字节序:Big Endian 和 Little Endian
字节序
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果C/C++中的一个int型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103位置。
根据整数 a 在连续的 4 byte 内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类。 然后就牵涉出两大CPU派系:
- Motorola 6800,PowerPC 970,SPARC(除V9外)等处理器采用 Big Endian方式存储数据;
- x86系列,VAX,PDP-11等处理器采用Little Endian方式存储数据。
另外,还有一些处理器像ARM, DEC Alpha的字节序是可配置的。
大端与小端
那么,到底什么是大端,什么是小端? 如下图:
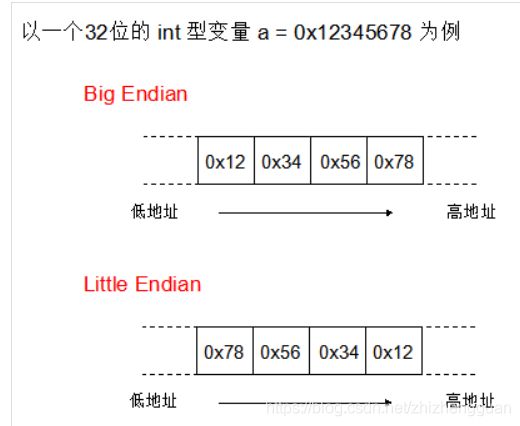
我相信上面的图已经够直观了。也就是说:
- Big Endian 是指低地址端 存放 高位字节。
- Little Endian 是指低地址端 存放 低位字节。
各自的优势:
- Big Endian:符号位的判定固定为第一个字节,容易判断正负。
- Little Endian:长度为1,2,4字节的数,排列方式都是一样的,数据类型转换非常方便。
为什么要注意字节序
如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。
但是,如果你的程序要跟别人的程序产生交互呢? 比如,当一个 C/C++ 的程序要与一个 Java 程序交互时:
-
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而现在比较普遍的 x86 处理器是 Little Endian
-
JAVA编写的程序则唯一采用 Big Endian 方式来存储数据
试想,如果你的C/C++程序将变量 a = 0x12345678 的首地址传递给了Java程序,由于Java采取 Big Endian 方式存储数据,很自然的它会将你的数据翻译为 0x78563412。显然,问题就出现了!!!
另外,网络传输一般采用 Big Endian,也被称之为网络字节序,或网络序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。
两种字节序:网络序和主机序
网络字节序:TCP/IP各层协议将字节序定义为 Big Endian,因此TCP/IP协议中使用的字节序是大端序。是确定的
主机字节序:整数在内存中存储的顺序,由 CPU 架构决定,可能是小端,也可能是大端,常用的 Intel 与 AMD 的 CPU 均为小端字节序。
在进行网络通信时 通常需要调用相应的函数进行主机序和网络序的转换。
判断机器的字节序
由于 C/C++ 存储数据时的字节序依赖所在平台的CPU,所以我们可以通过C/C++程序判定机器的端序:
void Endianness()
{
int a = 0x12345678;
if( *((char*)&a) == 0x12)
cout << "Big Endian" << endl;
else
cout << "Little Endian" << endl;
}
golang
package main
import (
"fmt"
)
import "unsafe"
func IsLittleEndian() bool {
n := 0x12345678
return *(*byte)(unsafe.Pointer(&n)) == 0x78 //Golang 是强类型语言,不允许不同类型的指针之间进行强制转化,因此需要借助 unsafe.Pointer 进行一次中转。
}
func main() {
fmt.Println(IsLittleEndian())
}
golang固定长度编码 Fixed-length encoding
Go 中有多种类型的整型, int8, int16, int32 和 int64 ,分别使用 1, 3, 4, 8 个字节表示,我们称之为固定长度类型 (fixed-length types)。
Go 处理固定长度字节序
Go中处理大小端序的代码位于 encoding/binary ,包中的全局变量BigEndian用于操作大端序数据,LittleEndian用于操作小端序数据,这两个变量所对应的数据类型都实行了ByteOrder接口
type ByteOrder interface {
Uint16([]byte) uint16
Uint32([]byte) uint32
Uint64([]byte) uint64
PutUint16([]byte, uint16)
PutUint32([]byte, uint32)
PutUint64([]byte, uint64)
String() string
}
其中,前三个方法用于读取数据,后三个方法用于写入数据。
上面的方法操作的都是无符号整型,如果我们要操作有符号整型的时候怎么办呢?很简单,强制转换就可以了,比如这样:
func PutInt32(b []byte, v int32) {
binary.BigEndian.PutUint32(b, uint32(v))
}
BigEndian 和 LittleEndian 实现了 ByteOrder 接口
//BigEndian is the big-endian implementation of ByteOrder.
