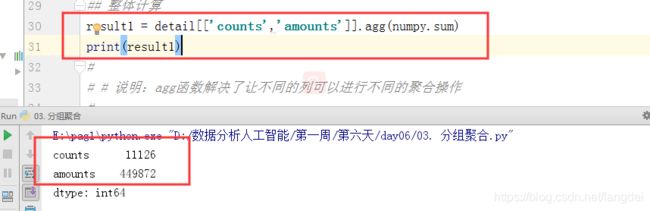
说明:agg函数解决了让不同的列可以进行不同的聚合操作
① 使用方法1
-
对counts和amounts进行均值、求和操作
result2 = detail[['counts','amounts']].agg([numpy.sum,numpy.mean]) print(result2)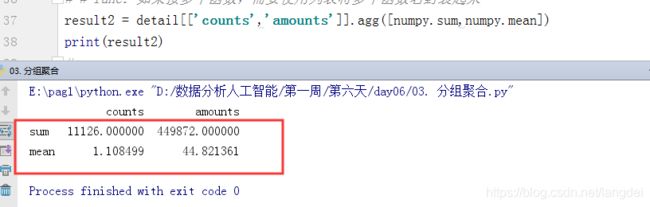
② 使用方法2
-
对counts进行求和操作,对amounts进行均值操作
result3 = detail.agg({'counts':numpy.sum,'amounts':numpy.mean}) print(result3)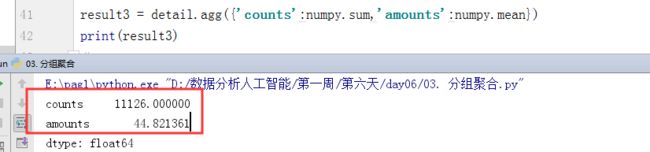
③ 使用方法3
-
对一个列进行多个聚合操作,
result4 = detail.agg({'counts':numpy.sum,'amounts':[numpy.sum,numpy.mean]}) print(result4)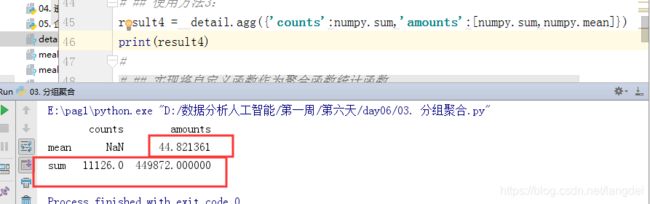
④ 使用方法4
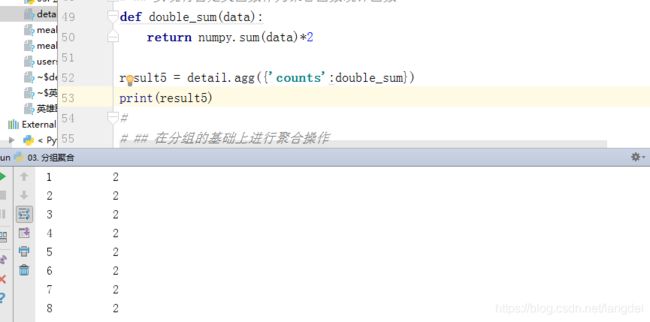
- 实现将自定义函数作为聚合函数统计函数
def double_sum(data):
return numpy.sum(data)*2
result5 = detail.agg({'counts':double_sum})
print(result5)
(2)在分组的基础上进行聚合操作
即DataFrameGroupBy.聚合操作
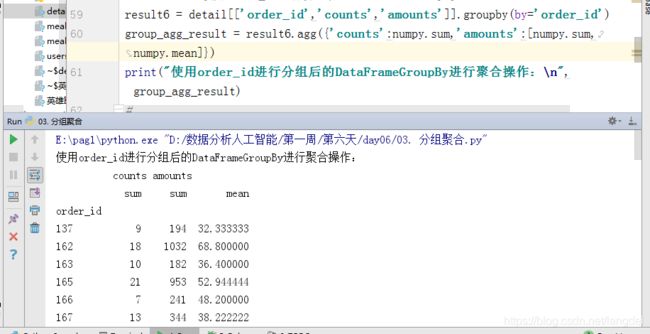
result6 = detail[['order_id','counts','amounts']].groupby(by='order_id')
group_agg_result = result6.agg({'counts':numpy.sum,'amounts':[numpy.sum,numpy.mean]})
print("使用order_id进行分组后的DataFrameGroupBy进行聚合操作:\n",group_agg_result)
(3)apply()方法
注意:agg与apply的区别:
主要区别在于
- apply是对整个表格中的数据进行聚合操作
- 而agg方法可以让不同的字段应用不同的聚合函数
相同之处就是:
- 都可以对分组后的数据进行聚合操作
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)

