LinkedHashMap原理
LinkedHashMap是hashmap和链表的结合体,通过链表记录元素的顺序和连接关系,通过hashmap来存储数据,可以控制元素被遍历的时候输出的顺序(按访问顺序,还是按照插入顺序)。
元素被保存在一个双向链表中,默认的遍历顺序是插入顺序来遍历,通过构造函数的accessOder来控制是否按照访问顺序来遍历,
linkedHashMap总是将最近访问的元素放在队列的尾部,所以第一个元素就是最不经常访问的元素,当容量充满了时候就会将第一个元素移除。
1)get的时候将当前被访问的这个对象移动到表的最后面。
2)linkedHashmap 没有put方法,直接调用父类hashmap的put方法。
hashmap的put方法如下:
//hash(key)就是上面讲的hash方法,对其进行了第一步和第二步处理
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
*
* @param hash 索引的位置
* @param key 键
* @param value 值
* @param onlyIfAbsent true 表示不要更改现有值
* @param evict false表示table处于创建模式
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//如果table为null或者长度为0,则进行初始化
//resize()方法本来是用于扩容,由于初始化没有实际分配空间,这里用该方法进行空间分配,后面会详细讲解该方法
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//注意:这里用到了前面讲解获得key的hash码的第三步,取模运算,下面的if-else分别是 tab[i] 为null和不为null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//tab[i] 为null,直接将新的key-value插入到计算的索引i位置
else {//tab[i] 不为null,表示该位置已经有值了
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//节点key已经有值了,直接用新值覆盖
//该链是红黑树
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
//该链是链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度大于8,转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//用作修改和新增快速失败
if (++size > threshold)//超过最大容量,进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
为了保证 LinkedHashMap 的迭代顺序,在添加元素时重写了的4个方法
1 newNode(hash, key, value, null);
2 putTreeVal(this, tab, hash, key, value)//newTreeNode(h, k, v, xpn)
3 afterNodeAccess(e);
4 afterNodeInsertion(evict);
1.newNode(hash, key, value, null);
HashMap.Node newNode(int hash, K key, V value, HashMap.Node e) {
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry p) {
//用临时变量last记录尾节点tail
LinkedHashMap.Entry last = tail;
//将尾节点设为当前插入的节点p
tail = p;
//如果原先尾节点为null,表示当前链表为空
if (last == null)
//头结点也为当前插入节点
head = p;
else {
//原始链表不为空,那么将当前节点的上节点指向原始尾节点
p.before = last;
//原始尾节点的下一个节点指向当前插入节点
last.after = p;
}
}
将当前添加的元素设为原始链表的尾结点。
2.putTreeVal(this, tab, hash, key, value)
1 TreeNode newTreeNode(int hash, K key, V value, Node next) {
2 TreeNode p = new TreeNode(hash, key, value, next);
3 linkNodeLast(p);
4 return p;
5 }
上面两个方法都是在将新添加的元素放置到链表的尾部,并维护链表节点之间的关系。
3.afterNodeAccess(e);
在 putVal 方法中,是当添加数据键值对的 key 存在时,会对 value 进行替换。然后调用 afterNodeAccess(e) 方法:
//把当前节点放到双向链表的尾部
void afterNodeAccess(HashMap.Node e) { // move node to last
LinkedHashMap.Entry last;
//当 accessOrder = true 并且当前节点不等于尾节点tail。这里将last节点赋值为tail节点
if (accessOrder && (last = tail) != e) {
//记录当前节点的上一个节点b和下一个节点a
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
//释放当前节点和后一个节点的关系
p.after = null;
//如果当前节点的前一个节点为null
if (b == null)
//头节点=当前节点的下一个节点
head = a;
else
//否则b的后节点指向a
b.after = a;
//如果a != null
if (a != null)
//a的前一个节点指向b
a.before = b;
else
//b设为尾节点
last = b;
//如果尾节点为null
if (last == null)
//头节点设为p
head = p;
else {
//否则将p放到双向链表的最后
p.before = last;
last.after = p;
}
//将尾节点设为p
tail = p;
//LinkedHashMap对象操作次数+1,用于快速失败校验
++modCount;
}
}
该方法是在AccessOder = true 并且插入的当前节点不等于尾结点时,该方法才生效,并且该方法的作用是将插入的节点变为尾节点,后面在get方法中也会调用。
4.afterNodeInsertion(evict);
void afterNodeInsertion(boolean evict) { // possibly remove eldest2 LinkedHashMap.Entry first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
该方法用来移除最老的首节点,首先方法要能执行到if语句里面,必须 evict = true,并且 头节点不为null,并且 removeEldestEntry(first) 返回true,这三个条件必须同时满足,前面两个好理解,我们看最后这个方法条件:
1 protected boolean removeEldestEntry(Map.Entry eldest) {
2 return false;
3 }
该方法直接返回的是 false,也就是说怎么都不会进入到 if 方法体内了,那这是这么回事呢?
