Pig-使用PigLatin操作员工表和部门表
前提条件:
安装好hadoop2.7.3(Linux系统下)
安装好pig(Linux系统下),参考:Pig安装配置
准备源数据:
1. 打开终端,新建emp.csv文件
$ nano emp.csv输入内容如下,保存退出。
7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,102. 新建dept.csv文件
$ nano dept.csv输入以下内容,保存退出
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON开启jobhistoryserver进程:
jps确认hadoop进程是否完全开启,如果没有开启,用start-all.sh命令开启。此外,还要打开jobhistory进程,命令为:
$ mr-jobhistory-daemon.sh start historyserver![]()
jps命令可以发现多了一个进程:JobHistoryServer ,如果不开启jobhistory,执行dump命令会报错10020端口连接拒绝异常:
java.io.IOException: java.net.ConnectException: Call From node1/192.168.249.131 to 0.0.0.0:10020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
实验操作:
把上面两张表上传到hdfs某个目录下,如/001/pig,001表示学号,注意修改。
hdfs dfs -mkdir -p /001/pig
hdfs dfs -put dept.csv /001/pig
hdfs dfs -put emp.csv /001/pig(1)启动pig
$ pig(2) 加载hdfs中的文件,创建员工表、部门表
emp = load '/001/pig/emp.csv' using PigStorage(',') as(empno:int,ename:chararray,job:chararray,mgr:int,hiredate:chararray,sal:int,comm:int,deptno:int);
dept = load '/001/pig/dept.csv' using PigStorage(',') as(deptno:int,dname:chararray,loc:chararray);(3)查询员工信息:员工号 姓名 薪水
类似于SQL: select empno,ename,sal from emp; 以下语句不会触发计算,只有到dump语句时才触发计算。
emp3 = foreach emp generate empno,ename,sal; 执行输出命令:
dump emp3;(4)查询员工信息,按照月薪排序
类似于SQL: select * from emp order by sal;
emp4 = order emp by sal;dump emp4;(5)分组:求每个部门的最高工资: 部门号 部门的最高工资
类似于SQL: select deptno,max(sal) from emp group by deptno;
第一步:先分组:
emp51 = group emp by deptno;查看emp51的表结构:
describe emp51;dump emp51;第二步:求每个组(每个部门)工资的最大值 注意:MAX大写:
emp52 = foreach emp51 generate group,MAX(emp.sal);dump emp52;(6)查询10号部门的员工
类似于SQL: select * from emp where deptno=10;
emp6 = filter emp by deptno==10;注意:两个等号
dump emp6;(7)多表查询:部门名称、员工姓名
类似于SQL: select d.dname,e.ename from emp e,dept d where e.deptno=d.deptno;
emp71 = join dept by deptno,emp by deptno;emp72 = foreach emp71 generate dept::dname,emp::ename;dump emp72;(8)集合运算:查询10和20号部门的员工信息
select * from emp where deptno=10
union
select * from emp where deptno=20;
emp10 = filter emp by deptno==10;
emp20 = filter emp by deptno==20;
emp1020 = union emp10,emp20;
dump emp1020;(9)存储表到HDFS
store emp1020 into '/001/output_pig'; 注意:HDFS的/output_pig目录预先不存在
查看/001/output_pig目录的文件,用以下命令:sh开头表示在pig命令行下,不用切换到linux终端就可以执行Linux命令。
sh hdfs dfs -ls /001/output_pig 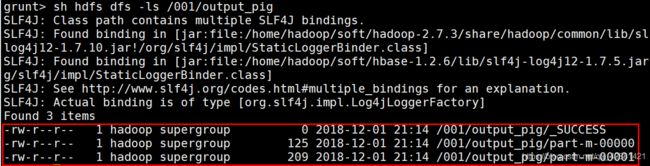
查看输出文件内容:
sh hdfs dfs -cat /001/output_pig/part-m-00000sh hdfs dfs -cat /001/output_pig/part-m-00001
(10)执行WordCount
准备数据:
Linux本地新建一个data.txt的文本文件,
$ nano data.txt内容如下:
Hello world
Hello hadoop
Hello pig将data.txt上传到HDFS的/001目录下
$ hdfs dfs -put data.txt /001a.加载数据
mydata = load '/001/data.txt' as (line:chararray);b.将字符串分割成单词
words = foreach mydata generate flatten(TOKENIZE(line)) as word;c.对单词进行分组
grpd = group words by word; d.统计每组中单词数量
cntd = foreach grpd generate group,COUNT(words);e.打印结果
dump cntd;
完成! enjoy it!