var BigEndian bigEndian
//LittleEndian is the little-endian implementation of ByteOrder.
var LittleEndian littleEndian
举个例子,把固定长度的数字写入字节切片 (byte slice),然后从字节切片中读取到并赋值给一个变量:
// write
v := uint32(500)
buf := make([]byte, 4)
binary.BigEndian.PutUint32(buf, v)
// read
x := binary.BigEndian.Uint32(buf)
在这里,需要注意的是使用 put 写时要保证足够的切片长度,另外如果从流 (stream) 读取时要使用 io.ReadFull 确保读取的是原始字节,而不是使用特定的 read Buffer 编码处理过的字节。
go处理大端序和小端序的方式:
package main
import (
"encoding/binary"
"fmt"
"unsafe"
)
const INT_SIZE int = int(unsafe.Sizeof(0))
//判断我们系统中的字节序类型
func systemEdian() {
var i int = 0x1
bs := (*[INT_SIZE]byte)(unsafe.Pointer(&i))
if bs[0] == 0 {
fmt.Println("system edian is little endian")
} else {
fmt.Println("system edian is big endian")
}
}
func testBigEndian() {
// 0000 0000 0000 0000 0000 0001 1111 1111
var testInt int32 = 256
fmt.Printf("%d use big endian: \n", testInt)
var testBytes []byte = make([]byte, 4)
binary.BigEndian.PutUint32(testBytes, uint32(testInt))
fmt.Println("int32 to bytes:", testBytes)
convInt := binary.BigEndian.Uint32(testBytes)
fmt.Printf("bytes to int32: %d\n\n", convInt)
}
func testLittleEndian() {
// 0000 0000 0000 0000 0000 0001 1111 1111
var testInt int32 = 256
fmt.Printf("%d use little endian: \n", testInt)
var testBytes []byte = make([]byte, 4)
binary.LittleEndian.PutUint32(testBytes, uint32(testInt))
fmt.Println("int32 to bytes:", testBytes)
convInt := binary.LittleEndian.Uint32(testBytes)
fmt.Printf("bytes to int32: %d\n\n", convInt)
}
func main() {
systemEdian()
fmt.Println("")
testBigEndian()
testLittleEndian()
}
Go 处理固定长度流 (stream processing)
binary package 提供了内置的读写固定长度值的流 (stream):
func Read(r io.Reader, order ByteOrder, data interface{}) error
func Write(w io.Writer, order ByteOrder, data interface{}) error
Read 通过指定类型的字节序把字节解码 (decode) 到 data 变量中。解码布尔类型时,0 字节 (也就是 []byte{0x00}) 为 false, 其他都为 true
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
func main() {
var(
piVar float64
boolVar bool
)
piByte := []byte{0x18, 0x2d, 0x44, 0x54, 0xfb, 0x21, 0x09, 0x40}
boolByte := []byte{0x00}
piBuffer := bytes.NewReader(piByte)
boolBuffer := bytes.NewReader(boolByte)
binary.Read(piBuffer, binary.LittleEndian, &piVar)
binary.Read(boolBuffer, binary.LittleEndian, & boolByte)
fmt.Println("pi", piVar) // pi 3.141592653589793
fmt.Println("bool", boolVar) // bool false
}
Write 是 Read 的逆过程,直接看例子比较直观:
package main
import (
"bytes"
"encoding/binary"