这其实是用来实现 LRU(Least Recently Used,最近最少使用)Cache 时,重写的一个方法。比如在 mybatis-connector 包中,有这样一个类:
package com.mysql.jdbc.util;
import java.util.LinkedHashMap;
import java.util.Map.Entry;
public class LRUCache extends LinkedHashMap {
private static final long serialVersionUID = 1L;
protected int maxElements;
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true);
this.maxElements = maxSize;
}
protected boolean removeEldestEntry(Entry eldest) {
return this.size() > this.maxElements;
}
}
3)删除元素
也是调用了hashmap的remove方法
public V remove(Object key) {
Node e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
//(n - 1) & hash找到桶的位置
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
//如果键的值与链表第一个节点相等,则将 node 指向该节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//如果桶节点存在下一个节点
else if ((e = p.next) != null) {
//节点为红黑树
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);//找到需要删除的红黑树节点
else {
do {//遍历链表,找到待删除的节点
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//删除节点,并进行调节红黑树平衡
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
void afterNodeRemoval ( HashMap.Node e ) { // unlink
LinkedHashMap.Entry p = (LinkedHashMap.Entry)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
当我们删除某个节点时,为了保证链表还是有序的,那么必须维护其前后节点。而该方法的作用就是维护删除节点的前后节点关系。
4)get查找元素
public V get(Object key) {
Node e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
相比于 HashMap 的 get 方法,这里多出了第 5,6行代码,当 accessOrder = true 时,即表示按照最近访问的迭代顺序,会将访问过的元素放在链表后面。
5)遍历元素
①、得到 Entry 集合,然后遍历 Entry
LinkedHashMap map = new LinkedHashMap<>();
map.put("A","1");
map.put("B","2");
map.put("C","3");
map.get("B");
Set> entrySet = map.entrySet();
for(Map.Entry entry : entrySet ){
System.out.println(entry.getKey()+"---"+entry.getValue());
}
②、迭代
1 Iterator> iterator = map.entrySet().iterator();
2 while(iterator.hasNext()){
3 Map.Entry entry = iterator.next();
4 System.out.println(entry.getKey()+"----"+entry.getValue());
5 }
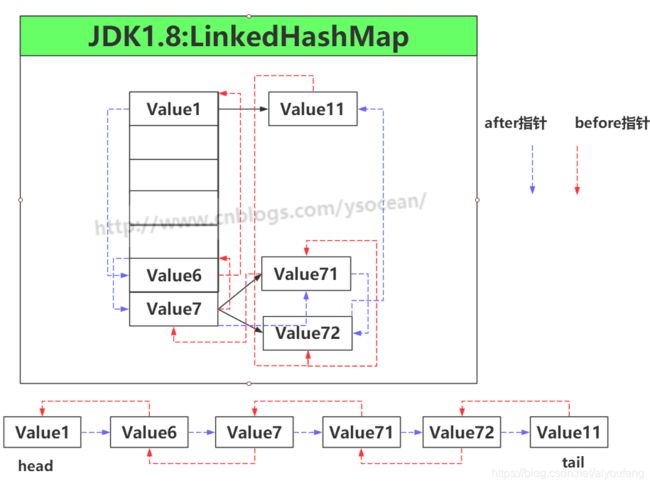
去掉红色和蓝色的虚线指针,其实就是一个HashMap。