Hyperledger Fabric RAFT共识协议探究
Hyperledger Fabric在发布1.4.3版本时,增加了新的共识策略Raft,以此来循序渐进地迁移至拜占庭容错算法(PBFT),它是一种基于etcd的崩溃容错(CFT)排序服务。Raft 遵循 “领导者和追随者” 模型,其中每个通道都会选举一个 leader,而且它的决策会复制给追随者。和基于 Kafka 的排序服务相比,基于 Raft 的排序服务将变得更容易设置和管理,并且它的设计允许遍布全球的组织成为分散的排序服务贡献节点。
拜占庭将军问题是分布式领域最复杂、最严格的容错模型。但在日常工作中使用的分布式系统面对的问题不会那么复杂,更多的是计算机故障挂掉了,或者网络通信问题而没法传递信息,这种情况不考虑计算机之间互相发送恶意信息,极大简化了系统对容错的要求,最主要的是达到一致性。
所以将拜占庭将军问题根据常见的工作上的问题进行简化:假设将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成一致性决定?
对于这个简化后的问题,有许多解决方案,第一个被证明的共识算法是 Paxos,由拜占庭将军问题的作者 Leslie Lamport 在1990年提出,最初以论文难懂而出名,后来这哥们在2001重新发了一篇简单版的论文 Paxos Made Simple,然而还是挺难懂的。
因为 Paxos 难懂,难实现,所以斯坦福大学的教授在2014年发表了新的分布式协议 Raft。与 Paxos 相比,Raft 有着基本相同运行效率,但是更容易理解,也更容易被用在系统开发上。
1. Raft 节点状态
从拜占庭将军的故事映射到分布式系统上,每个将军相当于一个分布式网络节点,每个节点有三种状态:Follower,Candidate,Leader,状态之间是互相转换的。
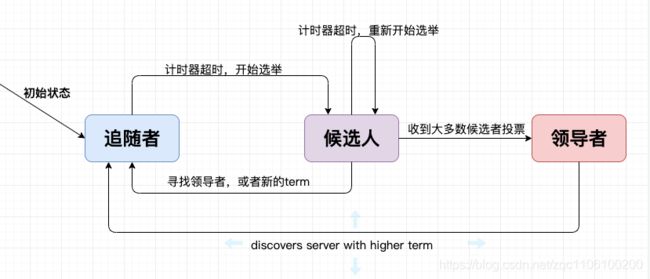