apply仅支持对某些列或所有数据进行聚合操作,但满足不了不同的列应用不同的聚合操作
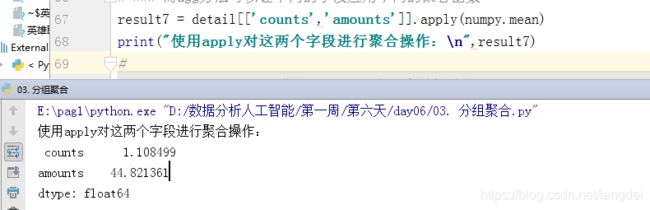
result7 = detail[['counts','amounts']].apply(numpy.mean)
print("使用apply对这两个字段进行聚合操作:\n",result7)
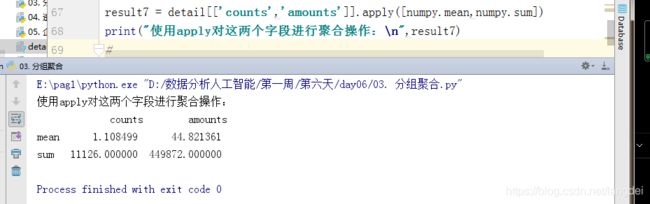
因为参数是func,亦可以完成多个聚合操作
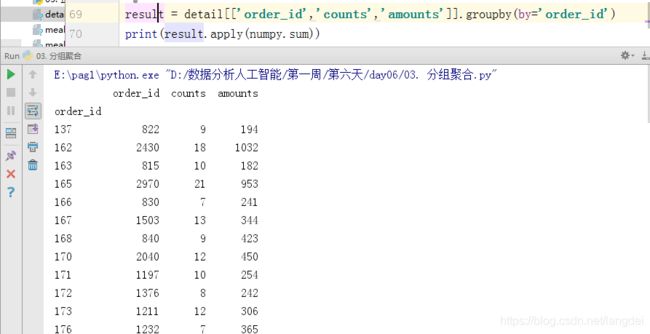
在分组后也可以使用apply进行聚合操作
(4)transform()方法
- transform 方法能够对整个 DataFrame 的所有元素进行操作。且 transform 方法只有一个 参数“func”,表示对 DataFrame 操作的函数。
- 同时 transform 方法还能够对 DataFrame 分组后的对象 GroupBy 进行操作,可以实现组 内离差标准化等操作。
- 若在计算离差标准化的时候结果中有 NaN,这是由于根据离差标准化公式,最大值和 最小值相同的情况下分母是 0。而分母为 0 的数在 Python 中表示为 NaN。
def transform(self, func, *args, **kwargs)
func表名可以传入函数对其聚合操作,自定义函数进行离差标准化操作

① 对于离差标准化
agg/apply/transform都可以用来做离差标准化;因为参数中都有func,都可以自定义函数
counts_min = detail['counts'].min()
counts_max = detail['counts'].max()
# ## 用result6报错是因为分组后取counts是一组一组的,不是一个一个的数据
print("对counts进行离差标准化",detail['counts'].transform(lambda x:(x-counts_min)/(counts_max-counts_min)))
print("对counts进行离差标准化",detail['counts'].apply(lambda x:(x-counts_min)/(counts_max-counts_min)))
print("对counts进行离差标准化",detail['counts'].agg(lambda x:(x-counts_min)/(counts_max-counts_min)))

注意:不能用分组后的数据来进行离差标准化;分组后取counts是一组一组的,不是一个一个的数据
通过离差标准化可以计算方差或标准差
衡量数据离散程度可以使用方差或标准差
amounts_min = detail['amounts'].min()