"fmt"
"math"
)
func main() {
buf := new(bytes.Buffer)
var pi float64 = math.Pi
err := binary.Write(buf, binary.LittleEndian, pi)
if err != nil {
fmt.Println("binary.Write failed:", err)
}
fmt.Printf("% x", buf.Bytes()) // 18 2d 44 54 fb 21 09 40
}
在实际编码中,面对复杂的数据结构,可考虑使用更标准化高效的协议,比如 Protocol Buffer。
可变长度编码 Variable-length encoding
固定长度编码对存储空间的占用不灵活,比如一个 int64 类型范围内的值,当值较小时就会产生比较多的 0 字节无效位,直至达到 64 位。使用可变长度编码可限制这种空间浪费。
原理
可变长度编码理想情况下值小的数字占用的空间比值大的数字少,有多种实现方案,Go Binary 实现方式和 protocol buffer encoding 一致,具体原理如下:
每个字节的首位存放一个标识位,用以表明是否还有跟多字节要读取及剩下的七位是否真正存储数据。标识位分别为 0 和 1
- 1 表示还要继续读取该字节后面的字节
- 0 表示停止读取该字节后面的字节
一旦所有读取完所有的字节,每个字节串联的结果就是最后的值。举例说明:数字 53 用二进制表示为 110101 ,需要六位存储,除了标识位还剩余七位,所以在标识位后补 0 凑够七位,最终结果为 00110101。标识位 0 表明所在字节后面没有字节可读了,标识位后面的 0110101 保存了值。
再来一个大点的数字举例,1732 二进制使用 11011000100 表示,实际上只需使用 11 位的空间存储,除了标识位每个字节只能保存 7 位,所以数字 1732 需要两个字节存储。第一个字节使用 1 表示所在字节后面还有字节,第二个字节使用 0 表示所在字节后面没有字节,最终结果为:10001101 01000100
go处理可变长度的字节序
函数 putVarint() 和 putUvarint() 把可变长值写到内存字节切片中
func PutVarint(buf []byte, x int64) int
func PutUvarint(buf []byte, x uint64) int
这两个函数把 x 编码到 buf 中并返回写入 buf 中字节的长度,如果 buf 初始化长度过小(比 x 还要小)函数就会 panic , 建议使用 binary.MaxVarintLen64 常量确保出现 panic 的情况。
package main
import (
"encoding/binary"
"fmt"
)
func main() {
buf := make([]byte, binary.MaxVarintLen64)
for _, x := range []int64{-65, 1, 2, 127, 128, 255, 256} {
n := binary.PutVarint(buf, x)
fmt.Print(x, "输出的可变长度为:", n, ",十六进制为:")
fmt.Printf("%x\n", buf[:n])
}
}
-65输出的可变长度为:2,十六进制为:8101
1输出的可变长度为:1,十六进制为:02
2输出的可变长度为:1,十六进制为:04
127输出的可变长度为:2,十六进制为:fe01
128输出的可变长度为:2,十六进制为:8002
255输出的可变长度为:2,十六进制为:fe03
256输出的可变长度为:2,十六进制为:8004
函数 Varint() 和 Uvarint() 把字节码转为十进制。
func Varint(buf []byte) (int64, int)
func Uvarint(buf []byte) (uint64, int)
package main
import (
"encoding/binary"
"fmt"
)
func main() {
inputs := [][]byte{
[]byte{0x81, 0x01},
[]byte{0x7f},
[]byte{0x03},
[]byte{0x01},
[]byte{0x00},
[]byte{0x02},
[]byte{0x04},
[]byte{0x7e},
[]byte{0x80, 0x01},
}
for _, b := range inputs {
x, n := binary.Varint(b)
if n != len(b) {
fmt.Println("Varint did not consume all of in")
}
fmt.Println(x) // -65,-64,-2,-1,0,1,2,63,64,
}
}
go处理可变长度字节流数据 Decoding from a byte stream
binary 包提供了两个函数从字节流中读取到可变长度值。
func ReadVarint(r io.ByteReader) (int64, error)
func ReadUvarint(r io.ByteReader) (uint64, error)
总结
二进制协议 (Binary protocol) 高效地在底层处理数据通信,字节序决定字节输出的顺序、通过可变长度编码压缩数据存储空间。理解了 Encoding/binary 库之后,我们可以继续深入理解当前一些主流的二进制协议。