每个节点上都有一个倒计时器 (Election Timeout),时间随机在 150ms 到 300ms 之间。有几种情况会重设 Timeout:
- 收到选举的请求
- 收到 Leader 的 Heartbeat
2.选举Leader
2.1 正常情况下选leader
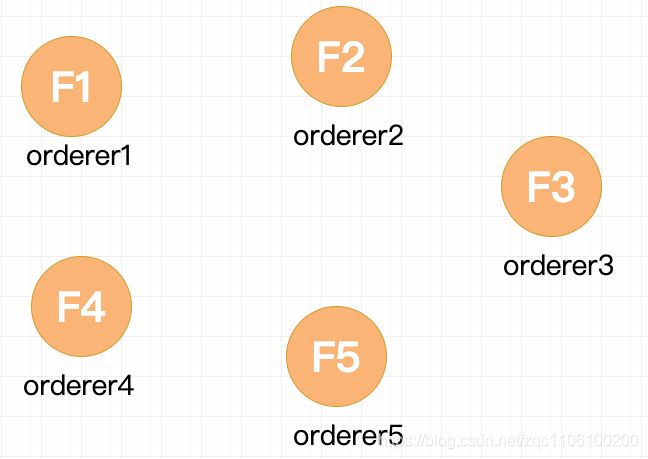
假设现在有如图5个orderer节点,5个节点一开始的状态都是 Follower
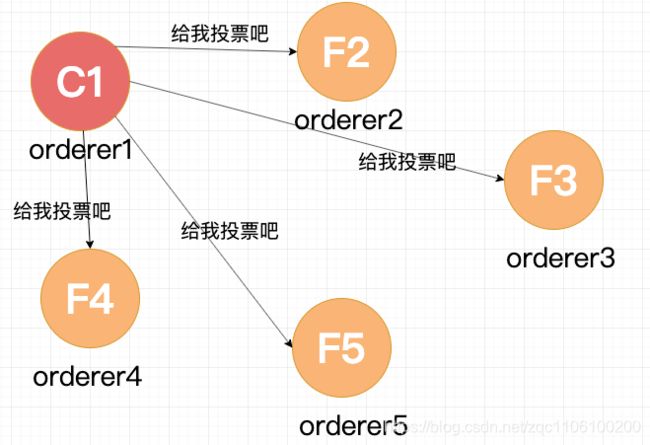
在一个节点倒计时结束 (Timeout) 后,这个节点的状态变成 Candidate 开始选举,它给其他几个节点发送选举请求 (RequestVote)
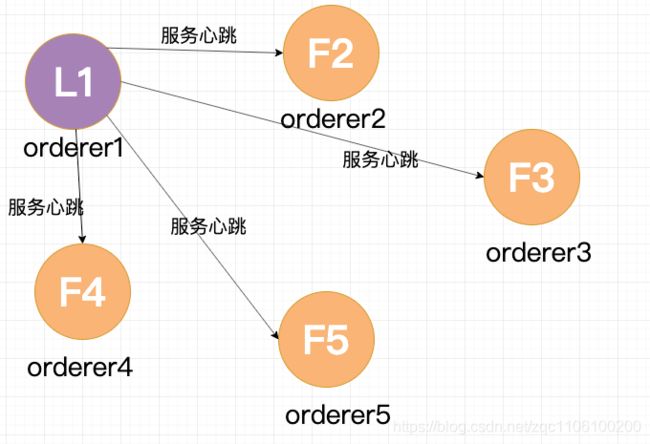
其他四个节点都返回成功,这个节点的状态由 Candidate 变成了 Leader,并在每个一小段时间后,就给所有的 Follower 发送一个 Heartbeat 以保持所有节点的状态,Follower 收到 Leader 的 Heartbeat 后重设 Timeout。
这是最简单的选主情况,只要有超过一半的节点投支持票了,Candidate 才会被选举为 Leader。
2.2 Leader 出故障情况下的选举
一开始已经有一个 Leader,所有节点正常运行。

Leader 出故障挂掉了,其他四个 Follower 将进行重新选主。
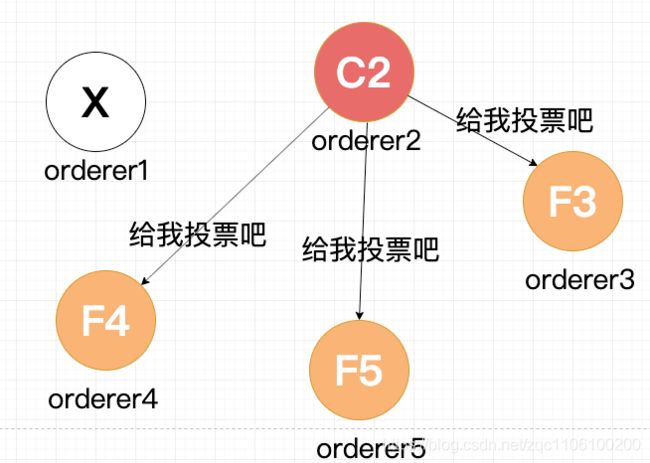
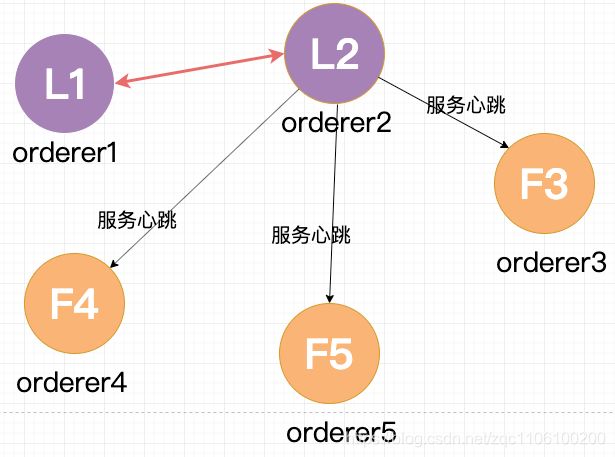
4个节点的选主过程和5个节点的类似,在选出一个新的 Leader 后,原来的 Leader 恢复了又重新加入了,这个时候怎么处理?在 Raft 里,第几轮选举是有记录的,重新加入的 Leader 是第一轮选举 (Term 1) 选出来的,而现在的 Leader 则是 Term 2,所有原来的 Leader 会自觉降级为 Follower