amounts_max = detail['amounts'].max()
print('菜品价格的标准差:',detail['amounts'].std())
detail['amounts_licha']= (detail['amounts'] - amounts_min)/(amounts_max-amounts_min)
print('菜品价格的离差标准化:',detail['amounts_licha'].std())
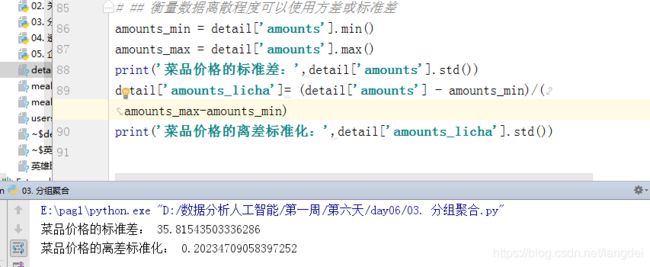
不使用离差标准化会因为单位不同等原因造成方差的结果很大,对实际不符
四、透视表
利用 pivot_table 函数可以实现透视表,pivot_table()函数的常用参数及其使用格式如下
def pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',fill_value=None, margins=False, dropna=True,margins_name='All')
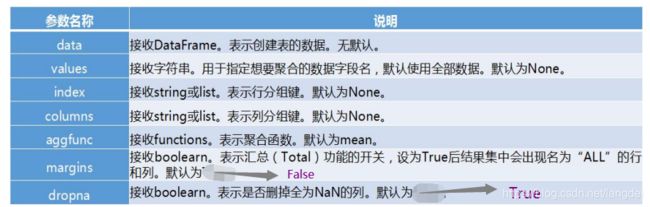
- pivot_table自带聚合函数mean操作(默认的)在不特殊指定聚合函数 aggfunc 时,会默认使用 numpy.mean 进行聚合运算,numpy.mean 会自动过滤掉非数值类型数据。可以通过指定 aggfunc 参数修改聚合函数。
- index相当于分组;如下面对order_id分组;和 groupby 方法分组的时候相同,pivot_table 函数在创建透视表的时候分组键 index 可 以有多个
- 通过设置 columns 参数可以指定列分组
- 当全部数据列数很多时,若只想要显示某列,可以通过指定 values 参数来实现。
- 当某些数据不存在时,会自动填充 NaN,因此可以指定 fill_value 参数,表示当存在缺 失值时,以指定数值进行填充
- 可以更改 margins 参数,查看汇总数据。
detail_pivot1 = pandas.pivot_table(detail[['order_id','counts','amounts']],index='order_id')
print(detail_pivot1)
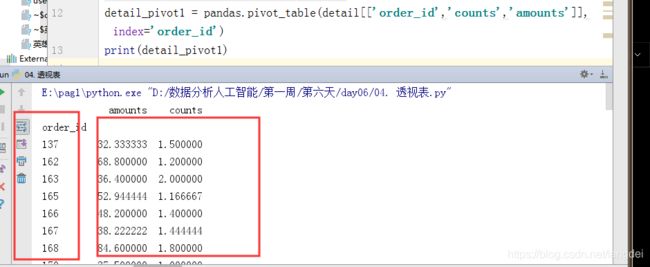
按order_id分组,并求均值
如果想要指定聚合函数aggfunc=’'
aggfunc=’'内置是字符串可以直接写聚合函数,但最好用numpy.方法;可以提示,防止写错
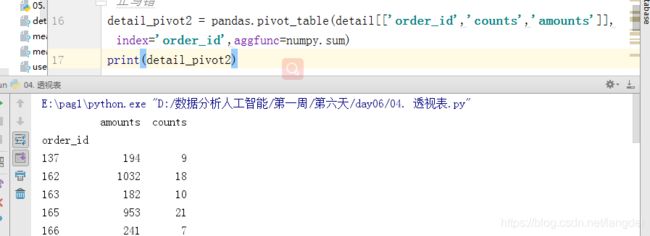