2.3 多个 Candidate 情况下的选主
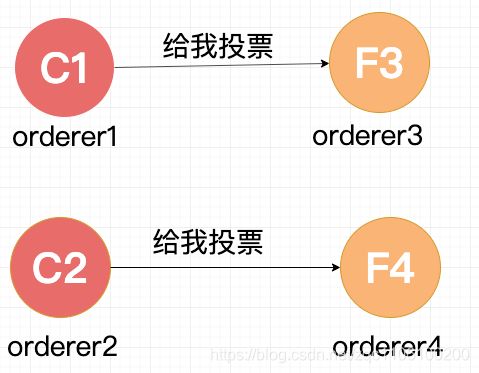
有两个 Follower 同时 Timeout,都变成了 Candidate 开始选举,分别给一个 Follower 发送了投票请求。
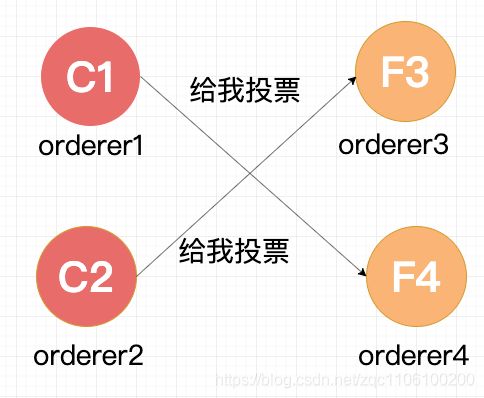
两个 Follower 分别返回了ok,这时两个 Candidate 都只有2票,要3票才能被选成 Leader。两个 Candidate 会分别给另外一个还没有给自己投票的 Follower 发送投票请求。但是因为 Follower 在这一轮选举中,都已经投完票了,所以都拒绝了他们的请求。所以在 Term 2 没有 Leader 被选出来。

这时,两个节点的状态是 Candidate,两个是 Follower,但是他们的倒计时器仍然在运行,最先 Timeout 的那个节点会进行发起新一轮 Term 3 的投票。两个 Follower 在 Term 3 还没投过票,所以返回 OK,这时 Candidate 一共有三票,被选为了 Leader。

如果 Leader Heartbeat 的时间晚于另外一个 Candidate timeout 的时间,另外一个 Candidate 仍然会发送选举请求。两个 Follower 已经投完票了,拒绝了这个 Candidate 的投票请求。
Leader 进行 Heartbeat, Candidate 收到后状态自动转为 Follower,完成选主。
总结
Raft 是能够实现分布式系统强一致性的算法,每个系统节点有三种状态 Follower,Candidate,Leader。
参考链接:
Raft 官网:https://raft.github.io/
Raft 原理动画 (推荐看看):http://thesecretlivesofdata.com/raft/