detail_pivot2 = pandas.pivot_table(detail[['order_id','counts','amounts']],index='order_id',aggfunc=numpy.sum)
print(detail_pivot2)
五、crosstab 函数创建交叉表
交叉表是一种特殊的透视表,主要用于计算分组频率。利用 pandas 提供的 crosstab 函数 可以制作交叉表,crosstab 函数的常用参数和使用格式如下
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, dropna=True, normalize=False)
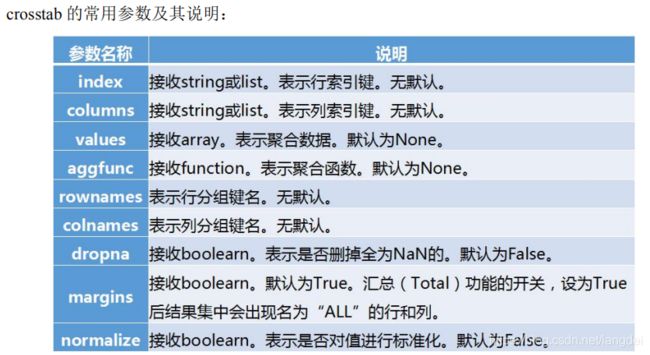
由于交叉表是透视表的一种,其参数基本保持一致,不同之处在于 crosstab 函数中的 index,columns,values 填入的都是对应的从 Dataframe 中取出的某一列。
交叉表和透视表的index区别:交叉表index不能直接跟字段名‘order_id’,跟的是字段值detail[‘order_id’]
result = pandas.crosstab(index=detail['order_id'],columns=detail['dishes_name'],values=detail['counts'],aggfunc=numpy.sum) ## sum是把相同order_id的放在一行了
print(result)
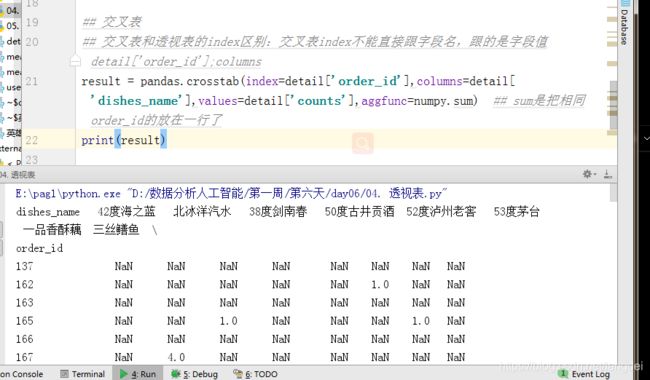
columns为对应列的所有数据作为交叉表的列,values是对应数量放在对应列下,aggfunc=numpy.sum是把分组order_id的所有内容加到一行
六、excel表的数据处理
1. 工号与名字一致重复(去重)
def drop_duplicates(self, subset=None, keep='first', inplace=False)
import pandas
data = pandas.read_excel('英雄联盟员工信息表.xlsx')
print("原始数据:",data.shape) # 原始数据: (22, 8)
#1. 工号与名字一致重复
# def drop_duplicates(self, subset=None, keep='first', inplace=False)
data.drop_duplicates(subset=['工号','姓名'],inplace=True)
print("去除重复员工后:",data.shape) # 去除重复员工后: (20, 8)
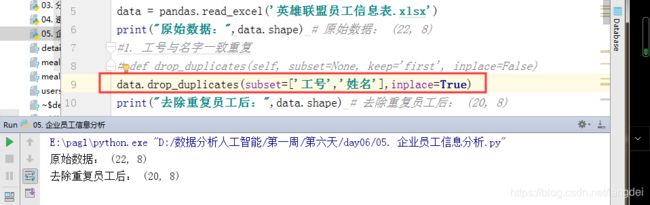
注意:drop_duplicates默认是对这一行的所有数据进行比对,完全一样才会骑去重;我们可以通过subset=[’’,’’]来指定几个字段去重
inplace=False有返回值,不作用在原数据上;inplace=True无返回值,作用在原数据上
2. 员工平均工作年限
print(data['工龄'].mean()) # 3.8
3. 任职最久的3位
对序列进行排序用sort_values
def sort_values(self, by, axis=0, ascending=True, inplace=False,kind='quicksort', na_position='last')
result_Sort = data[['姓名','工龄']].sort_values(by='工龄',ascending=False,inplace=False)
print(result_Sort.head(3))
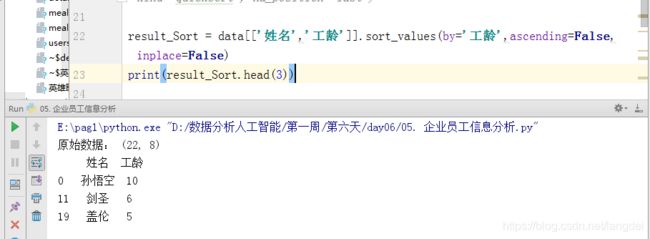
ascending有两个值:True和False,升序和降序
注意:若是之前的表格改变,而且排序后再将值赋给表格会报错,可能是行缺失,可能是排序后值不匹配;所以用inplace=False
4. 员工总体流失率
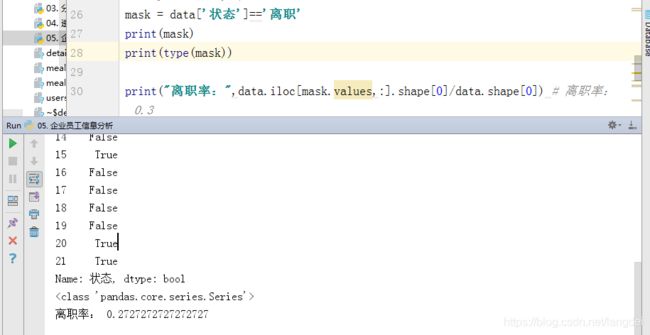
mask = data['状态']=='离职'
print(mask)
print(type(mask))
print("离职率:",data.iloc[mask.values,:].shape[0]/data.shape[0]) # 离职率: 0.3
mask.values为False的则不显示,True的显示。通过判断有多少行来求离职的,除以所有的,即为离职率
对一个序列对象如果单纯的想获取值,可以使用values属性
print(mask.values) # [ True False False True False False False False False False False False True False True False False False True True]
根据上面的代码我们可以利用Boolean值相加减来获得离职的人数,以此来求离职率
print("离职率:",mask.values.sum()/data.shape[0]) # 离职率: 0.3
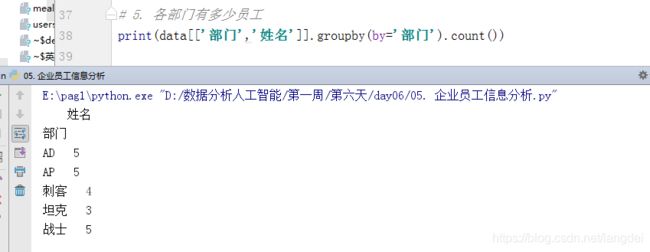
5. 各部门有多少员工
print(data[['部门','姓名']].groupby(by='部门').count())
print((data[['部门']].groupby(by='部门')).count())
这种方式取出为空,因为你没有索引让他列出值